Amazon Aurora Serverless poskytuje na vyžádání, automaticky škálovatelnou, vysoce dostupnou relační databázi, která vám účtuje poplatky, pouze když se používá. Poskytuje relativně jednoduchou, nákladově efektivní možnost pro občasné, přerušované nebo nepředvídatelné úlohy. To umožňuje to, že se automaticky spouští, přizpůsobuje výpočetní kapacitu tak, aby odpovídala využití vaší aplikace, a poté se vypíná, když již není potřeba.
Následující diagram ukazuje architekturu Aurora Serverless na vysoké úrovni.
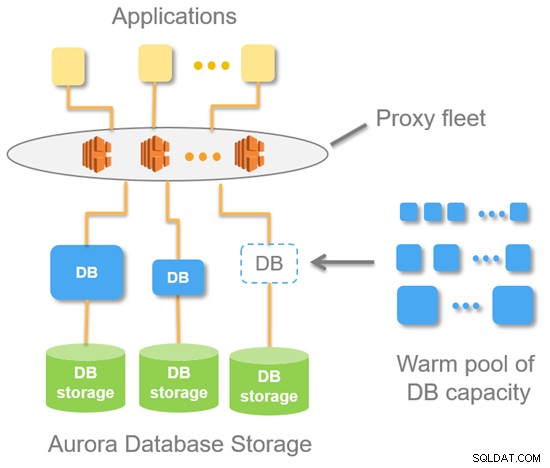
S Aurora Serverless získáte jeden koncový bod (na rozdíl od dvou koncových bodů pro standardní zřízenou DB Aurora). Toto je v podstatě DNS záznam sestávající z flotily proxy, které jsou umístěny na vrcholu instance databáze. Z bodu serveru MySQL to znamená, že připojení vždy pocházejí z flotily proxy.
Automatické škálování bez serveru Aurora
Aurora Serverless je aktuálně dostupná pouze pro MySQL 5.6. V zásadě musíte nastavit jednotku minimální a maximální kapacity pro cluster DB. Každá jednotka kapacity je ekvivalentní specifické konfiguraci výpočtu a paměti. Aurora Serverless snižuje zdroje pro cluster DB, když je jeho pracovní zátěž pod těmito prahovými hodnotami. Aurora Serverless může snížit kapacitu na minimum nebo zvýšit kapacitu na jednotku maximální kapacity.
Cluster se automaticky zvětší, pokud je splněna některá z následujících podmínek:
- Využití CPU je nad 70 % NEBO
- Je využíváno více než 90 % připojení
Cluster se automaticky zmenší, pokud jsou splněny obě následující podmínky:
- Využití CPU klesne pod 30 % AND
- Je využíváno méně než 40 % připojení.
Některé z důležitých věcí, které byste měli vědět o toku automatického škálování Aurora:
- Zvětší se pouze tehdy, když zjistí problémy s výkonem, které lze vyřešit zvýšením.
- Po zvýšení měřítka je doba ochlazení pro zmenšení 15 minut.
- Po zmenšení je doba ochlazení pro další snížení opět 310 sekund.
- Pokud po dobu 5 minut nedojde k žádnému připojení, změní se na nulovou kapacitu.
Ve výchozím nastavení Aurora Serverless provádí automatické škálování hladce, aniž by přerušila jakákoli aktivní databázová připojení k serveru. Je schopen určit škálovací bod (časový bod, ve kterém může databáze bezpečně zahájit operaci škálování). Za následujících podmínek však Aurora Serverless nemusí být schopna najít měřítko:
- Probíhají dlouhotrvající dotazy nebo transakce.
- Používají se dočasné tabulky nebo zámky tabulek.
Pokud dojde k některému z výše uvedených případů, Aurora Serverless se bude nadále snažit najít měřítko, aby mohla zahájit operaci měřítka (pokud není povoleno "Force Scaling"). Dělá to tak dlouho, dokud určí, že klastr DB by měl být škálován.
