Záleží na vašem výběru datových typů SQL serveru a jejich velikosti?
Odpověď spočívá ve výsledku, který jste dostali. Změnila se vaše databáze v krátké době? Jsou vaše dotazy pomalé? Měli jste špatné výsledky? A co chyby za běhu během vkládání a aktualizací?
Není to tak skličující úkol, pokud víte, co děláte. Dnes se dozvíte 5 nejhorších možností, které lze s těmito datovými typy udělat. Pokud se staly vaším zvykem, je to věc, kterou bychom měli opravit pro vaše vlastní dobro a vaše uživatele.
Spousta datových typů v SQL, spousta zmatků
Když jsem se poprvé dozvěděl o datových typech SQL Server, možnosti byly ohromující. Všechny typy jsou v mé mysli pomíchané jako tento slovní mrak na obrázku 1:

Můžeme jej však uspořádat do kategorií:
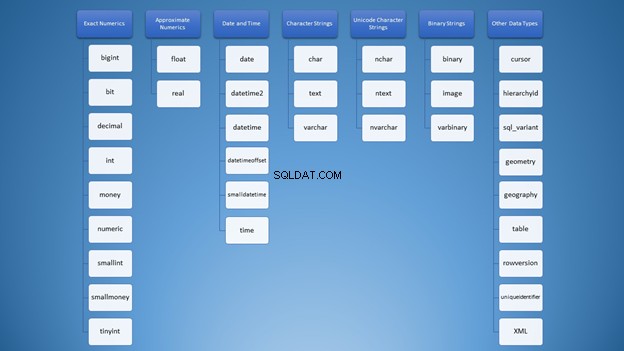
Přesto pro použití řetězců máte spoustu možností, které mohou vést k nesprávnému použití. Nejprve jsem si myslel, že varchar a nvarchar byly úplně stejné. Kromě toho jsou oba typy řetězců znaků. Použití čísel není jiné. Jako vývojáři potřebujeme vědět, který typ použít v různých situacích.
Možná se ale ptáte, co nejhoršího se může stát, když se rozhodnu špatně? Řeknu vám to!
1. Výběr nesprávných datových typů SQL
Tato položka bude používat řetězce a celá čísla k prokázání pointy.
Použití datového typu SQL s nesprávným znakovým řetězcem
Nejprve se vraťme ke strunám. Existuje něco, co se nazývá Unicode a non-Unicode řetězce. Oba mají různé velikosti úložiště. Často to definujete ve sloupcích a deklaracích proměnných.
Syntaxe je buď varchar (n)/char (n) nebo nvarchar (n)/nchar (n) kde n je velikost.
Všimněte si, že n není počet znaků, ale počet bajtů. Je to běžná mylná představa, která se stává, protože v varchar , počet znaků je stejný jako velikost v bajtech. Ale ne v nvarchar .
Abychom tuto skutečnost dokázali, vytvoříme 2 tabulky a vložíme do nich nějaká data.
CREATE TABLE dbo.VarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString VARCHAR(4000)
)
GO
CREATE TABLE dbo.NVarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString NVARCHAR(4000)
)
GO
INSERT INTO VarcharTable (someString)
VALUES (REPLICATE('x',4000))
GO 1000
INSERT INTO NVarcharTable (someString)
VALUES (REPLICATE(N'y',4000))
GO 1000
Nyní zkontrolujeme jejich velikosti řádků pomocí DATALENGTH.
SET STATISTICS IO ON
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM VarcharTable
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM NVarcharTable
SET STATISTICS IO OFF
Obrázek 3 ukazuje, že rozdíl je dvojnásobný. Podívejte se na to níže.
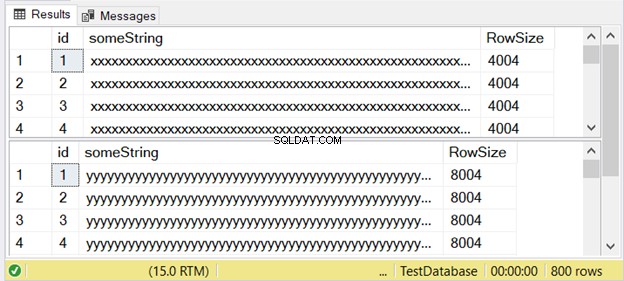
Všimněte si druhé sady výsledků s velikostí řádku 8004. Toto používá nvarchar datový typ. Je také téměř dvakrát větší než velikost řádku první sady výsledků. A to používá varchar datový typ.
Vidíte důsledky pro úložiště a I/O. Obrázek 4 ukazuje logická čtení 2 dotazů.
