V dnešní době existuje mnoho poskytovatelů cloudu. Mohou být malé nebo velké, místní nebo s datovými centry rozmístěnými po celém světě. Mnoho z těchto poskytovatelů cloudu nabízí nějaký druh řešení spravované relační databáze. Podporované databáze bývají MySQL nebo PostgreSQL nebo nějaká jiná varianta relační databáze.
Při navrhování jakéhokoli druhu databázové infrastruktury je důležité porozumět potřebám vaší firmy a rozhodnout se, jaký druh dostupnosti potřebujete dosáhnout.
V tomto příspěvku na blogu se podíváme na možnosti vysoké dostupnosti řešení založených na MySQL od jednoho z největších cloudových poskytovatelů – Google Cloud Platform.
Nasazení vysoce dostupného prostředí pomocí instance SQL GCP
Pro tento blog chceme velmi jednoduché prostředí – jednu databázi, možná s jednou nebo dvěma replikami. Chceme mít možnost snadného převzetí služeb při selhání a obnovení operací co nejdříve, pokud selže hlavní server. Jako verzi použijeme MySQL 5.7 a začneme s průvodcem nasazením instance:
Potom musíme vytvořit heslo uživatele root, nastavit název instance a určit, kde má být umístěn:
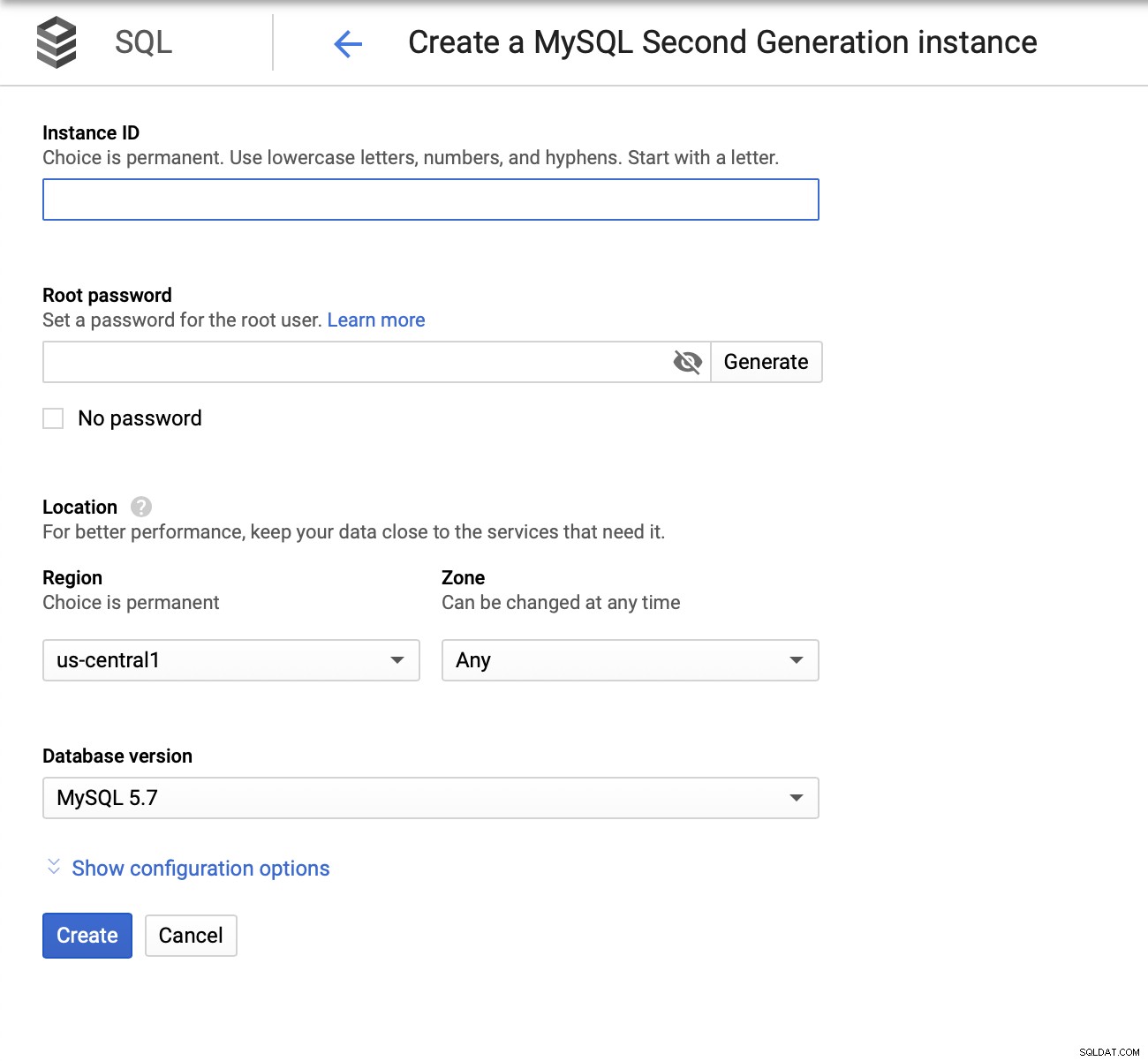
Dále se podíváme na možnosti konfigurace:
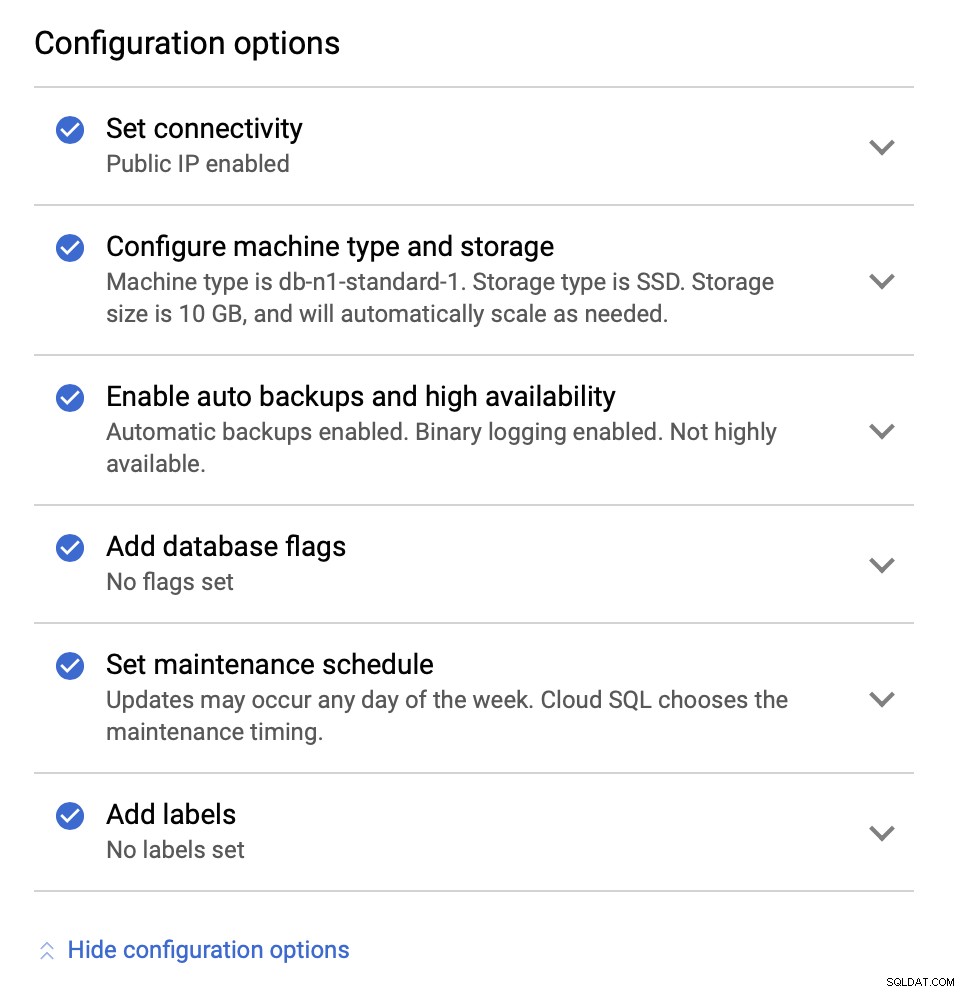
Můžeme provést změny, pokud jde o velikost instance (použijeme db-n1-standard-4), úložiště a plán údržby. Co je pro nás v tomto nastavení nejdůležitější, jsou možnosti vysoké dostupnosti:
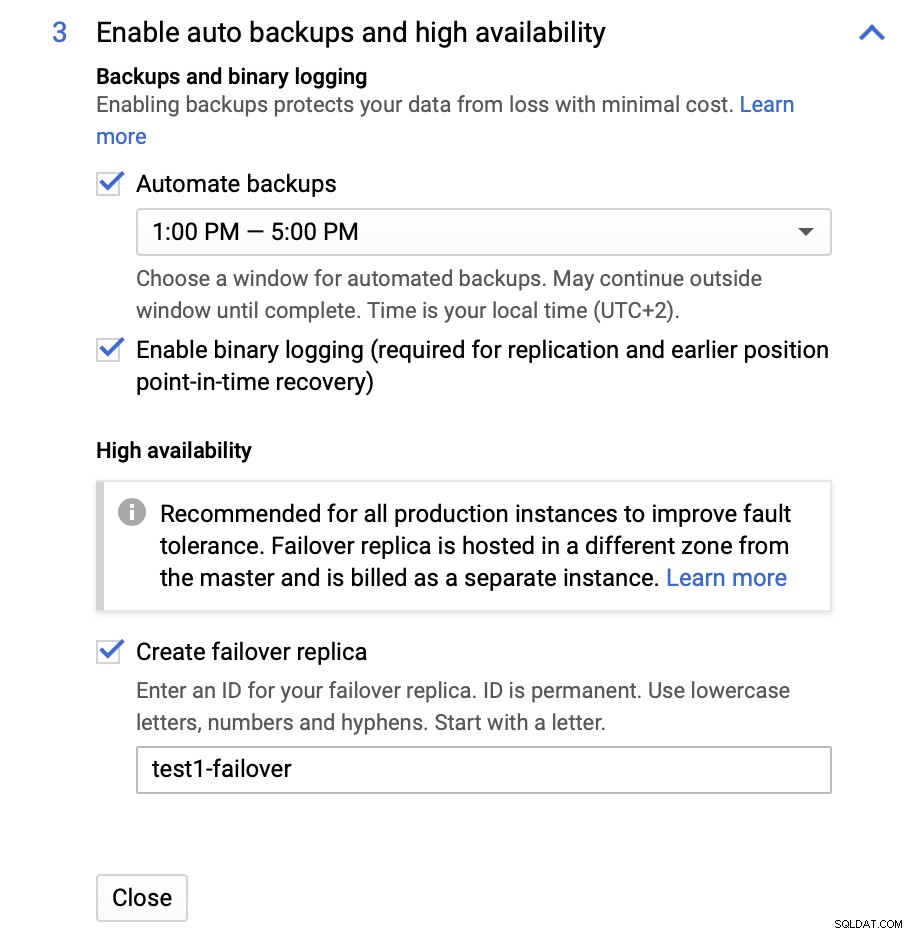
Zde si můžeme zvolit vytvoření repliky pro převzetí služeb při selhání. Tato replika bude povýšena na předlohu, pokud původní předloha selže.