Pozorování Aurora Auto Scaling Behavior
Všimněte si, že v Aurora Serverless lze upravit pouze malý počet parametrů a max_connections mezi ně nepatří. Pro všechny ostatní konfigurační parametry používají clustery Aurora MySQL Serverless výchozí hodnoty. Pro max_connections je dynamicky řízena Aurora Serverless pomocí následujícího vzorce:
max_connections =NEJLEPŠÍ({log(DBInstanceClassMemory/805306368)*45},{log(DBInstanceClassMemory/8187281408)*1000})
Kde, log je log2 (log base-2) a "DBInstanceClassMemory" je počet bajtů paměti přidělených třídě instance DB přidružené k aktuální instanci DB, mínus paměť používaná procesy Amazon RDS, které instanci spravují. Je docela těžké předem určit hodnotu, kterou bude Aurora používat, a proto je dobré provést několik testů, abyste pochopili, jak je tato hodnota odpovídajícím způsobem škálována.
Zde je naše shrnutí nasazení Aurora Serverless pro tento test:
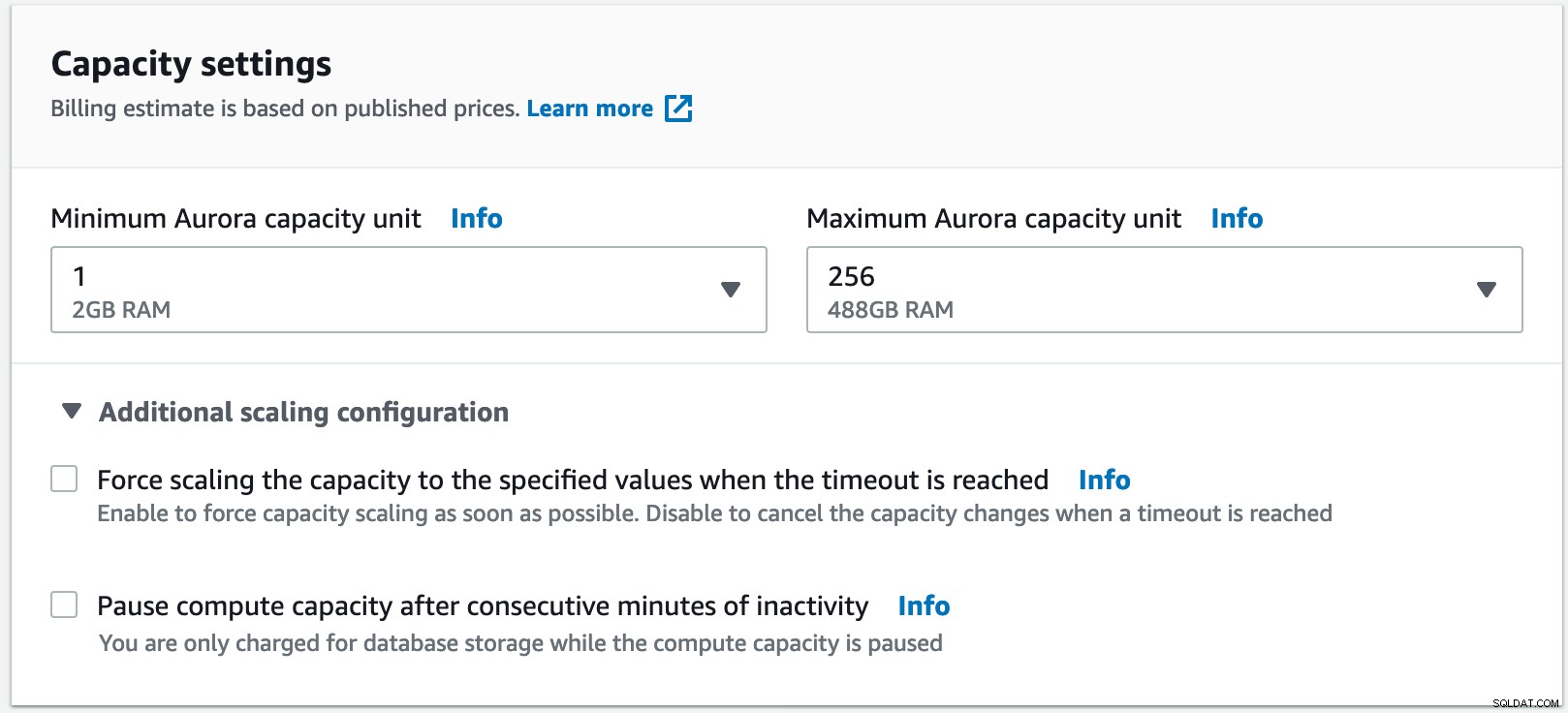
Pro tento příklad jsem vybral minimálně 1 jednotku s kapacitou Aurora, což se rovná 2 GB RAM až po jednotku s maximální kapacitou 256 s 488 GB RAM.
