Tento článek je čtvrtou částí série o tabulkových výrazech. V části 1 a části 2 jsem se zabýval koncepčním zpracováním odvozených tabulek. V části 3 jsem se začal zabývat optimalizačními úvahami odvozených tabulek. Tento měsíc se věnuji dalším aspektům optimalizace odvozených tabulek; konkrétně se zaměřuji na substituci/rozpojování odvozených tabulek.
Ve svých příkladech použiji vzorové databáze nazvané TSQLV5 a PerformanceV5. Skript, který vytváří a naplňuje TSQLV5, najdete zde a jeho ER diagram zde. Skript, který vytváří a naplňuje PerformanceV5, najdete zde.
Zrušení vnoření/substituce
Rozpojení/substituce tabulkových výrazů je proces převzetí dotazu, který zahrnuje vnoření tabulkových výrazů a jako by jej nahradil dotazem, kde je vnořená logika eliminována. Měl bych zdůraznit, že v praxi neexistuje žádný skutečný proces, ve kterém SQL Server převede původní řetězec dotazu s vnořenou logikou na nový řetězec dotazu bez vnoření. Ve skutečnosti se stane, že proces analýzy dotazu vytvoří počáteční strom logických operátorů přesně odrážejících původní dotaz. Potom SQL Server použije transformace na tento strom dotazů, čímž eliminuje některé zbytečné kroky, sbalí více kroků do méně kroků a přesune operátory. Při svých transformacích, pokud jsou splněny určité podmínky, může SQL Server posouvat věci přes původní hranice tabulkových výrazů – někdy efektivně, jako by eliminoval vnořené jednotky. To vše ve snaze najít optimální plán.
V tomto článku se zabývám jak případy, kdy k takovému odhnízdění dochází, tak i inhibitory odhnízdění. To znamená, že když použijete určité prvky dotazu, zabrání to serveru SQL Server v tom, aby mohl přesouvat logické operátory ve stromu dotazů, což jej nutí zpracovat operátory na základě hranic tabulkových výrazů použitých v původním dotazu.
Začnu demonstrací jednoduchého příkladu, kde se odvozené tabulky rozloží. Uvedu také příklad pro neuhnízděný inhibitor. Poté budu hovořit o neobvyklých případech, kdy může být rozkládání nežádoucí, což vede buď k chybám, nebo ke snížení výkonu, a předvedu, jak v těchto případech rozkládání zabránit použitím inhibitoru rozpojení.
Následující dotaz (nazýváme ho Dotaz 1) používá několik vnořených vrstev odvozených tabulek, kde každý z tabulkových výrazů používá základní logiku filtrování založenou na konstantách:
SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180201' AS D3WHERE datum objednávky>='20180401';
Jak vidíte, každý z tabulkových výrazů filtruje rozsah dat objednávky počínaje jiným datem. SQL Server zruší vnoření této vícevrstvé logiky dotazování, což mu umožňuje sloučit čtyři predikáty filtrování do jednoho, který představuje průnik všech čtyř predikátů.
Prozkoumejte plán pro Dotaz 1 zobrazený na obrázku 1.
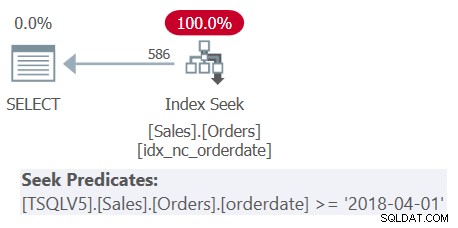 Obrázek 1:Plán pro dotaz 1
Obrázek 1:Plán pro dotaz 1
Všimněte si, že všechny čtyři filtrující predikáty byly sloučeny do jednoho predikátu představujícího průnik těchto čtyř. Plán použije vyhledávání v indexu idx_nc_orderdate na základě jediného sloučeného predikátu jako predikátu vyhledávání. Tento index je definován na orderdate (explicitně), orderid (implicitně kvůli přítomnosti seskupeného indexu na orderid) jako indexové klíče.
