Zvažte následující dotaz AdventureWorks, který vrací ID transakcí tabulky historie pro produkt ID 421:
SELECT TH.TransactionID FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 421;
Optimalizátor dotazů rychle najde účinný plán provádění s odhadem mohutnosti (počet řádků), který je přesně správný, jak je znázorněno v Průzkumníku plánů SQL Sentry:

Nyní řekněme, že chceme najít ID transakcí historie pro produkt AdventureWorks s názvem "Metal Plate 2". Existuje mnoho způsobů, jak vyjádřit tento dotaz v T-SQL. Jedna přírodní formulace je:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Prováděcí plán je následující:
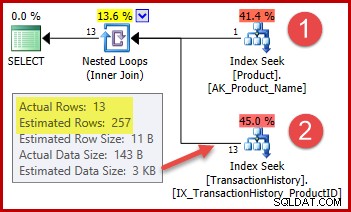
Strategie je:
- Vyhledejte ID produktu v tabulce Produkt ze zadaného názvu
- Vyhledejte řádky pro toto ID produktu v tabulce Historie
Odhadovaný počet řádků pro krok 1 je přesně správný, protože použitý index je deklarován jako jedinečný a je založen pouze na názvu produktu. Test rovnosti na "Metal Plate 2" tedy zaručeně vrátí přesně jeden řádek (nebo nula řádků, pokud zadáme název produktu, který neexistuje).
Zvýrazněný odhad 257 řádků pro krok 2 je méně přesný:ve skutečnosti je zjištěno pouze 13 řádků. Tato nesrovnalost vzniká, protože optimalizátor neví, které konkrétní ID produktu je spojeno s produktem s názvem „Kovová deska 2“. Hodnotu považuje za neznámou a generuje odhad mohutnosti pomocí informace o průměrné hustotě. Výpočet používá prvky ze statistického objektu zobrazeného níže:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH STAT_HEADER, DENSITY_VECTOR;
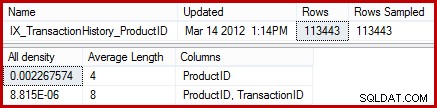
Statistiky ukazují, že tabulka obsahuje 113443 řádků se 441 jedinečnými ID produktů (1/0,002267574 =441). Za předpokladu, že distribuce řádků mezi ID produktů je rovnoměrná, odhad mohutnosti očekává, že ID produktu se bude shodovat (113443 / 441) =v průměru 257,24 řádků. Jak se ukazuje, distribuce není nijak zvlášť rovnoměrná; pro produkt "Metal Plate 2" je pouze 13 řádků.
Aside
Možná si říkáte, že odhad 257 řádků by měl být přesnější. Například vzhledem k tomu, že ID a názvy produktů jsou omezeny na to, aby byly jedinečné, může SQL Server automaticky udržovat informace o tomto vztahu jedna ku jedné. Poté by věděl, že „Kovová deska 2“ je spojen s produktem ID 479, a použije tento poznatek ke generování přesnějšího odhadu pomocí histogramu ProductID:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH HISTOGRAM;
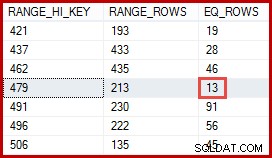
Odhad 13 řádků odvozených tímto způsobem by byl přesně správný. Nicméně odhad 257 řádků nebyl nepřiměřený vzhledem k dostupným statistickým informacím a běžným zjednodušujícím předpokladům (jako je rovnoměrné rozdělení), které dnes používá odhad mohutnosti. Přesné odhady jsou vždy hezké, ale "rozumné" odhady jsou také naprosto přijatelné.
