Tento článek je pátou částí série o tabulkových výrazech. V části 1 jsem poskytl pozadí tabulkových výrazů. V části 2, části 3 a části 4 jsem pokryl logické i optimalizační aspekty odvozených tabulek. Tento měsíc začínám pokrývat běžné tabulkové výrazy (CTE). Stejně jako u odvozených tabulek se nejprve budu věnovat logickému zacházení s CTE a v budoucnu se dostanu k úvahám o optimalizaci.
Ve svých příkladech použiji ukázkovou databázi nazvanou TSQLV5. Skript, který jej vytváří a naplňuje, najdete zde a jeho ER diagram zde.
CTE
Začněme termínem běžný tabulkový výraz . Tento termín ani jeho zkratka CTE se neobjevují ve specifikacích standardu ISO/IEC SQL. Mohlo se tedy stát, že tento termín pochází z jednoho z databázových produktů a později jej převzali někteří další prodejci databází. Najdete ho v dokumentaci k Microsoft SQL Server a Azure SQL Database. T-SQL jej podporuje počínaje SQL Server 2005. Standard používá termín výraz dotazu reprezentovat výraz, který definuje jeden nebo více CTE, včetně vnějšího dotazu. Používá výraz s prvkem seznamu reprezentovat to, co T-SQL nazývá CTE. Brzy poskytnu syntaxi výrazu dotazu.
Zdroj termínu stranou, běžný tabulkový výraz nebo CTE , je běžně používaný termín praktiky T-SQL pro strukturu, na kterou se zaměřuje tento článek. Nejprve se tedy podívejme, zda je to vhodný termín. Již jsme došli k závěru, že výraz tabulkový výraz je vhodný pro výraz, který koncepčně vrací tabulku. Odvozené tabulky, CTE, pohledy a funkce s hodnotou vložené tabulky jsou všechny typy výrazů pojmenovaných tabulek které T-SQL podporuje. Tedy tabulkový výraz součástí běžného tabulkového výrazu určitě se zdá vhodné. Pokud jde o běžné součástí termínu to pravděpodobně souvisí s jednou z konstrukčních výhod CTE oproti odvozeným tabulkám. Pamatujte, že ve vnějším dotazu nemůžete znovu použít odvozený název tabulky (nebo přesněji název proměnné rozsahu) více než jednou. Naopak název CTE lze ve vnějším dotazu použít vícekrát. Jinými slovy, název CTE je běžný na vnější dotaz. Tento designový aspekt samozřejmě předvedu v tomto článku.
CTE vám poskytují podobné výhody jako odvozené tabulky, včetně umožnění vývoje modulárních řešení, opětovného použití aliasů sloupců, nepřímé interakce s funkcemi oken v klauzulích, které je běžně neumožňují, podpory úprav, které nepřímo spoléhají na TOP nebo OFFSET FETCH se specifikací objednávky, a další. Ve srovnání s odvozenými tabulkami však existují určité konstrukční výhody, kterým se budu podrobně věnovat poté, co poskytnu syntaxi struktury.
Syntaxe
Zde je standardní syntaxe pro výraz dotazu:
7.17
Funkce
Určete tabulku.
Formát
[ ]
[
::=S [ REKURZIVNÍ ]
[ { <čárka> }… ]
::=
AS
|
[
|
[
|
[
|
[
ODPOVÍDAJÍCÍ [ BY
NAČÍST { FIRST | NEXT } [
|
7.18
Funkce
Určete generování informací o řazení a detekci cyklu ve výsledku rekurzivních dotazových výrazů.
Formát
HLEDAT
DEPTH FIRST BY
CYCLE
VÝCHOZÍ
7.3
Funkce
Určete sadu
Standardní výraz výraz dotazu představuje výraz obsahující klauzuli WITH, se seznamem , který se skládá z jednoho nebo více prvků seznamu a vnější dotaz. T-SQL odkazuje na standardní se seznamovým prvkem jako CTE.
