Když vyvíjíte aplikaci nebo píšete kód v databázovém systému SQL, je zásadní pochopit, jak budou data tříděna a porovnávána. Svá data můžete ukládat v konkrétním jazyce nebo můžete chtít, aby SQL Server zpracovával data rozlišující malá a velká písmena odděleně. Společnost Microsoft poskytla nastavení serveru SQL Server s názvem Collation kontrolovat a řešit takové požadavky.
Co je řazení na serveru SQL?
Můžeme nastavit řazení na různých úrovních v SQL Server, jak je uvedeno níže.
- Úroveň serveru
- Úroveň databáze
- Úroveň sloupce
- Úroveň výrazu
Porovnání na úrovni serveru může být někdy nazýváno Řazení na úrovni instance serveru SQL .
Pokud během vytváření databáze nezvolíte žádné konkrétní řazení, bude řazení na úrovni databáze zděděno z nastavení řazení na úrovni serveru. Řazení na úrovni databáze můžete také změnit později. Mějte na paměti, že změna řazení databáze bude použita pouze pro nadcházející nebo nové objekty, které budou vytvořeny po změně řazení.
Nové řazení nezmění existující data uložená v tabulkách, které byly seřazeny podle posledního typu řazení. Aplikační tým potřebuje další plánování, aby zvládl tuto konverzi uložených dat kvůli novému nastavení řazení.
Existuje několik způsobů, jak to udělat. Jedním z nich je zkopírovat data ze stávající tabulky do nové tabulky vytvořené s novým řazením a poté nahradit starou tabulku novou. Můžete také přesunout data tabulky do nové databáze vytvořením nového řazení a nahradit starou databázi novou.
POZNÁMKA :Změna řazení je složitý úkol a měli byste se mu vyhnout, pokud nemáte povinný obchodní případ.
Jak najít a změnit řazení databází na serveru SQL?
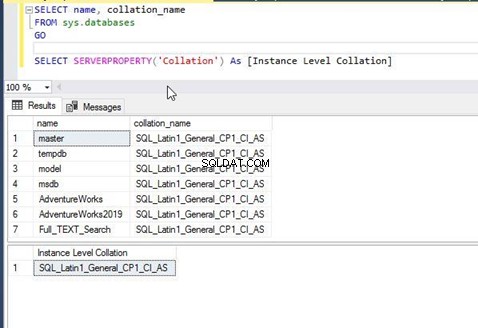
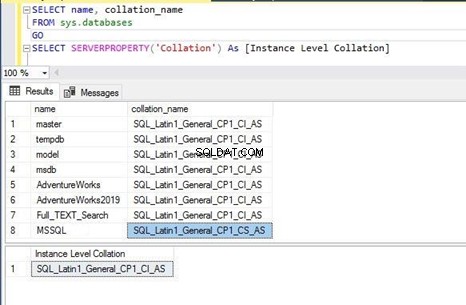
Pojďme do toho a zkontrolujeme řazení instance SQL Server a všech databází hostovaných v této instanci. Porovnání můžete zkontrolovat v vlastnostech na úrovni databáze nebo instance pomocí SQL Server Management Studio nebo jednoduše provedením níže uvedeného příkazu T-SQL. Porovnání pro každou databázi je uloženo v systémovém objektu sys.databases – přistoupíme k němu, abychom tyto informace získali.
--Check Database Collation
SELECT name, collation_name
FROM sys.databases
GO
--Check Server or Instance level Collation
SELECT SERVERPROPERTY('Collation') As [Instance Level Collation]
Provedl jsem výše uvedený příkaz T-SQL a získal jsem níže uvedený výstup. Vidíme, že všechny databáze a řazení na úrovni serveru mají stejná nastavení jako SQL_Latin1_General_CP1_CI_AS . Znamená to, že databázová kolace byla při jejich vytváření zděděna kolací na úrovni serveru a výchozí hodnota se nezměnila.
Nyní vám ukážu, jak zkontrolovat řazení databází pomocí GUI v SQL Server Management Studio.
