Obecná strategie, kterou databázový stroj SQL Server používá k udržení synchronizovaného indexovaného pohledu se svými základními tabulkami – kterou jsem podrobněji popsal ve svém posledním příspěvku – je provádět přírůstkovou údržbu pohledu, kdykoli dojde k operaci změny dat u jedné z tabulek, na které pohled odkazuje. Obecně řečeno, myšlenka je:
- Shromažďujte informace o změnách základní tabulky
- Použijte projekce, filtry a spojení definované v pohledu
- Agregujte změny podle seskupeného klíče indexovaného zobrazení
- Rozhodněte, zda má každá změna vést k vložení, aktualizaci nebo odstranění do zobrazení
- Vypočítejte hodnoty, které chcete v zobrazení změnit, přidat nebo odebrat
- Použijte změny zobrazení
Nebo ještě stručněji (i když s rizikem hrubého zjednodušení):
- Vypočítejte inkrementální efekty zobrazení původních úprav dat;
- Použijte tyto změny na zobrazení
Toto je obvykle mnohem efektivnější strategie než přebudování celého pohledu po každé změně základních dat (bezpečná, ale pomalá možnost), ale spoléhá se na to, že logika přírůstkové aktualizace je správná pro každou myslitelnou změnu dat, proti každé možné definici indexovaného pohledu.
Jak název napovídá, tento článek se zabývá zajímavým případem, kdy se logika přírůstkové aktualizace porouchá, což má za následek poškozený indexovaný pohled, který již neodpovídá podkladovým datům. Než se dostaneme k samotné chybě, musíme rychle zkontrolovat skalární a vektorové agregáty.
Skalární a vektorové agregáty
V případě, že tento pojem neznáte, existují dva typy kameniva. Agregát, který je spojen s klauzulí GROUP BY (i když je seznam seskupit podle prázdný), se nazývá vektorový agregát . Agregát bez klauzule GROUP BY je známý jako skalární agregát .
Zatímco u vektorového agregátu je zaručeno, že vytvoří jeden výstupní řádek pro každou skupinu přítomnou v sadě dat, skalární agregáty jsou trochu jiné. Skalární agregáty vždy vytvořit jeden výstupní řádek, i když je vstupní sada prázdná.
Příklad agregace vektorů
Následující příklad AdventureWorks počítá dva vektorové agregáty (součet a počet) na prázdné vstupní sadě:
-- There are no TransactionHistory records for ProductID 848 -- Vector aggregate produces no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID;
Tyto dotazy vytvářejí následující výstup (bez řádků):

Výsledek je stejný, pokud nahradíme klauzuli GROUP BY prázdnou sadou (vyžaduje SQL Server 2008 nebo novější):
-- Equivalent vector aggregate queries with -- an empty GROUP BY column list -- (SQL Server 2008 and later required) -- Still no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY (); SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY ();
Prováděcí plány jsou v obou případech rovněž totožné. Toto je plán provádění dotazu na počet:
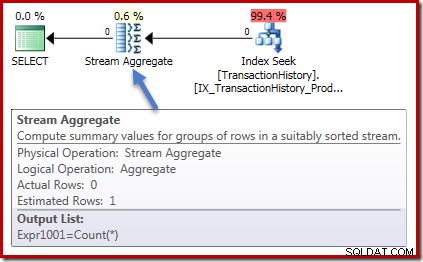
Nula řádků vstup do Stream Aggregate a nula řádků ven. Plán realizace součtu vypadá takto:

Opět nula řádků do agregace a nula řádků ven. Zatím všechny dobré jednoduché věci.