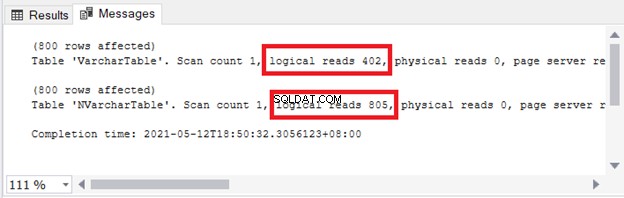
Vidět? Logická čtení jsou také dvojnásobná při použití nvarchar ve srovnání s varchar .
Nemůžete tedy každý zaměnitelně používat. Pokud potřebujete uložit vícejazyčné znaků, použijte nvarchar . V opačném případě použijte varchar .
To znamená, že pokud použijete nvarchar pouze pro jednobajtové znaky (jako angličtina) velikost úložiště je vyšší . Výkon dotazu je také pomalejší s vyšším logickým čtením.
V SQL Server 2019 (a vyšším) můžete ukládat celý rozsah znakových dat Unicode pomocí varchar nebo char s některou z možností řazení UTF-8.
Použití nesprávného číselného datového typu SQL
Stejný koncept platí pro bigint vs. int – jejich velikosti mohou znamenat noc a den. Jako nvarchar a varchar , velký je dvakrát větší než int (8 bajtů pro bigint a 4 bajty pro int ).
Přesto je možný další problém. Pokud vám jejich velikosti nevadí, může dojít k chybám. Pokud použijete int sloupec a uložíte číslo větší než 2 147 483 647, dojde k aritmetickému přetečení:
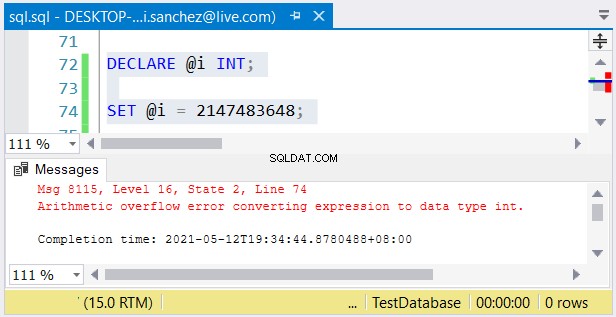
Při výběru typů celých čísel se ujistěte, že se vejdou data s maximální hodnotou . Můžete například navrhovat tabulku s historickými daty. Plánujete použít celá čísla jako hodnotu primárního klíče. Myslíte si, že nedosáhne 2 147 483 647 řádků? Poté použijte int místo velký jako typ sloupce primárního klíče.
Nejhorší věc, která se může stát
Výběr nesprávných datových typů může ovlivnit výkon dotazu nebo způsobit chyby za běhu. Vyberte tedy typ dat, který je pro data vhodný.
2. Vytváření velkých řádků tabulky pomocí velkých datových typů pro SQL
Naše další položka souvisí s tou první, ale ještě více rozšíří pointu o příklady. Také to má něco společného se stránkami a velkým varchar nebo nvarchar sloupce.
Co je to se stránkami a velikostmi řádků?
Koncept stránek v SQL Server lze přirovnat ke stránkám spirálového poznámkového bloku. Každá stránka v poznámkovém bloku má stejnou fyzickou velikost. Píšeš slova a kreslíš na ně obrázky. Pokud stránka na sadu odstavců a obrázků nestačí, pokračuje se na další stránce. Někdy také roztrhnete stránku a začnete znovu.
Podobně jsou data tabulek, položky rejstříku a obrázky na serveru SQL uloženy na stránkách.
Stránka má stejnou velikost 8 kB. Pokud je řádek dat velmi velký, nevejde se na stránku o velikosti 8 kB. Jeden nebo více sloupců bude zapsáno na jiné stránce pod alokační jednotkou ROW_OVERFLOW_DATA. Obsahuje ukazatel na původní řádek na stránce pod alokační jednotkou IN_ROW_DATA.
Na základě toho nemůžete při návrhu databáze jen tak umístit spoustu sloupců do tabulky. To bude mít důsledky na I/O. Pokud se na tato data o přetečení řádků dotazujete hodně, bude doba provádění pomalejší . To může být noční můra.
Problém nastane, když vytěžíte všechny sloupce různé velikosti. Poté se data přenesou na další stránku pod ROW_OVERFLOW_DATA. aktualizujte sloupce daty menší velikosti a je třeba je na této stránce odstranit. Nový menší datový řádek bude zapsán na stránku pod IN_ROW_DATA spolu s ostatními sloupci. Představte si I/O, které jsou zde zapojeny.
