Kamery, otočné dveře, výtahy, teplotní čidla, alarmy – všechna tato zařízení produkují velké množství vzájemně propojených signálů, které souvisejí s událostmi kolem nás. Nyní si představte, že jste člověk, který potřebuje sledovat stavy, vytvářet zprávy v reálném čase a předpovídat na základě všech těchto signálů. Chcete-li to provést, musíte tato data nejprve uložit. Datový model, který takové zpracování signálu podporuje, je tématem dnešního článku.
Nejjednodušší způsob, jak uložit příchozí signály, by bylo jednoduše uložit jejich textovou reprezentaci do jednoho velkého seznamu. Tento přístup by nám umožnil provádět vkládání rychle, ale aktualizace by byly problematické. Takový model by také nebyl normalizován, a proto se tímto směrem nevydáme.
Vytvoříme normalizovaný datový model, který lze použít k ukládání dat generovaných různými zařízeními a také definujeme, jak spolu zařízení souvisí. Takový model by efektivně uložil vše, co potřebujeme, a mohl by být také použit pro analýzy a prediktivní analýzy.
Datový model
Datový model zpracování signálu
Model se skládá ze tří tematických oblastí:
ComplexesInstallations & DevicesSignals & Events
Každou z těchto tematických oblastí popíšeme v pořadí, v jakém jsou uvedeny.
Komplexy
Při vytváření tohoto datového modelu jsem vycházel z předpokladu, že jej použijeme ke sledování toho, co se děje ve větších komplexech. Komplexy se liší velikostí od jednolůžkového pokoje až po nákupní centrum. Je důležité, aby každý komplex měl alespoň jedno zařízení/senzor, ale pravděpodobně jich bude mít mnohem více.
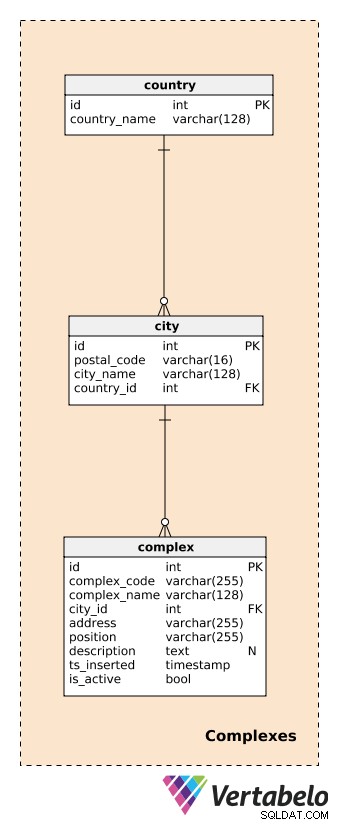
Než popíšeme komplexy, musíme definovat tabulky manipulující se zeměmi a městy. Ty poskytnou poměrně podrobný popis umístění každého komplexu.
Pro každou country , uložíme jeho UNIKÁTNÍ country_name; pro každé city , uložíme UNIKÁTNÍ kombinaci postal_code , city_name a country_id . Nebudu zde zacházet do podrobností a budeme předpokládat, že každé město má pouze jedno PSČ. Ve skutečnosti bude mít většina měst více než jedno PSČ; v takovém případě můžeme použít hlavní kód pro každé město.
complex je skutečná budova nebo místo, kde jsou instalována zařízení generující data. Jak již bylo řečeno, komplexy se mohou lišit od jedné místnosti nebo měřicí stanice až po mnohem větší místa, jako jsou parkoviště, nákupní centra, kina atd. Jsou předmětem naší analýzy. Chceme mít možnost sledovat, co se děje na komplexní úrovni v reálném čase a později vytvářet reporty a analýzy. Pro každý komplex definujeme:
complex_code– UNIKÁTNÍ identifikátor pro každý komplex. I když máme samostatný atribut primárního klíče (id) u této tabulky můžeme očekávat, že zdědíme jiný identifikační kód pro každý komplex z jiného systému.complex_name– Název používaný k popisu tohoto komplexu. V případě nákupních center a kin by to mohl být jejich skutečný a známý název; pro měřicí stanici bychom mohli použít obecný název.city_id– Odkaz na město, kde se areál nachází.address– Fyzická adresa tohoto komplexu.position– Poloha komplexu (tj. zeměpisné souřadnice) definovaná v textovém formátu.description– Textový popis, který blíže popisuje tento komplex.ts_inserted– Časové razítko, kdy byl tento záznam vložen.is_active– Booleovská hodnota označující, zda je tento komplex stále aktivní nebo ne.