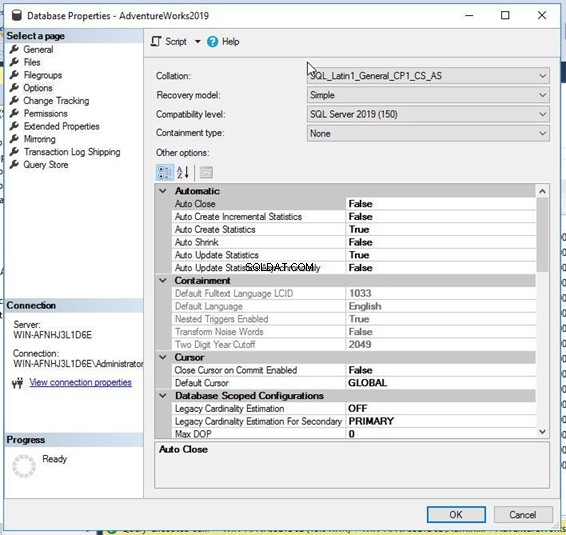
Nejprve se připojte k instanci SQL Server pomocí SQL Server Management Studio. Rozbalte uzel instance následovaný Databází složka. Klikněte pravým tlačítkem na cílovou databázi a vyberte Vlastnosti :
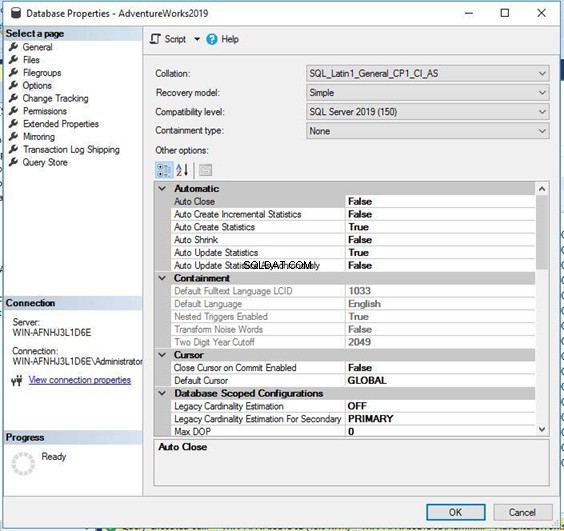
Získáte níže uvedené Vlastnosti databáze okno.
Nyní klikněte na Možnosti z panelu na levé straně. V panelu na pravé straně získáte několik nastavení vlastností. Řazení je první vlastností této stránky – můžete vidět, že je stejná jako ve výše uvedeném T-SQL skriptu.
Podobně můžete kliknout na uzel instance SQL Server a kliknout pravým tlačítkem na vlastnosti na úrovni instance zobrazíte řazení na úrovni serveru.
Pokud chcete toto řazení změnit na nové, stačí kliknout na Řazení rozevíracího seznamu a vyberte možnost, kterou potřebujete. Než to uděláte, ujistěte se, že jste provedli úplnou zálohu databáze.
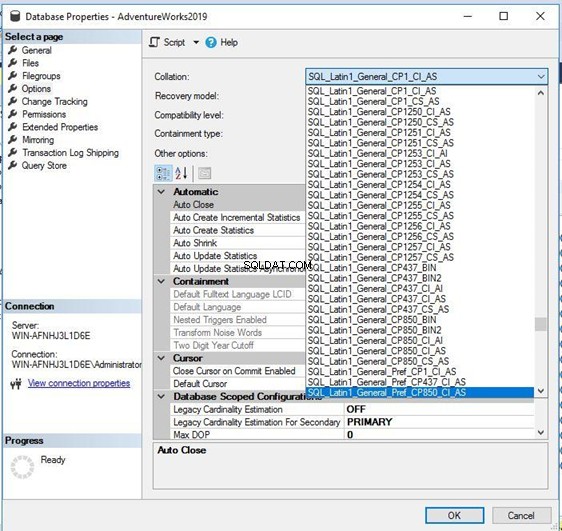
Vybral jsem podobné řazení s SQL_Latin1_General_CP1_CS rozlišující malá a velká písmena _AS pro tuto databázi a klikněte na OK to aplikovat. Poznámka:Ujistěte se, že během tohoto postupu není nikdo připojen k cílové databázi, jinak budete muset přepnout režim na režim pro jednoho uživatele a změňte tuto konfiguraci.
Toto řazení databáze můžete také změnit pomocí příkazu T-SQL. K tomu použijte COLLATE klauzule příkazu ALTER DATABASE.
