Lidé se ptají, zda by měli udělat vše, co je v jejich silách, aby výjimkám zabránili, nebo nechat systém, aby se s nimi vypořádal. Viděl jsem několik diskuzí, kde lidé debatují o tom, zda by měli udělat, co mohou, aby zabránili výjimce, protože zpracování chyb je „drahé“. Není pochyb o tom, že zpracování chyb není bezplatné, ale předpověděl bych, že porušení omezení je přinejmenším stejně účinné jako kontrola potenciálního porušení jako první. To se může u klíčového porušení lišit od například porušení statického omezení, ale v tomto příspěvku se zaměřím na první z nich.
Primární přístupy, které lidé používají k řešení výjimek, jsou:
- Prostě nechte motor, aby to zvládl, a případnou výjimku zašlete zpět volajícímu.
- Použijte
BEGIN TRANSACTIONaROLLBACKif@@ERROR <> 0. - Použijte
TRY/CATCHpomocíROLLBACKvCATCHblok (SQL Server 2005+).
A mnozí volí přístup, že by měli nejprve zkontrolovat, zda nedopustí porušení pravidel, protože se zdá čistší zvládnout duplikát sami, než k tomu nutit motor. Moje teorie je, že byste měli důvěřovat, ale prověřovat; zvažte například tento přístup (většinou pseudokód):
POKUD NEEXISTUJE ([řádek, který by způsobil porušení zásad]) BEGIN BEGIN ZKUSTE ZAČÁTE TRANSACTION; VLOŽIT ()... POTVRDIT TRANSAKCI; KONEC ZKUSTE ZAČÁTEK ZACHYCENÍ -- no, stejně jsme se dopustili porušení; -- Myslím, že byl vložen nový řádek nebo -- aktualizován, protože jsme provedli kontrolu ROLLBACK TRANSACTION; KONEC ÚLOHY
Víme, že IF NOT EXISTS check nezaručuje, že někdo jiný nevloží řádek, než se dostaneme k INSERT (pokud na stůl neumístíme agresivní zámky a/nebo nepoužijeme SERIALIZABLE ), ale vnější kontrola nám brání v pokusu o selhání a následném návratu. Držíme se mimo celý TRY/CATCH pokud již víme, že INSERT selže a bylo by logické předpokládat, že – alespoň v některých případech – to bude efektivnější než zadání TRY/CATCH struktura bezpodmínečně. V jediném INSERT to nedává smysl scénář, ale představte si případ, kdy se v tom TRY děje více blokovat (a více potenciálních porušení, která byste mohli předem zkontrolovat, což znamená ještě více práce, kterou byste jinak museli vykonat a poté se vrátit, pokud dojde k pozdějšímu porušení).
Nyní by bylo zajímavé vidět, co by se stalo, kdybyste použili jinou než výchozí úroveň izolace (něco, o čem se budu věnovat v budoucím příspěvku), zejména se souběžností. U tohoto příspěvku jsem však chtěl začít pomalu a otestovat tyto aspekty s jedním uživatelem. Vytvořil jsem tabulku s názvem dbo.[Objects] , velmi zjednodušená tabulka:
CREATE TABLE dbo.[Objects]( ObjectID INT IDENTITY(1,1), Name NVARCHAR(255) PRIMARY KEY);GO
Chtěl jsem naplnit tuto tabulku 100 000 řádky ukázkových dat. Aby byly hodnoty ve sloupci názvu jedinečné (protože PK je omezení, které jsem chtěl porušit), vytvořil jsem pomocnou funkci, která zabírá určitý počet řádků a minimální řetězec. Minimální řetězec by se použil k zajištění toho, že buď (a) sada začala za maximální hodnotou v tabulce Objects, nebo (b) sada začala na minimální hodnotě v tabulce Objects. (Uvedu je ručně během testů, ověřeno jednoduše kontrolou dat, i když jsem pravděpodobně mohl tuto kontrolu zabudovat do funkce.)