Příklad velkého řádku
Nejprve si připravíme data. Budeme používat datové typy řetězců znaků s velkými velikostmi.
CREATE TABLE [dbo].[LargeTable](
[id] [int] IDENTITY(1,1) NOT NULL,
[SomeString] [varchar](15) NOT NULL,
[LargeString] [nvarchar](3980) NOT NULL,
[AnotherString] [varchar](8000) NULL,
CONSTRAINT [PK_LargeTable] PRIMARY KEY CLUSTERED
(
[id] ASC
))
GO
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',500),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',50))
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',8000))
GO 100
Zjištění velikosti řádku
Z vygenerovaných dat se podívejme na jejich velikosti řádků na základě DATALENGTH.
SELECT *, DATALENGTH(id)
+ DATALENGTH(SomeString)
+ DATALENGTH(LargeString)
+ DATALENGTH(ISNULL(AnotherString,0)) AS RowSize
FROM LargeTable
Prvních 300 záznamů se vejde na stránky IN_ROW_DATA, protože každý řádek má méně než 8060 bajtů nebo 8 kB. Ale posledních 100 řádků je příliš velkých. Podívejte se na sadu výsledků na obrázku 6.
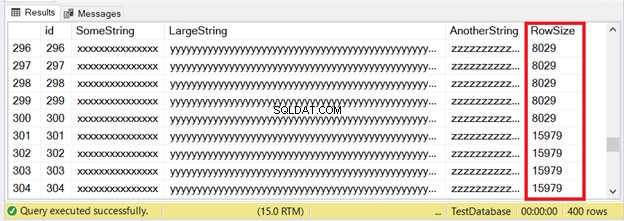
Vidíte část z prvních 300 řádků. Dalších 100 překračuje limit velikosti stránky. Jak víme, že posledních 100 řádků je v alokační jednotce ROW_OVERFLOW_DATA?
Kontrola ROW_OVERFLOW_DATA
Použijeme sys.dm_db_index_physical_stats . Vrací informace o stránce o položkách tabulky a rejstříku.
SELECT
ps.index_id
,[Index] = i.[name]
,ps.index_type_desc
,ps.alloc_unit_type_desc
,ps.index_depth
,ps.index_level
,ps.page_count
,ps.record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),
OBJECT_ID('dbo.LargeTable'), NULL, NULL, 'DETAILED') AS ps
INNER JOIN sys.indexes AS i ON ps.index_id = i.index_id
AND ps.object_id = i.object_id;
Sada výsledků je na obrázku 7.

Je to tady. Obrázek 7 ukazuje 100 řádků pod ROW_OVERFLOW_DATA. To je v souladu s obrázkem 6, když existují velké řádky počínaje řádky 301 až 400.
Další otázkou je, kolik logických čtení získáme, když se dotazujeme na těchto 100 řádků. Zkusme to.
SELECT * FROM LargeTable
WHERE id BETWEEN 301 AND 400
ORDER BY AnotherString DESC

Vidíme 102 logických čtení a 100 logických čtení LargeTable . Tato čísla zatím ponechte – porovnáme je později.
Nyní se podívejme, co se stane, když aktualizujeme 100 řádků menšími daty.
UPDATE LargeTable
SET AnotherString = 'updated',LargeString='updated'
WHERE id BETWEEN 301 AND 400
Tento příkaz aktualizace používal stejná logická čtení a logická čtení jako na obrázku 8. Z toho víme, že se stalo něco většího kvůli logickým čtením lob u 100 stránek.
Ale pro jistotu to zkontrolujte pomocí sys.dm_db_index_physical_stats jako jsme to udělali dříve. Obrázek 9 ukazuje výsledek:

Pryč! Stránky a řádky z ROW_OVERFLOW_DATA se po aktualizaci 100 řádků s menšími daty staly nulovými. Nyní víme, že k přesunu dat z ROW_OVERFLOW_DATA na IN_ROW_DATA dochází, když jsou velké řádky zmenšeny. Představte si, že se to stane často pro tisíce nebo dokonce miliony záznamů. Blázen, že?
Na obrázku 8 jsme viděli 100 logických čtení. Nyní se po opětovném spuštění dotazu podívejte na obrázek 10:

Stala se nulou!
Nejhorší věc, která se může stát
Pomalý výkon dotazů je vedlejším produktem dat o přetečení řádků. Zvažte přesunutí velkých sloupců do jiné tabulky, abyste tomu zabránili. Případně zmenšete velikost varchar nebo nvarchar sloupec.
