Předtím jsme zveřejnili blog pojednávající o dosažení převzetí služeb při selhání a zpětného převzetí služeb při selhání MySQL na platformě Google Cloud Platform (GCP) a v tomto blogu se podíváme na to, jak její konkurent, služba Amazon Relational Database Service (RDS), zvládá převzetí služeb při selhání. Podíváme se také na to, jak můžete provést obnovu vašeho bývalého hlavního uzlu a vrátit jej do původního pořadí jako hlavní uzel.
Při porovnávání veřejných cloudů technologického obra, které podporují služby spravovaných relačních databází, je Amazon jediným, který nabízí alternativní možnost (společně s MySQL/MariaDB, PostgreSQL, Oracle a SQL Server) vlastní druh správy databází s názvem Amazon Aurora. Pro ty, kteří nejsou obeznámeni s Aurorou, je to plně spravovaný relační databázový stroj, který je kompatibilní s MySQL a PostgreSQL. Aurora je součástí spravované databázové služby Amazon RDS, webové služby, která usnadňuje nastavení, provoz a škálování relační databáze v cloudu.
Proč byste potřebovali převzetí služeb při selhání nebo navrácení služeb při selhání?
Navrhování velkého systému, který je odolný vůči chybám, je vysoce dostupný a bez jediného bodu selhání (SPOF), vyžaduje řádné testování, aby se zjistilo, jak bude reagovat, když se něco pokazí.
Pokud se obáváte, jak by si váš systém vedl, když by reagoval na detekci chyb, izolaci a obnovu (FDIR) vašeho systému, pak by mělo být velmi důležité převzetí služeb při selhání a navrácení po selhání.
Převzetí selhání databáze v Amazon RDS
Přepnutí při selhání probíhá automaticky (ruční přepnutí při selhání se nazývá přepnutí). Jak bylo uvedeno v předchozím blogu, potřeba převzetí služeb při selhání nastane, jakmile váš aktuální master databáze zaznamená selhání sítě nebo abnormální ukončení hostitelského systému. Failover jej přepne do stabilního stavu redundance nebo do pohotovostního počítačového serveru, systému, hardwarové komponenty nebo sítě.
V Amazon RDS to nemusíte dělat, ani to nemusíte sami monitorovat, protože RDS je spravovaná databázová služba (to znamená, že Amazon tuto úlohu zpracuje za vás). Tato služba spravuje věci, jako jsou problémy s hardwarem, zálohování a obnova, aktualizace softwaru, upgrady úložiště a dokonce i opravy softwaru. Promluvíme si o tom později v tomto blogu.
Zálohování databáze v Amazon RDS
V předchozím blogu jsme se také zabývali tím, proč je potřeba vrátit se k selhání. V typickém replikovaném prostředí musí být master dostatečně výkonný, aby unesl obrovskou zátěž, zvláště když je požadavek na pracovní zátěž vysoký. Vaše hlavní nastavení vyžaduje odpovídající hardwarové specifikace, aby bylo zajištěno, že dokáže stabilně zpracovávat zápisy, generovat události replikace, zpracovávat kritická čtení atd. Když je během obnovy po havárii (nebo při údržbě) vyžadováno převzetí služeb při selhání, není neobvyklé, že při propagaci nového hlavního serveru můžete použít horší hardware. Tato situace může být dočasně v pořádku, ale z dlouhodobého hlediska musí být určený hlavní server přiveden zpět, aby vedl replikaci poté, co bude považován za zdravý (nebo je dokončena údržba).
Na rozdíl od převzetí služeb při selhání se operace navrácení služeb při selhání obvykle odehrávají v kontrolovaném prostředí pomocí přepnutí. V panickém režimu se to dělá jen zřídka. Tento přístup poskytuje vašim technikům dostatek času na pečlivé plánování a nacvičování cvičení, aby byl zajištěn hladký přechod. Jeho hlavním cílem je jednoduše vrátit starého dobrého mistra do nejnovějšího stavu a obnovit nastavení replikace do původní topologie. Vzhledem k tomu, že máme co do činění s Amazon RDS, opravdu není nutné, abyste se o tento typ problémů přehnaně starali, protože jde o spravovanou službu a většinu úloh zajišťuje Amazon.
Jak Amazon RDS řeší selhání databáze?