CREATE FUNCTION dbo.GenerateRows(@n INT, @minString NVARCHAR(32))RETURNS TABLEAS RETURN ( SELECT TOP (@n) name =name + '_' + RTRIM(rn) FROM ( SELECT a.name, rn =ŘÁDEK_ČÍSLO() PŘES (ODDĚLENÍ PODLE a.jména ORDER BY a.name) OD sys.all_objects AS a CROSS JOIN sys.all_objects AS b WHERE a.name>=@minString AND b.name>=@minString ) AS x );GO
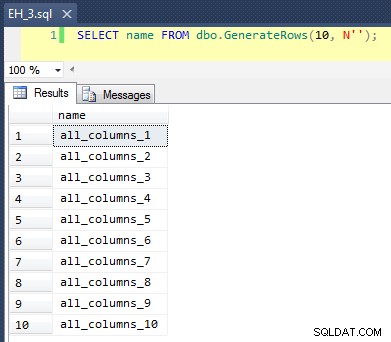
To platí CROSS JOIN z sys.all_objects na sebe, ke každému názvu připojí jedinečné číslo řádku, takže prvních 10 výsledků bude vypadat takto:
Naplnění tabulky 100 000 řádky bylo jednoduché:
INSERT dbo.[Objects](name) SELECT name FROM dbo.GenerateRows(100000, N'') ORDER BY name;GO
Nyní, protože budeme do tabulky vkládat nové jedinečné hodnoty, vytvořil jsem proceduru pro provedení určitého vyčištění na začátku a na konci každého testu – kromě smazání všech nových řádků, které jsme přidali, také vyčistí mezipaměti a vyrovnávací paměti. Samozřejmě to není něco, co byste chtěli zakódovat do procedury ve vašem produkčním systému, ale pro místní testování výkonu je to docela dobré.
POSTUP VYTVOŘENÍ dbo.EH_Cleanup-- P.S. „EH“ znamená Zpracování chyb, nikoli „Eh?“ ASBEGIN SET NOCOUNT ON; DELETE dbo.[Objects] WHERE ObjectID> 100000; DBCC FREEPROCCACHE; DBCC DROPCLEANBUFFERS;ENDGO
Vytvořil jsem také tabulku protokolů, abych mohl sledovat časy začátku a konce každého testu:
CREATE TABLE dbo.RunTimeLog( LogID INT IDENTITY(1,1), Spid INT, InsertType VARCHAR(255), ErrorHandlingMethod VARCHAR(255), StartDate DATETIME2(7) NOT NULL DEFAULT SYSUTCDATETIME(2(7) DATE );GO
Nakonec, testovací uložená procedura zpracovává různé věci. Máme tři různé metody zpracování chyb, jak je popsáno v odrážkách výše:"JustInsert", "Rollback" a "TryCatch"; máme také tři různé typy vložení:(1) všechny vložení úspěšné (všechny řádky jsou jedinečné), (2) všechny vložení selžou (všechny řádky jsou duplicitní) a (3) poloviční vložení úspěšné (polovina řádků je jedinečná a polovina řádky jsou duplicitní). S tím jsou spojeny dva různé přístupy:zkontrolujte, zda nedošlo k porušení před pokusem o vložení, nebo prostě pokračujte a nechte motor určit, zda je platná. Myslel jsem, že to poskytne dobré srovnání různých technik zpracování chyb v kombinaci s různou pravděpodobností kolizí, abych zjistil, zda vysoké nebo nízké procento kolizí významně ovlivní výsledky.
Pro tyto testy jsem vybral 40 000 řádků jako svůj celkový počet pokusů o vložení a v tomto postupu jsem provedl spojení 20 000 jedinečných nebo nejedinečných řádků s 20 000 dalšími jedinečnými nebo nejedinečnými řádky. Můžete vidět, že jsem v proceduře napevno zakódoval řetězce cutoff; prosím poznamenejte si, že ve vašem systému se tato omezení téměř jistě objeví na jiném místě.
