Nedávno jsem napsal příspěvek o DISTINCT a GROUP BY. Bylo to srovnání, které ukázalo, že GROUP BY je obecně lepší varianta než DISTINCT. Je to na jiném webu, ale určitě se hned poté vraťte na sqlperformance.com..
Jedno z porovnání dotazů, které jsem v tomto příspěvku ukázal, bylo mezi GROUP BY a DISTINCT pro dílčí dotaz, což ukazuje, že DISTINCT je mnohem pomalejší, protože musí načíst název produktu pro každý řádek v tabulce Prodej, spíše než jen pro každé jiné ProductID. To je zcela zřejmé z plánů dotazů, kde můžete vidět, že v prvním dotazu Aggregate pracuje s daty pouze z jedné tabulky, spíše než s výsledky spojení. Jo a oba dotazy dávají stejných 266 řádků.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID;
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od;

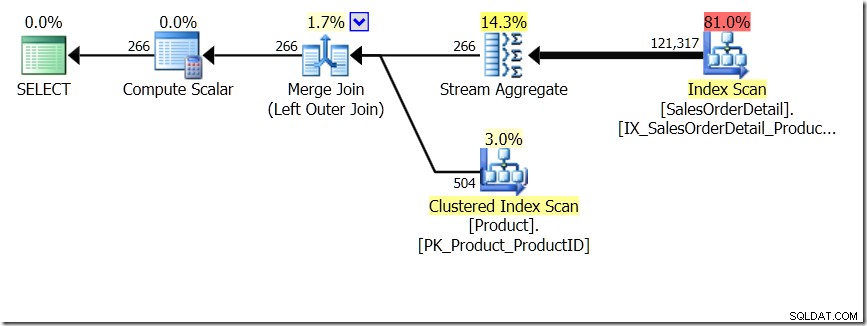
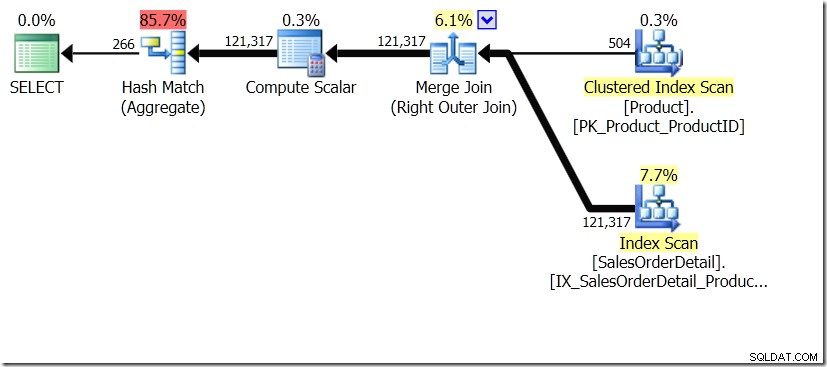
Nyní bylo zdůrazněno, včetně Adama Machanice (@adammachanic) v tweetu odkazujícím na Aaronův příspěvek o GROUP BY v DISTINCT, že tyto dva dotazy jsou v podstatě odlišné, že jeden ve skutečnosti požaduje sadu odlišných kombinací výsledků sub-query, spíše než spouštění dílčího dotazu přes různé hodnoty, které jsou předány. To je to, co vidíme v plánu, a je to důvod, proč je výkon tak odlišný.
Jde o to, že všichni bychom předpokládali, že výsledky budou identické.
Ale to je předpoklad a není dobrý.
Na chvíli si představím, že nástroj Query Optimizer přišel s jiným plánem. Použil jsem k tomu rady, ale jak víte, Optimalizátor dotazů se může rozhodnout vytvořit plány v nejrůznějších tvarech z nejrůznějších důvodů.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID
option (loop join);
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
option (loop join);
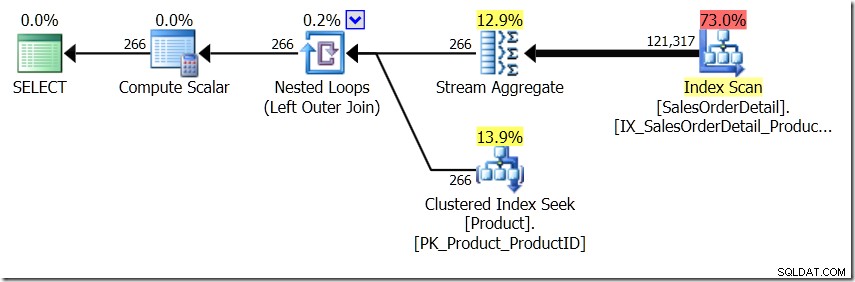
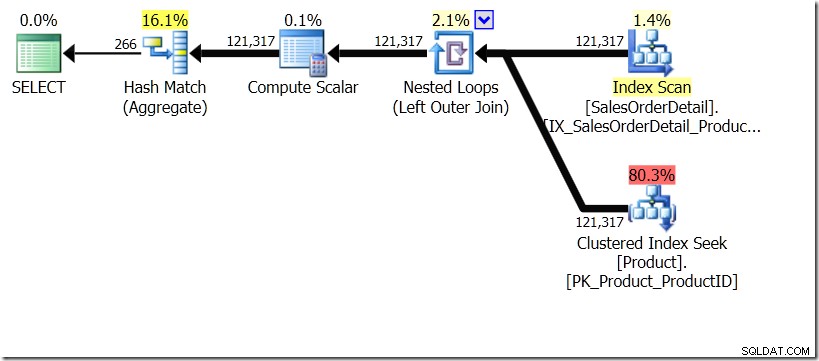
V této situaci buď provedeme 266 hledání v tabulce Produkt, jedno pro každé jiné ProductID, které nás zajímá, nebo 121 317 hledání. Pokud tedy uvažujeme o konkrétním ProductID, víme, že získáme zpět jeden název z prvního. A předpokládáme, že pro toto ProductID získáme zpět jeden název, i když o něj budeme muset žádat stokrát. Jen předpokládáme, že dostaneme zpět stejné výsledky.
