V dubnu jsem psal o některých nativních metodách v rámci SQL Server, které lze použít ke sledování automatických aktualizací statistik. Tři možnosti, které jsem poskytl, byly SQL Trace, Extended Events a snímky sys.dm_db_stats_properties. I když tyto tři možnosti zůstávají životaschopné (dokonce i v SQL Server 2014, ačkoli moje nejlepší doporučení je stále XE), další možností, kterou jsem si všiml při provádění některých testů v nedávné době, je SQL Sentry Plan Explorer.
Mnoho z vás používá Průzkumníka plánů pouze pro čtení plánů, což je skvělé. Má četné výhody oproti Management Studio, pokud jde o kontrolu plánů – od maličkostí, jako je schopnost třídit podle nejlepších operátorů a snadno vidět problémy s odhadem mohutnosti, až po větší výhody, jako je zpracování složitých a velkých plánů a možnost vybrat si jeden. výpis v dávce pro snazší kontrolu plánu. Ale za vizuálními prvky, které usnadňují rozbor plánů, nabízí Průzkumník plánů také možnost provést dotaz a zobrazit skutečný plán (spíše než jej spouštět v Management Studio a ukládat jej). A navíc, když plán spustíte z PE, jsou zde zachyceny další informace, které mohou být užitečné.
Začněme ukázkou, kterou jsem použil ve svém nedávném příspěvku Jak mohou automatické aktualizace statistiky ovlivnit výkon dotazů. Začal jsem s databází AdventureWorks2012 a vytvořil jsem kopii tabulky SalesOrderHeader s více než 200 miliony řádků. Tabulka má seskupený index na SalesOrderID a neclusterovaný index na CustomerID, OrderDate, SubTotal. [Znovu:pokud budete provádět opakované testy, udělejte si v tuto chvíli zálohu této databáze, abyste si ušetřili čas.] Nejprve jsem ověřil aktuální počet řádků v tabulce a počet řádků, které je třeba změnit pro vyvolání automatické aktualizace:
SELECT OBJECT_NAME([p].[object_id]) [TableName], [si].[name] [IndexName], [au].[type_desc] [Type], [p].[rows] [RowCount], ([p].[rows]*.20) + 500 [UpdateThreshold], [au].total_pages [PageCount], (([au].[total_pages]*8)/1024)/1024 [TotalGB] FROM [sys].[partitions] [p] JOIN [sys].[allocation_units] [au] ON [p].[partition_id] = [au].[container_id] JOIN [sys].[indexes] [si] on [p].[object_id] = [si].object_id and [p].[index_id] = [si].[index_id] WHERE [p].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Big_SalesOrderHeader Informace CIX a NCI
Také jsem ověřil aktuální záhlaví statistiky pro index:
DBCC SHOW_STATISTICS ('Sales.Big_SalesOrderHeader',[IX_Big_SalesOrderHeader_CustomerID_OrderDate_SubTotal]);

Statistiky NCI:Na začátku
Uložená procedura, kterou používám k testování, již byla vytvořena, ale pro úplnost je kód uveden níže:
CREATE PROCEDURE Sales.usp_GetCustomerStats
@CustomerID INT,
@StartDate DATETIME,
@EndDate DATETIME
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate), COUNT([SalesOrderID]) as Computed
FROM [Sales].[Big_SalesOrderHeader]
WHERE CustomerID = @CustomerID
AND OrderDate BETWEEN @StartDate and @EndDate
GROUP BY CustomerID, DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate)