Všimněte si také, že i když všechny tabulkové výrazy používají SELECT * a pouze nejvzdálenější dotaz promítá dva zájmové sloupce:orderdate a orderid, výše uvedený index je považován za krycí. Jak jsem vysvětlil v části 3, pro účely optimalizace, jako je výběr indexu, SQL Server ignoruje sloupce z tabulkových výrazů, které nakonec nejsou relevantní. Pamatujte však, že k dotazování na tyto sloupce potřebujete oprávnění.
Jak již bylo zmíněno, SQL Server se pokusí zrušit vnoření tabulkových výrazů, ale vyhne se zrušení vnoření, pokud narazí na inhibitor zrušení vnoření. S určitou výjimkou, kterou popíšu později, použití TOP nebo OFFSET FETCH zabrání rozkládání. Důvodem je, že pokus o zrušení vnoření tabulkového výrazu pomocí TOP nebo OFFSET FETCH by mohl vést ke změně významu původního dotazu.
Jako příklad uvažujme následující dotaz (budeme ho nazývat Dotaz 2):
SELECT orderid, orderdateFROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854772036854772036854775807)'8 datum objednávky DHE1 AS010807'8 datum objednávky DHE110108007 ' ) AS D2 WHERE datum objednávky>='20180301' ) AS D3WHERE datum objednávky>='20180401';
Vstupní počet řádků do TOP filtru je hodnota typu BIGINT. V tomto příkladu používám maximální hodnotu BIGINT (2^63 – 1, počítejte v T-SQL pomocí SELECT POWER(2., 63) – 1). I když vy i já víme, že naše tabulka Objednávky nikdy nebude mít tolik řádků, a proto je filtr TOP opravdu nesmyslný, SQL Server musí počítat s teoretickou možností, že filtr bude smysluplný. V důsledku toho SQL Server nezruší vnoření tabulkových výrazů v tomto dotazu. Plán pro Dotaz 2 je znázorněn na obrázku 2.
 Obrázek 2:Plán pro dotaz 2
Obrázek 2:Plán pro dotaz 2
Inhibitory unnesting zabránily SQL Serveru, aby mohl sloučit predikáty filtrování, což způsobilo, že tvar plánu se více podobal koncepčnímu dotazu. Je však zajímavé pozorovat, že SQL Server stále ignoroval sloupce, které nakonec nebyly relevantní pro nejvzdálenější dotaz, a proto byl schopen použít krycí index k datu objednávky, orderid.
Abychom ilustrovali, proč jsou TOP a OFFSET-FETCH inhibitory nesdružující se do vnoření, pojďme si vzít jednoduchou techniku predikátové pushdown optimalizace. Posunutí predikátu znamená, že optimalizátor posune predikát filtru do dřívějšího bodu ve srovnání s původním bodem, který se objevuje ve zpracování logického dotazu. Předpokládejme například, že máte dotaz s vnitřním spojením i filtrem WHERE založeným na sloupci z jedné ze stran spojení. Z hlediska zpracování logického dotazu se po spojení předpokládá vyhodnocení filtru WHERE. Optimalizátor však často posune predikát filtru na krok před spojením, protože spojení ponechává méně řádků pro práci, což obvykle vede k optimálnějšímu plánu. Pamatujte však, že takové transformace jsou povoleny pouze v případech, kdy je zachován význam původního dotazu v tom smyslu, že je zaručeno, že získáte správnou sadu výsledků.