Po nasazení nastavení přidejte replikační slave:
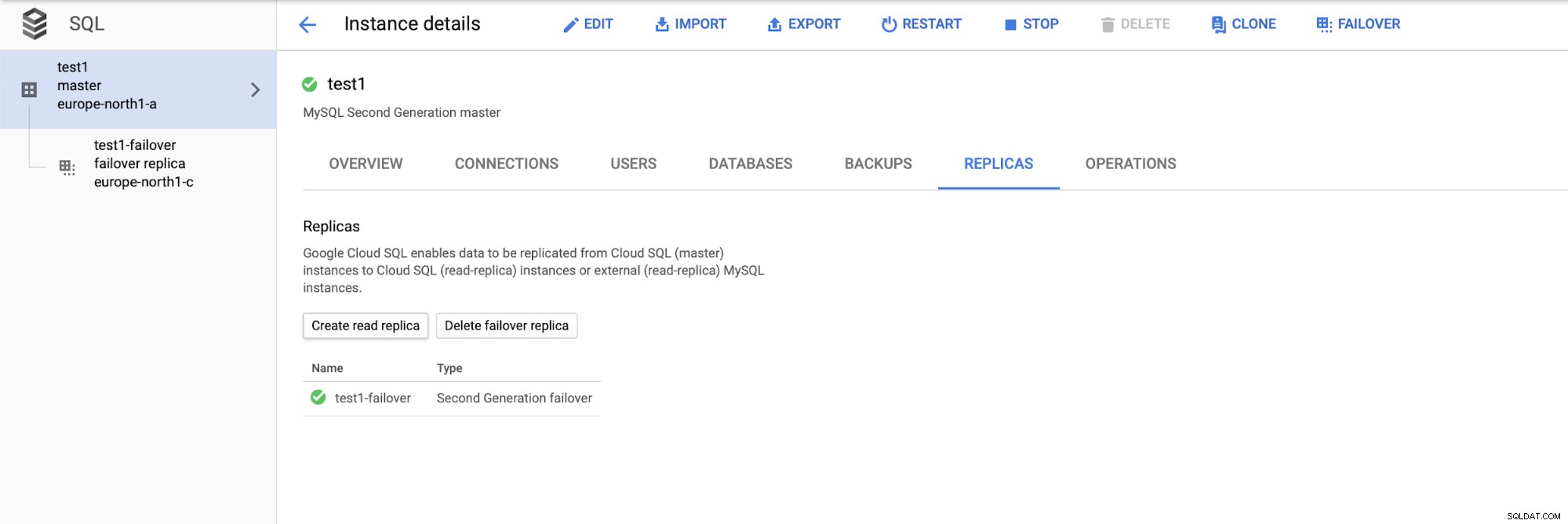
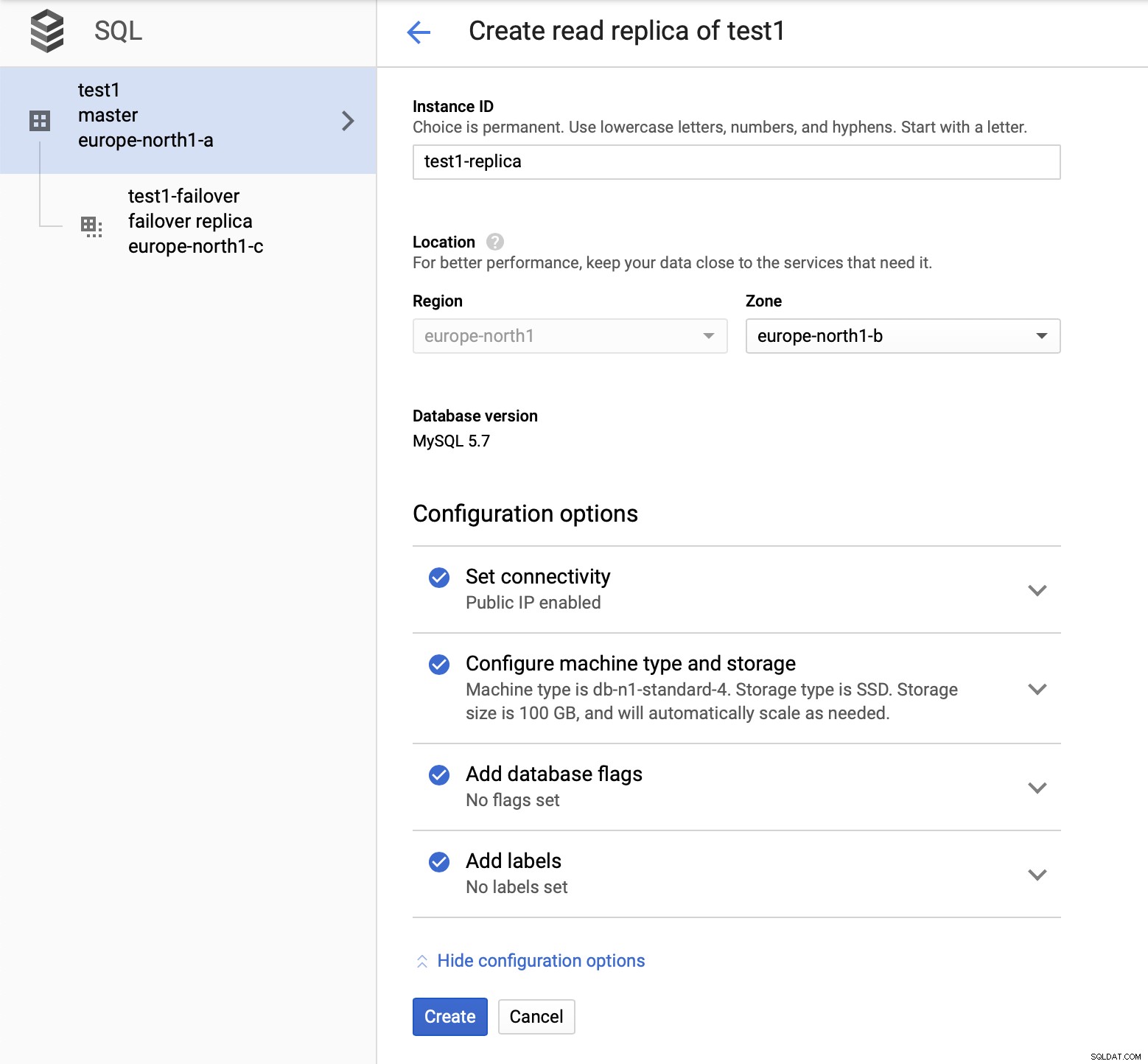
Po dokončení procesu přidávání repliky jsme připraveni na testy. Chystáme se spustit testovací zátěž pomocí Sysbench na naší hlavní, failover replice a číst repliku, abychom viděli, jak to bude fungovat. Spustíme tři instance Sysbenche s použitím koncových bodů pro všechny tři typy uzlů.
Potom spustíme ruční převzetí služeb při selhání prostřednictvím uživatelského rozhraní:
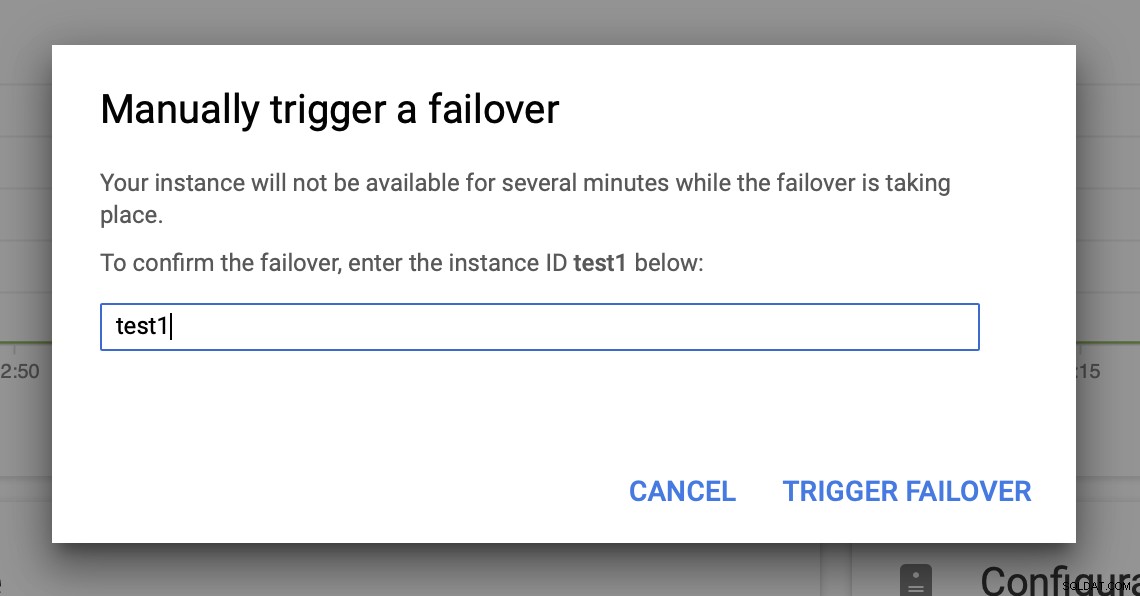
Testujete selhání MySQL na Google Cloud Platform?
Dostal jsem se do tohoto bodu bez jakýchkoli podrobných znalostí o tom, jak fungují uzly SQL v GCP. Měl jsem však určitá očekávání na základě předchozích zkušeností s MySQL a toho, co jsem viděl u jiných poskytovatelů cloudu. Pro začátečníky by převzetí služeb při selhání do uzlu převzetí služeb při selhání mělo být velmi rychlé. Chtěli bychom ponechat replikační podřízené jednotky dostupné bez nutnosti přestavby. Také bychom rádi viděli, jak rychle dokážeme provést převzetí služeb při selhání podruhé (protože není neobvyklé, že se problém šíří z jedné databáze do druhé).