Skalární agregáty
Nyní se podívejte, co se stane, když úplně odstraníme klauzuli GROUP BY z dotazů:
-- Scalar aggregate (no GROUP BY clause) -- Returns a single output row from an empty input SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848;
Místo prázdného výsledku vytvoří agregace COUNT nulu a SUM vrátí NULL:
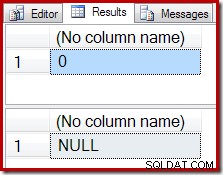
Plán provádění počtu potvrzuje, že nula vstupních řádků produkuje jeden řádek výstupu z agregátu streamů:
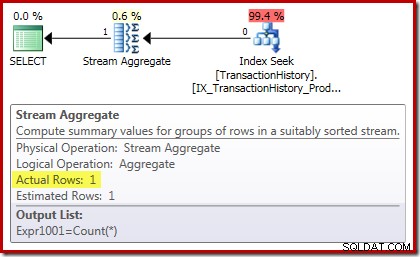
Plán realizace částky je ještě zajímavější:
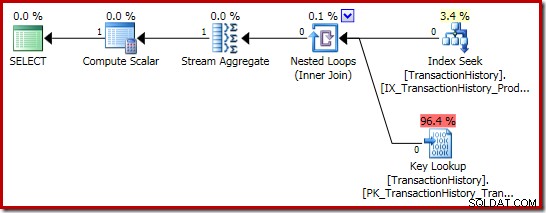
Vlastnosti Stream Aggregate ukazují, že se kromě součtu, o který jsme požádali, vypočítává souhrnný počet:
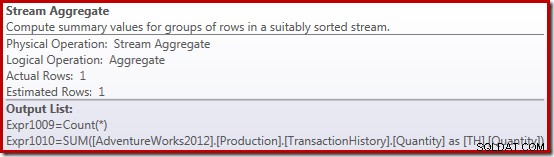
Nový operátor Compute Scalar se používá k vracení NULL, pokud je počet řádků přijatých agregátem Stream Aggregate nula, jinak vrací součet zjištěných dat:
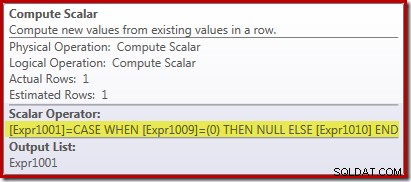
Může se to zdát trochu divné, ale funguje to takto:
- Vektorový souhrn nulových řádků vrátí nula řádků;
- Skalární agregát vždy vytváří přesně jeden řádek výstupu, a to i pro prázdný vstup;
- Skalární počet nulových řádků je nula; a
- Skalární součet nula řádků je NULL (nikoli nula).
Pro naše současné účely je důležité, že skalární agregáty vždy produkují jeden řádek výstupu, i když to znamená vytvořit jeden z ničeho. Skalární součet nulových řádků je také NULL, nikoli nula.
Mimochodem, všechna tato chování jsou „správná“. Věci jsou tak, jak jsou, protože standard SQL původně nedefinoval chování skalárních agregátů a ponechal to na implementaci. SQL Server zachovává svou původní implementaci z důvodů zpětné kompatibility. Vektorové agregáty měly vždy dobře definované chování.
Indexovaná zobrazení a vektorová agregace
Nyní zvažte jednoduchý indexovaný pohled zahrnující několik (vektorových) agregátů:
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
GroupSum = SUM(T1.Value),
RowsInGroup = COUNT_BIG(*)
FROM dbo.T1 AS T1
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); Následující dotazy zobrazují obsah základní tabulky, výsledek dotazování indexovaného zobrazení a výsledek spuštění dotazu zobrazení v tabulce, která je podkladem zobrazení:
-- Sample data SELECT * FROM dbo.T1 AS T1; -- Indexed view contents SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Underlying view query results SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
Výsledky jsou:
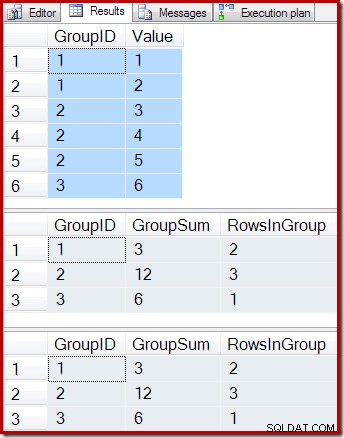
Jak se očekávalo, indexované zobrazení a základní dotaz vracejí přesně stejné výsledky. Výsledky zůstanou synchronizované i po všech možných změnách základní tabulky T1. Abychom si připomněli, jak to všechno funguje, zvažte jednoduchý případ přidání jednoho nového řádku do základní tabulky:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); Plán provádění pro tuto vložku obsahuje veškerou logiku potřebnou k udržení synchronizace indexovaného zobrazení:
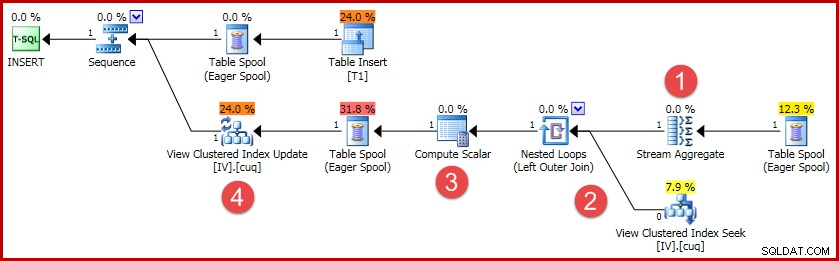
Hlavní aktivity v plánu jsou:
- Stream Aggregate počítá změny podle klíče indexovaného zobrazení
- Vnější spojení s pohledem propojí souhrn změn s řádkem cílového pohledu, pokud existuje
- Výpočetní skalár rozhodne, zda bude každá změna vyžadovat vložení, aktualizaci nebo odstranění zobrazení, a vypočítá potřebné hodnoty.
