Loni Andy Mallon blogoval o přenesení sloupce z int na bigint bez prostojů. (Proč to není operace pouze s metadaty v moderních verzích SQL Server je mimo mě, ale to je jiný příspěvek.)
Obvykle, když se zabýváme tímto problémem, jsou to široké a masivní tabulky (jak v počtu řádků, tak v samotné velikosti) a sloupec, který potřebujeme změnit, je jediný/hlavní sloupec v klíči shlukování. Obvykle jsou s tím spojeny i další komplikace – omezení příchozích cizích klíčů, spousta neklastrovaných indexů a zaneprázdněná databáze, která je extrémně citlivá na aktivitu protokolování (protože je zapojena do sledování změn, replikace, skupin dostupnosti nebo všech tří ).
Z tohoto důvodu musíme zaujmout přístup, jaký nastínil Andy, kde vytvoříme stínovou tabulku s novým schématem, vytvoříme spouštěče, aby byly obě kopie synchronizované, a pak dávkováme/zálohujeme vlastním tempem tohoto týmu, dokud nebudou připraveny k výměně. v kopii jako skutečný obchod.
Ale já jsem líný!
Existují některé případy, kdy můžete změnit sloupec přímo, pokud si můžete dovolit malé okno prostoje/blokování, a stane se to mnohem jednodušší operací. Minulý týden se objevil jeden takový případ s tabulkou přes 1 TB, ale pouze 100 tisíc řádků. Téměř všechna data byla mimo řádek (LOB), v případě potřeby si mohli dovolit malé časové prostoje a plánovali deaktivovat sledování změn a překonfigurovat je stejně. S jistotou, že opětovné vytvoření seskupeného PK by se nemuselo dotknout dat LOB (moc), navrhl jsem, že by to mohl být případ, kdy můžeme změnu použít přímo.
V izolovaném scénáři (žádné příchozí cizí klíče, žádné další indexy, žádné aktivity závislé na čtečce protokolů a žádné obavy ze souběžnosti) jsem dal dohromady několik testů, abych ve vakuu zjistil, co by tato změna vyžadovala z hlediska trvání. a dopad na protokol transakcí. Hlavní otázka, na kterou jsem předem nevěděl, jak odpovědět, byla:„Jaké jsou přírůstkové náklady na aktualizaci tabulek na místě, když existuje velké množství neklíčových dat?“
Pokusím se toho tady hodně zabalit do jednoho příspěvku. Hodně jsem testoval a všechno to nějak souvisí, i když ne všechny testovací scénáře se na vás vztahují. Prosím, mějte se mnou trpělivost.
Tabulky
Vytvořil jsem 6 tabulek, včetně základní linie, která pouze měl klíčový sloupec, jednu tabulku s 4K uloženou v řádku a pak čtyři tabulky, každou se sloupcem varchar(max) naplněným různým množstvím dat řetězce (4K, 16K, 64K a 256K).