Instalace a zařízení
Nyní se přibližujeme k srdci našeho modelu. Pravděpodobně budeme mít v každém komplexu nainstalováno několik zařízení. Téměř jistě tato zařízení seskupíme podle jejich účelu – např. mohli bychom umístit kamery, dveřní senzory a motor používaný k otevírání a zavírání dveří do skupiny, protože spolupracují.
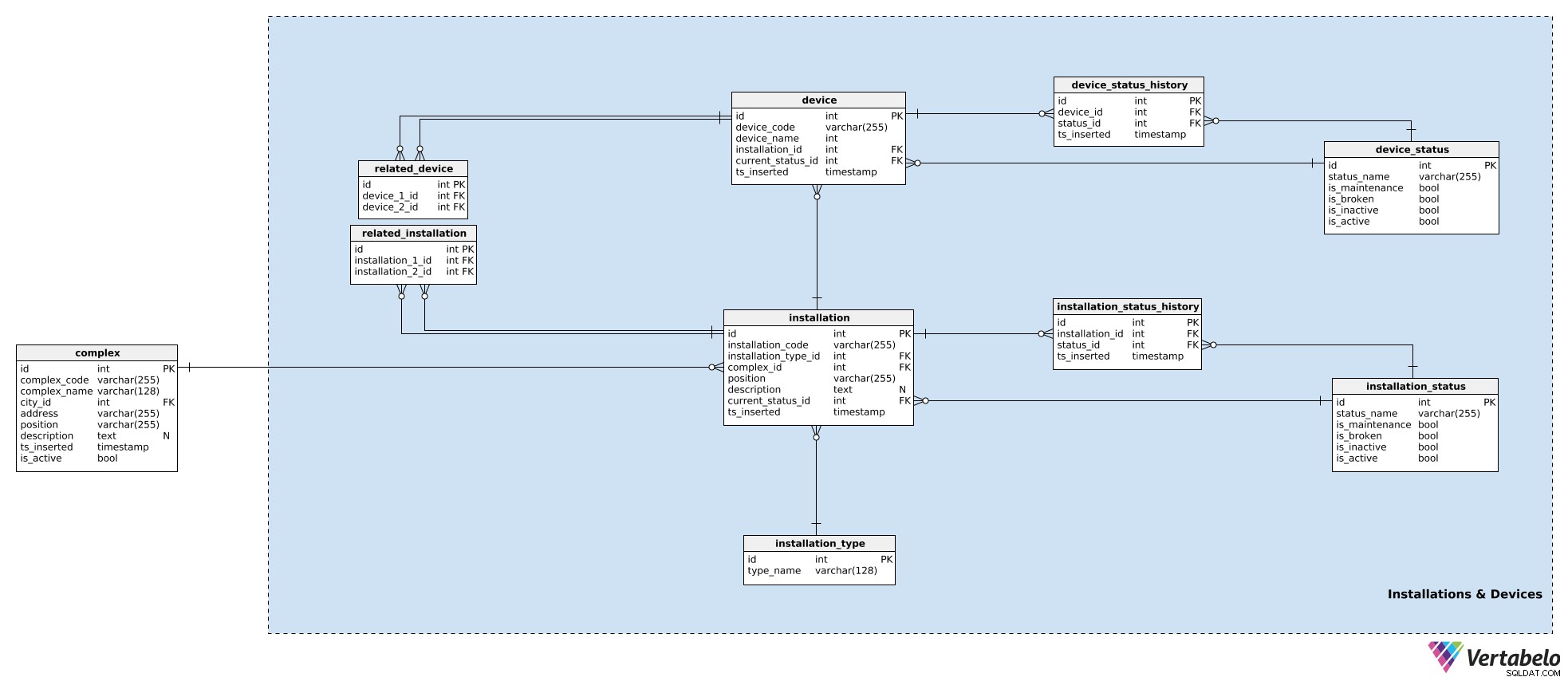
V našem modelu jsou zařízení, která spolupracují v jednom komplexu, seskupena do instalací. Mohou to být vstupní dveře, eskalátory, teplotní čidla atd. Pro každou instalaci uložíme do installation tabulka:
installation_code– UNIKÁTNÍ kód používaný k označení této instalace.installation type_id– Odkaz nainstallation_typeslovník. Tento slovník ukládá pouze UNIKÁTNÍtype_nameatribut, který popisuje typ, např. eskalátor, výtah.complex_id– Odkaz nacomplexže instalace patří.position– Souřadnice v textovém formátu této instalace uvnitř komplexu.description– Textový popis této instalace.current_status_id– Odkaz na aktuální stav (zinstallation_statustabulky) této instalace.ts_inserted– Časové razítko, kdy byl tento záznam vložen do našeho systému.