Při nasazování uzlů Amazon RDS můžete svůj databázový cluster nastavit s zónou Multi-Availability Zone (AZ) nebo do zóny Single-Availability Zone. Podívejme se na každý z nich, jak probíhá zpracování převzetí služeb při selhání.
Co je nastavení Multi-AZ?
Když dojde ke katastrofě nebo katastrofě, jako jsou neplánované výpadky nebo přírodní katastrofy, které postihnou instance vaší databáze, Amazon RDS se automaticky přepne do pohotovostní repliky v jiné zóně dostupnosti. Tento AZ se obvykle nachází v jiné pobočce datového centra, často daleko od aktuální zóny dostupnosti, kde jsou umístěny instance. Tyto AZ jsou vysoce dostupné, nejmodernější zařízení chránící instance vaší databáze. Doby převzetí služeb při selhání závisí na dokončení nastavení, které je často založeno na velikosti a aktivitě databáze a také na dalších podmínkách přítomných v době, kdy se primární instance DB stala nedostupnou.
Doby převzetí služeb při selhání jsou obvykle 60–120 sekund. Mohou však být delší, protože velké transakce nebo zdlouhavý proces obnovy mohou prodloužit dobu převzetí služeb při selhání. Po dokončení převzetí služeb při selhání může také trvat delší dobu, než konzola RDS (UI) zohlední novou zónu dostupnosti.
Co je nastavení Single-AZ?
Nastavení Single-AZ by se mělo používat pro instance databáze pouze v případě, že jsou vaše RTO (období obnovy) a RPO (období obnovy) dostatečně vysoké, aby to umožňovaly. S používáním Single-AZ jsou spojena rizika, jako jsou velké prostoje, které by mohly narušit obchodní operace.
Běžné scénáře selhání RDS
Množství prostojů závisí na typu selhání. Pojďme si projít, co to je a jak je řešeno obnovení instance.
Opravitelné selhání instance
Selhání instance Amazon RDS nastane, když dojde k selhání základní instance EC2. Jakmile k tomu dojde, AWS spustí upozornění na událost a odešle vám upozornění pomocí Amazon RDS Event Notifications. Tento systém používá jako procesor výstrah AWS Simple Notification Service (SNS).
RDS se automaticky pokusí spustit novou instanci ve stejné zóně dostupnosti, připojí svazek EBS a pokusí se obnovit. V tomto scénáři je RTO obvykle pod 30 minut. RPO je nula, protože svazek EBS bylo možné obnovit. Svazek EBS je v jediné zóně dostupnosti a tento typ obnovy probíhá ve stejné zóně dostupnosti jako původní instance.
Neopravitelná selhání instance nebo selhání objemu EBS
Pro neúspěšné obnovení instance RDS (nebo pokud podkladový svazek EBS utrpí selhání ztráty dat) je vyžadováno obnovení v určitém okamžiku (PITR). Amazon automaticky nezpracovává PITR, takže musíte buď vytvořit skript pro jeho automatizaci (pomocí AWS Lambda), nebo to udělat ručně.
Časování RTO vyžaduje spuštění nové instance Amazon RDS, která bude mít po vytvoření nový název DNS, a poté použití všech změn od poslední zálohy.
RPO obvykle trvá 5 minut, ale můžete jej zjistit zavoláním RDS:describe-db-instances:LatestRestorableTime. Doba se může lišit od 10 minut do hodin v závislosti na počtu polen, které je třeba použít. Lze ji určit pouze testováním, protože závisí na velikosti databáze, počtu změn provedených od poslední zálohy a úrovních zátěže databáze. Vzhledem k tomu, že zálohy a transakční protokoly jsou uloženy v Amazon S3, může k tomuto obnovení dojít v jakékoli podporované zóně dostupnosti v regionu.
Jakmile je vytvořena nová instance, budete muset aktualizovat název koncového bodu klienta. Máte také možnost ji přejmenovat na název koncového bodu staré instance DB (to však vyžaduje odstranění staré neúspěšné instance), ale to znemožňuje určení hlavní příčiny problému.