CREATE TABLE dbo.withJustId( id int NOT NULL, CONSTRAINT pk_withJustId PRIMÁRNÍ KLÍČ V CLUSTERU (id)); CREATE TABLE dbo.withoutLob( id int NOT NULL, extradata varchar(4000) NOT NULL DEFAULT (REPLICATE('x', 4000)), CONSTRAINT pk_withoutLob PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob004( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE('x', 4000)), CONSTRAINT pk_withLob004 PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob016( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 16000)), CONSTRAINT pk_withLob016 PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob064 ( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 64000)), CONSTRAINT pk_withLob064 PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob256 ( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 256000)), CONSTRAINT pk_withLob256 PRIMARY KEY CLUSTERED (id));
Každý jsem naplnil 100 000 řádky:
INSERT dbo.withJustId (id) SELECT TOP (100000) id =ROW_NUMBER() OVER (ORDER BY c1.name) FROM sys.all_columns AS c1 CROSS JOIN sys.all_objects; INSERT dbo.withoutLob (id) SELECT id FROM dbo.withJustId;INSERT dbo.withLob004 (id) SELECT id FROM dbo.withJustId;INSERT dbo.withLob016 (id) SELECT id FROM dbo.withJustId;INSERT6 id FROM dbo.withJustId;INSERT dbo.withLob256 (id) SELECT id FROM dbo.withJustId;
Uznávám, že výše uvedené je nereálné; jak často máme tabulku, která je pouze identifikátorem + data LOB? Provedl jsem testy znovu s těmito dalšími čtyřmi sloupci, abych dal datovým stránkám, které nejsou LOB, trochu reálnější podstatu:
fill1 char(320) NOT NULL DEFAULT ('x'), count1 int NOT NULL DEFAULT (0), count2 int NOT NULL DEFAULT (0), dt datetime2 NOT NULL DEFAULT sysutcdatetime(),
Tyto tabulky jsou jen o něco větší, pokud jde o celkovou velikost, ale proporcionální nárůst v množství neLOB dat (v tomto grafu není znázorněn) je velký, ale skrytý rozdíl:
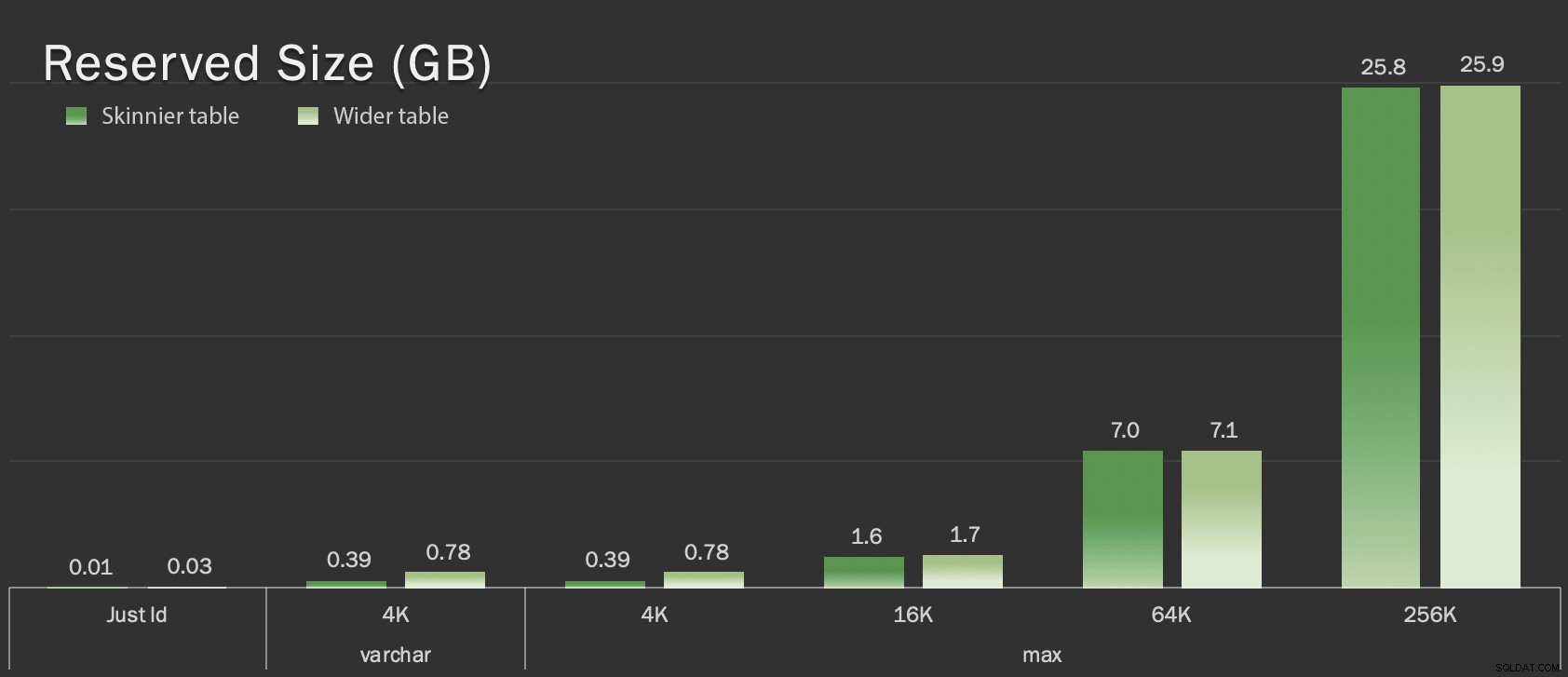 Rezervovaná velikost tabulek, v GB
Rezervovaná velikost tabulek, v GB
Testy
Poté jsem načasoval a shromáždil data protokolu pro každou z těchto operací (s a bez ONLINE = ON ) proti každé variantě tabulky:
ALTER TABLE dbo. DROP CONSTRAINT pk_; ALTER TABLE dbo. ALTER COLUMN id bigint NOT NULL; -- S (ONLINE =ZAPNUTO); ALTER TABLE dbo. PŘIDAT OMEZENÍ pk_ PRIMÁRNÍ KLÍČ SE SLUSTROVANÝ (id);
Ve skutečnosti jsem všechny tyto testy generoval pomocí dynamického SQL, takže jsem se před každým testem ručně nehrabal se skripty.
V dalším příspěvku se podělím o dynamický SQL, který jsem použil ke generování těchto testů, a shromáždím časování v každém kroku.
