Skupiny dostupnosti serveru SQL Server 2012 AlwaysOn vyžadují koncový bod zrcadlení databáze pro každou instanci serveru SQL Server, která bude hostit repliku skupiny dostupnosti a/nebo relaci zrcadlení databáze. Tento koncový bod instance SQL Server je pak sdílen jednou nebo více replikami skupiny dostupnosti a/nebo relacemi zrcadlení databáze a je mechanismem pro komunikaci mezi primární replikou a přidruženými sekundárními replikami.
V závislosti na pracovní zátěži úpravy dat na primární replice mohou být požadavky na propustnost zpráv skupiny dostupnosti netriviální. Tato aktivita je také citlivá na provoz ze souběžné aktivity skupiny nedostupné. Pokud propustnost trpí sníženou šířkou pásma a souběžným provozem, můžete zvážit izolaci provozu skupiny dostupnosti na vlastní vyhrazený síťový adaptér pro každou instanci serveru SQL Server hostující repliku dostupnosti. Tento příspěvek popíše tento proces a také stručně popíše, co byste mohli očekávat ve scénáři se sníženou propustností.
Pro tento článek používám pětiuzlový virtuální host Windows Server Failover Cluster (WSFC). Každý uzel ve WSFC má svou vlastní samostatnou instanci serveru SQL Server využívající nesdílené místní úložiště. Každý uzel má také samostatný virtuální síťový adaptér pro veřejnou komunikaci, virtuální síťový adaptér pro komunikaci WSFC a virtuální síťový adaptér, který vyhradíme pro komunikaci skupiny dostupnosti. Pro účely tohoto příspěvku se zaměříme na informace potřebné pro vyhrazené síťové adaptéry skupiny dostupnosti na každém uzlu:
| Název uzlu WSFC | Adresy NIC TCP/IPv4 skupiny dostupnosti |
|---|---|
| SQL2K12-SVR1 | 192.168.20.31 |
| SQL2K12-SVR2 | 192.168.20.32 |
| SQL2K12-SVR3 | 192.168.20.33 |
| SQL2K12-SVR4 | 192.168.20.34 |
| SQL2K12-SVR5 | 192.168.20.35 |
Nastavení skupiny dostupnosti pomocí vyhrazené síťové karty je téměř totožné s procesem sdílené síťové karty, pouze abych „svázal“ skupinu dostupnosti s konkrétní síťovou kartou, musím nejprve určit LISTENER_IP argument v CREATE ENDPOINT pomocí výše uvedených IP adres pro mé vyhrazené síťové karty. Níže ukazuje vytvoření každého koncového bodu napříč pěti uzly WSFC:
:CONNECT SQL2K12-SVR1
USE [master];
GO
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022, LISTENER_IP = (192.168.20.31))
FOR DATA_MIRRORING (ROLE = ALL, ENCRYPTION = REQUIRED ALGORITHM AES);
GO
IF (SELECT state FROM sys.endpoints WHERE name = N'Hadr_endpoint') <> 0
BEGIN
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
END
GO
USE [master];
GO
GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [SQLSKILLSDEMOS\SQLServiceAcct];
GO
:CONNECT SQL2K12-SVR2
-- ...repeat for other 4 nodes... Po vytvoření těchto koncových bodů přidružených k vyhrazené NIC se zbytek mých kroků při nastavování topologie skupiny dostupnosti neliší od scénáře sdílené NIC.
Když po vytvoření své skupiny dostupnosti začnu řídit zatížení modifikací dat proti primárním replikám databází dostupnosti, rychle uvidím, že komunikační provoz skupiny dostupnosti proudí na vyhrazené síťové kartě pomocí Správce úloh na kartě sítě (první část je propustnost pro vyhrazenou skupinu dostupnosti NIC):
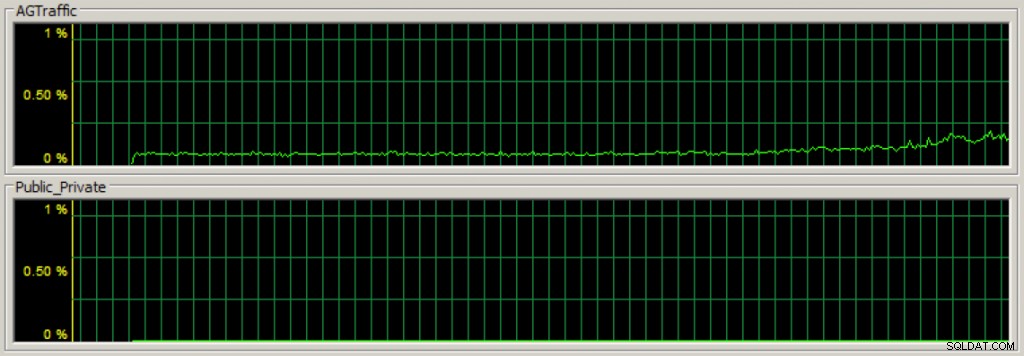
A také mohu sledovat statistiky pomocí různých počítadel výkonu. Na obrázku níže je Inetl[R] PRO_1000 MT Network Connection _2 moje vyhrazená NIC skupiny dostupnosti a má většinu provozu NIC ve srovnání se dvěma dalšími NIC:

Nyní mít vyhrazenou síťovou kartu pro provoz skupiny dostupnosti může být způsob, jak izolovat aktivitu a teoreticky zlepšit výkon, ale pokud má vaše vyhrazená síťová karta nedostatečnou šířku pásma, jak můžete očekávat, utrpí výkon a zhorší se stav topologie skupiny dostupnosti.
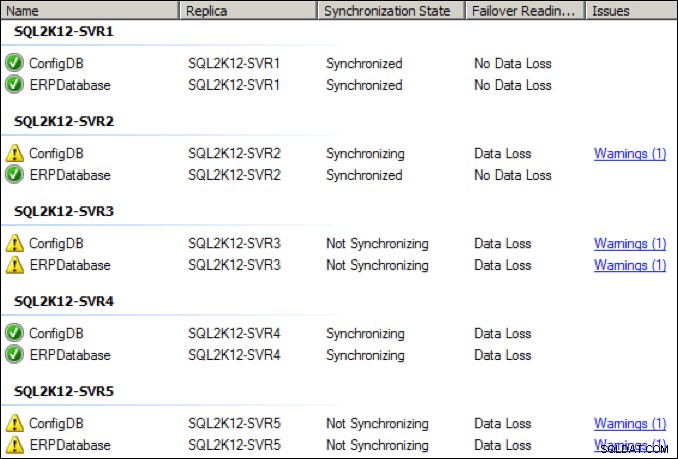
Například jsem změnil vyhrazenou skupinu dostupnosti NIC na primární replice na 28,8 kbps odchozí přenosovou šířku pásma, abych viděl, co se stane. Netřeba dodávat, že to nebylo dobré. Propustnost NIC skupiny dostupnosti výrazně klesla:

Během několika sekund se stav různých replik zhoršil a několik replik se přesunulo do stavu „nesynchronizuje se“:
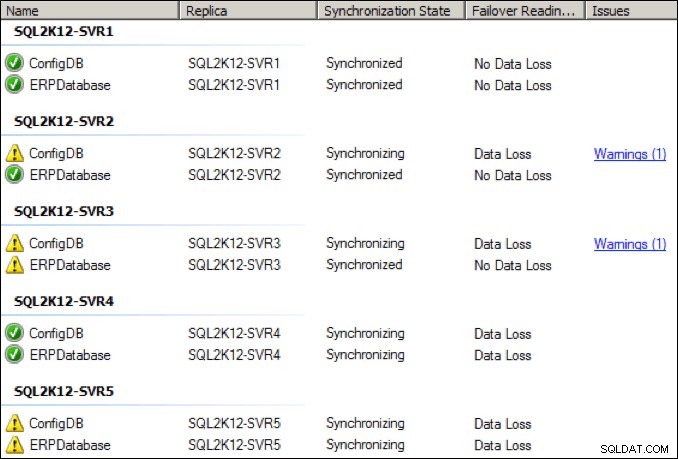
Zvýšil jsem vyhrazenou síťovou kartu na primární replice na 64 Kbps a po několika sekundách došlo také k počátečnímu nárůstu:

Zatímco se věci zlepšily, stal jsem se svědkem pravidelných odpojení a zdravotních varování při tomto nastavení nižší propustnosti NIC:
A co související statistiky čekání na primární replice?
Když byla na vyhrazené síťové kartě dostatek šířky pásma a všechny repliky dostupnosti byly v dobrém stavu, viděl jsem během načítání dat během 2 minut následující rozložení:
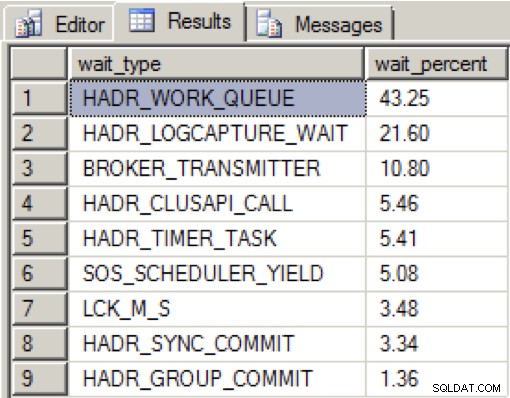
HADR_WORK_QUEUE představuje očekávané pracovní vlákno na pozadí čekající na novou práci. HADR_LOGCAPTURE_WAIT představuje další očekávané čekání na zpřístupnění nových záznamů protokolu a podle Books Online se očekává, pokud je skenování protokolu zachyceno nebo je načítáno z disku.
Když jsem dostatečně snížil propustnost NIC, aby se skupina dostupnosti dostala do nezdravého stavu, rozložení typu čekání bylo následující:
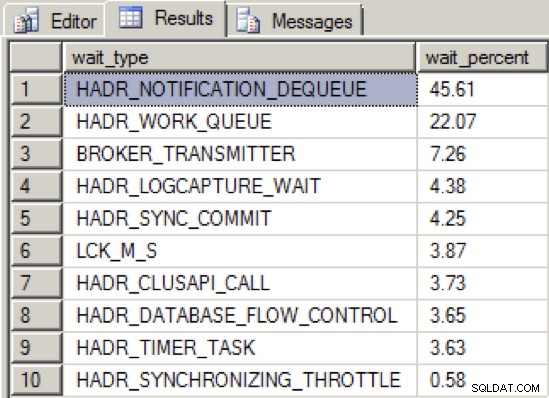
Nyní vidíme nový hlavní typ čekání, HADR_NOTIFICATION_DEQUEUE . Toto je jeden z těch typů čekání „pouze pro interní použití“, jak je definuje Books Online a představuje úlohu na pozadí, která zpracovává oznámení WSFC. Zajímavé je, že tento typ čekání neukazuje přímo na problém, a přesto testy ukazují, že tento typ čekání stoupá na vrchol ve spojení se sníženou propustností skupinových zpráv dostupnosti.
Základem je tedy izolace aktivity skupiny dostupnosti na vyhrazenou síťovou kartu, což může být výhodné, pokud poskytujete propustnost sítě s dostatečnou šířkou pásma. Pokud však nemůžete zaručit dobrou šířku pásma ani pomocí vyhrazené sítě, utrpí to zdraví vaší topologie skupiny dostupnosti.