Narušení zóny dostupnosti
Narušení zóny dostupnosti mohou být dočasná a jsou vzácná, pokud je však selhání AZ trvalejší, instance bude nastavena do stavu selhání. Obnova by fungovala tak, jak bylo popsáno dříve, a nová instance by mohla být vytvořena v jiném AZ pomocí obnovení v určitém okamžiku. Tento krok je nutné provést ručně nebo pomocí skriptu. Strategie pro tento typ scénáře obnovy by měla být součástí vašich větších plánů obnovy po havárii (DR).
Pokud je selhání zóny dostupnosti dočasné, databáze bude mimo provoz, ale zůstane v dostupném stavu. Jste zodpovědní za monitorování na úrovni aplikace (pomocí nástrojů Amazonu nebo třetích stran), abyste zjistili tento typ scénáře. Pokud k tomu dojde, můžete počkat, až se zóna dostupnosti obnoví, nebo se můžete rozhodnout obnovit instanci do jiné zóny dostupnosti s obnovením v určitém okamžiku.
RTO by byl čas, který zabere spuštění nové instance RDS a následné použití všech změn od poslední zálohy. RPO může být delší až do doby, kdy došlo k selhání zóny dostupnosti.
Testování funkce Failover a Failback na Amazon RDS
Vytvořili jsme a nastavili jsme Amazon RDS Aurora pomocí db.r4.large s nasazením Multi-AZ (které vytvoří repliku/čtečku Aurora v jiném AZ), které je dostupné pouze přes EC2. Pokud chcete jako mechanismus převzetí služeb při selhání používat službu Amazon RDS, musíte se ujistit, že jste tuto možnost vybrali při vytváření.
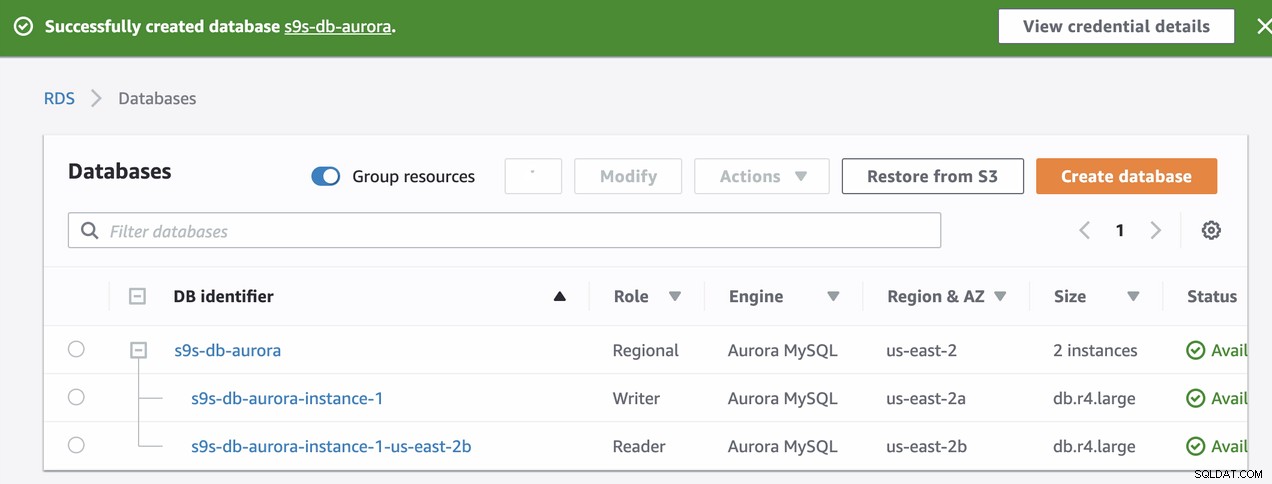
Během zřizování naší instance RDS to trvalo asi 11 minut, než instance se staly dostupnými a přístupnými. Níže je snímek obrazovky uzlů dostupných v RDS po vytvoření:
Tyto dva uzly budou mít své vlastní určené názvy koncových bodů, které budeme slouží k připojení z pohledu klienta. Nejprve jej ověřte a zkontrolujte základní název hostitele pro každý z těchto uzlů. Chcete-li to zkontrolovat, můžete spustit tento příkaz bash níže a podle toho nahradit názvy hostitelů / koncových bodů:
example@sqldat.com:~# host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done;
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Výsledek se vyjasňuje následovně,
s9s-db-aurora-instance-1 = s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-0-94 (read-write)
s9s-db-aurora-instance-1-us-east-2b = s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-1-139 (read-only)Simulace Amazon RDS Failover
Nyní nasimulujeme selhání, abychom simulovali převzetí služeb při selhání pro instanci zapisovače Amazon RDS Aurora, což je s9s-db-aurora-instance-1 s koncovým bodem s9s-db-aurora.cluster-cmu8qdlvkepg.us -východ-2.rds.amazonaws.com.