Pro srovnání jsem také testoval Andyho metodu (i když bez dávkování a pouze na skinny verzi tabulky):
CREATE TABLE dbo._copy ( id bigint NOT NULL -- <, sloupec extradata, pokud je to relevantní> OMEZENÍ pk_copy_ PRIMÁRNÍ KLÍČ SE SLUSTROVANÝM (id)); INSERT dbo._kopie SELECT * FROM dbo.; EXEC sys.sp_rename N'dbo.', N'dbo._old', N'OBJECT';EXEC sys.sp_rename N'dbo._copy', N'dbo.' , N'OBJECT';
Tady jsem přeskočil širší stoly; Nechtěl jsem zavádět složitost kódování a měření dávkových operací. Zjevnou bolestí je, že na rozdíl od změny sloupce na místě musíte pomocí metody stínu zkopírovat každý jednotlivý bajt těchto dat LOB. Dávkování může minimalizovat velký dopad pokusu o to v jediné transakci, ale celé to míchání bude nakonec muset být přepracováno po proudu. Dávkování u zdroje nemůže zcela ovlivnit, jak moc to bude bolet v cíli.
Výsledky
První výsledky, které ukážu, jsou pouze průměrné doby trvání pro změny na místě, pro všech 12 konfigurací tabulek a s a bez ONLINE = ON :
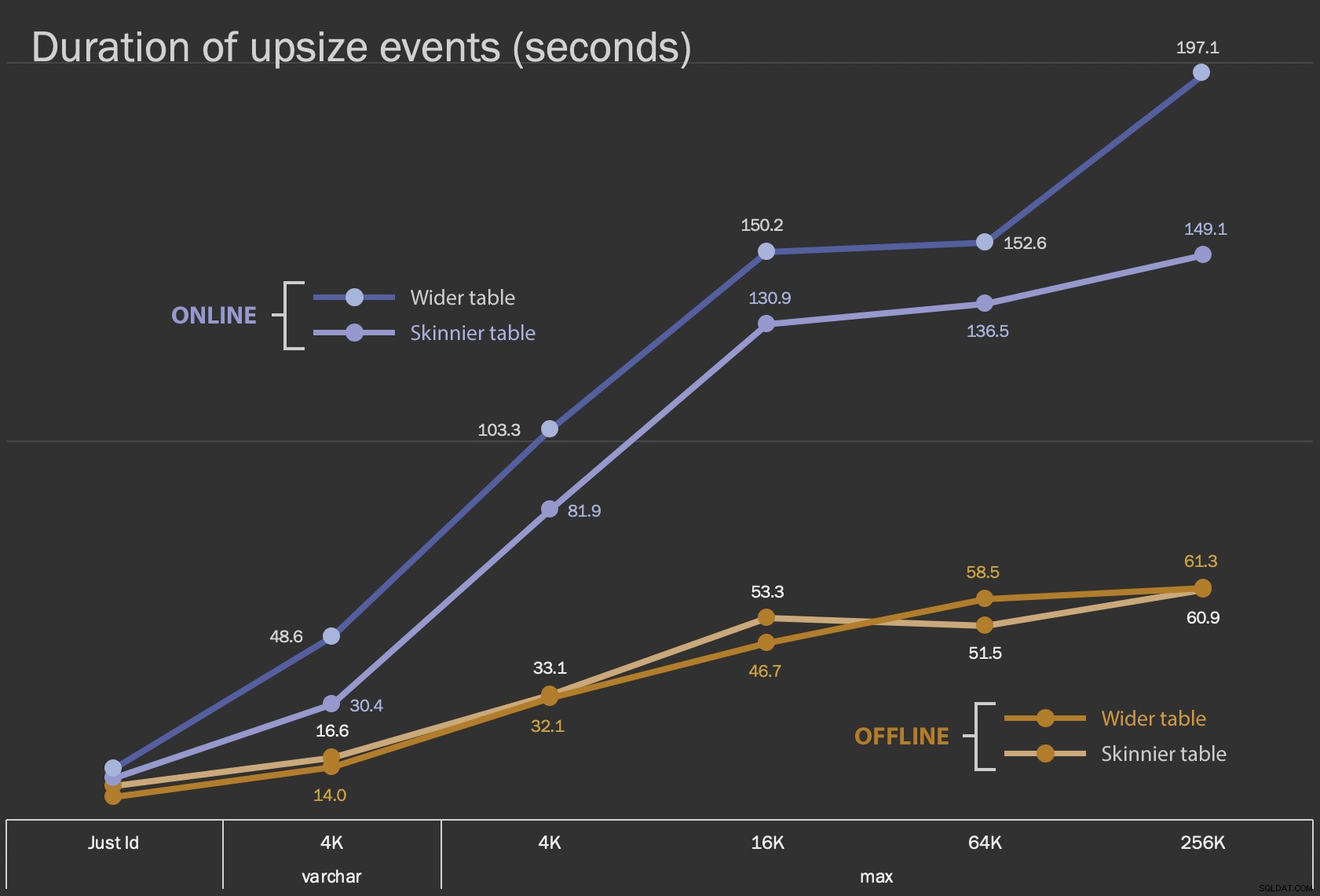 Doba trvání změny sloupce na místě v sekundách
Doba trvání změny sloupce na místě v sekundách
Provedení této operace jako online operace trvá déle (v nejhorším případě 200 sekund), ale neblokuje uživatele. Zdá se, že se zvětšuje spolu s velikostí, ale ne zcela lineárně. Provedení této operace offline způsobí zablokování, ale je mnohem rychlejší a nemění se tak drasticky, jak se tabulka zvětšuje (i při největší velikosti se to stále stalo asi za minutu).