Nejprve jsme přepnuli databázi na jednouživatelskou režimu, poté změnil řazení a nakonec přesunul databázi do více uživatelů režimu.
--Change Database Collation using T-SQL
USE master;
GO
Alter DATABASE [AdventureWorks2019] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
GO
ALTER DATABASE [AdventureWorks2019]
COLLATE SQL_Latin1_General_CP1_CI_AS;
GO
Alter DATABASE [AdventureWorks2019] SET MULTI_USER
Seznam všech podporovaných řazení na serveru SQL Server
Tato část vám ukáže, jak najít všechna dostupná kolace na serveru SQL Server. Nejprve vám ukážu, jak získat seznam všech podporovaných porovnávání pro instanci SQL Server.
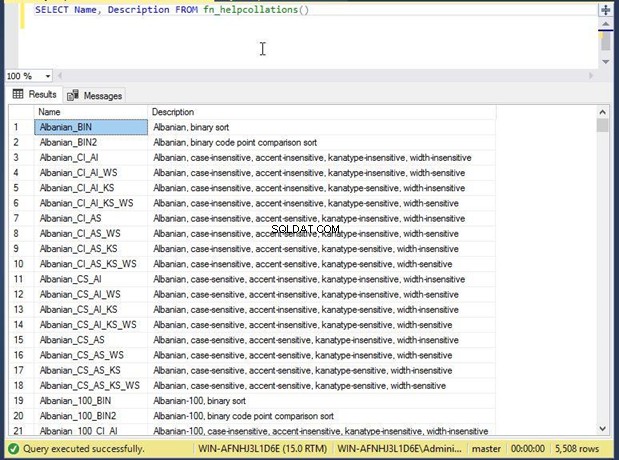
SQL Server má systémovou funkci nazvanou fn_helpcollations() kterou můžete použít k načtení všech porovnávání.
Spuštěním níže uvedeného příkazu zobrazte seznam.
--Display the list of all collations
SELECT name, description FROM fn_helpcollations()
Všech 5508 podporovaných porovnávání můžeme vidět ve výstupní sekci. Pokud si nejste jisti, které řazení zvolit, můžete pomocí klauzule WHERE v níže uvedeném skriptu odfiltrovat všechna možná řazení, která lze v databázi nastavit.
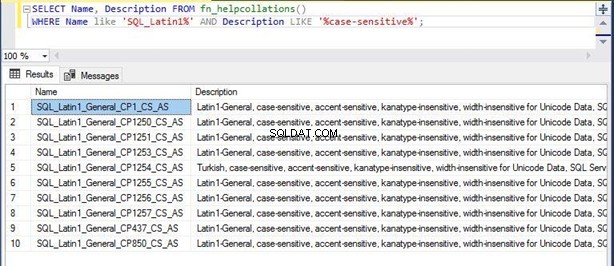
Řekněme, že potřebujete ukládat svá data v americké angličtině a chcete, aby je SQL Server zpracovával ve formátu, ve kterém se rozlišují velká a malá písmena. K načtení seznamu možných a podporovaných porovnávání pro váš dotaz můžete použít níže uvedený příkaz:
--Display the list of all collations with WHERE clause
SELECT Name, Description FROM fn_helpcollations()
WHERE Name like 'SQL_Latin1%' AND Description LIKE '%case-sensitive%’
Výstup zobrazuje pouze 10 řazení vyhovujících vašemu dotazu. Výše uvedený skript můžete použít k odfiltrování různých řazení.
Vliv změny řazení databází na výstup dotazu
V této části vám ukážu rozdíl mezi dvěma výstupy stejného dotazu, když jsou provedeny s různým řazením.
Nejprve vytvořím databázi s názvem MSSQL s řazením (SQL_Latin1_General_CP1_CS _AS ). Poté spustím stejný dotaz dvakrát, abych získal výstup. Později změním řazení na SQL_Latin1_General_CP1_CI _AS a znovu spusťte stejné dotazy, abyste získali jejich výstup. Můžete porovnat oba výstupy a pochopit dopad změny řazení databáze. Začněme tedy vytvořením databáze.