T-SQL nepodporuje všechny standardní prvky syntaxe. Nepodporuje například některé pokročilejší prvky rekurzivního dotazu, které vám umožňují ovládat směr vyhledávání a zpracovávat cykly ve struktuře grafu. Na rekurzivní dotazy se zaměřuje článek příští měsíc.
Zde je syntaxe T-SQL pro zjednodušený dotaz na CTE:
Zde je příklad jednoduchého dotazu na CTE zastupující zákazníky z USA:
Ve výpisu proti CTE najdete stejné tři části jako ve výpisu proti odvozené tabulce:
Co se na návrhu CTE ve srovnání s odvozenými tabulkami liší, je to, kde se v kódu tyto tři prvky nacházejí. U odvozených tabulek je vnitřní dotaz vnořen do klauzule FROM vnějšího dotazu a název tabulkového výrazu je přiřazen za samotný tabulkový výraz. Prvky se tak nějak prolínají. Naopak u CTE kód odděluje tři prvky:nejprve přiřadíte název tabulkového výrazu; za druhé zadáte tabulkový výraz – od začátku do konce bez přerušení; za třetí určíte vnější dotaz – od začátku do konce bez přerušení. Později v části „Úvahy o designu“ vysvětlím důsledky těchto rozdílů v designu.
Pár slov o CTE a použití středníku jako ukončovacího znaku příkazu. Bohužel na rozdíl od standardního SQL vás T-SQL nenutí ukončovat všechny příkazy středníkem. V T-SQL je však jen velmi málo případů, kdy bez terminátoru je kód nejednoznačný. V těchto případech je ukončení povinné. Jeden takový případ se týká skutečnosti, že klauzule WITH se používá pro více účelů. Jedním je definování CTE, druhým je definování nápovědy k tabulce pro dotaz a existuje několik dalších případů použití. Jako příklad je v následujícím příkazu použita klauzule WITH k vynucení úrovně serializovatelné izolace pomocí nápovědy k tabulce:
Potenciál nejednoznačnosti nastává, když máte před definicí CTE neukončený příkaz, v takovém případě analyzátor nemusí být schopen zjistit, zda klauzule WITH patří do prvního nebo druhého příkazu. Zde je příklad, který to demonstruje:
Zde parser nemůže určit, zda se má klauzule WITH použít k definování nápovědy k tabulce pro tabulku Customers v prvním příkazu, nebo ke spuštění definice CTE. Zobrazí se následující chyba:
Opravou je samozřejmě ukončení příkazu před definicí CTE, ale nejlepším postupem je skutečně ukončit všechny vaše příkazy:
Možná jste si všimli, že někteří lidé začínají své definice CTE středníkem, například takto:
Smyslem této praxe je snížit možnost budoucích chyb. Co když někdo později přidá neukončený příkaz přímo před vaši definici CTE do skriptu a neobtěžuje se kontrolou celého skriptu, ale pouze svého prohlášení? Středník těsně před klauzulí WITH se v podstatě stane jejich ukončovacím znakem. Praktičnost této praktiky jistě vidíte, ale je trochu nepřirozená. Co se doporučuje, i když je obtížnější dosáhnout, je vštípit organizaci správné programovací postupy, včetně ukončení všech příkazů.
Z hlediska pravidel syntaxe, která se vztahují na tabulkový výraz použitý jako vnitřní dotaz v definici CTE, jsou stejná jako ta, která se vztahují na tabulkový výraz použitý jako vnitřní dotaz v definici odvozené tabulky. Jsou to:
Podrobnosti naleznete v části „Tabulkový výraz je tabulka“ v části 2 této série.
