
Tento měsíc T-SQL Tuesday pořádá Mike Donnelly (@SQLMD) a shrnuje téma takto:
Téma tohoto měsíce je přímočaré, ale velmi otevřené. Musíte se naučit něco nového a pak napsat blogový příspěvek, který to vysvětlí.No, od chvíle, kdy Mike oznámil téma, jsem se ve skutečnosti nechystal učit se nic nového, a jak se blížil víkend a já věděl, že pondělí na mě zaútočí s povinností poroty, myslel jsem, že to budu muset sedět. měsíc.
Potom mě Martin Smith naučil něco, co jsem buď nikdy nevěděl, nebo jsem věděl už dávno, ale zapomněl jsem (někdy nevíte, co nevíte, a někdy si nemůžete vzpomenout na to, co jste nikdy nevěděli a co nemůžete pamatovat). Moje vzpomínka byla, že jsem změnil sloupec z NOT NULL na NULL měl by být operace pouze s metadaty, přičemž zápisy na kteroukoli stránku budou odloženy, dokud nebude tato stránka aktualizována z jiných důvodů, protože NULL bitmapa by ve skutečnosti nemusela existovat, dokud se alespoň jeden řádek nestane NULL .
U stejného příspěvku mi @ypercube také připomněl tento relevantní citát z Books Online (překlep a vše):
Změna sloupce z NOT NULL na NULL není podporována jako online operace, když změněný sloupec odkazuje indexy bez klastrů.„Není online operace“ lze interpretovat jako „není operace pouze s metadaty“ – což znamená, že se ve skutečnosti bude jednat o operaci velikosti dat (čím větší je váš index, tím déle to bude trvat).
Rozhodl jsem se to dokázat docela jednoduchým (ale zdlouhavým) experimentem proti konkrétnímu cílovému sloupci, který má být převeden z NOT NULL na NULL . Vytvořil bych 3 tabulky, všechny s seskupeným primárním klíčem, ale každou s jiným neshlukovaným indexem. Jeden by měl cílový sloupec jako klíčový sloupec, druhý jako INCLUDE a třetí by vůbec neodkazoval na cílový sloupec.
Zde jsou moje tabulky a způsob, jakým jsem je naplnil:
CREATE TABLE dbo.test1
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t1 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix1 ON dbo.test1(b,c);
GO
CREATE TABLE dbo.test2
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t2 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix2 ON dbo.test2(b) INCLUDE(c);
GO
CREATE TABLE dbo.test3
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t3 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix3 ON dbo.test3(b);
GO
INSERT dbo.test1(a,b,c) -- repeat for test2 / test3
SELECT n1, n2, ABS(n2)-ABS(n1)
FROM
(
SELECT TOP (100000) s1.[object_id], s2.[object_id]
FROM master.sys.all_objects AS s1
CROSS JOIN master.sys.all_objects AS s2
GROUP BY s1.[object_id], s2.[object_id]
) AS n(n1, n2);
Každá tabulka měla 100 000 řádků, seskupené indexy měly 310 stránek a neseskupené indexy měly buď 272 stránek (test1 a test2 ) nebo 174 stránek (test3 ). (Tyto hodnoty lze snadno získat z sys.dm_db_index_physical_stats .)
Dále jsem potřeboval jednoduchý způsob, jak zachytit operace, které byly protokolovány na úrovni stránky – zvolil jsem sys.fn_dblog() , i když jsem mohl sáhnout hlouběji a podívat se přímo na stránky. Neobtěžoval jsem se pohrávat si s hodnotami LSN, které se mají předat funkci, protože jsem to neprovozoval ve výrobě a moc se nestaral o výkon, takže po testech jsem výsledky funkce vyřadil, s vyloučením jakýchkoli dat, která byl přihlášen před ALTER TABLE operace.
-- establish an exclusion set SELECT * INTO #x FROM sys.fn_dblog(NULL, NULL);
Nyní jsem mohl spustit své testy, které byly mnohem jednodušší než nastavení.
ALTER TABLE dbo.test1 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test2 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test3 ALTER COLUMN c BIGINT NULL;
Nyní jsem mohl prozkoumat operace, které byly zaznamenány v každém případě:
SELECT AllocUnitName, [Operation], Context, c = COUNT(*)
FROM
(
SELECT * FROM sys.fn_dblog(NULL, NULL)
WHERE [Operation] = N'LOP_FORMAT_PAGE'
AND AllocUnitName LIKE N'dbo.test%'
EXCEPT
SELECT * FROM #x
) AS x
GROUP BY AllocUnitName, [Operation], Context
ORDER BY AllocUnitName, [Operation], Context; Zdá se, že výsledky naznačují, že každá listová stránka neseskupeného indexu je dotčena v případech, kdy byl cílový sloupec v indexu jakkoli zmíněn, ale k takovým operacím nedochází v případě, kdy cílový sloupec není uveden v žádném neklastrovaný index:
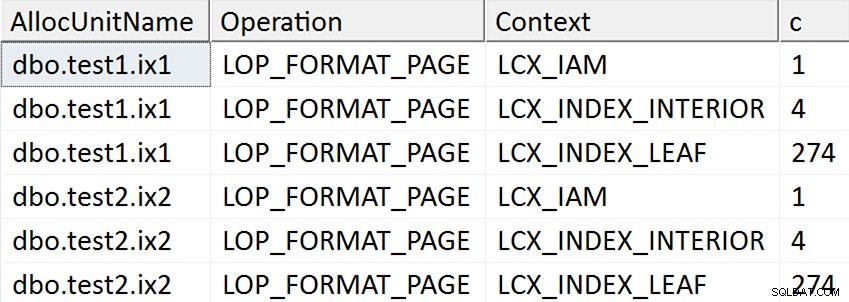
Ve skutečnosti jsou v prvních dvou případech přiděleny nové stránky (můžete to ověřit pomocí DBCC IND , jak to udělal Spörri ve své odpovědi), takže operace může probíhat online, ale to neznamená, že je rychlá (protože stále musí vypsat kopii všech těchto dat a vytvořit NULL změna bitmapy jako součást zápisu každé nové stránky a zaznamenat veškerou tuto aktivitu).
Myslím, že většina lidí by měla podezření, že změna sloupce z NOT NULL na NULL by byla ve všech scénářích pouze metadata, ale zde jsem ukázal, že to neplatí, pokud na sloupec odkazuje index bez klastrů (a podobné věci se stávají, ať už se jedná o klíč nebo INCLUDE sloupec). Možná lze tuto operaci také vynutit, aby byla ONLINE v Azure SQL Database dnes, nebo to bude možné v příští hlavní verzi? To nezbytně neurychlí skutečné fyzické operace, ale ve výsledku to zabrání zablokování.
Ten scénář jsem netestoval (a analýza, zda je skutečně online, je v Azure každopádně těžší), ani jsem ho netestoval na hromadě. Něco, k čemu se mohu vrátit v budoucím příspěvku. Mezitím si dávejte pozor na jakékoli domněnky, které byste mohli učinit o operacích pouze s metadaty.