Testování bylo prováděno pomocí sysbench, pouhým odesláním více vláken, dokud nedosáhlo limitu připojení k databázi MySQL. Náš první pokus o odeslání 128 současných databázových připojení najednou selhal:
$ sysbench \
/usr/share/sysbench/oltp_read_write.lua \
--report-interval=2 \
--threads=128 \
--delete_inserts=5 \
--time=360 \
--max-requests=0 \
--db-driver=mysql \
--db-ps-mode=disable \
--mysql-host=${_HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=20 \
--table-size=100000 \
runVýše uvedený příkaz okamžitě vrátil chybu „Příliš mnoho připojení“:
FATAL: unable to connect to MySQL server on host 'aurora-sysbench.cluster-cdw9q2wnb00s.ap-southeast-1.rds.amazonaws.com', port 3306, aborting...
FATAL: error 1040: Too many connectionsKdyž se podíváme na nastavení max_connection, máme následující:
mysql> SELECT @@hostname, @@max_connections;
+----------------+-------------------+
| @@hostname | @@max_connections |
+----------------+-------------------+
| ip-10-2-56-105 | 90 |
+----------------+-------------------+Ukazuje se, že počáteční hodnota max_connections pro naši instanci Aurora s jednou kapacitou DB (2 GB RAM) je 90. To je ve skutečnosti mnohem nižší než naše očekávaná hodnota, pokud se vypočítá pomocí poskytnutého vzorce pro odhad hodnota max_connections:
mysql> SELECT GREATEST({log2(2147483648/805306368)*45},{log2(2147483648/8187281408)*1000});
+------------------------------------------------------------------------------+
| GREATEST({log2(2147483648/805306368)*45},{log2(2147483648/8187281408)*1000}) |
+------------------------------------------------------------------------------+
| 262.2951 |
+------------------------------------------------------------------------------+To jednoduše znamená, že DBInstanceClassMemory se nerovná skutečné paměti pro instanci Aurora. Musí být mnohem nižší. Podle tohoto diskusního vlákna je hodnota proměnné upravena tak, aby zohledňovala paměť již používanou pro služby OS a démona správy RDS.
Nicméně nám nepomůže ani změna výchozí hodnoty max_connections na něco vyššího, protože tato hodnota je dynamicky řízena clusterem Aurora Serverless. Museli jsme tedy snížit hodnotu počátečních vláken sysbench na 84, protože interní vlákna Aurora již rezervovala přibližně 4 až 5 připojení prostřednictvím 'rdsadmin'@'localhost'. Navíc také potřebujeme další připojení pro účely správy a monitorování.