Pokud provedete průzkum mezi zkušenými vývojáři T-SQL, zda dávají přednost použití odvozených tabulek nebo CTE, ne všichni se shodnou na tom, co je lepší. Přirozeně, různí lidé mají různé stylingové preference. Někdy používám odvozené tabulky a někdy CTE. Je dobré být schopen vědomě identifikovat konkrétní rozdíly v jazykovém designu mezi těmito dvěma nástroji a vybrat si na základě svých priorit v jakémkoli daném řešení. S časem a zkušenostmi děláte svá rozhodnutí intuitivněji.
Dále je důležité nezaměňovat používání tabulkových výrazů a dočasných tabulek, ale to je diskuse související s výkonem, které se budu věnovat v budoucím článku.
CTE mají možnosti rekurzivního dotazování a odvozené tabulky nikoli. Takže pokud se na ně potřebujete spolehnout, přirozeně byste zvolili CTE. Na rekurzivní dotazy se zaměřuje článek příští měsíc.
V části 2 jsem vysvětlil, že vnořování odvozených tabulek vnímám jako přidávání složitosti kódu, protože je obtížné dodržovat logiku. Uvedl jsem následující příklad, který uvádí roky objednávek, ve kterých zadalo objednávky více než 70 zákazníků:
CTE nepodporují vnořování. Takže když kontrolujete nebo řešíte řešení založené na CTE, neztratíte se ve vnořené logice. Namísto vnořování vytváříte modulárnější řešení definováním více CTE pod stejným příkazem WITH, oddělených čárkami. Každý z CTE je založen na dotazu, který je napsán od začátku do konce bez přerušení. Vidím to jako dobrou věc z hlediska srozumitelnosti kódu a udržovatelnosti.
Zde je řešení výše uvedeného úkolu pomocí CTE:
Řešení založené na CTE se mi líbí více. Ale znovu se zeptejte zkušených vývojářů, které z výše uvedených dvou řešení preferují, a všichni nebudou souhlasit. Někteří ve skutečnosti preferují vnořenou logiku a možnost vidět vše na jednom místě.
Jedna velmi jasná výhoda CTE oproti odvozeným tabulkám je, když potřebujete ve svém řešení pracovat s více instancemi stejného tabulkového výrazu. Pamatujte si následující příklad založený na odvozených tabulkách z části 2 v seriálu:
Toto řešení vrací roky objednávek, počty objednávek za rok a rozdíl mezi počty v aktuálním roce a v předchozím roce. Ano, pomocí funkce LAG byste to mohli udělat snadněji, ale já se zde nezaměřuji na nalezení nejlepšího způsobu, jak dosáhnout tohoto velmi specifického úkolu. Tento příklad používám k ilustraci určitých aspektů návrhu jazyka pojmenovaných tabulkových výrazů.
Problém s tímto řešením je, že nemůžete přiřadit název tabulkovému výrazu a znovu jej použít ve stejném kroku zpracování logického dotazu. Odvozenou tabulku pojmenujete podle samotného tabulkového výrazu v klauzuli FROM. Pokud definujete a pojmenujete odvozenou tabulku jako první vstup spojení, nemůžete také znovu použít tento název odvozené tabulky jako druhý vstup stejného spojení. Pokud potřebujete sami spojit dvě instance stejného tabulkového výrazu, u odvozených tabulek nemáte jinou možnost, než kód duplikovat. To jste udělali ve výše uvedeném příkladu. Naopak jméno CTE je přiřazeno jako první prvek kódu mezi výše uvedenými třemi (jméno CTE, vnitřní dotaz, vnější dotaz). Z hlediska zpracování logického dotazu je v době, kdy se dostanete k vnějšímu dotazu, název CTE již definován a dostupný. To znamená, že můžete pracovat s více instancemi názvu CTE ve vnějším dotazu, například takto:
Toto řešení má jasnou výhodu programovatelnosti oproti řešení založenému na odvozených tabulkách v tom, že nepotřebujete udržovat dvě kopie stejného tabulkového výrazu. Dalo by se o tom říci více z pohledu fyzického zpracování a porovnat to s použitím dočasných tabulek, ale učiním tak v budoucím článku, který se zaměří na výkon.