- Operátor aktualizace zobrazení fyzicky provádí každou změnu seskupeného indexu zobrazení.
Existují určité rozdíly v plánu pro různé operace změn oproti základní tabulce (např. aktualizace a mazání), ale základní myšlenka zachování synchronizace zobrazení zůstává stejná:agregujte změny podle klíče zobrazení, vyhledejte řádek zobrazení, pokud existuje, a poté proveďte kombinace operací vložení, aktualizace a odstranění v indexu zobrazení podle potřeby.
Bez ohledu na to, jaké změny provedete v základní tabulce v tomto příkladu, indexované zobrazení zůstane správně synchronizované – výše uvedené dotazy NOEXPAND a EXPAND VIEWS vždy vrátí stejnou sadu výsledků. Takto by věci měly vždy fungovat.
Indexovaná zobrazení a skalární agregace
Nyní zkuste tento příklad, kde indexovaný pohled používá skalární agregaci (v pohledu není klauzule GROUP BY):
DROP VIEW dbo.IV;
DROP TABLE dbo.T1;
GO
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Toto je dokonale legální indexovaný pohled; při jeho vytváření nedochází k žádným chybám. Existuje však jedno vodítko, že možná děláme něco trochu divného:když přijde čas zhmotnit pohled vytvořením požadovaného jedinečného seskupeného indexu, neexistuje žádný zřejmý sloupec, který by bylo možné vybrat jako klíč. Normálně bychom samozřejmě zvolili seskupení sloupců z klauzule GROUP BY pohledu.
Výše uvedený skript libovolně vybere sloupec NumRows. Ta volba není důležitá. Neváhejte a vytvořte jedinečný seskupený index, ať už si vyberete. Zobrazení bude vždy obsahovat přesně jeden řádek kvůli skalárním agregátům, takže není šance na jedinečné porušení klíče. V tomto smyslu je výběr klíče indexu zobrazení nadbytečný, ale přesto nutný.
Opětovným použitím testovacích dotazů z předchozího příkladu můžeme vidět, že indexované zobrazení funguje správně:
SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
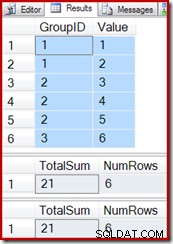
Vložení nového řádku do základní tabulky (jako jsme to udělali s indexovaným zobrazením vektorové agregace) také nadále funguje správně:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); Prováděcí plán je podobný, ale ne zcela identický:
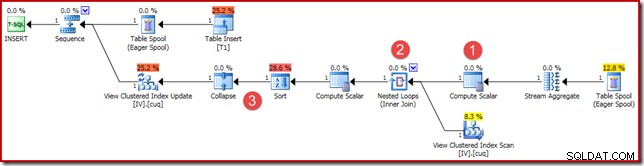
Hlavní rozdíly jsou:
- Tento nový výpočetní skalár je zde ze stejných důvodů, jako když jsme dříve porovnávali výsledky vektorové a skalární agregace:zajišťuje, že je vrácen součet NULL (místo nuly), pokud agregace pracuje s prázdnou množinou. Toto je požadované chování pro skalární součet bez řádků.