Zvažte následující kód, který má vnější dotaz s filtrem WHERE proti odvozené tabulce, která je zase založena na tabulkovém výrazu s filtrem TOP:
SELECT orderid, orderdateFROM ( SELECT TOP (3) * FROM Sales.Orders ) AS DWHERE orderdate>='20180101';
Tento dotaz je samozřejmě nedeterministický kvůli absenci klauzule ORDER BY v tabulkovém výrazu. Když jsem to spustil, SQL Server náhodou přistoupil k prvním třem řádkům s daty objednávek dříve než v roce 2018, takže jako výstup jsem dostal prázdnou sadu:
ID objednávky datum objednávky----------- ----------(0 ovlivněných řádků)
Jak již bylo zmíněno, použití TOP v tabulkovém výrazu zabránilo zde vnoření/substituci tabulkového výrazu. Pokud by SQL Server zrušil vnoření tabulkového výrazu, výsledkem procesu nahrazení by byl ekvivalent následujícího dotazu:
SELECT TOP (3) orderid, orderdateFROM Sales.OrdersWHERE orderdate>='20180101';
Tento dotaz je také nedeterministický kvůli absenci klauzule ORDER BY, ale zjevně má jiný význam než původní dotaz. Pokud tabulka Sales.Orders obsahuje alespoň tři objednávky zadané v roce 2018 nebo později – a má – tento dotaz nutně vrátí tři řádky, na rozdíl od původního dotazu. Zde je výsledek, který jsem dostal, když jsem spustil tento dotaz:
ID objednávky datum objednávky----------- ----------10400 2018-01-0110401 2018-01-0110402 2018-01-02 (dotčené 3 řádky)
V případě, že vás nedeterministická povaha dvou výše uvedených dotazů mate, zde je příklad s deterministickým dotazem:
SELECT orderid, orderdateFROM ( SELECT TOP (3) * FROM Sales.Orders ORDER BY orderid ) AS DWHERE orderdate>='20170708'ORDER BY orderid;
Tabulkový výraz filtruje tři objednávky s nejnižšími ID řádu. Vnější dotaz pak filtruje z těchto tří objednávek pouze ty, které byly zadány 8. července 2017 nebo později. Ukázalo se, že existuje pouze jedna oprávněná objednávka. Tento dotaz generuje následující výstup:
ID objednávky datum objednávky----------- ----------10250 2017-07-08 (dotčen 1 řádek)
Předpokládejme, že SQL Server zrušil vnoření tabulkového výrazu v původním dotazu, přičemž proces nahrazení vedl k následujícímu ekvivalentu dotazu:
SELECT TOP (3) orderid, orderdateFROM Sales.OrdersWHERE orderdate>='20170708'ORDER BY orderid;
Význam tohoto dotazu je jiný než původní dotaz. Tento dotaz nejprve filtruje objednávky, které byly zadány 8. července 2017 nebo později, a poté filtruje první tři mezi těmi s nejnižšími ID objednávek. Tento dotaz generuje následující výstup:
ID objednávky datum objednávky----------- ----------10250 2017-07-0810251 2017-07-0810252 2017-07-09 (dotčené 3 řádky)
Aby nedošlo ke změně významu původního dotazu, SQL Server zde nepoužije zrušení vnoření/substituci.
Poslední dva příklady zahrnovaly jednoduchou kombinaci filtrování WHERE a TOP, ale mohly se objevit další konfliktní prvky vyplývající z rozkládání. Co když například máte různé specifikace řazení ve výrazu tabulky a ve vnějším dotazu, jako v následujícím příkladu:
SELECT orderid, orderdateFROM ( SELECT TOP (3) * FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC ) AS DORDER BY orderid;
Uvědomíte si, že pokud SQL Server zruší vnoření tabulkového výrazu a sbalí dvě různé specifikace řazení do jedné, výsledný dotaz by měl jiný význam než původní dotaz. Buď by filtroval nesprávné řádky, nebo by zobrazil řádky výsledků ve špatném pořadí prezentace. Stručně řečeno, uvědomujete si, proč je pro SQL Server bezpečné vyhnout se zrušení vnoření/záměně tabulkových výrazů, které jsou založeny na dotazech TOP a OFFSET-FETCH.
Již dříve jsem zmínil, že existuje výjimka z pravidla, že použití TOP a OFFSET-FETCH zabraňuje rozkládání. To je, když použijete TOP (100) PERCENT ve výrazu vnořené tabulky, s nebo bez klauzule ORDER BY. SQL Server si uvědomuje, že neprobíhá žádné skutečné filtrování, a optimalizuje možnost. Zde je příklad, který to demonstruje:
SELECT orderid, orderdateFROM ( SELECT TOP (100) PRORCENT * FROM ( SELECT TOP (100) PRORCENT * FROM) ( SELECT TOP (100) PERCENT * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate> ='20180201' ) AS D2 WHERE datum objednávky>='20180301' ) AS D3WHERE datum objednávky>='20180401';
Filtr TOP je ignorován, dojde k rozpojení a získáte stejný plán jako ten, který byl zobrazen dříve pro Dotaz 1 na obrázku 1.