Kombinace dvou dotazů
Řekněme, že nyní chceme vidět všechna ID historie transakcí, kde je ID produktu 421 NEBO název produktu je "Metal Plate 2". Přirozený způsob, jak spojit dva předchozí dotazy, je:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
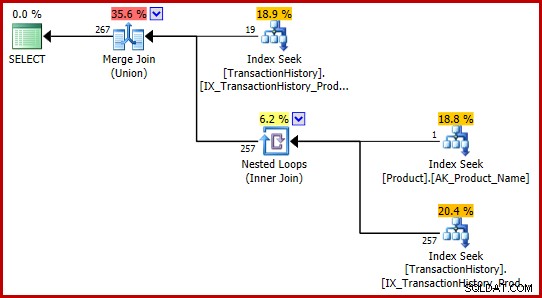
); Prováděcí plán je nyní trochu složitější, ale stále obsahuje rozpoznatelné prvky plánů s jedním predikátem:
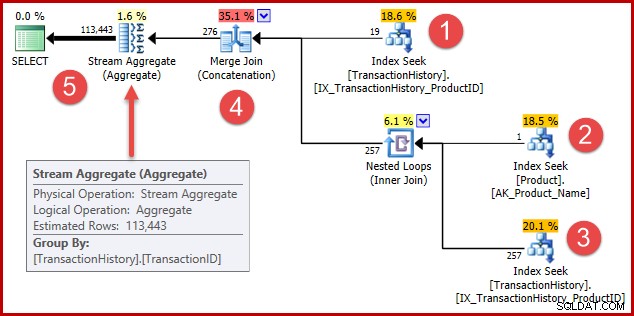
Strategie je:
- Najít záznamy historie pro produkt 421
- Vyhledejte ID produktu pro produkt s názvem "Metal Plate 2"
- Najděte záznamy historie pro ID produktu nalezené v kroku 2
- Zkombinujte řádky z kroků 1 a 3
- Odstraňte všechny duplikáty (protože produkt 421 může být také pojmenovaný "Kovová deska 2")
Kroky 1 až 3 jsou úplně stejné jako předtím. Ze stejných důvodů jsou vytvářeny stejné odhady. Krok 4 je nový, ale velmi jednoduchý:zřetězí očekávaných 19 řádků s očekávanými 257 řádky, čímž se získá odhad 276 řádků.
Krok 5 je zajímavý. Agregát streamů pro odstraňování duplikátů má odhadovaný vstup 276 řádků a odhadovaný výstup 113443 řádků. Agregát, který vydává více řádků, než přijímá, se zdá být nemožný, že?
* Pokud používáte model odhadu mohutnosti před rokem 2014, uvidíte zde odhad 102 099 řádků.
Chyba odhadu mohutnosti
Nemožný odhad Stream Aggregate v našem příkladu je způsoben chybou v odhadu mohutnosti. Je to zajímavý příklad, takže jej prozkoumáme trochu podrobněji.
Odstranění dílčího dotazu
Možná vás překvapí, že optimalizátor dotazů SQL Server nepracuje přímo s poddotazy. Jsou odstraněny ze stromu logických dotazů na začátku procesu kompilace a nahrazeny ekvivalentní konstrukcí, se kterou je optimalizátor nastaven tak, aby s ní pracoval a odůvodňoval ji. Optimalizátor má řadu pravidel, která odstraňují poddotazy. Ty mohou být uvedeny podle názvu pomocí následujícího dotazu (odkazovaný DMV je minimálně zdokumentován, ale není podporován):
SELECT name FROM sys.dm_exec_query_transformation_stats WHERE name LIKE 'RemoveSubq%';
Výsledky (na SQL Server 2014):
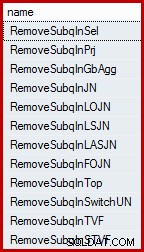
Kombinovaný testovací dotaz má dva predikáty ("výběry" v relačních termínech) v tabulce historie, spojené pomocí OR . Jeden z těchto predikátů obsahuje poddotaz. Celý podstrom (predikáty i poddotaz) se prvním pravidlem v seznamu ("odstranit poddotaz ve výběru") transformuje na semi-spojení nad sjednocením jednotlivých predikátů. I když není možné přesně znázornit výsledek této interní transformace pomocí syntaxe T-SQL, je to docela blízko:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
)
OPTION (QUERYRULEOFF ApplyUAtoUniSJ); Je trochu nešťastné, že moje T-SQL aproximace vnitřního stromu po odstranění poddotazu obsahuje poddotaz, ale v jazyce procesoru dotazu ne (jde o semi join). Pokud byste raději viděli nezpracovaný interní formulář namísto mého pokusu o ekvivalent T-SQL, buďte si jisti, že to bude za chvíli k dispozici.
Nedokumentovaná nápověda k dotazu obsažená ve výše uvedeném T-SQL má zabránit následné transformaci pro ty z vás, kteří chtějí vidět transformovanou logiku ve formě plánu provádění. Níže uvedené poznámky ukazují pozice dvou predikátů po transformaci:
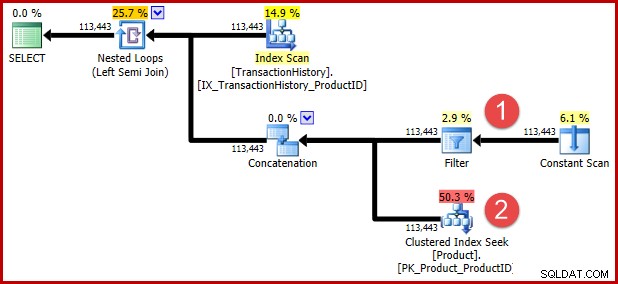
Intuice za transformací spočívá v tom, že řádek historie se kvalifikuje, pokud je splněn jeden z predikátů. Bez ohledu na to, jak užitečné považujete můj přibližný T-SQL a ilustraci plánu provádění, doufám, že je alespoň přiměřeně jasné, že přepsání vyjadřuje stejný požadavek jako původní dotaz.