Jedna výhoda, kterou má kód založený na odvozených tabulkách ve srovnání s kódem založeným na CTE, souvisí s vlastností uzavření, kterou má mít tabulkový výraz. Pamatujte, že uzavírací vlastnost relačního výrazu říká, že jak vstupy, tak výstupy jsou vztahy, a že tedy relační výraz lze použít tam, kde se vztah očekává, jako vstup do dalšího relačního výrazu. Podobně tabulkový výraz vrací tabulku a měl by být dostupný jako vstupní tabulka pro jiný tabulkový výraz. To platí pro dotaz, který je založen na odvozených tabulkách – můžete jej použít tam, kde se očekává tabulka. Můžete například použít dotaz, který je založen na odvozených tabulkách jako vnitřní dotaz definice CTE, jako v následujícím příkladu:
Totéž však neplatí pro dotaz, který je založen na CTE. I když je koncepčně považován za tabulkový výraz, nemůžete jej použít jako vnitřní dotaz v odvozených definicích tabulek, poddotazech a samotných CTE. Například následující kód není platný v T-SQL:
Dobrou zprávou je, že můžete použít dotaz, který je založen na CTE, jako vnitřní dotaz v pohledech a funkcích s hodnotou vložených tabulek, kterým se budu věnovat v budoucích článcích.
Také si pamatujte, že vždy můžete definovat další CTE na základě posledního dotazu a poté nechat reagovat nejvzdálenější dotaz s tímto CTE:
Z hlediska řešení problémů, jak již bylo zmíněno, je pro mě obvykle jednodušší sledovat logiku kódu, který je založen na CTE, ve srovnání s kódem založeným na odvozených tabulkách. Řešení založená na odvozených tabulkách však mají výhodu v tom, že můžete zvýraznit jakoukoli úroveň vnoření a spustit ji nezávisle, jak ukazuje obrázek 1.
S CTE jsou věci složitější. Aby bylo možné spustit kód obsahující CTE, musí začínat klauzulí WITH, za níž následuje jeden nebo více pojmenovaných tabulkových výrazů v závorkách oddělených čárkami, po nichž následuje dotaz bez závorek bez předchozí čárky. Jste schopni zvýraznit a spustit jakýkoli z vnitřních dotazů, které jsou skutečně samostatné, stejně jako kód kompletního řešení; nelze však zvýraznit a úspěšně spustit žádnou jinou mezilehlou část řešení. Například obrázek 2 ukazuje neúspěšný pokus o spuštění kódu představujícího C2.
Takže u CTE se musíte uchýlit k poněkud nepohodlným prostředkům, abyste mohli vyřešit problém s mezikrokem řešení. Jedním z běžných řešení je například dočasné vložení dotazu SELECT * FROM your_cte přímo pod relevantní CTE. Poté zvýrazníte a spustíte kód včetně vloženého dotazu, a když budete hotovi, vložený dotaz odstraníte. Obrázek 3 ukazuje tuto techniku.
Problém je v tom, že kdykoli provedete změny v kódu – dokonce i dočasné drobné, jako jsou výše uvedené – existuje šance, že když se pokusíte vrátit zpět k původnímu kódu, zavedete novou chybu.
Další možností je stylovat kód trochu jinak, takže každá neprvní definice CTE začíná samostatným řádkem kódu, který vypadá takto:
Kdykoli pak budete chtít spustit přechodnou část kódu až k danému CTE, můžete tak učinit s minimálními změnami kódu. Pomocí řádkového komentáře okomentujete pouze ten jeden řádek kódu, který odpovídá danému CTE. Poté zvýrazníte a spustíte kód až k vnitřnímu dotazu tohoto CTE, který je nyní považován za nejvzdálenější, jak je znázorněno na obrázku 4.