Chcete-li to provést, připojte se k instanci svého zapisovače pomocí příkazového řádku klienta mysql a poté zadejte níže uvedenou syntaxi:
ALTER SYSTEM SIMULATE percentage_of_failure PERCENT DISK FAILURE [ IN DISK index | NODE index ]
FOR INTERVAL quantity [ YEAR | QUARTER | MONTH | WEEK| DAY | HOUR | MINUTE | SECOND ];Vydání tohoto příkazu má detekci obnovení Amazon RDS a působí velmi rychle. Přestože je dotaz pro testovací účely, může se lišit, pokud k tomuto výskytu dojde ve skutečné události. Možná vás bude zajímat více o testování selhání instance v jejich dokumentaci. Podívejte se, jak jsme dopadli níže:
mysql> ALTER SYSTEM SIMULATE 100 PERCENT DISK FAILURE FOR INTERVAL 3 MINUTE;
Query OK, 0 rows affected (0.01 sec)Spuštění příkazu SQL výše znamená, že musí simulovat selhání disku po dobu alespoň 3 minut. Sledoval jsem bod v čase zahájení simulace a trvalo asi 18 sekund, než začalo převzetí služeb při selhání.
Podívejte se níže na to, jak RDS zpracovává selhání simulace a převzetí služeb při selhání,
Tue Sep 24 10:06:29 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
….
…..
………..
Tue Sep 24 10:06:44 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
……..
………..
Tue Sep 24 10:06:51 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
….
………..
…………………
Tue Sep 24 10:07:13 UTC 2019
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Výsledky této simulace jsou docela zajímavé. Vezměme to jeden po druhém.
- Kolem 10:06:29 jsem začal spouštět simulační dotaz, jak je uvedeno výše.
- Kolem 10:06:44 se ukazuje, že koncový bod s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com s přiřazeným názvem hostitele ip-10-20-1- 139 kde se ve skutečnosti jedná o instanci pouze pro čtení, byla nepřístupná, nicméně simulační příkaz byl spuštěn pod instancí pro čtení a zápis.
- Kolem 10:06:51 ukazuje, že koncový bod s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com s přiřazeným názvem hostitele ip-10-20-1- 139 je aktivní, ale má označení jako stav čtení-zápis. Vezměte na vědomí, že proměnná innodb_read_only, pro instance spravované Aurora MySQL, je to její identifikátor, který určuje, zda je hostitel uzel pouze pro čtení-zápis nebo pouze pro čtení, a Aurora také běží pouze na úložišti InnoDB pro instance kompatibilní s MySQL.
- Kolem 10:07:13 se pořadí změnilo. To znamená, že bylo provedeno převzetí služeb při selhání a instance byly přiřazeny k jeho určeným koncovým bodům.