Při použití OFFSET 0 ROWS bez klauzule FETCH ve výrazu vnořené tabulky také neprobíhá žádné skutečné filtrování. Teoreticky tedy mohl SQL Server optimalizovat i tuto možnost a povolit zrušení vnoření, ale v době psaní tohoto článku tomu tak není. Zde je příklad, který to demonstruje:
SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D1 WHERE orderdate>='20180201' ORDER (SELECT NULL) OFFSET 0 ŘÁDKŮ ) AS D2 WHERE datum objednávky>='20180301' ORDER BY (SELECT NULL) OFFSET 0 ŘÁDKŮ ) JAKO D3WHERE datum objednávky>='20180401';
Získáte stejný plán jako ten, který byl zobrazen dříve pro Dotaz 2 na obrázku 2, což ukazuje, že nedošlo k žádnému odstranění hnízd.
Již dříve jsem vysvětlil, že proces zrušení vnoření/substituce ve skutečnosti negeneruje nový řetězec dotazu, který se následně optimalizuje, ale má co do činění s transformacemi, které SQL Server aplikuje na strom logických operátorů. Existuje rozdíl mezi způsobem, jakým SQL Server optimalizuje dotaz s vnořenými tabulkovými výrazy, a skutečným logicky ekvivalentním dotazem bez vnoření. Použití tabulkových výrazů, jako jsou odvozené tabulky, a také poddotazů brání jednoduché parametrizaci. Připomeňte si dotaz 1 uvedený dříve v článku:
SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180201' AS D3WHERE datum objednávky>='20180401';
Protože dotaz používá odvozené tabulky, neprobíhá jednoduchá parametrizace. To znamená, že SQL Server nenahrazuje konstanty parametry a poté optimalizuje dotaz, spíše optimalizuje dotaz pomocí konstant. S predikáty založenými na konstantách může SQL Server sloučit protínající se období, což v našem případě vedlo k jedinému predikátu v plánu, jak je znázorněno dříve na obrázku 1.
Dále zvažte následující dotaz (budeme ho nazývat Dotaz 3), který je logickým ekvivalentem Dotazu 1, ale kde sami použijete zrušení vnoření:
SELECT orderid, orderdateFROM Sales.OrdersWHERE orderdate>='20180101' AND orderdate>='20180201' AND orderdate>='20180301' AND orderdate>='20180401';
Plán pro tento dotaz je znázorněn na obrázku 3.
 Obrázek 3:Plán pro dotaz 3
Obrázek 3:Plán pro dotaz 3
Tento plán je považován za bezpečný pro jednoduchou parametrizaci, takže konstanty jsou nahrazeny parametry a predikáty se tedy neslučují. Motivací pro parametrizaci je samozřejmě zvýšení pravděpodobnosti opětovného použití plánu při provádění podobných dotazů, které se liší pouze konstantami, které používají.
Jak již bylo zmíněno, použití odvozených tabulek v Dotazu 1 bránilo jednoduché parametrizaci. Podobně by použití poddotazů zabránilo jednoduché parametrizaci. Zde je například náš předchozí Dotaz 3 s nesmyslným predikátem založeným na dílčím dotazu přidaném do klauzule WHERE:
SELECT orderid, orderdateFROM Sales.OrdersWHERE orderdate>='20180101' AND orderdate>='20180201' AND orderdate>='20180301' AND orderdate>='20180401' AND (SELECT 42) =42;
Tentokrát neprobíhá jednoduchá parametrizace, což SQL Serveru umožňuje sloučit protínající se období reprezentované predikáty s konstantami, což vede ke stejnému plánu, jaký je znázorněn dříve na obrázku 1.