Měl bych zdůraznit, že optimalizátor doslova negeneruje alternativní syntaxi T-SQL ani nevytváří kompletní plány provádění v mezistupních. Výše uvedené reprezentace T-SQL a prováděcího plánu jsou určeny pouze jako pomůcka pro porozumění. Pokud vás zajímají nezpracované podrobnosti, slíbená interní reprezentace transformovaného stromu dotazů (mírně upravená kvůli přehlednosti/prostoru) je:
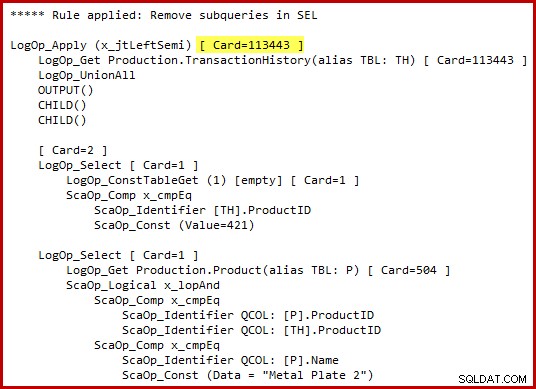
Všimněte si zvýrazněného odhadu mohutnosti použít semi spojení. Při použití odhadu mohutnosti z roku 2014 je to 113443 řádků (102099 řádků při použití starého CE). Mějte na paměti, že tabulka historie AdventureWorks obsahuje celkem 113443 řádků, takže to představuje 100% selektivitu (90% pro starý CE).
Již dříve jsme viděli, že použití jednoho z těchto predikátů samostatně vede pouze k malému počtu shod:19 řádků pro produkt s ID 421 a 13 řádků (odhadem 257) pro „Kovový plech 2“. Odhadujeme, že disjunkce (OR) z těchto dvou predikátů vrátí všechny řádky v základní tabulce se zdá být úplně šílené.
Podrobnosti o chybě
Podrobnosti o výpočtu selektivity pro semi spojení jsou viditelné pouze v SQL Server 2014 při použití nového estimátoru mohutnosti s (nedokumentovaným) příznakem trasování 2363. Pravděpodobně je možné vidět něco podobného u Extended Events, ale výstup příznaku trasování je pohodlnější. použít zde. Příslušná část výstupu je uvedena níže:
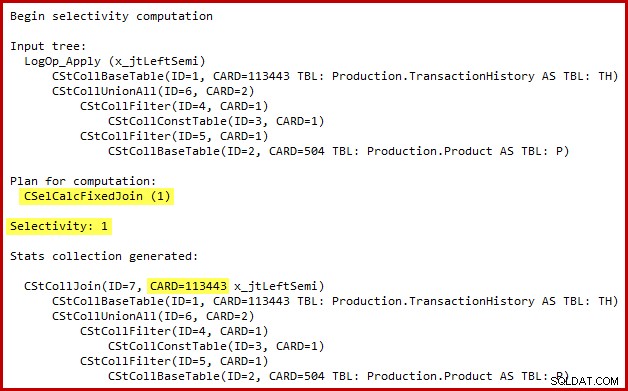
Odhad mohutnosti používá kalkulátor Fixed Join se 100% selektivitou. V důsledku toho je odhadovaná kardinalita výstupu semi spojení stejná jako jeho vstup, což znamená, že se očekává, že se kvalifikuje všech 113443 řádků z tabulky historie.
Přesná povaha chyby spočívá v tom, že při výpočtu selektivity semi spojení chybí jakékoli predikáty umístěné za sjednocením všech ve vstupním stromu. Na níže uvedeném obrázku nedostatek predikátů na samotném semi spojení znamená, že se kvalifikuje každý řádek; ignoruje účinek predikátů pod zřetězením (union all).