Podívejte se na výsledek níže, který je zobrazen v konzole RDS:
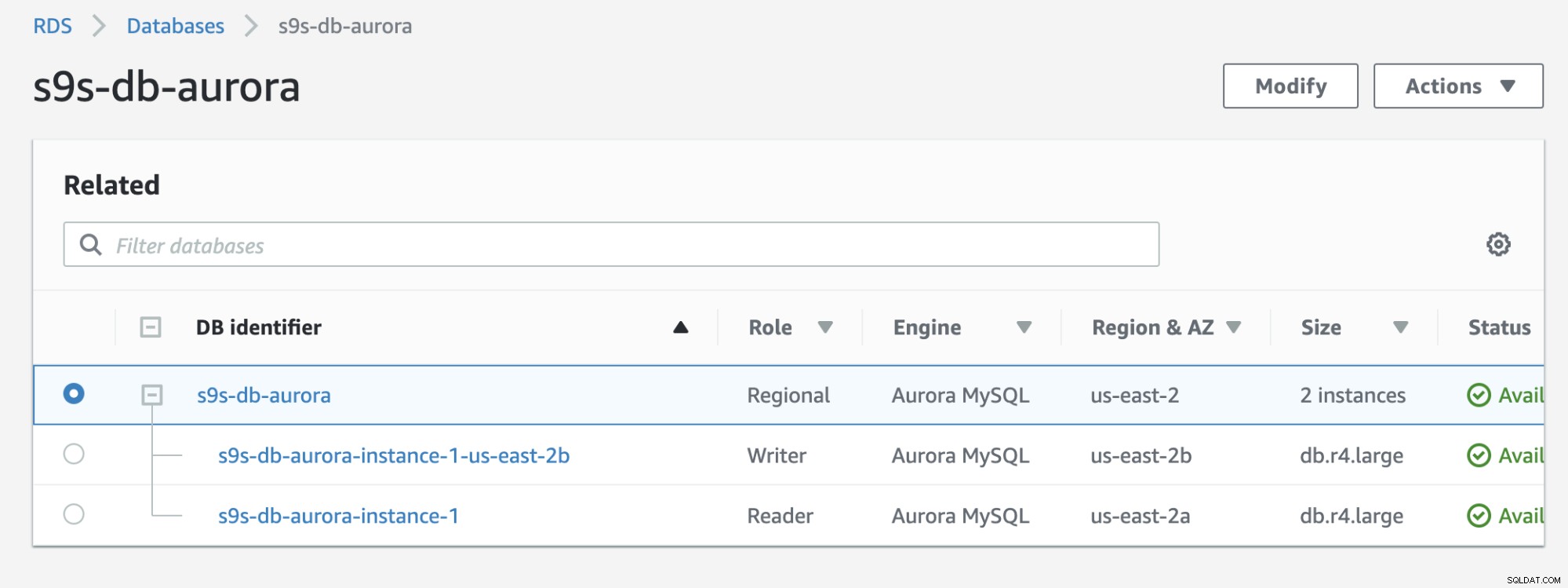
Pokud porovnáte s předchozím, s9s-db-aurora- instance-1 byl čtenář, ale po převzetí služeb při selhání byl povýšen jako zapisovatel. Proces včetně testu zabral k dokončení úkolu přibližně 44 sekund, ale převzetí služeb při selhání ukazuje dokončeno za téměř 30 sekund. To je působivé a rychlé pro převzetí služeb při selhání, zvláště vezmeme-li v úvahu, že se jedná o databázi spravovaných služeb; což znamená, že se nemusíte starat o žádné problémy s hardwarem nebo údržbou.
Provedení zálohy při selhání v Amazon RDS
Failback v Amazon RDS je docela jednoduchý. Než to projdeme, přidejme novou repliku čtečky. Potřebujeme možnost otestovat a identifikovat, z jakého uzlu by AWS RDS vybralo, když se pokusí o návrat k požadovanému masteru (nebo failback k předchozímu masteru), a abychom zjistili, zda vybere správný uzel na základě priority. Aktuální seznam instancí a jeho koncové body jsou uvedeny níže.
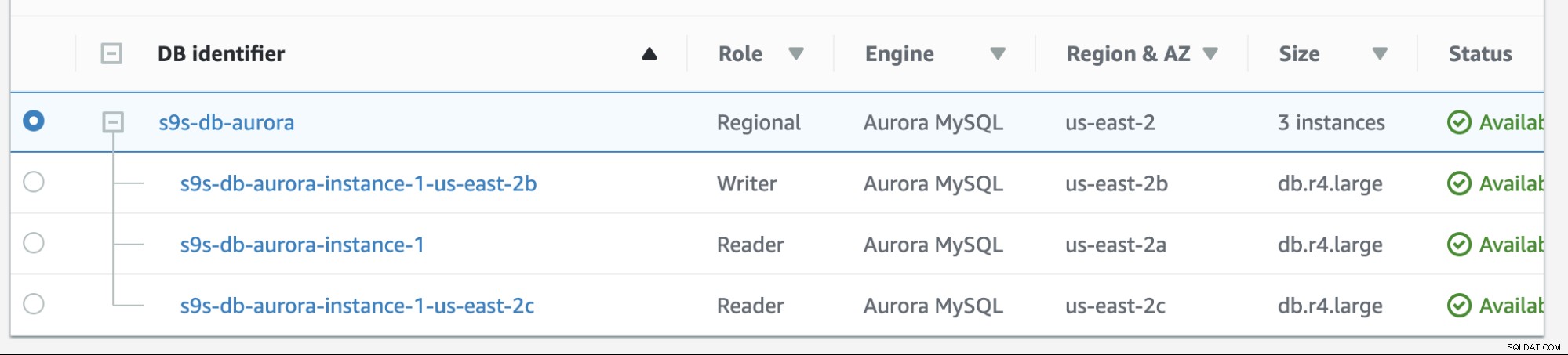

Nová replika je umístěna na us-východ-2c AZ s názvem hostitele db z IP-10-20-2-239.