Pokud s tímto stylem nejste spokojeni, máte další možnost. Můžete použít blokový komentář, který začíná těsně před čárkou před CTE zájmu a končí za otevřenou závorkou, jak je znázorněno na obrázku 5.
Záleží na osobních preferencích. Obvykle používám dočasně vloženou techniku dotazu SELECT *.
Ve srovnání se standardem existuje určité omezení v podpoře T-SQL pro konstruktory hodnot tabulek. Pokud nejste obeznámeni s konstrukcí, nezapomeňte se nejprve podívat na část 2 v sérii, kde ji podrobně popisuji. Zatímco T-SQL umožňuje definovat odvozenou tabulku na základě konstruktoru hodnot tabulky, neumožňuje definovat CTE na základě konstruktoru hodnot tabulky.
Zde je podporovaný příklad, který používá odvozenou tabulku:
Bohužel podobný kód, který používá CTE, není podporován:
Tento kód generuje následující chybu:
Existuje však několik řešení. Jedním z nich je použití dotazu proti odvozené tabulce, která je zase založena na konstruktoru hodnot tabulky jako vnitřní dotaz CTE, například takto:
Dalším je uchýlit se k technice, kterou lidé používali před zavedením tabulkových konstruktorů do T-SQL – pomocí řady dotazů FROMless oddělených operátory UNION ALL, například takto:
Všimněte si, že aliasy sloupců jsou přiřazeny hned za názvem CTE.
Obě metody jsou algebrizovány a optimalizovány stejně, takže použijte tu, která vám vyhovuje.
Nástroj, který ve svých řešeních používám poměrně často, je pomocná tabulka čísel. Jednou z možností je vytvořit tabulku skutečných čísel ve vaší databázi a naplnit ji sekvencí přiměřené velikosti. Dalším je vyvinout řešení, které vytváří posloupnost čísel za chodu. U druhé možnosti chcete, aby vstupy byly oddělovače požadovaného rozsahu (budeme je nazývat
Tento kód generuje následující výstup:
První CTE s názvem L0 je založen na konstruktoru hodnot tabulky se dvěma řádky. Skutečné hodnoty jsou tam nevýznamné; důležité je, že má dvě řady. Pak je tu sekvence pěti dalších CTE pojmenovaných L1 až L5, z nichž každý aplikuje křížové spojení mezi dvěma instancemi předchozího CTE. Následující kód vypočítá počet řádků potenciálně generovaných každým z CTE, kde @L je číslo úrovně CTE:
Zde jsou čísla, která získáte pro každý CTE:
Přechod na úroveň 5 vám poskytne více než čtyři miliardy řádků. To by mělo stačit pro jakýkoli případ praktického použití, který mě napadá. Další krok se odehrává v CTE zvaném Nums. Pomocí funkce ROW_NUMBER vygenerujete posloupnost celých čísel začínajících 1 na základě nedefinovaného pořadí (ORDER BY (SELECT NULL)) a pojmenujete výsledný sloupec rownum. Nakonec vnější dotaz používá TOP filtr založený na řazení rownum k filtrování tolika čísel, kolik je požadovaná mohutnost sekvence (@high – @low + 1), a vypočítá výsledné číslo n jako @low + rownum – 1.
Zde můžete skutečně ocenit krásu designu CTE a úspory, které umožňuje, když vytváříte řešení modulárním způsobem. Proces unnesting nakonec rozbalí 32 tabulek, z nichž každá se skládá ze dvou řádků založených na konstantách. To lze jasně vidět na prováděcím plánu pro tento kód, jak je znázorněno na obrázku 6 pomocí SentryOne Plan Explorer.
Každý operátor Constant Scan představuje tabulku konstant se dvěma řádky. Jde o to, že operátor Top je ten, kdo požaduje tyto řádky, a poté, co získá požadované číslo, zkratuje. Všimněte si 10 řádků naznačených nad šipkou vedoucí do horního operátoru.