- Dříve zobrazené vnější spojení bylo nahrazeno vnitřním spojením. V indexovaném zobrazení bude vždy přesně jeden řádek (kvůli skalární agregaci), takže není potřeba vnější spojení k testování, zda se řádek zobrazení shoduje nebo ne. Jeden řádek v zobrazení vždy představuje celou sadu dat. Toto vnitřní spojení nemá žádný predikát, takže se technicky jedná o křížové spojení (k tabulce se zaručeným jedním řádkem).
- Operátory Sort a Collapse jsou přítomny z technických důvodů, které jsem popsal v mém předchozím článku o údržbě indexovaného zobrazení. Nemají vliv na správné fungování údržby indexovaného zobrazení zde.
Ve skutečnosti lze v tomto příkladu úspěšně provést mnoho různých typů operací změny dat proti základní tabulce T1; efekty se správně projeví v indexovaném zobrazení. Při zachování správného indexovaného zobrazení lze provést všechny následující operace změn vůči základní tabulce:
- Smažte stávající řádky
- Aktualizujte stávající řádky
- Vložit nové řádky
Může se to zdát jako úplný seznam, ale není.
Chyba odhalena
Problém je poměrně jemný a souvisí (jak byste měli očekávat) s různým chováním vektorových a skalárních agregátů. Klíčovými body je, že skalární agregát vždy vytvoří výstupní řádek, i když na svém vstupu nepřijme žádné řádky a skalární součet prázdné množiny je NULL, nikoli nula.
Chceme-li způsobit problém, vše, co musíme udělat, je vložit nebo odstranit žádné řádky v základní tabulce.
Toto prohlášení není tak šílené, jak by se mohlo na první pohled zdát.
Jde o to, že dotaz pro vložení nebo odstranění, který neovlivňuje žádné řádky základní tabulky, přesto aktualizuje zobrazení, protože skalární Stream Aggregate v části údržby indexovaného zobrazení plánu dotazů vytvoří výstupní řádek, i když je prezentován bez vstupu. Compute Scalar, který následuje za Stream Aggregate, také vygeneruje součet NULL, když je počet řádků nula.
Následující skript ukazuje chybu v akci:
-- So we can undo BEGIN TRANSACTION; -- Show the starting state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- A table variable intended to hold new base table rows DECLARE @NewRows AS table (GroupID integer NOT NULL, Value integer NOT NULL); -- Insert to the base table (no rows in the table variable!) INSERT dbo.T1 SELECT NR.GroupID,NR.Value FROM @NewRows AS NR; -- Show the final state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Undo the damage ROLLBACK TRANSACTION;
Výstup tohoto skriptu je uveden níže:
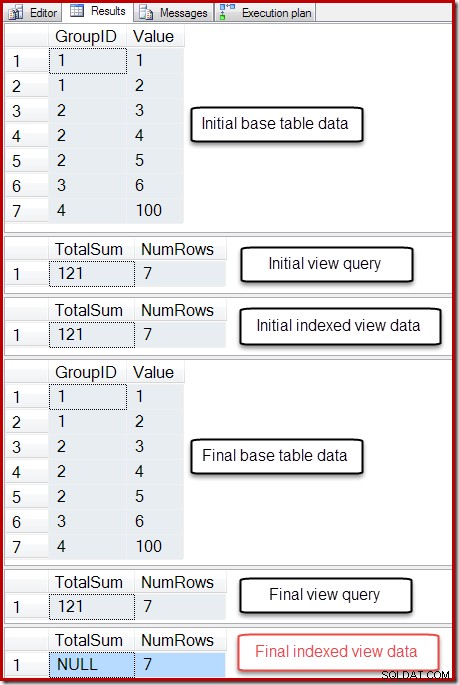
Konečný stav sloupce Celkový součet indexovaného zobrazení neodpovídá základnímu dotazu zobrazení nebo datům základní tabulky. Součet NULL poškodil zobrazení, což lze potvrdit spuštěním DBCC CHECKTABLE (v indexovaném zobrazení).