Co jsme zjistili během našich testů...
- Během selhání se hlavní server stal znovu dostupným za 75–80 sekund.
- Replika převzetí služeb při selhání nebyla k dispozici po dobu 5–6 minut.
- Během procesu převzetí služeb při selhání byla k dispozici replika pro čtení, ale po zpřístupnění repliky při převzetí služeb při selhání se stala nedostupnou na 55–60 sekund
Čím si nejsme jisti...
Co se stane, když replika převzetí služeb při selhání není k dispozici? Na základě času to vypadá, že replika převzetí služeb při selhání se přestavuje. To dává smysl, ale pak by doba obnovy silně souvisela s velikostí instance (zejména výkonem I/O) a velikostí datového souboru.
Co se děje s replikou pro čtení poté, co by byla přestavěna replika pro převzetí služeb při selhání? Původně byla čtená replika připojena k masteru. Když hlavní server selhal, očekávali bychom, že čtená replika poskytne zastaralý pohled na datovou sadu. Jakmile se objeví nový hlavní server, měl by se znovu připojit prostřednictvím replikace k instanci (která bývala replikou po převzetí služeb při selhání a která byla povýšena na hlavní). Při provádění CHANGE MASTER není potřeba minuta výpadku.
Důležitější je, že během procesu převzetí služeb při selhání neexistuje způsob, jak provést další převzetí služeb při selhání (což dává smysl):
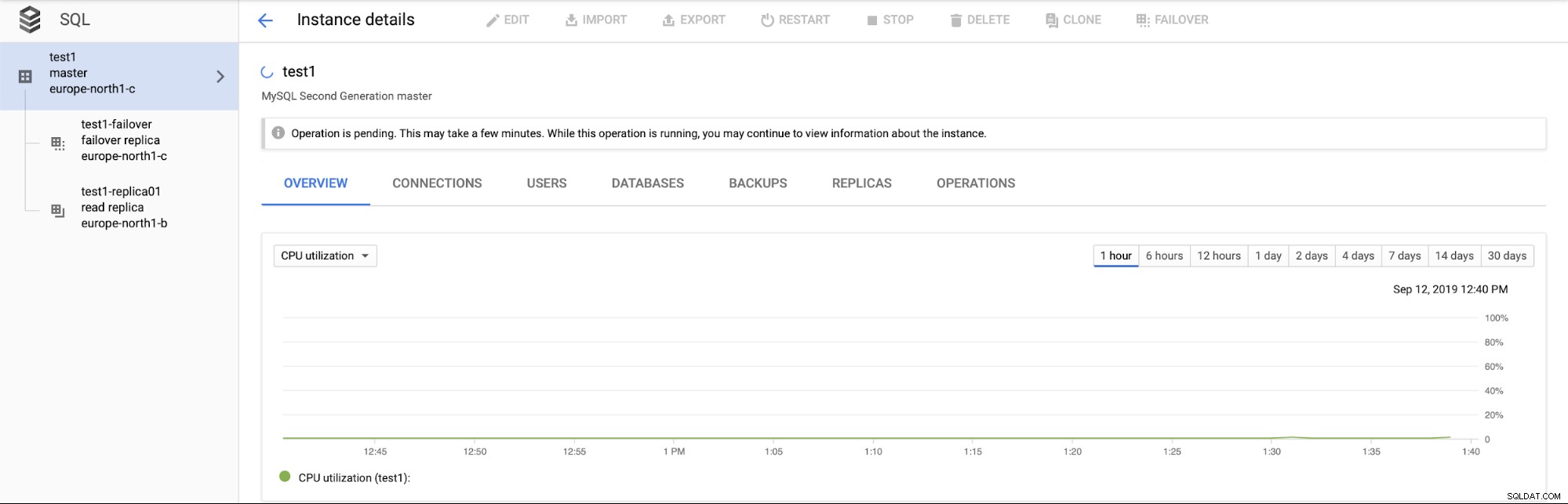
Také není možné propagovat čtenou repliku (což nemusí nutně dávat smysl - očekávali bychom, že budeme moci kdykoli propagovat přečtené repliky).