Vím, že se tento článek zaměřuje na koncepční zpracování CTE a ne na úvahy o fyzickém/výkonovém stavu, ale když se podíváte na plán, můžete skutečně ocenit stručnost kódu ve srovnání s rozvláčností toho, co se překládá do zákulisí.
Pomocí odvozených tabulek můžete skutečně napsat řešení, které nahradí každý odkaz CTE základním dotazem, který představuje. To, co získáte, je docela děsivé:
Obviously, you don’t want to write a solution like this, but it’s a good way to illustrate what SQL Server does behind the scenes with your CTE code.
If you were really planning to write a solution based on derived tables, instead of using the above nested approach, you’d be better off simplifying the logic to a single query with 31 cross joins between 32 table value constructors, each based on two rows, like so:
Still, the solution based on CTEs is obviously significantly simpler. The plans are identical.
CTEs can be used as the source and target tables in INSERT, UPDATE, DELETE and MERGE statements. They cannot be used in the TRUNCATE statement.
The syntax is pretty straightforward. You start the statement as usual with a WITH clause, followed by one or more CTEs separated by commas. Then you specify the outer modification statement, which interacts with the CTEs that were defined under the WITH clause as the source tables, target table, or both. Just like I explained in Part 2 about derived tables, also with CTEs what really gets modified is the underlying base table that the table expression uses. I’ll show a couple of examples using DELETE and UPDATE statements, but remember that you can use CTEs in MERGE and INSERT statements as well.
Here’s the general syntax of a DELETE statement against a CTE:
As an example (don’t actually run it), the following code deletes the 10 oldest orders:
Here’s the general syntax of an UPDATE statement against a CTE:
As an example, the following code updates the 10 oldest unshipped orders that have an overdue required date, increasing the required date to 10 days from today:
The code applies the update in a transaction that it then rolls back so that the change won’t stick.
This code generates the following output, showing both the old and the new required dates:
Of course you will get a different new required date based on when you run this code.
I like CTEs. They have a few advantages compared to derived tables. Instead of nesting the code, you define multiple CTEs separated by commas, typically leading to a more modular solution that is easier to review and maintain. Also, you can have multiple references to the same CTE name in the outer statement, so you don’t need to repeat the inner table expression’s code. However, unlike derived tables, CTEs cannot be defined directly based on a table value constructor, and you cannot highlight and execute some of the intermediate parts of the code. The following table summarizes the differences between derived tables and CTEs:
As the last item says, derived tables do not support recursive capabilities, whereas CTEs do. Recursive queries are the focus of next month’s article.