CREATE PROCEDURE dbo.EH_Insert @ErrorHandlingMethod VARCHAR(255), @InsertType VARCHAR(255), @RowSplit INT =20000ASBEGIN SET NOCOUNT ON; -- vyčistit všechny nové řádky a zahodit vyrovnávací paměti/vymazat proc cache EXEC dbo.EH_Cleanup; DECLARE @CutoffString1 NVARCHAR(255), @CutoffString2 NVARCHAR(255), @Name NVARCHAR(255), @Continue BIT =1, @LogID INT; -- vygenerovat novou položku protokolu INSERT dbo.RunTimeLog(Spid, InsertType, ErrorHandlingMethod) SELECT @@SPID, @InsertType, @ErrorHandlingMethod; SET @LogID =SCOPE_IDENTITY(); -- pokud chceme, aby vše bylo úspěšné, potřebujeme sadu dat -- která má 40 000 řádků, které jsou všechny jedinečné. Sjednocení dvě – sady, z nichž každá je od sebe vzdálená>=20 000 řádků, a nikoli – již v základní tabulce existují:IF @InsertType ='AllSuccess' SELECT @CutoffString1 =N'database_audit_specifications_1000', @CutoffString2 =N'dm_1988 '; -- pokud chceme, aby všechny selhaly, pak je to snadné, můžeme jen -- sjednotit dvě sady, které začínají na stejném místě jako počáteční -- populace:IF @InsertType ='AllFail' SELECT @CutoffString1 =N'', @CutoffString2 =N''; -- a pokud chceme, aby polovina uspěla, potřebujeme 20 000 jedinečných -- hodnot a 20 000 duplikátů:IF @InsertType ='HalfSuccess' SELECT @CutoffString1 =N'database_audit_specifications_1000', @CutoffString2 =N''; DECLARE c CURSOR LOCAL STATIC FORWARD_ONLY FOR SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString1) UNION ALL SELECT jméno FROM dbo.GenerateRows(@RowSplit, @CutoffString2); OTEVŘENO c; NAČÍST DALŠÍ Z c DO @Jméno; WHILE @@FETCH_STATUS =0 BEGIN SET @Continue =1; -- zadejme blok primárního kódu pouze v případě, že -- musíme zkontrolovat a kontrola se vrátí prázdná -- (jinými slovy, vůbec to nezkoušejte, pokud máme -- duplikát, ale pouze zkontrolujte duplikát - - v určitých případech:IF @ErrorHandlingMethod LIKE 'Check%' ZAČÁTE, POKUD EXISTUJE (VYBERTE 1 FROM dbo.[Objects] WHERE Name =@Name) SET @Continue =0; END IF @Continue =1 ZAČÁTE -- nechte motor catch IF @ErrorHandlingMethod LIKE '%Insert' ZAČÁTE INSERT dbo.[Objects](name) SELECT @name; END -- zahájí transakci, ale nechá motor zachytit IF @ErrorHandlingMethod LIKE '%Rollback' BEGIN BEGIN TRANSACTION; INSERT dbo. [Objects](name) SELECT @name; IF @@ERROR <> 0 ZAČÁTE TRANSAKCI VRÁCENÍM ZPŮSOBU; END ELSE ZAČNĚTE ZAČÁTKU TRANSAKCE; KONEC KONEC -- použijte try / catch IF @ErrorHandlingMethod LIKE '%TryCatch' ZAČÁTEK ZAČÁTE ZKUSTE ZAČÁTEK TRANSAKCI; dbo.[Objekty](jméno) SELECT @Jmeno; POTVRZTE TRANSAKCI; KONEC ZKUSTE ZAČÁTEK CATCH TRANSAKCE VRÁCENÍ; END CATCH END END FETCH NEXT FROM C INTO @Name; KONEC ZAVŘÍT c; DEALOCATE c; -- aktualizujte záznam protokolu UPDATE dbo.RunTimeLog SET EndDate =SYSUTCDATETIME() WHERE LogID =@LogID; -- vyčistit všechny nové řádky a zahodit vyrovnávací paměti/vymazat mezipaměť proc EXEC dbo.EH_Cleanup;ENDGO