3. Slepě pomocí implicitní konverze
SQL nám neumožňuje používat data bez určení typu. Ale je shovívavé, pokud se rozhodneme špatně. Snaží se převést hodnotu na typ, který očekává, ale s penalizací. To se může stát v klauzuli WHERE nebo JOIN.
USE AdventureWorks2017
GO
SET STATISTICS IO ON
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = 77775294979396 -- this will trigger an implicit conversion
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = '77775294979396'
SET STATISTICS IO OFF
Číslo karty sloupec není číselného typu. Je to nvarchar . První SELECT tedy způsobí implicitní převod. Oba však poběží v pořádku a vytvoří stejnou sadu výsledků.
Podívejme se na plán provádění na obrázku 11.
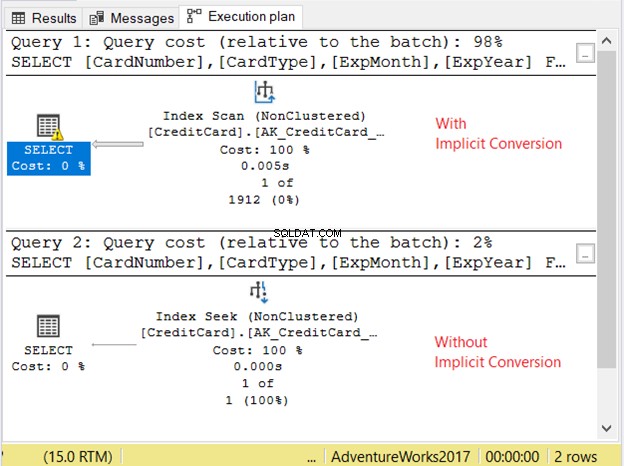
2 dotazy proběhly velmi rychle. Na obrázku 11 je to nula sekund. Ale podívejte se na 2 plány. Ten s implicitním převodem měl indexové skenování. Je zde také varovná ikona a tlustá šipka ukazující na operátor SELECT. Říká nám, že je to špatné.
Tím to ale nekončí. Pokud najedete myší na operátor SELECT, uvidíte něco jiného:

Varovná ikona v operátoru SELECT se týká implicitního převodu. Ale jak velký je dopad? Pojďme zkontrolovat logická čtení.
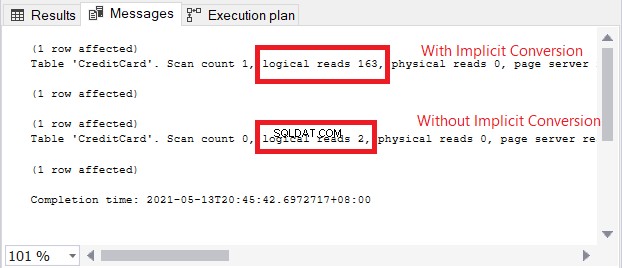
Porovnání logických čtení na obrázku 13 je jako nebe a země. V dotazu na informace o kreditní kartě způsobila implicitní konverze více než stonásobek logických čtení. Velmi špatné!
Nejhorší věc, která se může stát
Pokud implicitní převod způsobil vysoké logické čtení a špatný plán, očekávejte pomalý výkon dotazů u velkých sad výsledků. Chcete-li se tomu vyhnout, použijte přesný datový typ v klauzuli WHERE a JOIN při shodě s porovnávanými sloupci.
4. Použití přibližných čísel a jejich zaokrouhlení
Podívejte se znovu na obrázek 2. Datové typy serveru SQL patřící do přibližných čísel jsou float a skutečné . Sloupce a proměnné z nich vytvořené uchovávají blízkou aproximaci číselné hodnoty. Pokud máte v plánu tato čísla zaokrouhlit nahoru nebo dolů, můžete se dočkat velkého překvapení. Mám zde článek, který o tom podrobně pojednává. Podívejte se, jak 1 + 1 vede k 3 a jak se vypořádat se zaokrouhlováním čísel.
Nejhorší věc, která se může stát
Zaokrouhlení plovoucí hodnoty nebo skutečný může mít šílené výsledky. Pokud chcete přesné hodnoty po zaokrouhlení, použijte desítkové nebo numerické místo toho.
5. Nastavení datových typů řetězců s pevnou velikostí na hodnotu NULL
Zaměřme svou pozornost na datové typy s pevnou velikostí, jako je char a nchar . Kromě vycpaných mezer bude jejich nastavení na NULL mít stále velikost úložiště rovnající se velikosti znaku sloupec. Takže nastavením znaku Sloupec (500) na hodnotu NULL bude mít velikost 500, nikoli nulu nebo 1.