Pokud máte dotazy s tabulkovými výrazy, které používají konstanty, a je pro vás důležité, že SQL Server parametrizoval kód, a z jakéhokoli důvodu jej nemůžete parametrizovat sami, nezapomeňte, že máte možnost použít vynucenou parametrizaci s průvodcem plánem. Jako příklad následující kód vytvoří takového průvodce plánem pro dotaz 3:
DECLARE @stmt AS NVARCHAR(MAX), @params AS NVARCHAR(MAX); EXEC sys.sp_get_query_template @querytext =N'SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>=''20180101'' ) AS D1 WHERE orderdate>=''20180101'' )0201 AS D2 WHERE orderdate>=''20180301'' ) AS D3WHERE orderdate>=''20180401'';', @templatetext =@stmt OUTPUT, @parameters =@params OUTPUT; EXEC sys.sp_create_plan_guide @name =N'TG1', @stmt =@stmt, @type =N'TEMPLATE', @module_or_batch =NULL, @params =@params, @hints =N'OPTION(PARAMETERIZATION FORCED)';Po vytvoření průvodce plánem spusťte dotaz 3 znovu:
SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180201' AS D3WHERE datum objednávky>='20180401';Získáte stejný plán jako ten na obrázku 3 s parametrizovanými predikáty.
Až budete hotovi, spusťte následující kód, abyste průvodce plánem zrušili:
EXEC sys.sp_control_plan_guide @operation =N'DROP', @name =N'TG1';Prevence rozkládání
Pamatujte, že SQL Server zruší vnoření tabulkových výrazů z důvodů optimalizace. Cílem je zvýšit pravděpodobnost nalezení plánu s nižšími náklady ve srovnání s plánem bez rozkládání. To platí pro většinu transformačních pravidel aplikovaných optimalizátorem. Mohou však nastat některé neobvyklé případy, kdy byste chtěli zabránit vynoření. Může to být buď proto, aby se předešlo chybám (ano, v některých neobvyklých případech může rozpojení vést k chybám), nebo z důvodů výkonu vynutit určitý tvar plánu, podobně jako při použití jiných tipů pro výkon. Pamatujte, že máte jednoduchý způsob, jak zabránit rozkládání pomocí TOP s velmi velkým číslem.
Příklad, jak se vyhnout chybám
Začnu případem, kdy zrušení vnoření tabulkových výrazů může vést k chybám.
Zvažte následující dotaz (budeme ho nazývat Dotaz 4):
VYBERTE ID objednávky, id produktu, slevuFROM Sales.OrderDetailsWHERE sleva> (SELECT MIN(sleva) Z Sales.OrderDetails) A 1,0 / sleva> 10,0;Tento příklad je trochu vymyšlený v tom smyslu, že je snadné přepsat predikát druhého filtru, takže by to nikdy nevedlo k chybě (sleva <0,1), ale je to pro mě vhodný příklad pro ilustraci mého názoru. Slevy jsou nezáporné. Takže i když existují řádky objednávky s nulovou slevou, dotaz je má odfiltrovat (první predikát filtru říká, že sleva musí být větší než minimální sleva v tabulce). Neexistuje však žádná záruka, že SQL Server vyhodnotí predikáty v písemném pořadí, takže nemůžete počítat se zkratem.
Prozkoumejte plán pro Dotaz 4 zobrazený na obrázku 4.
Obrázek 4:Plán pro dotaz 4
Všimněte si, že v plánu je predikát 1,0 / sleva> 10,0 (druhý v klauzuli WHERE) vyhodnocen před predikátem sleva>
(první v klauzuli WHERE). Následně tento dotaz generuje chybu dělení nulou: Zpráva 8134, úroveň 16, stav 1Divide by zero zaznamenala chybu.Možná si myslíte, že se této chybě můžete vyhnout použitím odvozené tabulky, která oddělí úkoly filtrování na vnitřní a vnější, například takto:
VYBERTE ID objednávky, id produktu, slevuFROM ( SELECT * FROM Sales.OrderDetails WHERE sleva> (SELECT MIN(sleva) FROM Sales.OrderDetails) ) AS DWHERE 1.0 / sleva> 10.0;SQL Server však použije zrušení vnoření odvozené tabulky, což má za následek stejný plán znázorněný dříve na obrázku 4, a následně tento kód také selže s chybou dělení nulou:
Zpráva 8134, úroveň 16, stav 1Divide by zero zaznamenala chybu.Jednoduchou opravou je zavedení inhibitoru unnesting, jako je takový (toto řešení budeme nazývat Dotaz 5):
VYBERTE ID objednávky, id produktu, slevuFROM ( SELECT TOP (9223372036854775807) * FROM Sales.OrderDetails WHERE sleva> (SELECT MIN(sleva) FROM Sales.OrderDetails) ) JAKO DWHERE 1.0 / sleva> 10.0;Plán pro Dotaz 5 je znázorněn na obrázku 5.