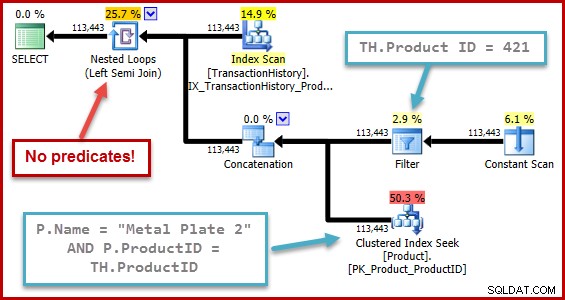
Toto chování je o to překvapivější, když uvážíte, že výpočet selektivity funguje na stromové reprezentaci, kterou optimalizátor vygeneroval sám (tvar stromu a umístění predikátů je výsledkem odstranění dílčího dotazu).
K podobnému problému dochází u odhadu mohutnosti před rokem 2014, ale konečný odhad je místo toho pevně stanoven na 90 % odhadovaného vstupu polospojení (ze zábavných důvodů souvisejících s inverzním pevným 10% predikátovým odhadem, který je příliš velkým odklonem k získání do).
Příklady
Jak bylo uvedeno výše, tato chyba se projevuje, když se provádí odhad pro semi spojení se souvisejícími predikáty umístěnými za sjednocením all. Zda k tomuto vnitřnímu uspořádání dojde během optimalizace dotazu, závisí na původní syntaxi T-SQL a přesné posloupnosti vnitřních optimalizačních operací. Následující příklady ukazují některé případy, kdy se chyba vyskytuje a nevyskytuje:
Příklad 1
Tento první příklad zahrnuje triviální změnu testovacího dotazu:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- The only change
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Odhadovaný plán provádění je:
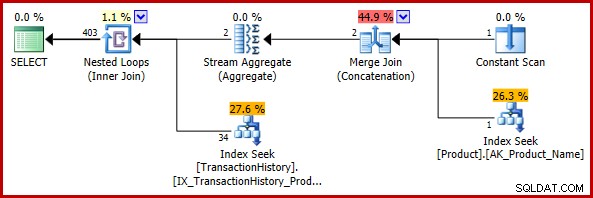
Konečný odhad 403 řádků je nekonzistentní se vstupními odhady spojení vnořených smyček, ale je stále rozumný (ve smyslu diskutovaném výše). Pokud by se chyba objevila, konečný odhad by byl 113443 řádků (nebo 102099 řádků při použití modelu před rokem 2014 CE).
Příklad 2
V případě, že jste se chystali uspěchat a přepsat všechna svá neustálá porovnávání jako triviální poddotazy, abyste se této chybě vyhnuli, podívejte se, co se stane, když provedeme další triviální změnu, tentokrát nahradíme test rovnosti ve druhém predikátu za IN. Význam dotazu zůstává nezměněn:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- Change 1
OR TH.ProductID IN -- Change 2
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Chyba se vrací:
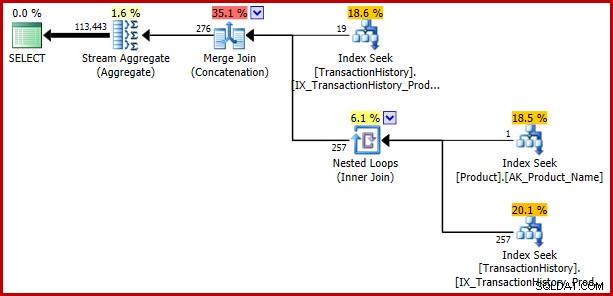
Příklad 3
Ačkoli se tento článek dosud soustředil na disjunktivní predikát obsahující poddotaz, následující příklad ukazuje, že stejná specifikace dotazu vyjádřená pomocí EXISTS a UNION ALL je také zranitelná:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
); Prováděcí plán:
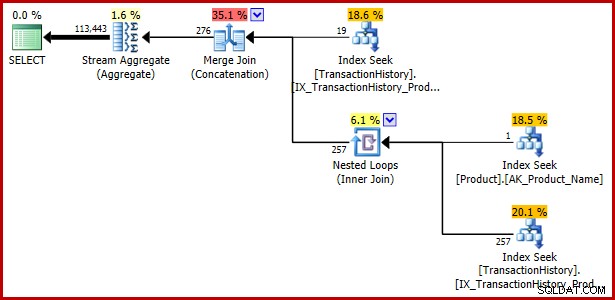
Příklad 4
Zde jsou další dva způsoby, jak vyjádřit stejný logický dotaz v T-SQL:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
);
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
JOIN Production.Product AS P
ON P.ProductID = TH.ProductID
AND P.Name = N'Metal Plate 2'; Žádný dotaz nenarazí na chybu a oba vytvářejí stejný plán provádění:
Tyto formulace T-SQL náhodou vytvářejí plán provádění se zcela konzistentními (a rozumnými) odhady.