Porovnání těchto operací na místě s operací swap and drop je obtížné pomocí spojnicového grafu kvůli obrovskému rozdílu v měřítku. Místo toho ukážu vodorovný pruhový graf pro dobu trvání každé konfigurace tabulky. Když je opětovné vytvoření rychlejší, vybarvím pozadí toho řádku zeleně; když je pomalejší (nebo spadá mezi offline a online metody), pravděpodobně to nepotřebuji, ale vybarvím pozadí toho řádku červeně.
| Velikost LOB | Přístup | Konfigurace tabulky | Trvání (v sekundách) | ||
|---|---|---|---|
| Jen ID | ALTER Offline | Skinnier table (10 MB) | 8.8 |
| Širší tabulka (30 MB) | 6.3 | ||
| ALTER Online | Šihlejší stůl | 11.0 | |
| Širší tabulka | 13.6 | ||
| Znovu vytvořit | Šihlejší stůl | 3.4 | |
| varchar 4K | Offline | Skinnier table (390 MB) | 16.6 |
| Širší tabulka (780 MB) | 14.0 | ||
| Online | Šihlejší stůl | 30.4 | |
| Širší tabulka | 48,6 | ||
| Znovu vytvořit | Šihlejší stůl | 1 290,0 | |
| max 4k | Offline | Skinnier table (390 MB) | 33.1 |
| Širší tabulka (780 MB) | 32.1 | ||
| Online | Šihlejší stůl | 81,9 | |
| Širší tabulka | 103.3 | ||
| Znovu vytvořit | Šihlejší stůl | 28.9 | |
| max 16k | Offline | Šihlejší stůl (1,6 GB) | 53,3 |
| Širší tabulka (1,7 GB) | 46,7 | ||
| Online | Šihlejší stůl | 130,9 | |
| Širší tabulka | 150,2 | ||
| Znovu vytvořit | Šihlejší stůl | 81,8 | |
| max 64k | Offline | Šihlejší stůl (7,0 GB) | 51,5 |
| Širší tabulka (7,1 GB) | 58,5 | ||
| Online | Šihlejší stůl | 136,5 | |
| Širší tabulka | 152,6 | ||
| Znovu vytvořit | Šihlejší stůl | 226,5 | |
| max 256k | Offline | Šihlejší stůl (25,8 GB) | 60,9 |
| Širší tabulka (25,9 GB) | 61.3 | ||
| Online | Šihlejší stůl | 149,1 | |
| Širší tabulka | 197.1 | ||
| Znovu vytvořit | Šihlejší stůl | 1 576,7 | |
Toto je nespravedlivé otřesy Andyho metody, protože – ve skutečném světě – byste neprovedli celou operaci na jeden záběr. Pro stručnost jsem zde neukázal použití transakčního protokolu, ale bylo by snazší to ovládat také pomocí dávkování v souběžné operaci. Zatímco jeho přístup vyžaduje více práce dopředu, je mnohem bezpečnější, pokud jde o prostoje a/nebo blokování. Ale můžete vidět v případech, kdy máte hodně dat mimo řádek a můžete si dovolit krátký výpadek, že přímá změna sloupce je mnohem méně bolestivá. „Příliš velké na změnu na místě“ je subjektivní a může přinést různé výsledky v závislosti na tom, co znamená „velký“. Než se zavážete k určitému přístupu, může mít smysl otestovat změnu proti přiměřené kopii, protože operace na místě může představovat přijatelný kompromis.
Závěr
Nepsal jsem to proto, abych se hádal s Andym. Přístup v původním příspěvku je zdravý, 100% spolehlivý a používáme ho neustále. Když je však hrubá síla oceňována před chirurgickou přesností, a zvláště pokud dokážete vzít kousek prostojů, může mít pro určité tvary stolů hodnotu jednodušší přístup.