Jak se všechna data o veřejném mínění ukládají? Podíváme se na datový model průzkumu veřejného mínění.
Každý chce vědět, co si myslí veřejnost, od politiků a firem až po jednotlivce, kteří chtějí vědět, co si o určitém tématu myslí ostatní. Tento druh práce obvykle vykonávají agentury, které se na tento typ výzkumu specializují.
Dnes se podíváme na datový model, který by taková agentura mohla použít k ukládání všech relevantních dat z průzkumů, od otázek a předdefinovaných odpovědí až po skutečnou zpětnou vazbu. Tato data by byla později použita k vytváření různých sestav. Takže začněme.
Nápad
Ankety lze vytvářet kdekoli. Mohly by být dobře naplánované a zahrnovat reprezentativní vzorek veřejnosti (na základě demografie). Nebo je můžete udělat na místě, např. pokud chcete předpovídat výsledky voleb na základě vzorku (např. exit poll), pravděpodobně byste se zeptali lidí ve volební místnosti, jak hlasovali.
Na druhou stranu, pokud chcete vytvořit stejný průzkum před volbami, pravděpodobně byste vybrali vzorek a kontaktovali jednotlivce telefonicky nebo osobně. Obvykle je pro tento typ průzkumu jen několik otázek – některé se týkají demografických údajů a jiné toho, co nás skutečně zajímá.
Ankety mohou být i mnohem složitější, např. pokud chcete znát veřejné mínění o určitém produktu, pokrývající vše od jeho výkonu až po jeho balení.
V tomto článku nebudu diskutovat o tom, jak vybrat vzorovou skupinu lidí; spíše se zaměřím na samotnou anketu, její otázky a odpovědi.
Datový model
Datový model agentury pro veřejné mínění
Model se skládá ze tří tematických oblastí:
PollsQuestions & AnswersResult
Každou předmětovou oblast popíšeme v pořadí, v jakém jsou uvedeny.
Ankety
Než začneme klást otázky, musíme definovat, co nás zajímá. V této sekci definujeme ankety a dotazníky a v další přidáme otázky a odpovědi.
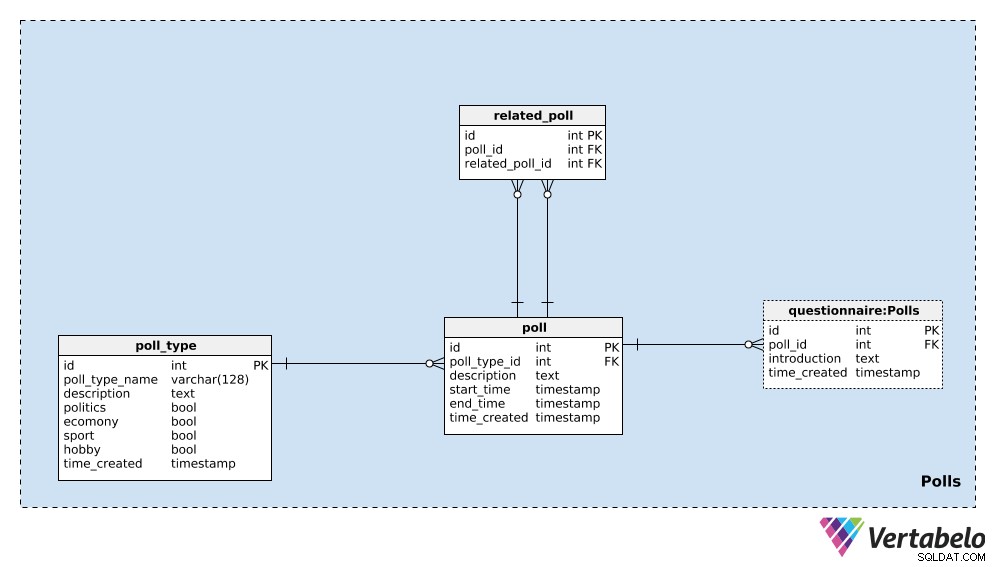
Začneme u poll_type slovník. Dá se očekávat, že budeme většinou opakovat ankety stejného typu. Nejběžnějším typem jsou pravděpodobně volební průzkumy, ale chceme mít možnost průběžně přidávat nové typy průzkumů. Pro každý typ ankety uložíme UNIKÁTNÍ poll_type_name a použijte description atribut pro poskytnutí dalších podrobností.
