Když SQL Server optimalizuje dotaz, během fáze průzkumu vytvoří kandidátní plány a vybere z nich ten, který má nejnižší náklady. Předpokládá se, že zvolený plán bude mít nejnižší dobu běhu mezi prozkoumanými plány. Jde o to, že optimalizátor si může vybrat pouze mezi strategiemi, které do něj byly zakódovány. Například při optimalizaci seskupování a agregace si v době psaní tohoto článku může optimalizátor vybrat pouze mezi strategiemi Stream Aggregate a Hash Aggregate. Dostupné strategie jsem popsal v dřívějších dílech této série. V části 1 jsem pokryl předobjednanou strategii Stream Aggregate, v části 2 strategii Sort + Stream Aggregate, v části 3 strategii Hash Aggregate a v části 4 úvahy o paralelismu.
Optimalizátor serveru SQL Server aktuálně nepodporuje přizpůsobení a umělou inteligenci. To znamená, že pokud dokážete zjistit strategii, která je za určitých podmínek optimálnější než ty, které podporuje optimalizátor, nemůžete optimalizátor vylepšit, aby ji podporoval, a optimalizátor se ji nemůže naučit používat. Co však můžete udělat, je přepsat dotaz pomocí alternativních prvků dotazu, které lze optimalizovat podle strategie, kterou máte na mysli. V této páté a poslední části série demonstruji tuto techniku ladění dotazů pomocí revizí dotazů.
Velké díky Paulu Whiteovi (@SQL_Kiwi) za pomoc s některými výpočty nákladů uvedenými v tomto článku!
Stejně jako v předchozích dílech série použiji ukázkovou databázi PerformanceV3. K odstranění nepotřebných indexů z tabulky Objednávky použijte následující kód:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders;DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Výchozí strategie optimalizace
Zvažte následující základní úkoly seskupování a agregace:
Vraťte maximální datum objednávky pro každého odesílatele, zaměstnance a zákazníka.
Pro optimální výkon vytvoříte následující podpůrné indexy:
VYTVOŘIT INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate);CREATE INDEX idx_eid_od ON dbo.Orders(empid, orderdate);CREATE INDEX idx_cid_od ON dbo.Orders(custid, orderdate);
Níže jsou uvedeny tři dotazy, které byste použili ke zpracování těchto úloh, spolu s odhadovanými náklady na podstrom a také statistikami I/O, CPU a uplynulého času:
-- Dotaz 1-- Odhadovaná cena podstromu:3,5344-- logická čtení:2484, CPU čas:281 ms, uplynulý čas:279 ms SELECT shipperid, MAX(orderdate) AS maxodFROM dbo.OrdersGROUP BY shipperid; -- Dotaz 2 -- Odhadovaná cena podstromu:3,62798 -- logické čtení:2610, čas CPU:250 ms, uplynulý čas:283 ms SELECT empid, MAX(datum objednávky) AS maxodFROM dbo.OrdersGROUP BY empid; -- Dotaz 3-- Odhadovaná cena podstromu:4,27624 --- logické čtení:3479, čas CPU:406 ms, uplynulý čas:506 ms SELECT custid, MAX(datum objednávky) AS maxodFROM dbo.OrdersGROUP BY custid;
Obrázek 1 ukazuje plány pro tyto dotazy:
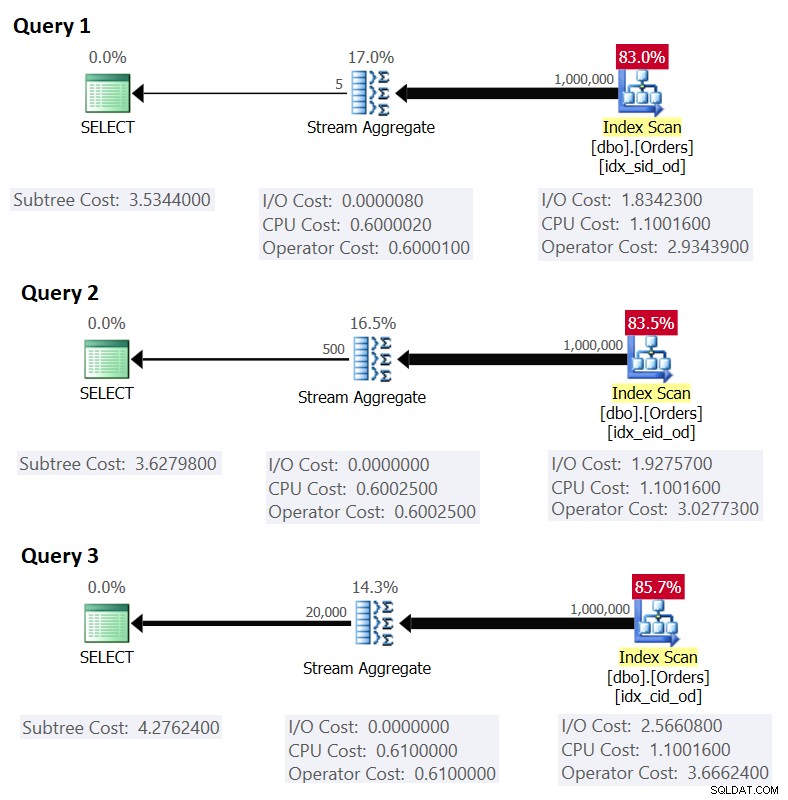 Obrázek 1:Plány pro seskupené dotazy
Obrázek 1:Plány pro seskupené dotazy
Připomeňme, že pokud máte na místě krycí index se sloupci seskupení jako hlavními klíčovými sloupci, za nimiž následuje sloupec agregace, SQL Server pravděpodobně zvolí plán, který provede uspořádané skenování krycího indexu podporujícího strategii Stream Aggregate. . Jak je patrné z plánů na obrázku 1, operátor Index Scan je zodpovědný za většinu nákladů plánu a v něm je nejvýraznější I/O část.