Nyní můžeme tuto proceduru zavolat s různými argumenty, abychom získali odlišné chování, o které usilujeme, a pokusíme se vložit 40 000 hodnot (a samozřejmě s vědomím, kolik by mělo v každém případě uspět nebo selhat). Pro každou „metodu zpracování chyb“ (vyzkoušejte vložení, použijte begin tran/rollback nebo try/catch) a každý typ vložení (všechny úspěšné, polovina úspěšné a žádné) v kombinaci s tím, zda se má či nemá kontrolovat porušení za prvé, to nám dává 18 kombinací:
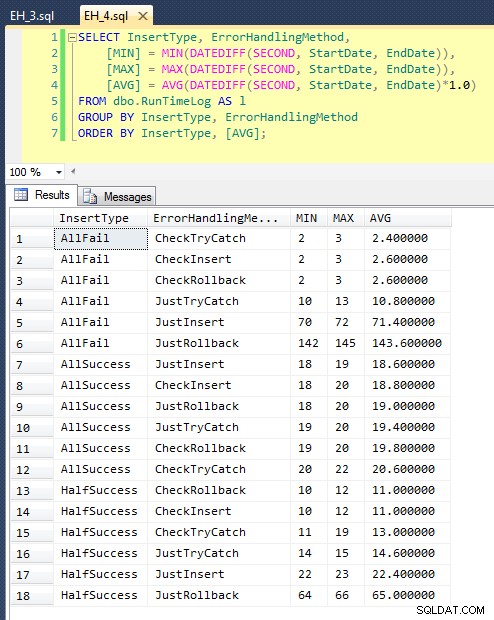
EXEC dbo.EH_Insert 'JustInsert', 'AllSuccess', 20000;EXEC dbo.EH_Insert 'JustInsert', 'HalfSuccess', 20000;EXEC dbo.EH_Insert 'JustInsert','JustInsert','JustInsert','JustInsert','JustInsert','JustInsert','JustInsert','JustInsert' EXEC dbo.EH_Insert 'JustTryCatch', 'AllSuccess', 20000;EXEC dbo.EH_Insert 'JustTryCatch', 'HalfSuccess', 20000;EXEC dbo.EH_Insert '2ch,0FAll','; EXEC dbo.EH_Insert 'JustRollback', 'AllSuccess', 20000;EXEC dbo.EH_Insert 'JustRollback', 'HalfSuccess', 20000;EXEC dbo.EH_Insert 'JustRollback','AllFail00','0 EXEC dbo.EH_Insert 'CheckInsert', 'AllSuccess', 20000;EXEC dbo.EH_Insert 'CheckInsert', 'HalfSuccess', 20000;EXEC dbo.EH_Insert 'CheckInsert','All2Fa2sert','CheckInsert','All2Fa2sert' EXEC dbo.EH_Insert 'CheckTryCatch', 'AllSuccess', 20000;EXEC dbo.EH_Insert 'CheckTryCatch', 'HalfSuccess', 20000;EXEC dbo.EH_Insert' '2Catech'AllSuccess00 EXEC dbo.EH_Insert 'CheckRollback', 'AllSuccess', 20000;EXEC dbo.EH_Insert 'CheckRollback', 'HalfSuccess', 20000;EXEC dbo.EH_Insert,'CheckAll2Fa>0;0Poté, co jsme to spustili (v mém systému to trvá asi 8 minut), máme v našem protokolu nějaké výsledky. Spustil jsem celou dávku pětkrát, abych se ujistil, že máme slušné průměry a vyhladil všechny anomálie. Zde jsou výsledky:
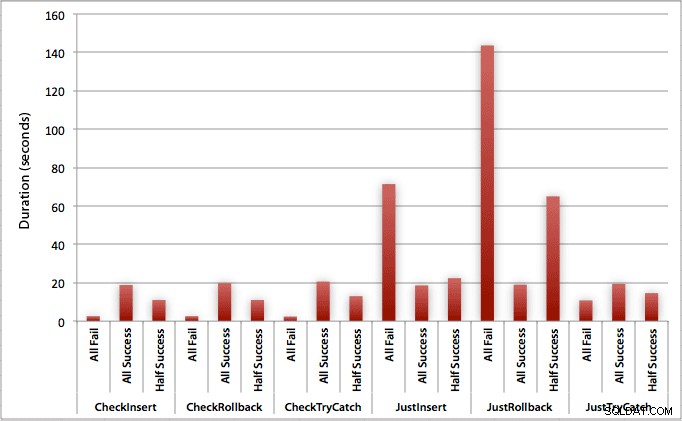
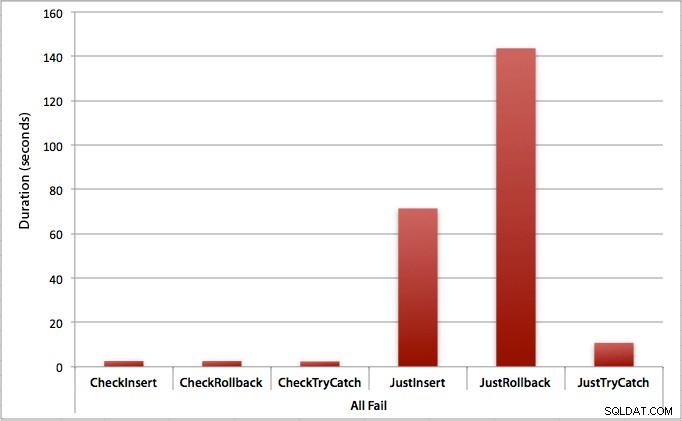
Graf, který zobrazuje všechna trvání najednou, ukazuje několik vážných odlehlých hodnot:
Můžete vidět, že v případech, kdy očekáváme vysokou míru selhání (v tomto testu 100 %), je zahájení transakce a vrácení zpět zdaleka nejméně atraktivním přístupem (3,59 milisekundy na pokus), přičemž stačí nechat motor zvednout chyba je asi o polovinu horší (1,785 milisekundy na pokus). Dalším nejhorším výsledkem byl případ, kdy zahájíme transakci a poté ji vrátíme zpět, ve scénáři, kdy očekáváme, že přibližně polovina pokusů selže (v průměru 1,625 milisekundy na pokus). 9 případů na levé straně grafu, kde nejprve kontrolujeme porušení pravidel, nepřesáhlo 0,515 milisekundy na pokus.