Čtyři příznaky – politics , economy , sport a hobby – se používají k označení typu ankety. Průzkum by se mohl týkat jednoho nebo více těchto témat; v případě potřeby bychom mohli tyto kategorie rozdělit do samostatného slovníku a mít vztah mnoho k mnoha mezi tímto slovníkem a poll_type tabulka.
Poslední atribut v této tabulce je time_created . Označuje okamžik, kdy je do této tabulky vložen řádek.
Další věc, kterou musíme udělat, je definovat jeden poll . Jedná se o jeden případ, např. „Prezidentské volby v roce 2020 ve Spojených státech – průzkum v dubnu 2020“ . Pro každou anketu uložíme následující podrobnosti:
poll_type_id– Odkaz napoll_type.description– Všechny podrobnosti týkající se tohoto hlasování v textovém formátu.start_timeaend_time– Definované počáteční a koncové časy, během kterých se toto hlasování provádí.time_created– Skutečný okamžik, kdy bylo toto hlasování vytvořeno.
Ankety spolu mohou souviset. Na příkladu „Prezidentské volby v roce 2020 ve Spojených státech – průzkum z dubna 2020“ , mohli bychom udělat stejnou anketu příští měsíc, abychom viděli nejaktuálnější názory. Nazvali bychom to „Prezidentské volby ve Spojených státech 2020 – průzkum v květnu 2020“ . Tyto dva průzkumy spolu souvisí, protože jejich výsledky ukazují trendy. K vytvoření tohoto vztahu použijeme related_poll stůl v našem modelu. Obsahuje pouze UNIKÁTNÍ pár poll_id – related_poll_id , označující anketu a jejího předchůdce.
Všimněte si, že tuto tabulku můžeme použít k uložení všech dotazování, které spolu jakýmkoli způsobem souvisí, nejen předchůdců/následníků. Pokud bychom chtěli definovat různé vztahy, museli bychom přidat další slovník – ale tímto způsobem v tomto článku nepůjdeme.
Poslední tabulkou v této tematické oblasti je questionnaire stůl. Ve většině případů bude mít každý průzkum přesně jeden dotazník, ale chci ponechat možnost, že bychom jich mohli mít v případě potřeby více. Proto jsem použil samostatnou tabulku. V této tabulce uložíme pouze ID souvisejícího průzkumu (poll_id ), introduction popisující tento dotazník a časové razítko, kdy byl záznam vložen (time_created ).