Stavy instalace jsme již zmínili. Seznam všech možných stavů je uložen v installation_status slovník. Každý stav je JEDINEČNĚ definován svým status_name . Kromě toho budeme ukládat příznaky označující, zda tento stav při použití znamená, že instalace is_broken , is_inactive , is_maintenance nebo is_active . Najednou by měl být nastaven pouze jeden z těchto příznaků.
Instalaci jsme již přiřadili aktuální stav. Pokud budeme sledovat, co se děje se zařízením, musíme také uložit jeho historii. K tomu použijeme ještě jednu tabulku, installation_status_history . Pro každý záznam zde uložíme odkazy na související instalaci a stav a také okamžik (ts_inserted ), kdy byl tento stav přidělen.
Instalace jsou součástí našich komplexů. I když je každá instalace jedinou entitou, stále může souviset s jinými instalacemi. (Např. videosystém u předního vchodu nákupního centra zjevně souvisí s předními dveřmi nákupního centra – lidé budou nejprve spatřeni kamerou a poté se dveře otevřou.) Pokud chceme tyto vztahy sledovat, uložíme je v related_installation stůl. Upozorňujeme, že tato tabulka obsahuje pouze UNIKÁTNÍ páry dvou klíčů, přičemž oba odkazují na installation stůl.
Stejná logika se používá pro ukládání zařízení. Zařízení jsou jednotlivé kusy hardwaru, které produkují signály, které nás zajímají. Zatímco instalace patří do komplexů, zařízení patří k instalacím. Pro každé device , uložíme:
device_code– UNIKÁTNÍ způsob, jak označit každé zařízení.device_name– Název tohoto zařízení.installation_id– Odkaz na instalaci, ke které toto zařízení patří.current_status_id– Aktuální stav zařízení.ts_inserted– Časové razítko, kdy byl tento záznam vložen.
Stejným způsobem se zachází se stavy. Použijeme device_status tabulka pro uložení seznamu všech možných stavů zařízení. Tato tabulka má stejnou strukturu jako installation_status a atributy se používají stejným způsobem. Důvodem existence dvou samostatných stavových slovníků je to, že zařízení a jejich instalace mohou mít různé stavy – alespoň podle názvu.
Aktuální stav je uložen v device.current_status_id atribut a historie stavu je uložena v device_status_history stůl. Pro každý záznam zde uložíme vztahy k zařízení a stavu a také okamžik, kdy byl tento záznam vložen.
Poslední tabulkou v této oblasti je related_device stůl. I když je celkem zřejmé, že všechna zařízení ve stejné instalaci spolu úzce souvisejí, chci mít možnost spojit jakákoli dvě zařízení patřící k jakékoli instalaci. Uděláme to uložením jejich dvou ID zařízení do této tabulky.
Signály a události
Nyní jsme připraveni na srdce celého modelu.