Obrázek 5:Plán pro dotaz 5
Nenechte se zmást tím, že výraz 1.0 / sleva se objevuje ve vnitřní části operátoru Nested Loops, jako by byl vyhodnocen jako první. Toto je pouze definice člena Expr1006. Vlastní vyhodnocení predikátu Expr1006> 10,0 aplikuje operátor Filter jako poslední krok v plánu poté, co byly dříve operátorem Nested Loops odfiltrovány řádky s minimální slevou. Toto řešení běží úspěšně bez chyb.
Příklad z důvodů výkonu
Budu pokračovat případem, kdy zrušení vnoření tabulkových výrazů může poškodit výkon.
Začněte spuštěním následujícího kódu pro přepnutí kontextu do databáze PerformanceV5 a povolení STATISTICS IO a TIME:
USE PerformanceV5; SET STATISTICS IO, TIME ON;Zvažte následující dotaz (budeme ho nazývat Dotaz 6):
SELECT shipperid, MAX(orderdate) AS maxodFROM dbo.OrdersGROUP BY shipperid;Optimalizátor identifikuje podpůrný krycí index s shipperid a orderdate jako hlavní klíče. Vytvoří tedy plán s uspořádaným skenováním indexu následovaným operátorem Stream Aggregate založeným na pořadí, jak je znázorněno v plánu pro Dotaz 6 na obrázku 6.
Obrázek 6:Plán pro dotaz 6
Tabulka Objednávky má 1 000 000 řádků a seskupovací sloupec shipperid je velmi hustý – existuje pouze 5 různých ID odesílatelů, což má za následek 20% hustotu (průměrné procento na odlišnou hodnotu). Použití úplného skenování indexového listu zahrnuje přečtení několika tisíc stránek, což má za následek dobu běhu asi třetinu sekundy v mém systému. Zde jsou statistiky výkonu, které jsem získal pro provedení tohoto dotazu:
Čas CPU =344 ms, uplynulý čas =346 ms, logická čtení =3854Indexový strom má v současnosti tři úrovně.
Znásobme počet objednávek faktorem 1 000 až 1 000 000 000, ale stále pouze s 5 různými odesílateli. Počet stránek v indexovém listu by vzrostl o faktor 1 000 a indexový strom by pravděpodobně vedl k jedné úrovni navíc (do čtyř úrovní). Tento plán má lineární měřítko. Skončili byste s téměř 4 000 000 logickými čteními a dobou běhu několika minut.
Když potřebujete spočítat MIN nebo MAX agregaci proti velké tabulce s velmi vysokou hustotou ve sloupci seskupení (důležité!) a podpůrným indexem B-stromu zakódovaným ve sloupci seskupení a agregačním sloupci, existuje mnohem optimálnější tvar plánu než ten na obrázku 6. Představte si tvar plánu, který skenuje malou sadu ID odesílatelů z nějakého indexu v tabulce Odesílatelů a ve smyčce aplikuje pro každého odesílatele hledání proti podpůrnému indexu na Objednávkách, aby získal souhrn. Při 1 000 000 řádcích v tabulce by 5 hledání znamenalo 15 čtení. Při 1 000 000 000 řádcích by 5 hledání znamenalo 20 čtení. S trilionem řádků, celkem 25 čtení. Jednoznačně mnohem optimálnější plán. Takový plán můžete ve skutečnosti dosáhnout dotazem na tabulku Odesílatelů a získáním souhrnu pomocí skalárního agregačního dílčího dotazu na Objednávky, jako je tento (toto řešení budeme nazývat Dotaz 7):
SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxodFROM dbo.Shippers AS S;Plán pro tento dotaz je znázorněn na obrázku 7.