Takže jsme místo toho provedli následující příkaz (s --threads=84):
$ sysbench \
/usr/share/sysbench/oltp_read_write.lua \
--report-interval=2 \
--threads=84 \
--delete_inserts=5 \
--time=600 \
--max-requests=0 \
--db-driver=mysql \
--db-ps-mode=disable \
--mysql-host=${_HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=20 \
--table-size=100000 \
runPo dokončení výše uvedeného testu za 10 minut (--time=600) jsme znovu spustili stejný příkaz a v tuto chvíli se některé z významných proměnných a stav změnily, jak je uvedeno níže:
mysql> SELECT @@hostname AS hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+--------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+--------------+-----------------+-------------------+--------+
| ip-10-2-34-7 | 180 | 179 | 157 |
+--------------+-----------------+-------------------+--------+Všimněte si, že max_connections se nyní zdvojnásobil na 180, s jiným názvem hostitele a malou dobou provozu, jako by se server právě spouštěl. Z pohledu aplikace to vypadá, že koncový bod převzala jiná „větší instance databáze“ a nakonfigurovala se s jinou proměnnou max_connections. Při pohledu na událost Aurora se stalo následující:
Wed, 04 Sep 2019 08:50:56 GMT The DB cluster has scaled from 1 capacity unit to 2 capacity units.Potom jsme spustili stejný příkaz sysbench a vytvořili dalších 84 připojení ke koncovému bodu databáze. Po dokončení vygenerovaného zátěžového testu se server automaticky zvětší až na kapacitu 4 DB, jak je znázorněno níže:
mysql> SELECT @@hostname AS hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+---------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+---------------+-----------------+-------------------+--------+
| ip-10-2-12-75 | 270 | 6 | 300 |