Spusťte okno pro vytvoření nové databáze, jak je znázorněno na obrázku níže. Tuto databázi můžete také vytvořit pomocí T-SQL. Poté můžete vidět název databáze a její datové soubory. Nyní klikněte na druhou kartu na levém panelu a přepněte se do okna vlastností řazení.
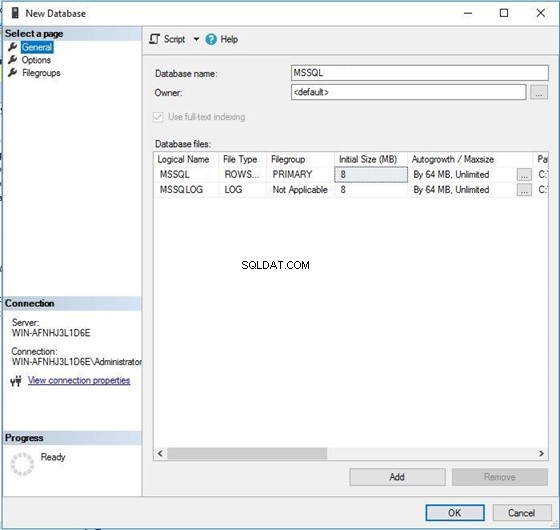
Můžete vidět, že název řazení pro tuto databázi je výchozí . To znamená, že tato databáze zdědí řazení od typu řazení na úrovni serveru. Klikněte na Řazení rozbalovací nabídky a vyberte si nové řazení.
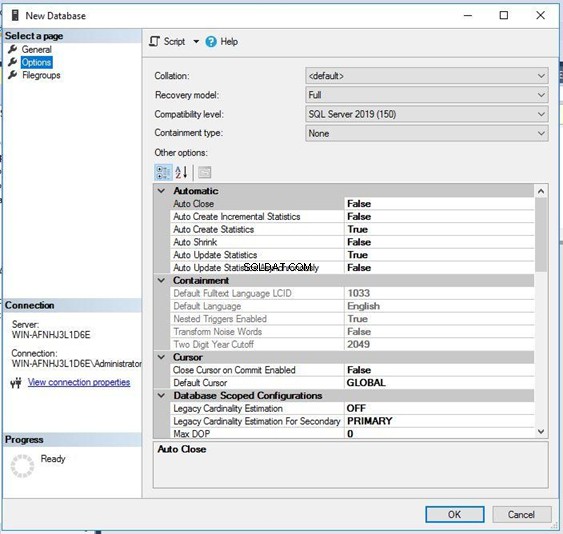
Vybral jsem níže uvedené řazení SQL_Latin1_General_CP1_CS _AS pro tuto databázi – nikoli výchozí. Klikněte na OK pokračovat ve vytváření databáze.
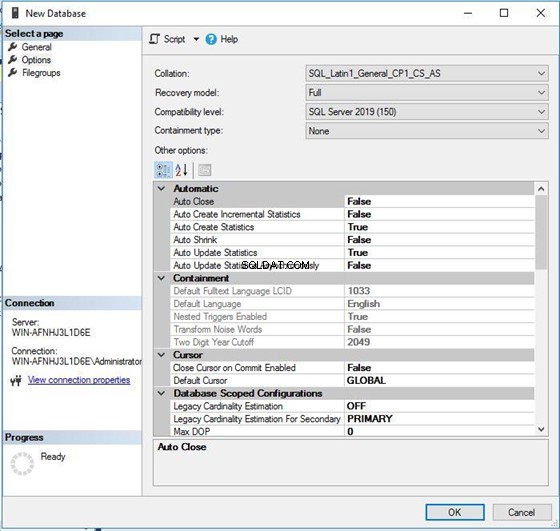
Nyní zkontrolujte třídění databáze pro nově vytvořenou databázi. Vidíme, že je to SQL_Latin1_General_CP1_CS _AS jak jsme vybrali v předchozím kroku.
V SQL_Latin1_General_CP1_CS _AS , CS znamená rozlišovat malá a velká písmena režim a CI znamená nerozlišují malá a velká písmena režimu. Nyní můžete spustit buď níže uvedený kód T-SQL nebo jakýkoli kód, abyste získali výstup.