ORDER BY DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate);
END Dříve jsem buď spustil relaci Trace nebo Extended Events, nebo jsem nastavil svou metodu k zachycení sys.dm_db_stats_properties do tabulky. Pro tento příklad jsem jen několikrát spustil výše uvedenou uloženou proceduru:
EXEC Sales.usp_GetCustomerStats 11331, '2012-08-01 00:00:00.000', '2012-08-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11330, '2013-01-01 00:00:00.000', '2013-01-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11506, '2012-11-01 00:00:00.000', '2012-11-30 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 17061, '2013-01-01 00:00:00.000', '2013-01-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11711, '2013-03-01 00:00:00.000', '2013-03-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 15131, '2013-02-01 00:00:00.000', '2013-02-28 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 29837, '2012-10-01 00:00:00.000', '2012-10-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 15750, '2013-03-01 00:00:00.000', '2013-03-31 23:59:59.997' GO
Poté jsem zkontroloval mezipaměť procedur, abych ověřil počet provedení, a také ověřil plán, který byl uložen do mezipaměti:
SELECT OBJECT_NAME([st].[objectid]), [st].[text], [qs].[execution_count], [qs].[creation_time], [qs].[last_execution_time], [qs].[min_worker_time], [qs].[max_worker_time], [qs].[min_logical_reads], [qs].[max_logical_reads], [qs].[min_elapsed_time], [qs].[max_elapsed_time], [qp].[query_plan] FROM [sys].[dm_exec_query_stats] [qs] CROSS APPLY [sys].[dm_exec_sql_text]([qs].plan_handle) [st] CROSS APPLY [sys].[dm_exec_query_plan]([qs].plan_handle) [qp] WHERE [st].[text] LIKE '%usp_GetCustomerStats%' AND OBJECT_NAME([st].[objectid]) IS NOT NULL;

Informace o mezipaměti plánu pro SP:Na začátku
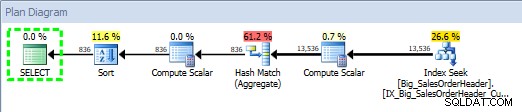
Plán dotazů pro uloženou proceduru pomocí Průzkumníka plánů SQL Sentry
Plán byl vytvořen 2014-09-29 23:23.01.
Dále jsem do tabulky přidal 61 milionů řádků, abych zneplatnil aktuální statistiku, a jakmile je vložení dokončeno, zkontroloval jsem počty řádků:

Big_SalesOrderHeader Informace CIX a NCI:Po vložení 61 milionů řádky
Před dalším spuštěním uložené procedury jsem ověřil, že se počet provedení nezměnil, že čas vytvoření byl pro plán stále 2014-09-29 23:23.01 a že se statistiky neaktualizovaly:
Plánovat informace o mezipaměti pro SP:Ihned po vložení

Statistika NCI:Po vložení
Nyní, v předchozím příspěvku na blogu, jsem spustil příkaz v Management Studio, ale tentokrát jsem spustil dotaz přímo z Plan Explorer a zachytil skutečný plán přes PE (možnost zakroužkovaná červeně na obrázku níže).
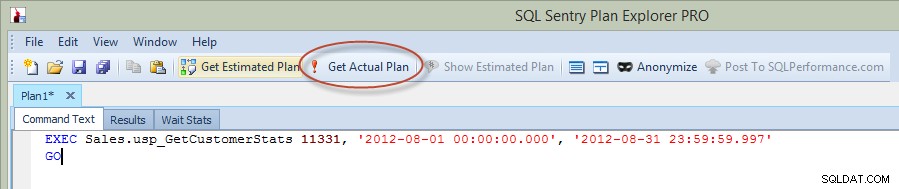
Spustit uloženou proceduru z Průzkumníka plánu
Když provedete příkaz z PE, musíte zadat instanci a databázi, ke které se chcete připojit, a poté budete upozorněni, že dotaz bude spuštěn a bude vrácen skutečný plán, ale nebudou vráceny výsledky. Všimněte si, že se liší od Management Studio, kde vidíte výsledky.