+---------------+-----------------+-------------------+--------+To poznáte podle odlišného názvu hostitele, hodnoty max_connection a uptime ve srovnání s předchozí. Další větší instance „převzaly“ roli od předchozí instance, kde byla kapacita DB rovna 2. Skutečný bod škálování je, když zatížení serveru klesalo a téměř padalo na podlahu. V našem testu, pokud bychom udržovali připojení plné a zatížení databáze trvale vysoké, automatické škálování by neproběhlo.
Podíváme-li se na oba níže uvedené snímky obrazovky, můžeme říci, že k škálování dojde pouze tehdy, když náš Sysbench dokončí zátěžový test po dobu 600 sekund, protože to je nejbezpečnější bod pro provedení automatického škálování.
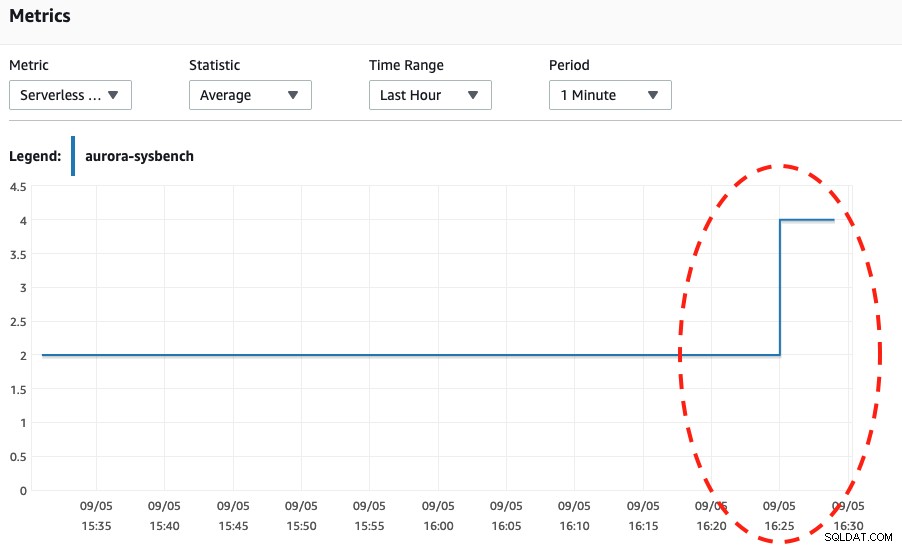 Kapacita DB bez serveru Využití CPU
Kapacita DB bez serveru Využití CPU 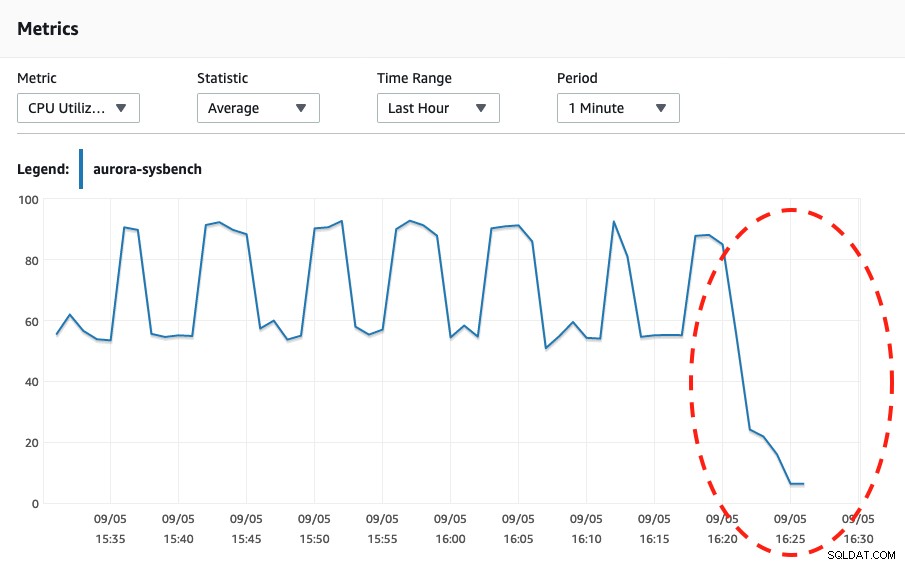 Využití CPU
Využití CPU Když se díváte na události Aurory, staly se následující události:
Wed, 04 Sep 2019 16:25:00 GMT Scaling DB cluster from 4 capacity units to 2 capacity units for this reason: Autoscaling.
Wed, 04 Sep 2019 16:25:05 GMT The DB cluster has scaled from 4 capacity units to 2 capacity units.Nakonec jsme vygenerovali mnohem více připojení až do téměř 270 a počkáme, až to skončí, abychom se dostali do kapacity 8 DB:
mysql> SELECT @@hostname as hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+---------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+---------------+-----------------+-------------------+--------+
| ip-10-2-72-12 | 1000 | 144 | 230 |
+---------------+-----------------+-------------------+--------+V instanci s 8 kapacitními jednotkami je nyní hodnota max_connections MySQL 1000. Opakovali jsme podobné kroky, kdy jsme maximalizovali databázová připojení a dosáhli limitu 256 kapacitních jednotek. Následující tabulka shrnuje celkovou jednotku kapacity DB versus hodnotu max_connections v našem testování až do maximální kapacity DB:
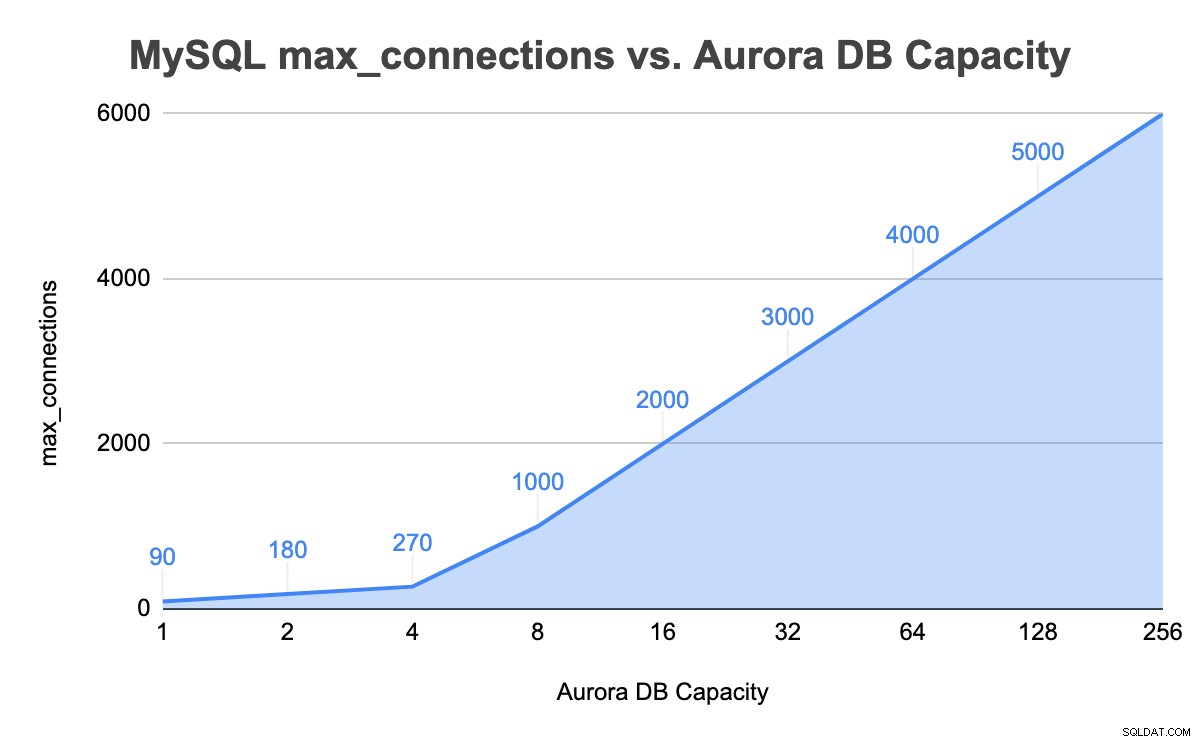