Příklad 5
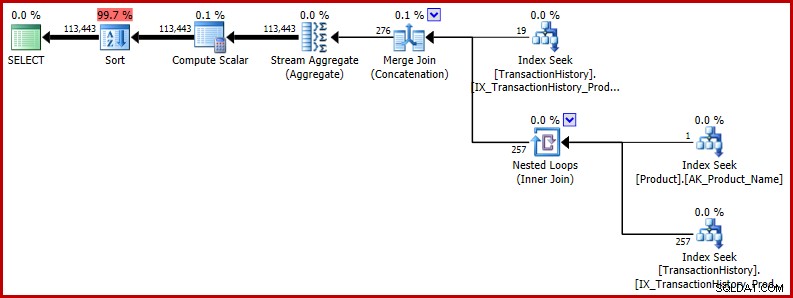
Možná se ptáte, zda je nepřesný odhad důležitý. V dosud prezentovaných případech tomu tak není, alespoň ne přímo. Problémy nastanou, když se chyba objeví ve větším dotazu a nesprávný odhad ovlivní rozhodnutí optimalizátoru jinde. Jako minimálně rozšířený příklad zvažte vrácení výsledků našeho testovacího dotazu v náhodném pořadí:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
)
ORDER BY NEWID(); -- New Prováděcí plán ukazuje, že nesprávný odhad ovlivňuje pozdější operace. Je to například základ pro přidělení paměti vyhrazené pro řazení:
Pokud byste chtěli vidět reálnější příklad potenciálního dopadu této chyby, podívejte se na tuto nedávnou otázku od Richarda Mansella na webu SQLPerformance.com Q &A, Answers.SQLPerformance.com.
Shrnutí a závěrečné myšlenky
Tato chyba se spustí, když optimalizátor za určitých okolností provede odhad mohutnosti pro semi spojení. Odhalit a obejít tuto chybu je náročné z mnoha důvodů:
- Neexistuje žádná explicitní syntaxe T-SQL, která by specifikovala semi spojení, takže je těžké předem zjistit, zda bude konkrétní dotaz touto chybou ohrožen.
- Optimalizátor může zavést poloviční spojení za nejrůznějších okolností, z nichž ne všechny jsou zřejmými kandidáty na poloviční spojení.
- Problematické semi spojení je často transformováno na něco jiného pozdější činností optimalizátoru, takže se ani nemůžeme spolehnout na to, že v konečném plánu realizace bude operace semi-spojení.
- Ne každý podivně vypadající odhad mohutnosti je způsoben touto chybou. Mnoho příkladů tohoto typu je skutečně očekávaným a neškodným vedlejším účinkem normální činnosti optimalizátoru.
- Chybný odhad selektivity semi spojení bude vždy 90 % nebo 100 % jeho vstupu, ale to obvykle nebude odpovídat mohutnosti tabulky použité v plánu. Navíc vstupní mohutnost semi-connect použitá ve výpočtu nemusí být viditelná ani v konečném plánu realizace.
- Zpravidla existuje mnoho způsobů, jak vyjádřit stejný logický dotaz v T-SQL. Některé z nich chybu spustí, jiné nikoli.
Díky těmto úvahám je obtížné nabídnout praktické rady, jak tuto chybu odhalit nebo obejít. Určitě stojí za to zkontrolovat plány provádění na "pobuřující" odhady a prošetřit dotazy s výkonem, který je mnohem horší, než se očekávalo, ale obojí může mít příčiny, které s touto chybou nesouvisí. To znamená, že stojí za to zkontrolovat zejména dotazy, které zahrnují disjunkci predikátů a poddotaz. Jak ukazují příklady v tomto článku, není to jediný způsob, jak se s chybou setkat, ale očekávám, že to bude běžná chyba.
Pokud máte to štěstí, že používáte SQL Server 2014 s povoleným novým estimátorem mohutnosti, můžete být schopni potvrdit chybu ruční kontrolou výstupu příznaku trasování 2363 pro pevný odhad 100% selektivity na semi spojení, ale toto je sotva pohodlné. Samozřejmě nebudete chtít používat nedokumentované příznaky trasování v produkčním systému.
Hlášení o chybě User Voice k tomuto problému naleznete zde. Chcete-li, aby byl tento problém prošetřen (a případně opraven), hlasujte a komentujte.