Otázky a odpovědi
Nyní jsme připraveni vytvořit všechny podrobnosti dotazníku. Můžeme také uvést všechny otázky, které chceme položit, a také všechny předdefinované odpovědi.
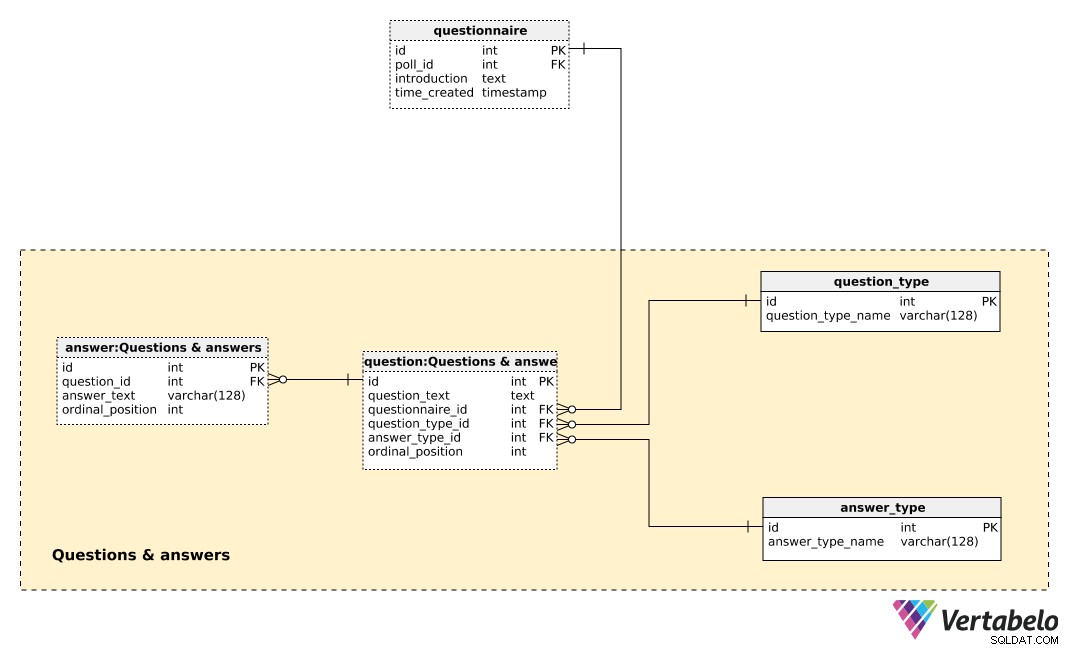
Ústřední tabulkou v této oblasti je question stůl. Každá otázka je definována následujícími detaily:
question_text– Text, který se zobrazí každému dotazovanému.questionnaire_id– Odkaz označující dotazník k této otázce.question_type_id– Odkaz označujícíquestion_type, který je JEDNOZNAČNĚ označenquestion_type_name. Jde v zásadě o kategorie, kupř. „demografie“, „názor“, „kontrola“ atd. To by nám umožnilo oddělit demografické a názorové otázky a najít mezi nimi korelaci.answer_type_id– Odkaz na typ odpovědi, který bude pro tuto otázku použit. Každýanswer_typeje JEDINEČNĚ definován pomocíanswer_type_namea označuje způsob zobrazení odpovědi. Některé očekávané typy jsou „otevřené“, „seznam“, „zaškrtávací políčko“ a „více“.ordinal_position– Tato hodnota označuje pozici této otázky v dotazníku. Společně squestionnaire_id, tvoří alternativní klíč této tabulky.
Seznam všech předdefinovaných odpovědí je uložen v answer stůl. Pokud není typ otázky otevřený (tj. text nezadá jednotlivec), budeme mít sadu předdefinovaných odpovědí. Pro každou odpověď definujeme otázku, ke které patří (question_id ), answer_text a ordinal_position té odpovědi uvnitř té otázky. Ještě jednou UNIKÁTNÍ pár – tentokrát question_id – ordinal_position – tvoří alternativní klíč této tabulky.
Výsledek
V předchozích dvou tematických oblastech jsme definovali vše, co potřebujeme k vytvoření ankety a zahájení kladení otázek. Nyní potřebujeme definovat datovou strukturu pro uložení aktuálních odpovědí.
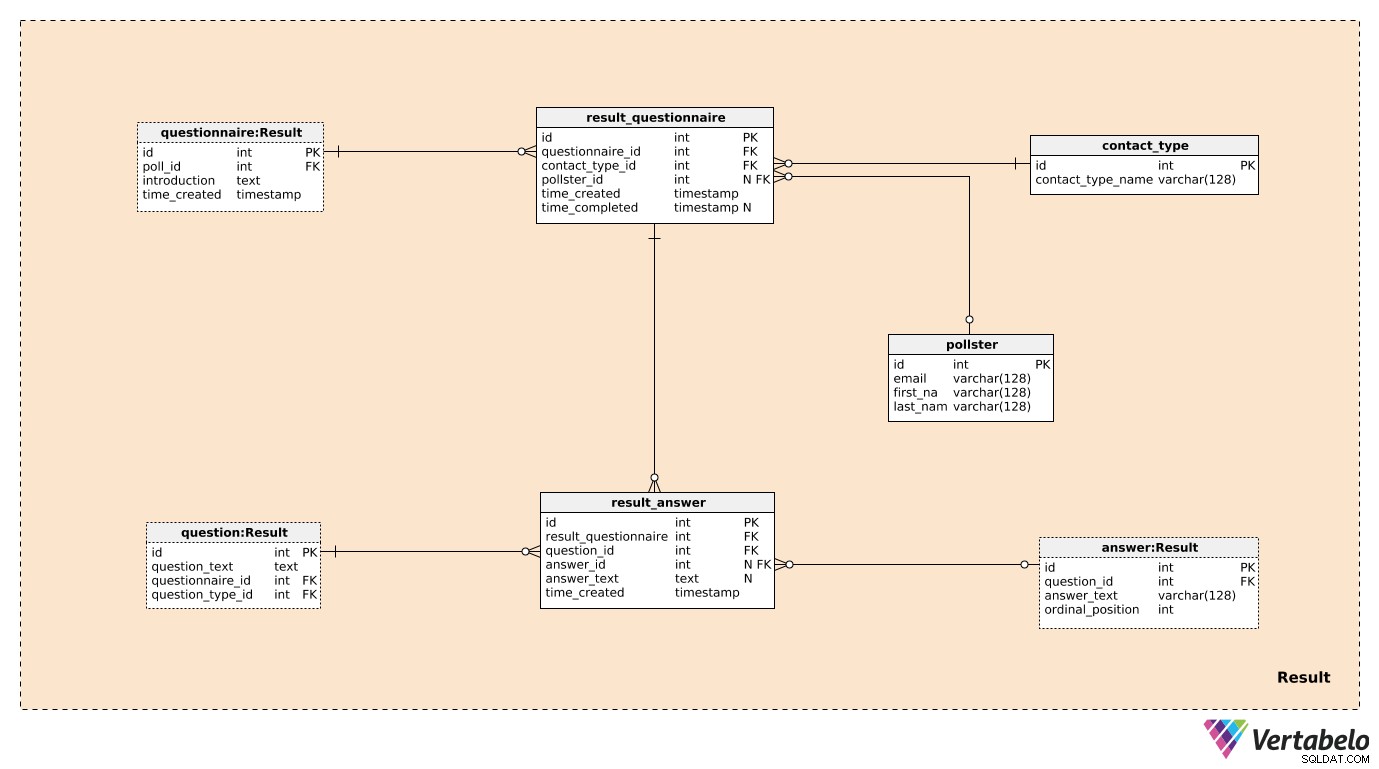
Tři ze sedmi tabulek ve Result předmětná oblast byla zmíněna a popsána dříve. Jedná se o questionnaire , question a answer . Zbývající čtyři tabulky slouží k uložení toho, co nás skutečně zajímá.