Formát
HODNOTY
[ { <čárka> WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
SELECT < select list >
FROM < table name >;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
SELECT custid, country FROM Sales.Customers WITH (SERIALIZABLE);
SELECT custid, country FROM Sales.Customers
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC
Nesprávná syntaxe poblíž 'UC'. Pokud se má jednat o běžný tabulkový výraz, musíte předchozí příkaz explicitně ukončit středníkem. SELECT custid, country FROM Sales.Customers;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
;WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
Úvahy o návrhu
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70; WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70;
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM ( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS CUR
LEFT OUTER JOIN
( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH OrdCount AS
(
SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate)
)
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM OrdCount AS CUR
LEFT OUTER JOIN OrdCount AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH C AS
(
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C; SELECT orderyear, custid
FROM (WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70) AS D; WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
),
C3 AS
(
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C3;
 Obrázek 1:Může zvýraznit a spustit část kódu s odvozenými tabulkami
Obrázek 1:Může zvýraznit a spustit část kódu s odvozenými tabulkami  Obrázek 2:Nelze zvýraznit a spustit část kódu pomocí CTE
Obrázek 2:Nelze zvýraznit a spustit část kódu pomocí CTE  Obrázek 3:Vložení SELECT * pod relevantní CTE
Obrázek 3:Vložení SELECT * pod relevantní CTE , cte_name AS (
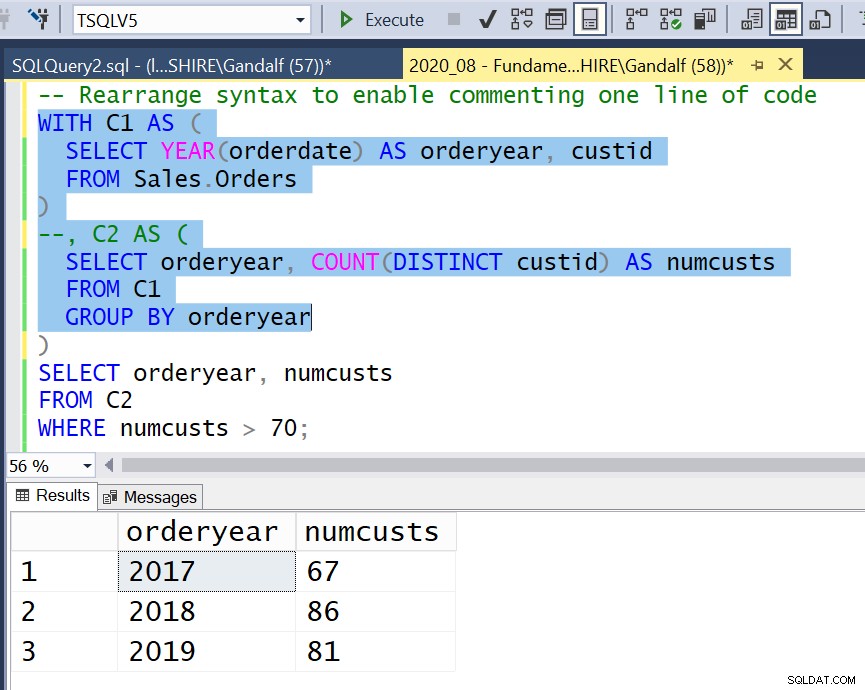 Obrázek 4:Změna uspořádání syntaxe, aby bylo možné komentovat jeden řádek kódu
Obrázek 4:Změna uspořádání syntaxe, aby bylo možné komentovat jeden řádek kódu  Obrázek 5:Použití blokového komentáře
Obrázek 5:Použití blokového komentáře Konstruktor hodnot tabulky
SELECT custid, companyname, contractdate
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate); WITH MyCusts(custid, companyname, contractdate) AS
(
VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' )
)
SELECT custid, companyname, contractdate
FROM MyCusts;
Nesprávná syntaxe poblíž klíčového slova 'VALUES'. WITH MyCusts AS
(
SELECT *
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate)
)
SELECT custid, companyname, contractdate
FROM MyCusts; WITH MyCusts(custid, companyname, contractdate) AS
(
SELECT 2, 'Cust 2', '20200212'
UNION ALL SELECT 3, 'Cust 3', '20200118'
UNION ALL SELECT 5, 'Cust 5', '20200401'
)
SELECT custid, companyname, contractdate
FROM MyCusts; Vytvoření posloupnosti čísel
@low a @high ). Chcete, aby vaše řešení podporovalo potenciálně velké rozsahy. Zde je mé řešení pro tento účel pomocí CTE s požadavkem na rozsah 1001 až 1010 v tomto konkrétním příkladu:DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; n