Poté, co jsem spustil uloženou proceduru, ve výstupu dostanu nejen plán, ale vidím, jaké příkazy byly provedeny:
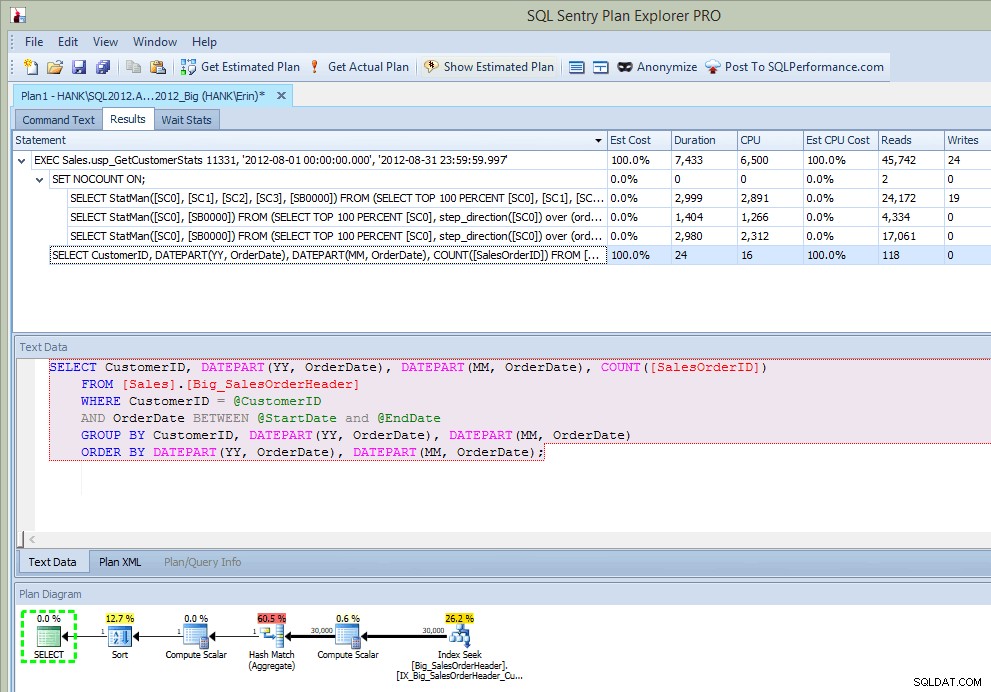
Plánovat výstup Průzkumníka po spuštění SP (po vložení)
To je docela fajn…kromě toho, že vidím provedený příkaz v uložené proceduře, vidím také aktualizace statistik, stejně jako když jsem zachytil aktualizace pomocí Extended Events nebo SQL Trace. Spolu s prováděním příkazu můžeme také vidět informace o CPU, trvání a IO. Nyní – upozorněním je, že tyto informace vidím pokud Spustím příkaz, který vyvolá aktualizaci statistik z Průzkumníka plánu. To se pravděpodobně ve vašem produkčním prostředí nestane často, ale můžete to vidět, když provádíte testování (protože doufejme, že vaše testování nezahrnuje pouze spouštění SELECT dotazů, ale také zahrnuje INSERT/UPDATE/DELETE dotazy stejně jako vy viz v běžné pracovní zátěži). Pokud však své prostředí monitorujete pomocí nástroje, jako je SQL Sentry, můžete tyto aktualizace vidět v Top SQL pokud překračují práh shromažďování Top SQL. SQL Sentry má výchozí prahové hodnoty, které musí dotazy překročit, než budou zachyceny jako Top SQL (např. doba trvání musí přesáhnout pět (5) sekund), ale můžete je změnit a přidat další prahové hodnoty, jako je čtení. V tomto příkladu pouze pro účely testování , Změnil jsem minimální práh trvání Top SQL na 10 milisekund a práh čtení na 500 a SQL Sentry dokázal zachytit některé aktualizace statistik:
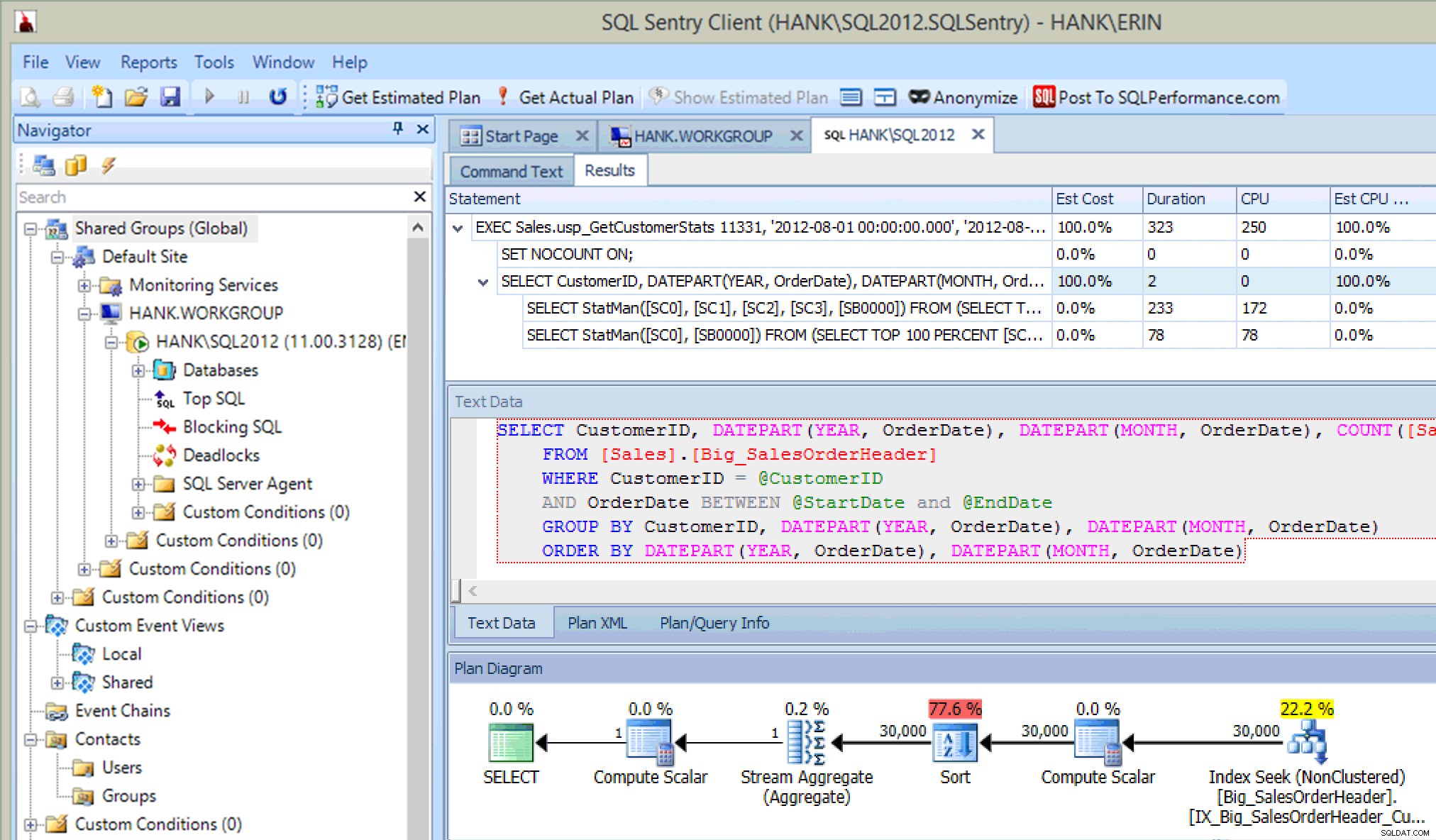
Aktualizace statistik zachycené službou SQL Sentry
To znamená, že to, zda monitorování dokáže zachytit tyto události, bude v konečném důsledku záviset na systémových prostředcích a množství dat, která je třeba načíst, aby se statistika aktualizovala. Aktualizace vašich statistik nesmí překročit tyto prahové hodnoty, takže je možná budete muset proaktivněji hledat.
Shrnutí
Vždy doporučuji správcům databází, aby proaktivně spravovali statistiky – což znamená, že je na místě pravidelně aktualizovat statistiky. I když však tato úloha běží každou noc (což nutně nedoporučuji), je stále docela možné, že aktualizace statistik probíhají automaticky během dne, protože některé tabulky jsou více volatilní než jiné a mají vysoký počet úprav. To není nic neobvyklého a v závislosti na velikosti tabulky a množství úprav nemusí automatické aktualizace výrazně zasahovat do uživatelských dotazů. Ale jediný způsob, jak to zjistit, je sledovat tyto aktualizace – ať už používáte nativní nástroje nebo nástroje třetích stran – abyste měli náskok před potenciálními problémy a řešili je dříve, než eskalují.