Vynucené škálování
Jak je uvedeno výše, Aurora Serverless provede automatické škálování pouze tehdy, když to bude bezpečné. Uživatel však má možnost vynutit okamžité provedení škálování kapacity DB zaškrtnutím políčka Vynutit škálování pod možností 'Další konfigurace škálování':
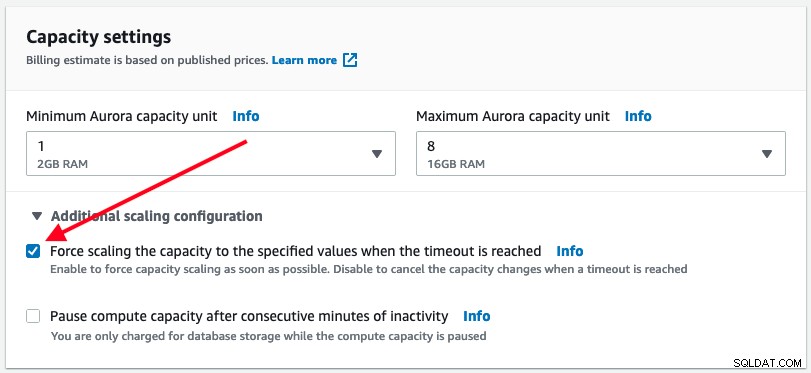
Když je povoleno vynucené škálování, škálování proběhne, jakmile vyprší časový limit dosaženo, což je 300 sekund. Toto chování může způsobit přerušení databáze z vaší aplikace, kdy může dojít k přerušení aktivních připojení k databázi. Když došlo k vynucení automatického škálování poté, co vypršel časový limit, pozorovali jsme následující chybu:
FATAL: mysql_drv_query() returned error 1105 (The last transaction was aborted due to an unknown error. Please retry.) for query 'SELECT c FROM sbtest19 WHERE id=52824'
FATAL: `thread_run' function failed: /usr/share/sysbench/oltp_common.lua:419: SQL error, errno = 1105, state = 'HY000': The last transaction was aborted due to an unknown error. Please retry.Výše uvedené jednoduše znamená, že místo hledání správného času pro škálování Aurora Serverless vynutí výměnu instance ihned po vypršení časového limitu, což způsobí přerušení a vrácení transakcí. Druhý pokus o přerušený dotaz pravděpodobně problém vyřeší. Tuto konfiguraci lze použít, pokud je vaše aplikace odolná vůči výpadkům připojení.
Shrnutí
Automatické škálování Amazon Aurora Serverless je řešení vertikálního škálování, kde výkonnější instance přebírá podřízenou instanci a efektivně využívá základní technologii sdíleného úložiště Aurora. Ve výchozím nastavení se operace automatického škálování provádí hladce, přičemž Aurora najde bezpečný bod škálování pro provedení přepínání instance. Jeden má možnost vynutit automatické škálování s rizikem, že aktivní databázová připojení budou zrušena.