Hash indexy jsou nedílnou součástí databází. Pokud jste někdy používali databázi, je pravděpodobné, že jste je viděli v akci, aniž byste si to uvědomovali.
Hash indexy se v práci liší od jiných typů indexů, protože ukládají hodnoty spíše než ukazatele na záznamy umístěné na disku. To zajišťuje rychlejší vyhledávání a vkládání do indexu. Proto se hash indexy často používají jako primární klíče nebo jedinečné identifikátory.
Porozumění hash indexům
Hash index je typ indexu, který se nejčastěji používá při správě dat. Obvykle se vytváří ve sloupci, který obsahuje jedinečné hodnoty, jako je primární klíč nebo e-mailová adresa. Hlavní výhodou používání hash indexů je jejich rychlý výkon.
Koncepce těchto indexů může být sofistikovaná, aby ji pochopil někdo, kdo o nich nikdy předtím neslyšel. Pochopení hash indexů je však důležité, pokud potřebujete porozumět tomu, jak databáze fungují. Je nezbytný pro řešení běžných problémů souvisejících s databázemi a jejich rychlostí.
Dobrou zprávou je, že s trochou trpělivosti a vypnutým mobilním telefonem hash indexy určitě zvládnete! Pojďme se na to tedy podívat lépe.
Rychle a snadno
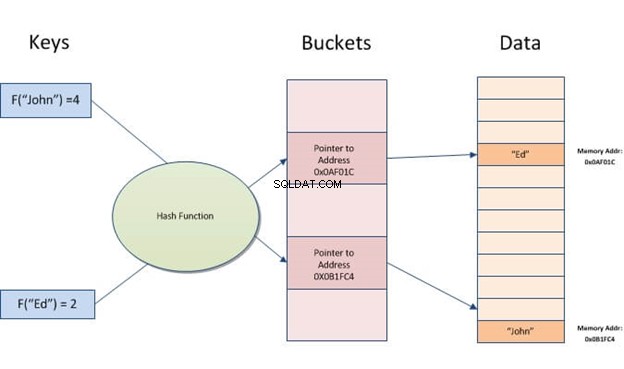
Hash index je datová struktura, kterou lze použít k urychlení databázových dotazů. Funguje to tak, že převádí vstupní záznamy do pole segmentů. Každý segment má stejný počet záznamů jako všechny ostatní segmenty v tabulce. Bez ohledu na to, kolik různých hodnot máte pro konkrétní sloupec, bude každý řádek vždy mapován do jednoho segmentu.
Hash indexy umožňují rychlé vyhledávání dat uložených v tabulkách. Fungují tak, že z hodnoty vytvoří indexový klíč a poté jej vyhledá na základě výsledného hashe. Je to užitečné, když existuje mnoho vstupů s podobnými hodnotami nebo duplikáty, protože potřebuje pouze porovnávat klíče namísto procházení všech záznamů.
Nebylo to ani rychlé, ani snadné? Chcete-li porozumět tomu, jak fungují indexy hash a proč jsou tak výkonné, musíte porozumět tomu, co se rozumí hashováním.
Hašování bere část informace (řetězec) a mění ji na adresu nebo ukazatel pro rychlý přístup později.
Myšlenka hashování spočívá v tom, že datům je přiřazeno malé číslo. Když vyhledáváte data, nemusíte ve skutečnosti probírat masy. Místo toho stačí vyhledat to jedno číslo. Nejjednodušším příkladem je Ctrl+F-ing slova, které hledáte v textu, místo abyste sami četli desítky stránek.
K čemu jsou hash indexy?
Hash index je způsob, jak urychlit proces vyhledávání. U tradičních indexů musíte procházet každý řádek, abyste se ujistili, že je váš dotaz úspěšný. Ale u hash indexů tomu tak není!
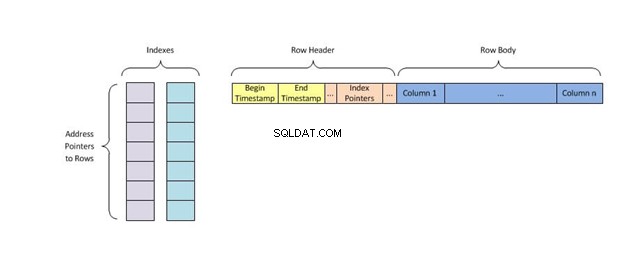
Každý klíč indexu obsahuje pouze jeden řádek dat tabulky a používá indexovací algoritmus zvaný hašování který jim přiřadí jedinečné umístění v paměti a eliminuje všechny ostatní klíče s duplicitními hodnotami, než najde, co hledá.
