Typ a počet zámků získaných a uvolněných během provádění dotazu může mít překvapivý vliv na výkon (při použití úrovně izolace zamykání, jako je výchozí potvrzené čtení), i když nedochází k žádnému čekání nebo blokování. V prováděcích plánech nejsou žádné informace, které by indikovaly množství aktivity zamykání během provádění, což ztěžuje rozpoznání, kdy nadměrné zamykání způsobuje problém s výkonem.
Abych prozkoumal některé méně známé chování zamykání na serveru SQL Server, znovu použiji dotazy a ukázková data z mého posledního příspěvku o výpočtu mediánů. V tom příspěvku jsem zmínil, že OFFSET seskupené mediánové řešení potřebovalo explicitní PAGLOCK zamykací nápověda, aby nedošlo ke ztrátě vnořeného kurzoru řešení, takže začněme tím, že se podrobně podíváme na důvody.
Řešení OFFSET Grouped Medián
Test seskupeného mediánu znovu použil ukázková data z dřívějšího článku Aarona Bertranda. Skript níže znovu vytvoří toto nastavení s milionem řádků, které se skládá z deseti tisíc záznamů pro každého ze sta imaginárních prodejců:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
SQL Server 2012 (a novější) OFFSET řešení vytvořené Peterem Larssonem je následující (bez jakýchkoli zámků):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Důležité části plánu po provedení jsou uvedeny níže:

Se všemi požadovanými daty v paměti se tento dotaz provede za 580 ms v průměru na mém notebooku (s SQL Server 2014 Service Pack 1). Výkon tohoto dotazu lze zlepšit na 320 ms jednoduše přidáním nápovědy k uzamčení granularity stránky do tabulky Prodej v poddotazu použití:
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK) -- NEW!
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Prováděcí plán je nezměněn (samozřejmě kromě textu nápovědy pro zamykání v showplan XML):
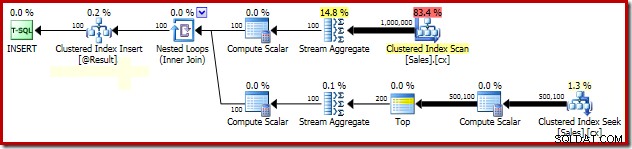
Analýza seskupeného mediánu uzamčení
Vysvětlení pro dramatické zlepšení výkonu díky PAGLOCK nápověda je docela jednoduchá, alespoň zpočátku.
Pokud ručně monitorujeme aktivitu zamykání během provádění tohoto dotazu, vidíme, že bez nápovědy k granularitě zamykání stránky SQL Server získává a uvolňuje více než půl milionu zámků na úrovni řádků při hledání seskupeného indexu. Na vině není žádné blokování; prosté získání a uvolnění takového množství zámků přidává podstatnou režii na provádění tohoto dotazu. Vyžadování zámků na úrovni stránky výrazně snižuje aktivitu zamykání, což vede k mnohem lepšímu výkonu.
Problém s výkonem zamykání tohoto konkrétního plánu je omezen na hledání seskupeného indexu ve výše uvedeném plánu. Úplné prohledávání seskupeného indexu (používá se k výpočtu počtu řádků přítomných pro každého prodejce) automaticky používá zámky na úrovni stránky. To je zajímavý bod. Podrobné zamykání enginu SQL Serveru není v Books Online do velké míry zdokumentováno, ale různí členové týmu SQL Server učinili v průběhu let několik obecných poznámek, včetně skutečnosti, že neomezené skenování má tendenci začínat načítáním stránky. zámky, zatímco menší operace mají tendenci začínat zámky řádků.
Optimalizátor dotazů zpřístupňuje úložišti některé informace, včetně odhadů mohutnosti, interních rad pro úroveň izolace a granularity zamykání, které interní optimalizace lze bezpečně použít a tak dále. Tyto podrobnosti opět nejsou v Books Online zdokumentovány. Úložný modul nakonec používá různé informace, aby rozhodl, které zámky jsou vyžadovány za běhu a s jakou granularitou by měly být použity.
Jako vedlejší poznámku a při vědomí, že mluvíme o dotazu spouštěném pod výchozí úrovní izolace potvrzené transakce pro čtení zamykáním, si všimněte, že zámky řádků provedené bez náznaku granularity se v tomto případě nezvýší na zámek tabulky. Je to proto, že normálním chováním při čtení potvrzeno je uvolnit předchozí zámek těsně před získáním dalšího zámku, což znamená, že v každém konkrétním okamžiku bude zadržen pouze jeden sdílený zámek řádku (s přidruženými zámky sdílenými záměry vyšší úrovně). Vzhledem k tomu, že počet souběžně držených zámků řádků nikdy nedosáhne prahové hodnoty, nedojde k pokusu o eskalaci zámku.
Řešení OFFSET Single Medián
Test výkonu pro výpočet jediného mediánu používá jinou sadu vzorových dat, opět reprodukovaných z Aaronova dřívějšího článku. Skript níže vytvoří tabulku s deseti miliony řádků pseudonáhodných dat:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
OFFSET řešení je:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Plán po provedení je:

Tento dotaz se provede za 910 ms v průměru na mém testovacím stroji. Výkon se nezmění, pokud PAGLOCK je přidána nápověda, ale důvodem není to, co si možná myslíte…
Analýza zamykání jednoho mediánu
Možná očekáváte, že úložný modul si stejně vybere sdílené zámky na úrovni stránky, kvůli skenování seskupeného indexu, což vysvětluje, proč PAGLOCK nápověda nemá žádný účinek. Sledování uzamčení přijatých během provádění tohoto dotazu ve skutečnosti odhalí, že nejsou přijaty žádné sdílené zámky (S), při jakékoli granularitě . Jedinými přijatými zámky jsou sdílené záměry (IS) na úrovni objektu a stránky.
Vysvětlení tohoto chování má dvě části. První věc, kterou si všimnete, je, že Clustered Index Scan je v plánu provádění pod nejvyšším operátorem. To má důležitý vliv na odhady mohutnosti, jak ukazuje plán před provedením (odhadovaný):

OFFSET a FETCH klauzule v dotazu odkazují na výraz a proměnnou, takže optimalizátor dotazů odhadne počet řádků, které budou potřeba za běhu. Standardní odhad pro Top je sto řádků. To je samozřejmě hrozný odhad, ale stačí to k tomu, abyste přesvědčili modul úložiště, aby se uzamkl na úrovni granularity řádků místo na úrovni stránky.
Pokud zakážeme efekt „cíl řádku“ operátoru Top pomocí dokumentovaného příznaku trasování 4138, odhadovaný počet řádků při skenování se změní na deset milionů (což je stále špatně, ale v opačném směru). To stačí ke změně rozhodnutí o granularitě zamykání úložiště, takže se použijí sdílené zámky na úrovni stránky (poznámka, nikoli zámky sdílené záměrem):
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1
OPTION (QUERYTRACEON 4138); -- NEW!
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Odhadovaný plán provádění vytvořený pod příznakem trasování 4138 je:

Vrátíme-li se k hlavnímu příkladu, stořádkový odhad kvůli uhádnutému cíli řádku znamená, že se modul úložiště rozhodne uzamknout na úrovni řádku. Zámky sdíleného záměru (IS) však pozorujeme pouze na úrovni tabulky a stránky. Tyto zámky vyšší úrovně by byly docela normální, kdybychom viděli sdílené (S) zámky na úrovni řádků, kam se tedy poděly?
Odpověď je, že modul úložiště obsahuje další optimalizaci, která může za určitých okolností přeskočit sdílené zámky na úrovni řádků. Když je tato optimalizace použita, budou stále získávány zámky sdílené záměrem vyšší úrovně.
Abychom to shrnuli, pro dotaz s jedním mediánem:
- Použití proměnné a výrazu v
OFFSETklauzule znamená, že optimalizátor odhadne mohutnost. - Nízký odhad znamená, že se o strategii zamykání na úrovni řádků rozhodne modul úložiště.
- Interní optimalizace znamená, že zámky S na úrovni řádků jsou za běhu přeskočeny a ponechávají pouze zámky IS na úrovni stránky a objektu.
Jediný mediánový dotaz by měl stejný problém s výkonem zamykání řádků jako seskupený medián (kvůli nepřesnému odhadu optimalizátoru dotazů), ale byl uložen samostatnou optimalizací úložiště, která vedla k tomu, že byly použity pouze zámky stránek a tabulek sdílených záměrem. za běhu.
Znovu navštívený test seskupeného mediánu
Možná se divíte, proč Clustered Index Seek v testu seskupeného mediánu nevyužil stejnou optimalizaci úložiště k přeskočení sdílených zámků na úrovni řádků. Proč bylo použito tolik zámků sdílených řádků, takže PAGLOCK nutná nápověda?
Krátká odpověď je, že tato optimalizace není dostupná pro INSERT...SELECT dotazy. Pokud spustíme SELECT samostatně (tj. bez zápisu výsledků do tabulky) a bez PAGLOCK tip, optimalizace přeskakování zámku řádku je použito:
DECLARE @s datetime2 = SYSUTCDATETIME();
--DECLARE @Result AS table
--(
-- SalesPerson integer PRIMARY KEY,
-- Median float NOT NULL
--);
--INSERT @Result
-- (SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());
Používají se pouze zámky sdíleného záměru (IS) na úrovni tabulky a stránky a výkon se zvýší na stejnou úroveň, jako když použijeme PAGLOCK náznak. Toto chování v dokumentaci samozřejmě nenajdete a může se kdykoli změnit. Přesto je dobré si toho být vědom.
V případě, že by vás to zajímalo, příznak trasování 4138 nemá v tomto případě žádný vliv na volbu uzamykací granularity modulu úložiště, protože odhadovaný počet řádků při hledání je příliš nízký (na iteraci aplikace), i když je cíl řádku deaktivován.
Před vyvozením závěrů o výkonu dotazu nezapomeňte zkontrolovat počet a typ zámků, které při provádění provádí. Přestože SQL Server obvykle volí „správnou“ granularitu, jsou chvíle, kdy se může něco pokazit, někdy s dramatickými dopady na výkon.