Je důležité poznamenat, že při zajištění vysoké dostupnosti spoléháme na repliky pro čtení (bez vytvoření repliky převzetí služeb při selhání) není schůdným řešením. Můžete povýšit repliku pro čtení, aby se stala hlavní, ale byl by vytvořen nový cluster; odpojený od zbytku uzlů.
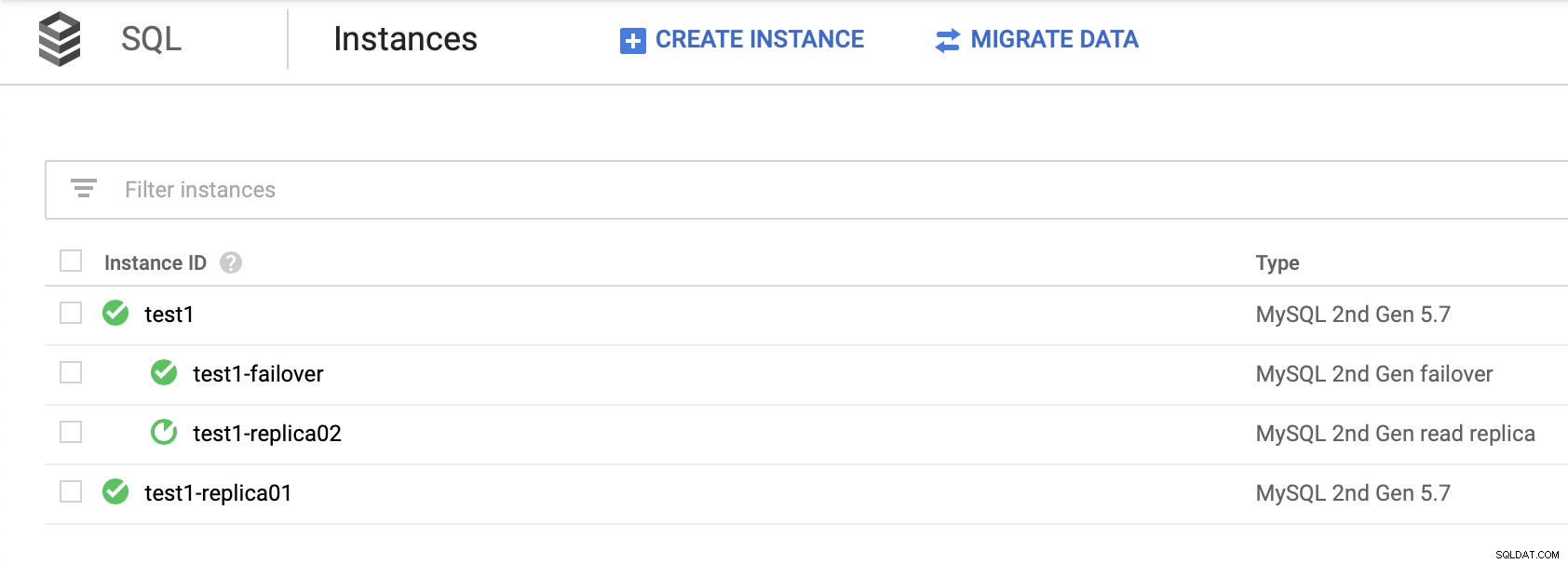
Neexistuje žádný způsob, jak podřídit vaše další repliky z nového clusteru. Jediný způsob, jak toho dosáhnout, by bylo vytvořit nové repliky, ale to je časově náročný proces. Je také prakticky nepoužitelná, takže replika převzetí služeb při selhání je jedinou skutečnou možností vysoké dostupnosti pro uzly SQL v Google Cloud Platform.
Závěr
I když je možné vytvořit vysoce dostupné prostředí pro uzly SQL v GCP, master nebude dostupný zhruba minutu a půl. Celý proces (včetně opětovného sestavení repliky pro převzetí služeb při selhání a některých akcí na přečtených replikách) trval několik minut. Během té doby jsme nebyli schopni spustit další převzetí služeb při selhání ani jsme nebyli schopni propagovat repliku pro čtení.
Máme tam nějaké uživatele GCP? Jak dosahujete vysoké dostupnosti?