Hash indexy jsou jedním z mnoha způsobů, jak organizovat data v databázi. Fungují tak, že převezmou vstup a použijí jej jako klíč pro uložení na disk. Tyto klíče nebo hodnoty hash , může být cokoli od délky řetězců po znaky ve vstupu.
Hash indexy se nejčastěji používají při dotazování na konkrétní vstupy se specifickými atributy. Například může najít všechna písmena A, která jsou vyšší než 10 cm. Můžete to udělat rychle vytvořením funkce hash indexu.
Hash indexy jsou součástí databázového systému PostgreSQL. Tento systém byl vyvinut pro zvýšení rychlosti a výkonu. Hash indexy lze použít ve spojení s jinými typy indexů, jako je B-tree nebo GiST.
Hašovací index ukládá klíče tak, že je rozděluje do menších částí nazývaných segmenty, kde je každému segmentu přiděleno celé číslo ID, aby bylo možné jej rychle získat při hledání umístění klíče v tabulce hash. Kbelíky jsou ukládány postupně na disk, takže k datům, která obsahují, lze rychle přistupovat.
Další technická vysvětlení lze nalézt na této stránce (klikněte pravým tlačítkem myši a vyberte „Přeložit do angličtiny“).
Výhody
Hlavní výhodou použití hash indexů je, že umožňují rychlý přístup při načítání záznamu podle hodnoty klíče. To je často užitečné pro dotazy s podmínkou rovnosti. Použití hash benchmarků také nebude vyžadovat mnoho úložného prostoru. Jedná se tedy o účinný nástroj, ale ne bez nevýhod.
Nevýhody
Hash indexy jsou relativně novou strukturou indexování s potenciálem poskytovat významné výkonnostní výhody. Můžete si je představit jako rozšíření binárních vyhledávacích stromů (BST).
Hash indexy fungují tak, že ukládají data do segmentů na základě jejich hash hodnot, což umožňuje rychlé a efektivní načítání dat. Jsou zaručeně v pořádku.
Není však možné ukládat duplicitní klíče do bucketu. Vždy tu tedy bude nějaká režie. Ale zatím klady používání hash indexů převažují nad zápory.
Jak to všechno funguje trochu více do hloubky?
Podívejme se na ukázku aviasales databáze, abyste lépe porozuměli tomu, jak fungují hash indexy.
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged
CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN
----------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (flight_no = 'PG0001'::bpchar)
-> Bitmap Index Scan on flights_flight_no_idx
Index Cond: (flight_no = 'PG0001'::bpchar)
(4 rows)
Zde můžete vidět, jak implementujeme hash indexy kompilací dat do sad.
Toto je snadný příklad, ale všimněte si, že omezení přicházejí s menší infrastrukturou kódu. Může existovat nedostatek přístupu k protokolu WAL nebo nemožnost obnovit indexy (indexy?) po havárii. Kromě toho se indexy nemusí účastnit replikace – je to kvůli zastaralosti PostgreSQL. Stejně jako u Pythonu však dostáváte varování, která vám často umožňují předcházet chybám.
Pokud jste dostatečně zaujatí, můžete se do těchto indexů podívat hlouběji. Za tímto účelem vytváříme kontrolu stránky instance rozšíření.
demo=# create extension pageinspect;
CREATE EXTENSION
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type
----------------
metapage
(1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket
---------+-----------
33121 | 127
(1 row)
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type
----------------
bucket
(1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items
------------+------------
407 | 0
(1 row)
Pokud chcete celý kód zkontrolovat, začněte s README.
Shrnutí
Hash indexy jsou datovou strukturou, která urychluje proces vyhledávání informací ve velkých databázích. Fungují tak, že data rozdělují na menší části a pak je třídí. Když tedy něco hledáte, můžete to najít mnohem rychleji.
Pokud chcete vyhledat více věcí, existují zdroje pro DYOR. Sledujte také naše nové články, které vycházejí rychleji, než stihnete Ctrl+F slovo „hash“ na této stránce. Doufám, že to pomůže!