Obrázek 7:Plán pro dotaz 7
Požadovaný tvar plánu je dosažen a čísla výkonu pro provedení tohoto dotazu jsou podle očekávání zanedbatelná:
Čas CPU =0 ms, uplynulý čas =0 ms, logické čtení =15Dokud je sloupec seskupení velmi hustý, velikost tabulky Objednávky se stává prakticky bezvýznamnou.
Ale počkejte chvíli, než půjdete slavit. Existuje požadavek ponechat pouze odesílatele, jejichž maximální související datum objednávky v tabulce Objednávky je rok 2018 nebo později. Zní to jako dostatečně jednoduchý doplněk. Definujte odvozenou tabulku založenou na Dotazu 7 a aplikujte filtr ve vnějším dotazu, podobně (toto řešení budeme nazývat Dotaz 8):
SELECT shipperid, maxodFROM ( SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) AS DWHERE maxod>='20180101';Bohužel, SQL Server zruší vnoření odvozeného tabulkového dotazu i poddotazu a převede agregační logiku na ekvivalent logiky seskupeného dotazu s shipperid jako seskupovacím sloupcem. A způsob, jakým SQL Server zná optimalizaci seskupeného dotazu, je založen na jediném průchodu vstupními daty, což vede k plánu velmi podobnému plánu uvedenému dříve na obrázku 6, pouze s dodatečným filtrem. Plán pro Dotaz 8 je znázorněn na obrázku 8.
Obrázek 8:Plán pro dotaz 8
V důsledku toho je škálování lineární a čísla výkonu jsou podobná těm pro dotaz 6:
Čas CPU =328 ms, uplynulý čas =325 ms, logická čtení =3854Oprava spočívá v zavedení inhibitoru unnesting. Toho lze dosáhnout přidáním filtru TOP k tabulkovému výrazu, na kterém je odvozená tabulka založena, např. (toto řešení budeme nazývat Dotaz 9):
SELECT shipperid, maxodFROM ( SELECT TOP (9223372036854775807) S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S) DWHERE maxod>='20180101';Plán pro tento dotaz je znázorněn na obrázku 9 a má požadovaný tvar plánu s hledáním:
Obrázek 9:Plán pro dotaz 9
Výkonnostní čísla pro toto provedení jsou pak samozřejmě zanedbatelná:
Čas CPU =0 ms, uplynulý čas =0 ms, logické čtení =15Další možností je zabránit zrušení vnoření poddotazu nahrazením agregace MAX ekvivalentním filtrem TOP (1), jako je tento (toto řešení budeme nazývat Dotaz 10):
SELECT shipperid, maxodFROM ( SELECT S.shipperid, (SELECT TOP (1) O.orderdate FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid ORDER BY O.orderdate DESC) AS maxod FROM dbo.Shippers AS S ) AS DWHERE maxod>='20180101';Plán pro tento dotaz je znázorněn na obrázku 10 a opět má požadovaný tvar s prohledáváním.
Obrázek 10:Plán pro dotaz 10
Získal jsem známá zanedbatelná čísla výkonu pro toto provedení:
Čas CPU =0 ms, uplynulý čas =0 ms, logické čtení =15Až budete hotovi, spusťte následující kód, abyste přestali vykazovat statistiky výkonu:
SET STATISTICS IO, TIME OFF;Shrnutí
V tomto článku jsem pokračoval v diskusi, kterou jsem začal minulý měsíc o optimalizaci odvozených tabulek. Tento měsíc jsem se zaměřil na rozkládání odvozených tabulek. Vysvětlil jsem, že typicky vylučování vede k optimálnějšímu plánu ve srovnání s bez vylučování, ale také jsem uvedl příklady, kdy je to nežádoucí. Ukázal jsem příklad, kdy rozkládání vedlo k chybě, a také příklad vedoucí ke snížení výkonu. Ukázal jsem, jak zabránit vynořování pomocí aplikace inhibitoru vylučování, jako je TOP.
Příští měsíc budu pokračovat ve zkoumání pojmenovaných tabulkových výrazů a přesunu zaměření na CTE.