Pokusíme se provést obnovu při selhání s použitím instance s9s-db-aurora-instance-1 jako požadovaného cíle zpětného volání. V tomto nastavení máme dvě instance čtečky. Abyste zajistili, že během převzetí služeb při selhání bude vyzvednut správný uzel, budete muset určit, zda je priorita nebo dostupnost nahoře (vrstva 0> vrstva-1> vrstva-2 atd. až do úrovně 15). To lze provést úpravou instance nebo během vytváření repliky.
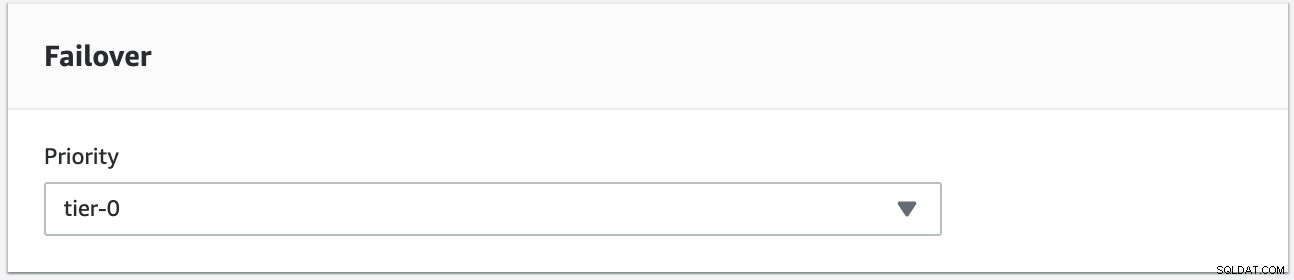
Můžete si to ověřit ve své konzoli RDS.
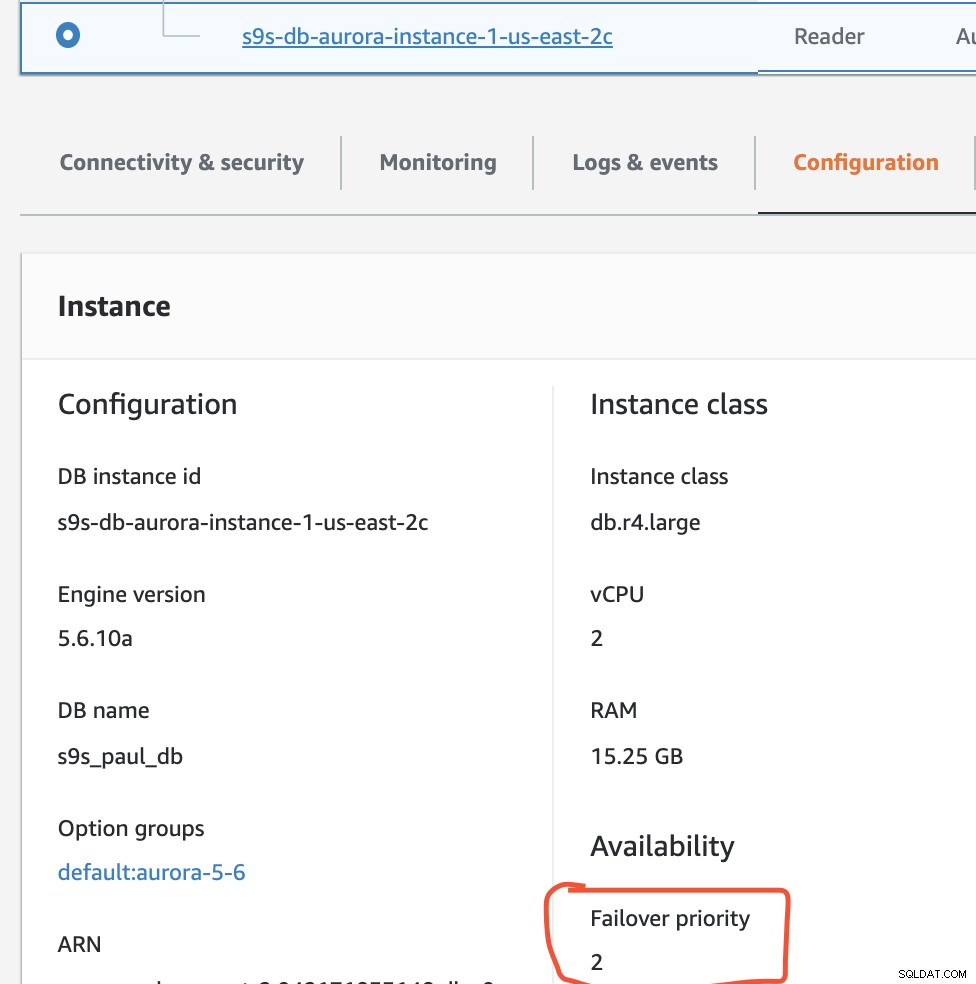
V tomto nastavení má prioritu s9s-db-aurora-instance-1 =0 (a je replikou pro čtení), s9s-db-aurora-instance-1-us-east-2b má prioritu =1 (a je aktuálním zapisovatelem) a s9s-db-aurora-instance-1-us- východ-2c má prioritu =2 (a je také replikou pro čtení). Podívejme se, co se stane, když se pokusíme o failback.
Stav můžete sledovat pomocí tohoto příkazu.
$ host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); while true; do echo -e "\n==========================================="; date; echo -e "===========================================\n"; for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done; sleep 1; done;Po spuštění převzetí služeb při selhání dojde k návratu k našemu požadovanému cíli, kterým je uzel s9s-db-aurora-instance-1.
===========================================
Tue Sep 24 13:30:59 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
…
……
………
===========================================
Tue Sep 24 13:31:35 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
…..
===========================================
Tue Sep 24 13:31:38 UTC 2019
===========================================