CREATE TABLE dbo.CharNullSample
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
col1 CHAR(500) NULL,
col2 CHAR(200) NULL,
col3 CHAR(350) NULL,
col4 VARCHAR(500) NULL,
col5 VARCHAR(200) NULL,
col6 VARCHAR(350) NULL
)
GO
INSERT INTO CharNullSample (col1, col2, col3, col4, col5, col6)
VALUES (REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350), REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350));
GO 200
Ve výše uvedeném kódu jsou data maximalizována na základě velikosti char a varchar sloupců. Kontrola jejich velikosti řádku pomocí DATALENGTH také zobrazí součet velikostí každého sloupce. Nyní nastavíme sloupce na NULL.
UPDATE CharNullSample
SET col1 = NULL, col2=NULL, col3=NULL, col4=NULL, col5=NULL, col6=NULL
Dále se dotazujeme na řádky pomocí DATALENGTH:
SELECT
DATALENGTH(ISNULL(col1,0)) AS Col1Size
,DATALENGTH(ISNULL(col2,0)) AS Col2Size
,DATALENGTH(ISNULL(col3,0)) AS Col3Size
,DATALENGTH(ISNULL(col4,0)) AS Col4Size
,DATALENGTH(ISNULL(col5,0)) AS Col5Size
,DATALENGTH(ISNULL(col6,0)) AS Col6Size
FROM CharNullSample
Jaká bude podle vás datová velikost každého sloupce? Podívejte se na obrázek 14.
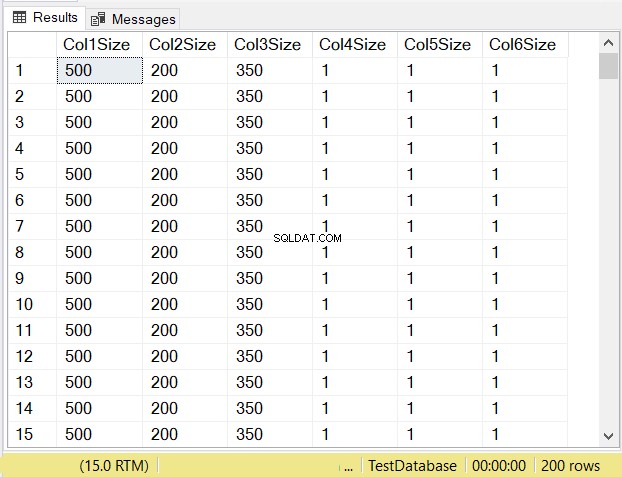
Podívejte se na velikosti sloupců prvních 3 sloupců. Poté je porovnejte s kódem výše, když byla tabulka vytvořena. Velikost dat sloupců NULL se rovná velikosti sloupce. Mezitím varchar sloupce, když NULL mají velikost dat 1.
Nejhorší věc, která se může stát
Během navrhování tabulek použijte char s možnou hodnotou null Pokud jsou sloupce nastaveny na hodnotu NULL, budou mít stále stejnou velikost úložiště. Budou také spotřebovávat stejné stránky a RAM. Pokud nevyplníte celý sloupec znaky, zvažte použití varchar místo toho.
Co bude dál?
Záleží tedy na vašem výběru datových typů SQL serveru a jejich velikosti? Body, které jsou zde uvedeny, by měly stačit k vyjádření. Co tedy můžete nyní dělat?
- Udělejte si čas na kontrolu databáze, kterou podporujete. Začněte tím nejjednodušším, pokud jich máte na talíři několik. A ano, udělat si čas, ne najít si čas. V našem oboru je téměř nemožné najít si čas.
- Prohlédněte si tabulky, uložené procedury a vše, co se zabývá datovými typy. Všimněte si pozitivního dopadu při identifikaci problémů. Budete to potřebovat, až se vás šéf zeptá, proč na tom musíte pracovat.
- Plánujte útok na každou z problémových oblastí. Při řešení problémů dodržujte jakékoli metodiky nebo zásady, které má vaše společnost.
- Jakmile problémy pominou, oslavte to.
Zní to jednoduše, ale všichni víme, že není. Víme také, že na konci cesty je i světlá stránka. Proto se jim říká problémy - protože existuje řešení. Tak se rozveselte.
Chcete k tomuto tématu ještě něco dodat? Dejte nám vědět v sekci Komentáře. A pokud vám tento příspěvek dal dobrý nápad, sdílejte jej na svých oblíbených platformách sociálních médií.