-----
1001
1002
1003
1004
1005
1006
1007
1008
1009
1010
DECLARE @L AS INT = 5;
SELECT POWER(2., POWER(2., @L));
CTE Kardinalita L0 2 L1 4 L2 16 L3 256 L4 65 536 L5 4 294 967 296  Obrázek 6:Plán sekvence čísel pro generování dotazu
Obrázek 6:Plán sekvence čísel pro generování dotazu DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D9
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D10 ) AS Nums
ORDER BY rownum; DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN (VALUES(1),(1)) AS D02(c)
CROSS JOIN (VALUES(1),(1)) AS D03(c)
CROSS JOIN (VALUES(1),(1)) AS D04(c)
CROSS JOIN (VALUES(1),(1)) AS D05(c)
CROSS JOIN (VALUES(1),(1)) AS D06(c)
CROSS JOIN (VALUES(1),(1)) AS D07(c)
CROSS JOIN (VALUES(1),(1)) AS D08(c)
CROSS JOIN (VALUES(1),(1)) AS D09(c)
CROSS JOIN (VALUES(1),(1)) AS D10(c)
CROSS JOIN (VALUES(1),(1)) AS D11(c)
CROSS JOIN (VALUES(1),(1)) AS D12(c)
CROSS JOIN (VALUES(1),(1)) AS D13(c)
CROSS JOIN (VALUES(1),(1)) AS D14(c)
CROSS JOIN (VALUES(1),(1)) AS D15(c)
CROSS JOIN (VALUES(1),(1)) AS D16(c)
CROSS JOIN (VALUES(1),(1)) AS D17(c)
CROSS JOIN (VALUES(1),(1)) AS D18(c)
CROSS JOIN (VALUES(1),(1)) AS D19(c)
CROSS JOIN (VALUES(1),(1)) AS D20(c)
CROSS JOIN (VALUES(1),(1)) AS D21(c)
CROSS JOIN (VALUES(1),(1)) AS D22(c)
CROSS JOIN (VALUES(1),(1)) AS D23(c)
CROSS JOIN (VALUES(1),(1)) AS D24(c)
CROSS JOIN (VALUES(1),(1)) AS D25(c)
CROSS JOIN (VALUES(1),(1)) AS D26(c)
CROSS JOIN (VALUES(1),(1)) AS D27(c)
CROSS JOIN (VALUES(1),(1)) AS D28(c)
CROSS JOIN (VALUES(1),(1)) AS D29(c)
CROSS JOIN (VALUES(1),(1)) AS D30(c)
CROSS JOIN (VALUES(1),(1)) AS D31(c)
CROSS JOIN (VALUES(1),(1)) AS D32(c) ) AS Nums
ORDER BY rownum; Used in modification statements
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
DELETE [ FROM ] <table name>
[ WHERE <filter predicate> ];
WITH OldestOrders AS
(
SELECT TOP (10) *
FROM Sales.Orders
ORDER BY orderdate, orderid
)
DELETE FROM OldestOrders;
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
UPDATE <table name>
SET <assignments>
[ WHERE <filter predicate> ];
BEGIN TRAN;
WITH OldestUnshippedOrders AS
(
SELECT TOP (10) orderid, requireddate,
DATEADD(day, 10, CAST(SYSDATETIME() AS DATE)) AS newrequireddate
FROM Sales.Orders
WHERE shippeddate IS NULL
AND requireddate < CAST(SYSDATETIME() AS DATE)
ORDER BY orderdate, orderid
)
UPDATE OldestUnshippedOrders
SET requireddate = newrequireddate
OUTPUT
inserted.orderid,
deleted.requireddate AS oldrequireddate,
inserted.requireddate AS newrequireddate;
ROLLBACK TRAN; orderid oldrequireddate newrequireddate
----------- --------------- ---------------
11008 2019-05-06 2020-07-16
11019 2019-05-11 2020-07-16
11039 2019-05-19 2020-07-16
11040 2019-05-20 2020-07-16
11045 2019-05-21 2020-07-16
11051 2019-05-25 2020-07-16
11054 2019-05-26 2020-07-16
11058 2019-05-27 2020-07-16
11059 2019-06-10 2020-07-16
11061 2019-06-11 2020-07-16
(10 rows affected)
Shrnutí
Item Derived table CTE Supports nesting Yes No Supports multiple references No Yes Supports table value constructor Yes No Can highlight and run part of code Yes No Supports recursion No Yes