Vytvoříme jeden záznam v result_questionnaire tabulka pro každého jednotlivce účastnícího se ankety. questionnaire_id poskytnout esus všechny informace o příslušné anketě. contact_type_id je odkaz na contact_type slovník. Hodnoty v této tabulce popisují způsob, jakým jsme s touto osobou komunikovali. Tyto hodnoty jsou JEDINEČNĚ definovány contact_type_name hodnotu a může to být něco jako „telefon“, „osobně“, „e-mail“, „webový formulář“ atd.
pollster_id atribut je odkaz na pollster tabulka, která poskytuje informace o tom, kdo provedl daný skutečný průzkum. Pro každého pollster , uložíme pouze jejich UNIKÁTNÍ e-mail a jejich first_name a last_name . time_created atribut označuje skutečný čas, kdy byl tento záznam vytvořen, zatímco time_completed bude nastavena v okamžiku dokončení tohoto průzkumu. (Do té doby bude mít hodnotu NULL).
Poslední tabulkou v modelu je result_answer stůl. Jak název napovídá, zde budeme ukládat skutečné odpovědi, které jsme dostali od účastníků průzkumu. Pro každý záznam v této tabulce budeme mít:
result_questionnaire_id– Odkaz na příslušný dotazník.question_id– Odkaz označující otázku zodpovězenou touto odpovědí.answer_id– Odkaz na odpověď, která byla použita k odpovědi na tuto otázku. Tento atribut bude obsahovat hodnotu NULL, pokud je otázka „otevřeného“ typu (protože nebyly na výběr žádné předdefinované odpovědi).answer_text– Text, který byl vložen jako odpověď na tuto otázku. Tento atribut bude obsahovat hodnotu, když byla otázka „otevřená“; ve všech ostatních případech bude mít hodnotu NULL.time_created– Skutečný čas, kdy byla tato odpověď vložena do našeho systému.
Možná vylepšení
Zatím jsme se zabývali tím, jak bychom mohli ukládat data z průzkumů. Nediskutovali jsme o tom, co bychom s daty udělali po uzavření hlasování. Můžeme očekávat, že stará data v budoucnu nebudeme potřebovat, alespoň ne v naší provozní databázi. Proto bychom mohli udělat dvě věci:
- Uložte shrnutí hlasování do samostatné tabulky v provozní databázi. Tím bychom tyto informace měli k dispozici, pokud bychom chtěli vidět, co se stalo s podobným průzkumem.
- Všechna data dotazování uložte do záložní databáze, která měla stejnou strukturu jako provozní databáze. To nám umožní přístup k podrobnostem, když je budeme potřebovat.
Mohli bychom také vytvořit datový sklad pro ukládání výsledků průzkumu, ale to by nebylo nutné, pokud bychom již provedli úkoly popsané ve dvou odrážkách.
Co si myslíte o našem datovém modelu průzkumu veřejného mínění?
Rádi bychom slyšeli váš názor na to, co bychom mohli změnit, abychom zlepšili datový model průzkumu veřejného mínění. Máte zkušenosti z oboru? Myslíte, že nám něco uniklo? Přidáte nebo odeberete něco? Těšíme se na vaše názory.