Jednotlivé grafy pro každý scénář (vysoké % úspěšnosti, vysoké % neúspěchu a 50–50) skutečně ukazují dopad každé metody.
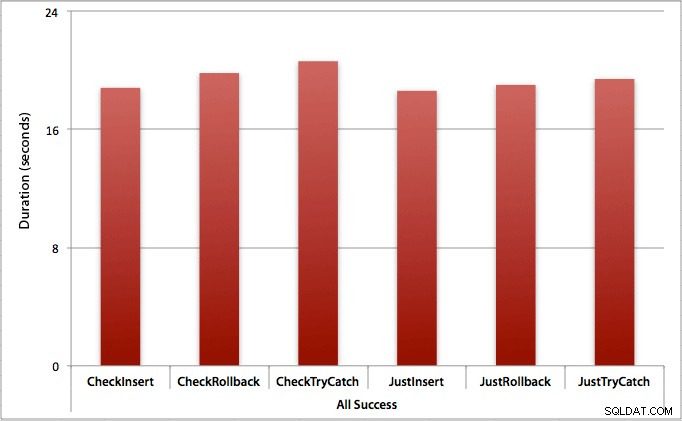
Kde jsou všechny vložky úspěšné
V tomto případě vidíme, že režie nejprve zkontrolovat porušení je zanedbatelná, s průměrným rozdílem 0,7 sekundy v celé dávce (nebo 125 mikrosekund na pokus o vložení):
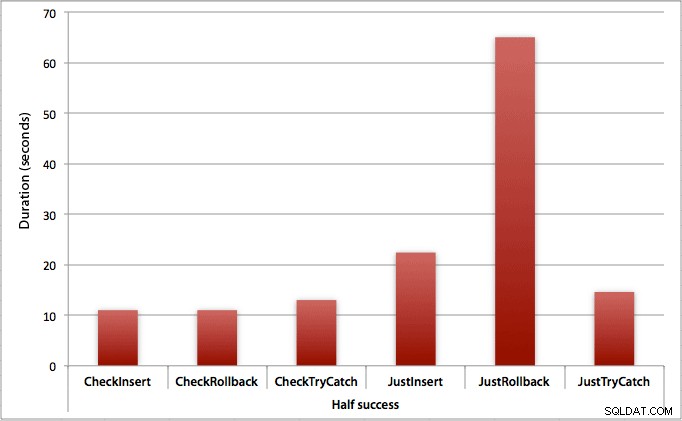
Kde je úspěšná pouze polovina vložení
Když polovina vložek selže, vidíme velký skok v trvání metod vkládání / vrácení zpět. Scénář, kdy zahájíme transakci a vrátíme ji zpět, je v celé dávce asi 6x pomalejší ve srovnání s první kontrolou (1,625 milisekundy na pokus vs. 0,275 milisekundy na pokus). Dokonce i metoda TRY/CATCH je o 11 % rychlejší, když nejprve zkontrolujeme:
Kde selžou všechny vložky
Jak byste mohli očekávat, ukazuje to nejvýraznější dopad zpracování chyb a nejzjevnější výhody první kontroly. Metoda vrácení zpět je v tomto případě téměř 70x pomalejší, když nekontrolujeme, ve srovnání se situací, kdy ji provádíme (3,59 milisekundy na pokus vs. 0,065 milisekundy na pokus):
co nám to říká? Pokud si myslíme, že budeme mít vysokou poruchovost, nebo nemáme ponětí, jaká bude naše potenciální poruchovost, pak se první kontrola, abychom se vyhnuli porušením v motoru, nesmírně vyplatí. I v případě, že máme pokaždé úspěšnou vložku, jsou náklady na první kontrolu marginální a lze je snadno ospravedlnit potenciálními náklady na pozdější zpracování chyb (pokud vaše předpokládaná míra selhání není přesně 0 %).
Zatím si tedy myslím, že se budu držet své teorie, že v jednoduchých případech má smysl zkontrolovat potenciální porušení, než řeknete SQL Serveru, aby pokračoval a vložil přesto. V budoucím příspěvku se podívám na dopad různých úrovní izolace, souběžnosti a možná i několika dalších technik zpracování chyb na výkon.
[Kromě toho jsem v únoru napsal zkrácenou verzi tohoto příspěvku jako tip pro mssqltips.com.]