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Pokus o obnovení služby začal ve 13:30:59 a skončil kolem 13:31:38 (nejbližší značka 30 sekund). V tomto testu to skončí ~32 sekund, což je stále rychlé.
Ověřil jsem převzetí služeb při selhání/vrácení služeb při selhání několikrát a neustále vyměňuje svůj stav čtení a zápisu mezi instancemi s9s-db-aurora-instance-1 a s9s-db-aurora-instance-1- us-východ-2b. To ponechává s9s-db-aurora-instance-1-us-east-2c bez výběru, pokud oba uzly nemají problémy (což je velmi vzácné, protože se všechny nacházejí v různých AZ).
Během pokusů o převzetí služeb při selhání/navrácení služeb při selhání běží RDS rychlým přechodovým tempem během převzetí služeb při selhání přibližně za 15–25 sekund (což je velmi rychlé). Mějte na paměti, že v této instanci nemáme uložené velké datové soubory, ale stále je to docela působivé vzhledem k tomu, že není co dále spravovat.
Závěr
Spuštění Single-AZ představuje nebezpečí při provádění převzetí služeb při selhání. Amazon RDS vám umožňuje upravit a převést váš Single-AZ na nastavení podporující Multi-AZ, i když to pro vás bude znamenat určité náklady. Single-AZ může být v pořádku, pokud jste v pořádku s vyšší dobou RTO a RPO, ale rozhodně se nedoporučuje pro vysoce provozované, kritické obchodní aplikace.
S Multi-AZ můžete automatizovat převzetí služeb při selhání a navrácení služeb při selhání na Amazon RDS a věnovat svůj čas ladění dotazů nebo optimalizaci. To usnadňuje mnoho problémů, kterým čelí DevOps nebo DBA.
I když může Amazon RDS v některých organizacích způsobit dilema (protože není agnostik platformy), stále stojí za zvážení; zvláště pokud vaše aplikace vyžaduje dlouhodobý plán DR a nechcete trávit čas starostmi s plánováním hardwaru a kapacity.