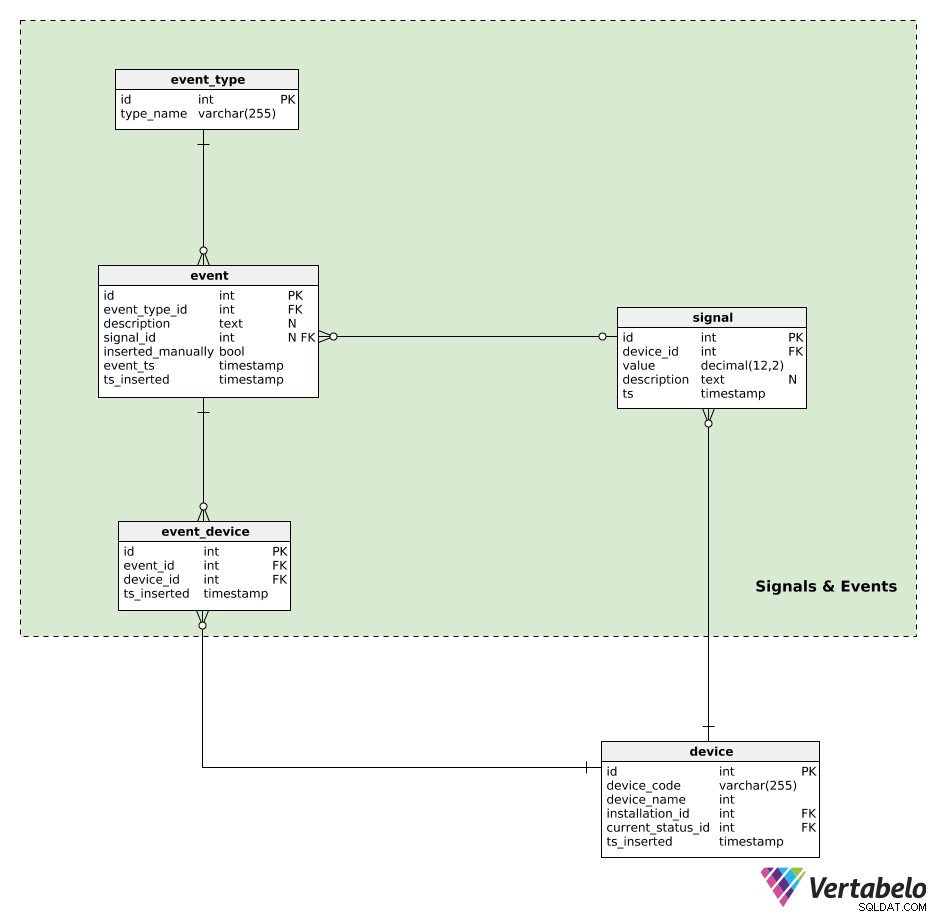
Zařízení generují signály. Všechna data signálu jsou uchovávána v signal stůl. Pro každý signál uložíme:
device_id– Odkaz na zařízení, které tento signál vygenerovalo.value– Číselná hodnota tohoto signálu.description– Textová hodnota, která by mohla obsahovat jakékoli další parametry (např. typ signálu, hodnoty, použitá jednotka měření) související s tímto jediným signálem. Tato data jsou uložena ve formátu podobném JSON.ts– Časové razítko, kdy byl tento signál vložen do tabulky.
Můžeme očekávat, že tento stůl bude extrémně náročný na používání s velkým počtem vložek za sekundu. Údržba databáze by se proto měla zaměřit na sledování velikosti této tabulky.
Poslední věc, kterou chci udělat, je přidat události do našeho datového modelu. Události mohou být automaticky generovány signálem nebo vkládány ručně. Jedna automaticky generovaná událost může být „dveře otevřené na 5 minut“, zatímco ručně vložená událost může být „zařízení muselo být kvůli tomuto signálu vypnuto“. Celá myšlenka spočívá v ukládání akcí, ke kterým došlo v důsledku chování zařízení. Později bychom mohli tyto události použít při provádění analýzy chování zařízení.
Události budou rozděleny podle event_type . Každý typ je JEDNOZNAČNĚ definován svým type_name .
Všechny automaticky generované nebo ručně vložené události jsou zaznamenány v event stůl. Pro každý záznam zde uložíme:
event_type_id– Odkaz na související typ události.description– Textový popis této události.signal_id– Odkaz na signál, pokud existuje, který událost způsobil.inserted_manually– Příznak označující, zda byl tento záznam vložen ručně nebo ne.event_tsats_inserted– Časová razítka, kdy se tato událost skutečně stala a kdy byl vložen její záznam. Tyto dva se mohou lišit, zvláště když jsou záznamy událostí vkládány ručně.
Poslední tabulkou v našem modelu je event_device stůl. Tato tabulka se používá ke spojení událostí se všemi zapojenými zařízeními. Pro každý záznam uložíme UNIKÁTNÍ pár event_id – device_id a časové razítko, kdy byl záznam vložen.
Co si myslíte o našem datovém modelu zpracování signálu?
Dnes jsme analyzovali zjednodušený datový model, který bychom mohli použít ke sledování signálů ze sady zařízení nainstalovaných na různých místech. Samotný model by měl stačit k uložení všeho, co potřebujeme ke sledování stavů a provádění analýz. Přesto je možná spousta vylepšení. Co bychom mohli přidat? Řekněte nám to prosím v komentářích níže.