Ale co když ne?
Zní to jako věc na úrovni izolace, takže když narazíme na tabulku produktů, použijme NOLOCK. A spustíme (v jiném okně) skript, který změní text ve sloupcích Název. Budu to dělat znovu a znovu, abych se pokusil získat některé změny mezi mým dotazem.
update Production.Product set Name = cast(newid() as varchar(36)); go 1000
Nyní jsou mé výsledky jiné. Plány jsou stejné (kromě počtu řádků vycházejících z Hash Aggregate ve druhém dotazu), ale mé výsledky jsou odlišné.
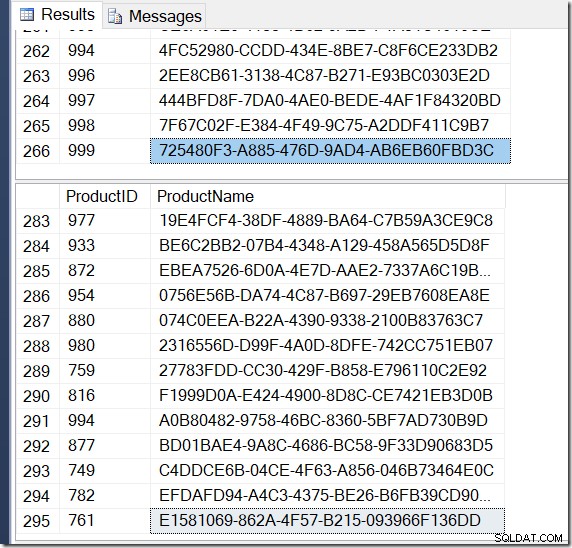
Jistě, mám více řádků s DISTINCT, protože najde různé hodnoty Name pro stejné ProductID. A nemusím mít nutně 295 řádků. Když to spustím znovu, možná dostanu 273 nebo 300 nebo možná 121 317.
Není těžké najít příklad ProductID, který zobrazuje více hodnot Name a potvrzuje, co se děje.

Abychom zajistili, že tyto řádky ve výsledcích neuvidíme, museli bychom buď NEPOUŽÍVAT DISTINCT, nebo použít přísnější úroveň izolace.
Jde o to, že ačkoli jsem v tomto příkladu zmínil použití NOLOCK, nepotřeboval jsem to. K této situaci dochází i při READ COMMITTED, což je výchozí úroveň izolace na mnoha systémech SQL Server.
Víte, potřebujeme úroveň izolace REPEATABLE READ, abychom se vyhnuli této situaci, abychom udrželi zámky na každém řádku, jakmile byl přečten. V opačném případě může samostatné vlákno změnit data, jak jsme viděli.
Ale... Nemohu vám ukázat, že výsledky jsou opravené, protože se mi nepodařilo vyhnout uváznutí dotazu.
Změňme tedy podmínky tím, že zajistíme, aby náš další dotaz byl menší problém. Místo aktualizace celé tabulky najednou (což je stejně v reálném světě mnohem méně pravděpodobné), aktualizujme pouze jeden řádek najednou.
declare @id int = 1; declare @maxid int = (select count(*) from Production.Product); while (@id < @maxid) begin with p as (select *, row_number() over (order by ProductID) as rn from Production.Product) update p set Name = cast(newid() as varchar(36)) where rn = @id; set @id += 1; end go 100
Nyní můžeme stále demonstrovat problém na nižší úrovni izolace, jako je READ COMMITTED nebo READ UNCOMMITTED (ačkoli budete možná muset spustit dotaz několikrát, pokud dostanete 266 poprvé, protože šance na aktualizaci řádku během dotazu je méně) a nyní můžeme prokázat, že REPEATABLE READ to opraví (bez ohledu na to, kolikrát spustíme dotaz).
OPAKOVANÉ PŘEČTENÍ dělá to, co je napsáno na plechovce. Jakmile přečtete řádek v rámci transakce, je uzamčen, aby bylo zajištěno, že můžete čtení opakovat a získat stejné výsledky. Nižší úrovně izolace tyto zámky nezruší, dokud se nepokusíte změnit data. Pokud váš plán dotazů nikdy nepotřebuje opakovat čtení (jako je tomu v případě tvaru našich plánů GROUP BY), pak nebudete potřebovat OPAKOVATELNÉ ČTENÍ.
Pravděpodobně bychom měli vždy používat vyšší úrovně izolace, jako je REPEATABLE READ nebo SERIALIZABLE, ale vše záleží na tom, abychom zjistili, co naše systémy potřebují. Tyto úrovně mohou způsobit nechtěné zamykání a úrovně izolace SNAPSHOT vyžadují verzování, které je také spojeno s cenou. Za mě si myslím, že je to kompromis. Pokud žádám o dotaz, který by mohl být ovlivněn změnou dat, pak možná budu muset na chvíli zvýšit úroveň izolace.
V ideálním případě jednoduše neaktualizujete data, která byla právě načtena a která by mohla být potřeba přečíst znovu během dotazu, takže nepotřebujete OPAKOVANÉ ČTENÍ. Ale rozhodně stojí za to pochopit, co se může stát, a uvědomit si, že toto je ten typ scénáře, kdy DISTINCT a GROUP BY nemusí být stejné.
@rob_farley