Prováděcí plán odpovědný za korupci je uveden níže:
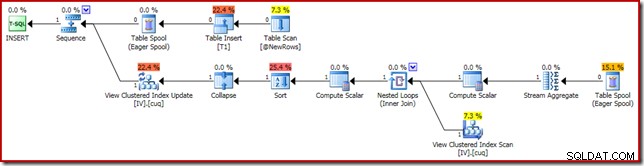
Přiblížení zobrazuje vstup s nulovými řádky do agregátu streamů a výstup s jedním řádkem:
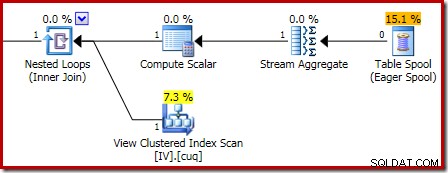
Pokud chcete vyzkoušet výše uvedený skript poškození s odstraněním namísto vložení, zde je příklad:
-- No rows match this predicate DELETE dbo.T1 WHERE Value BETWEEN 10 AND 50;
Odstranění neovlivní žádné řádky základní tabulky, ale přesto změní sloupec součtu indexovaného zobrazení na hodnotu NULL.
Zobecnění chyby
Pravděpodobně můžete přijít s libovolným počtem vložení a odstranění dotazů základní tabulky, které neovlivňují žádné řádky a způsobují toto poškození indexovaného zobrazení. Stejný základní problém se však týká širší třídy problémů, než jsou jen vkládání a mazání, které neovlivňují žádné řádky základní tabulky.
Je například možné vytvořit stejné poškození pomocí vložky, která dělá přidat řádky do základní tabulky. Základní složkou je, že žádné přidané řádky by neměly splňovat podmínky pro zobrazení . To bude mít za následek prázdný vstup do Stream Aggregate a výstup řádku NULL způsobující poškození z následujícího výpočetního skaláru.
Jedním ze způsobů, jak toho dosáhnout, je zahrnout do pohledu klauzuli WHERE, která odmítá některé řádky základní tabulky:
ALTER VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
-- New!
T1.GroupID BETWEEN 1 AND 3;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Vzhledem k novému omezení ID skupin zahrnutých v zobrazení následující vložení přidá řádky do základní tabulky, ale přesto poškodí indexovaný pohled a bude mít součet NULL:
-- So we can undo
BEGIN TRANSACTION;
-- Show the starting state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- The added row does not qualify for the view
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100);
-- Show the final state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- Undo the damage
ROLLBACK TRANSACTION; Výstup ukazuje nyní známé poškození indexu:
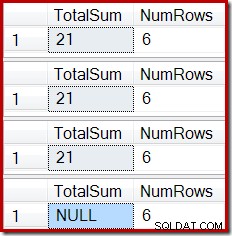
Podobný efekt lze vytvořit pomocí pohledu, který obsahuje jedno nebo více vnitřních spojení. Dokud budou řádky přidané do základní tabulky odmítnuty (například tím, že se nepodaří připojit), nebude Stream Aggregate přijímat žádné řádky, Compute Scalar vygeneruje součet NULL a indexovaný pohled bude pravděpodobně poškozen.
Poslední myšlenky
Tento problém se u aktualizačních dotazů nevyskytuje (alespoň pokud mohu říci), ale zdá se, že jde spíše o náhodu než o návrh – problematický Stream Aggregate je stále přítomen v potenciálně zranitelných plánech aktualizací, ale výpočetní skalár, který generuje součet NULL není přidán (nebo možná optimalizován). Dejte mi prosím vědět, pokud se vám podaří chybu reprodukovat pomocí aktualizačního dotazu.
Dokud nebude tato chyba opravena (nebo možná nebudou skalární agregáty v indexovaných zobrazeních povoleny), buďte velmi opatrní při používání agregátů v indexovaném zobrazení bez klauzule GROUP BY.
Tento článek byl vyvolán položkou Connect odeslanou Vladimírem Moldovaněnkem, který byl tak laskav a zanechal komentář k mému starému příspěvku na blogu (který se týká jiného poškození indexovaného zobrazení způsobeného prohlášením MERGE). Vladimir používal skalární agregáty v indexovaném zobrazení ze zdravých důvodů, takže nebuďte příliš rychlí a neposuzujte tuto chybu jako okrajový případ, se kterým se v produkčním prostředí nikdy nesetkáte! Děkuji Vladimírovi za upozornění na jeho položku Connect.