Nejrychlejší způsob, jak vypočítat medián, používá SQL Server 2012 OFFSET rozšíření na ORDER BY doložka. Další nejrychlejší řešení, které běží těsně za sekundu, používá (možná vnořený) dynamický kurzor, který funguje na všech verzích. Tento článek se zabývá běžným ROW_NUMBER před rokem 2012 řešení problému výpočtu mediánu, abyste viděli, proč funguje méně dobře a co lze udělat, aby to šlo rychleji.
Test s jedním mediánem
Ukázková data pro tento test se skládají z jediné tabulky s deseti miliony řádků (reprodukované z původního článku Aarona Bertranda):
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); Řešení OFFSET
Chcete-li nastavit benchmark, zde je řešení OFFSET pro SQL Server 2012 (nebo novější) vytvořené Peterem Larssonem:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - (@Count % 2)) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Dotaz na počítání řádků v tabulce je zakomentován a nahrazen pevně zakódovanou hodnotou, aby se mohl soustředit na výkon základního kódu. Při vypnutém shromažďování teplé mezipaměti a plánu provádění tento dotaz běží po dobu 910 ms v průměru na mém testovacím stroji. Prováděcí plán je uveden níže:

Jako vedlejší poznámku je zajímavé, že tento středně složitý dotaz se kvalifikuje pro triviální plán:
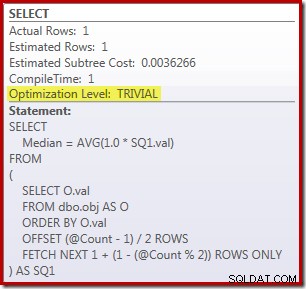
Řešení ROW_NUMBER
U systémů se systémem SQL Server 2008 R2 nebo starším používá nejvýkonnější alternativní řešení dynamický kurzor, jak bylo zmíněno dříve. Pokud to nemůžete (nebo nechcete) považovat za možnost, je přirozené uvažovat o emulaci 2012 OFFSET plán provádění pomocí ROW_NUMBER .
Základní myšlenkou je očíslovat řádky ve vhodném pořadí a poté filtrovat pouze jeden nebo dva řádky potřebné k výpočtu mediánu. Existuje několik způsobů, jak to napsat v Transact SQL; kompaktní verze, která zachycuje všechny klíčové prvky, je následující:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
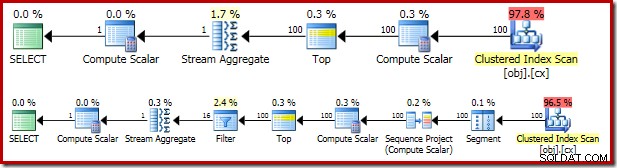
Výsledný plán provádění je velmi podobný OFFSET verze:

Stojí za to se postupně podívat na každého z operátorů plánu, abyste jim plně porozuměli:
- Operátor segmentu je v tomto plánu nadbytečný. Bude vyžadováno, pokud
ROW_NUMBERfunkce hodnocení mělaPARTITION BYklauzule, ale není tomu tak. I tak zůstává ve finálním plánu. - Projekt Sequence přidá do proudu řádků vypočítané číslo řádku.
- Výpočetní skalár definuje výraz spojený s potřebou implicitně převést
valsloupec na číselný, takže jej lze vynásobit konstantou literál1.0v dotazu. Tento výpočet je odložen, dokud jej nebude potřebovat pozdější operátor (což je shodou okolností Stream Aggregate). Tato optimalizace za běhu znamená, že implicitní převod se provádí pouze pro dva řádky zpracované agregátem Stream Aggregate, nikoli pro 5 000 001 řádků uvedených pro výpočetní skalár. - Operátor Top je zaveden optimalizátorem dotazů. Rozpozná, že maximálně pouze první
(@Count + 2) / 2řádky jsou vyžadovány dotazem. Mohli jsme přidatTOP ... ORDER BYv poddotazu, aby to bylo explicitní, ale tato optimalizace to z velké části dělá zbytečným. - Filtr implementuje podmínku v
WHEREklauzule, která odfiltruje všechny řádky kromě dvou „středních“ potřebných k výpočtu mediánu (na této podmínce je také založeno zavedení Top). - Stream Aggregate vypočítá
SUMaCOUNTze dvou středních řad. - Konečný výpočetní skalár vypočítá průměr ze součtu a počtu.
Rovný výkon
V porovnání s OFFSET můžeme očekávat, že další operátory Segment, Sequence Project a Filter budou mít nepříznivý vliv na výkon. Stojí za to věnovat chvíli porovnání odhadu náklady na dva plány:
OFFSET plán má odhadované náklady 0,0036266 jednotky, zatímco ROW_NUMBER plán se odhaduje na 0,0036744 Jednotky. Toto jsou velmi malá čísla a mezi nimi je malý rozdíl.
Je tedy možná překvapivé, že ROW_NUMBER dotaz ve skutečnosti trvá 4000 ms v průměru ve srovnání s 910 ms průměr pro OFFSET řešení. Část tohoto nárůstu lze jistě vysvětlit režií operátorů zvláštního plánu, ale čtyřnásobek se zdá být přehnaný. Musí toho být víc.
Pravděpodobně jste si také všimli, že odhady mohutnosti pro oba výše uvedené odhadované plány jsou docela beznadějně špatné. To je způsobeno účinkem operátorů Top, které mají jako limity počtu řádků výraz odkazující na proměnnou. Optimalizátor dotazů nemůže vidět obsah proměnných v době kompilace, takže se uchýlí k výchozímu odhadu 100 řádků. Oba plány ve skutečnosti za běhu narazí na 5 000 001 řádků.
To vše je velmi zajímavé, ale přímo to nevysvětluje, proč ROW_NUMBER dotaz je více než čtyřikrát pomalejší než OFFSET verze. Koneckonců, odhad mohutnosti 100 řádků je v obou případech stejně chybný.
Zlepšení výkonu řešení ROW_NUMBER
V mém předchozím článku jsme viděli, jak je výkon seskupeného mediánu OFFSET test lze téměř zdvojnásobit jednoduchým přidáním PAGLOCK náznak. Tato nápověda přepíše normální rozhodnutí úložiště úložiště získat a uvolnit sdílené zámky na úrovni granularity řádků (kvůli nízké očekávané mohutnosti).
Jako další připomenutí, PAGLOCK nápověda byla zbytečná v jediném mediánu OFFSET test kvůli samostatné interní optimalizaci, která může přeskočit sdílené zámky na úrovni řádků, což má za následek pouze malý počet zámků sdílených záměrem na úrovni stránky.
Můžeme očekávat ROW_NUMBER řešení s jediným mediánem těžit ze stejné vnitřní optimalizace, ale ne. Sledování aktivity zamykání při ROW_NUMBER dotazu, vidíme více než půl milionu jednotlivých sdílených zámků na úrovni řádků je vzat a propuštěn.
Nyní tedy víme, v čem je problém, můžeme zlepšit výkon zamykání stejným způsobem jako dříve:buď pomocí PAGLOCK náznak granularity zámku nebo zvýšením odhadu mohutnosti pomocí dokumentovaného příznaku trasování 4138.
Zakázání "cíle řádku" pomocí příznaku trasování je méně uspokojivým řešením z několika důvodů. Za prvé, je účinný pouze v SQL Server 2008 R2 nebo novějším. Nejspíše bychom preferovali OFFSET řešení v SQL Server 2012, takže to účinně omezuje opravu příznaku trasování pouze na SQL Server 2008 R2. Za druhé, použití příznaku trasování vyžaduje oprávnění na úrovni správce, pokud není použito prostřednictvím průvodce plánem. Třetím důvodem je, že deaktivace cílů řádků pro celý dotaz může mít další nežádoucí účinky, zejména ve složitějších plánech.
Naproti tomu PAGLOCK nápověda je účinná, dostupná ve všech verzích SQL Serveru bez jakýchkoliv zvláštních oprávnění a nemá žádné větší vedlejší účinky kromě granularity zamykání.
Použití PAGLOCK nápověda k ROW_NUMBER dotaz dramaticky zvyšuje výkon:od 4000 ms až 1500 ms:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK) -- New!
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
1500 ms výsledek je stále výrazně pomalejší než 910 ms pro OFFSET řešení, ale alespoň je nyní na stejném hřišti. Zbývající rozdíl ve výkonu je jednoduše způsoben prací navíc v prováděcím plánu:

V OFFSET plánu je zpracováno pět milionů řádků až k vrcholu (s výrazy definovanými na výpočetním skaláru, jak bylo uvedeno výše). V ROW_NUMBER stejný počet řádků musí zpracovat segment, sekvenční projekt, horní část a filtr.