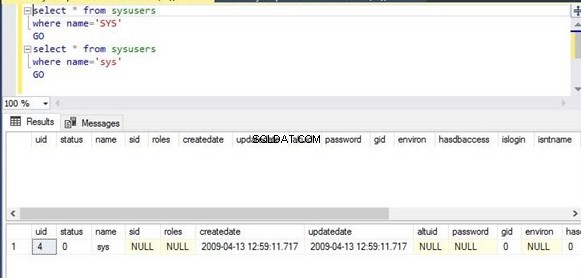
Dvakrát jsem provedl stejný příkaz. První skript filtruje názvy sloupců s hodnotou SYS kapitálem písmena, zatímco druhý skript bude filtrovat stejný sloupec se stejnou hodnotou sys v malém písmena. Sekce výstupu ukazuje, že první skript neukázal žádný výstup, zatímco druhý skript zobrazil výstup kvůli jeho chování rozlišující malá a velká písmena.
Select * from sysusers
Where name=’SYS’
Go
Select * from sysusers
Where name=’sys’
GO
Nyní změníme řazení této databáze na rozlišování velkých a malých písmen SQL_Latin1_General_CP1_CI _AS provedením níže uvedených příkazů T-SQL. Můžete jej také změnit pomocí GUI v okně Vlastnosti databáze v SQL Server Management Studio.
--Change database collation to SQL_Latin1_General_CP1_CI_AS
USE master;
GO
Alter DATABASE [MSSQL] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
GO
ALTER DATABASE [MSSQL]
COLLATE SQL_Latin1_General_CP1_CI_AS;
GO
Alter DATABASE [MSSQL] SET MULTI_USER
Výše uvedený skript jsem provedl na jeden záběr a řazení databáze bylo úspěšně změněno na nové řazení s podporou bez ohledu na velikost písmen.
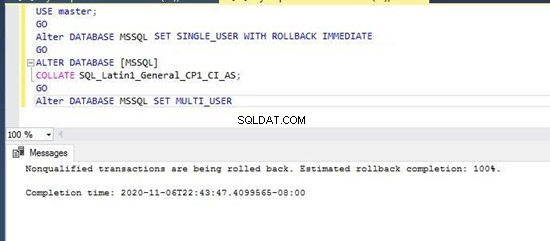
Tuto změnu můžete ověřit spuštěním níže uvedených skriptů pro kontrolu řazení nově vytvořené databáze MSSQL. Na obrázku níže vidíme, že nové řazení je nastaveno pro tuto databázi.
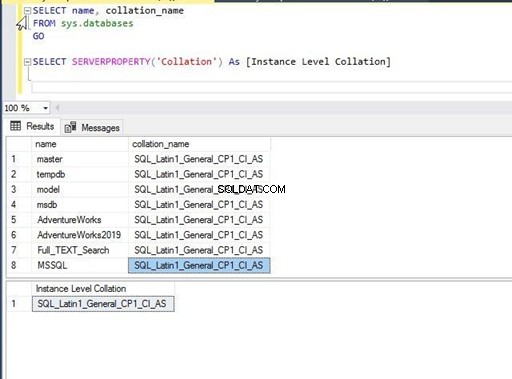
Před změnou řazení znovu spustíme stejný příkaz T-SQL, abychom viděli dopad této změny. Jak nyní vidíme, oba příkazy T-SQL jsou ve výstupu.
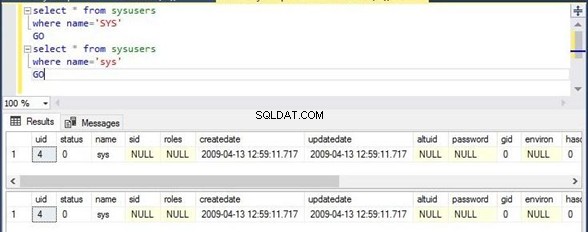
Závěr
Doufám, že je zřejmé, že řazení v SQL Serveru je zásadní. Definovali jsme, jaký dopad to zanechá, pokud provedete změny v řazení na jakékoli úrovni v SQL Server. Vždy proveďte správné plánování a nejprve otestujte úpravy v prostředí nižšího životního cyklu.
Zůstaňte naladěni na můj další článek, kde vám ukážu krok za krokem způsob, jak změnit řazení na úrovni serveru.
Sdílejte prosím tento článek a poskytněte nám svůj názor, pomáhá nám to zlepšovat se.