Než představím alternativní strategii a vysvětlím okolnosti, za kterých je optimálnější než výchozí strategie, zhodnoťme cenu stávající strategie. Protože I/O část je nejdominantnější při určování nákladů plánu této výchozí strategie, pojďme nejprve odhadnout, kolik logických přečtení stránky bude zapotřebí. Později také odhadneme cenu plánu.
Chcete-li odhadnout počet logických čtení, která bude operátor Index Scan vyžadovat, musíte vědět, kolik řádků máte v tabulce a kolik řádků se vejde na stránku na základě velikosti řádku. Jakmile budete mít tyto dva operandy, bude váš vzorec pro požadovaný počet stránek na úrovni listu indexu CEILING(1e0 * @číslo řádků / @rowsperpage). Pokud máte pouze strukturu tabulky a žádná existující ukázková data, se kterými byste mohli pracovat, můžete tento článek použít k odhadu počtu stránek, které byste měli na úrovni listu podpůrného indexu. Pokud máte dobrá reprezentativní ukázková data, i když ne ve stejném měřítku jako v produkčním prostředí, můžete vypočítat průměrný počet řádků, které se vejdou na stránku dotazem na katalog a objekty dynamické správy, například takto:
SELECT I.name, row_count, in_row_data_page_count, CAST(ROUND(1e0 * row_count / in_row_data_page_count, 0) AS INT) AS avgrowperpage FROM sys.indexes AS I INNER JOIN sys.dm_db_partition_stats AS P ON I.object_id AND I.index_id =P.index_id WHERE I.object_id =OBJECT_ID('dbo.Orders') AND I.name IN ('idx_sid_od', 'idx_eid_od', 'idx_cid_od'); Tento dotaz generuje v naší ukázkové databázi následující výstup:
name row_count in_row_data_page_count avgrowsperpage ----------- ---------- ---------------------- --------------- idx_sid_od 1000000 2473 404 idx_eid_od 1000000 2599 385 idx_cid_od 1000000 3461 289
Nyní, když máte počet řádků, které se vejdou na listovou stránku rejstříku, můžete odhadnout celkový počet listových stránek v rejstříku na základě počtu řádků, které očekáváte ve své produkční tabulce. Toto bude také očekávaný počet logických čtení, která má operátor Index Scan použít. V praxi je počet přečtení, ke kterému by mohlo dojít, více než jen počet stránek na úrovni listu rejstříku, jako jsou další čtení vytvořená mechanismem předčítání, ale budu je ignorovat, aby byla naše diskuse jednoduchá. .
Například odhadovaný počet logických čtení pro Dotaz 1 s ohledem na očekávaný počet řádků je CEILING(1e0 * @numorws / 404). Při 1 000 000 řádcích je očekávaný počet logických čtení 2 476. Rozdíl mezi 2 476 a hlášeným počtem 2 473 řádkových stránek lze připsat zaokrouhlení, které jsem provedl při výpočtu průměrného počtu řádků na stránku.
Pokud jde o náklady plánu, vysvětlil jsem, jak zpětně analyzovat náklady operátora Stream Aggregate v části 1 v seriálu. Podobným způsobem můžete zpětně analyzovat náklady na operátor Index Scan. Náklady plánu jsou pak součtem nákladů operátorů Index Scan a Stream Aggregate.
Chcete-li vypočítat náklady na operátor Index Scan, chcete začít s reverzním inženýrstvím některých důležitých konstant nákladového modelu:
@randomio =0,003125 -- Náhodné I/O náklady@seqio =0,000740740740741 -- Sekvenční I/O náklady@cpubase =0,000157 -- CPU základní náklady@cpurow =0,0000011 -- CPU náklady na řádek
Po určení výše uvedených konstant nákladového modelu můžete přistoupit k reverzní analýze vzorců pro I/O náklady, náklady na CPU a celkové náklady na operátora operátora Index Scan:
Cena I/O:@randomio + (@numpages - 1e0) * @seqio =0,003125 + (@numpages - 1e0) * 0,000740740740741CPU:@cpubase + @numrows * @cpurow =0150 +0 náklady:0,002541259259259 + @numpages * 0,000740740740741 + @numrows * 0,0000011
Například cena operátora Index Scan pro Dotaz 1 s 2473 stránkami a 1 000 000 řádky je:
0,002541259259259 + 2473 * 0,000740740740741 + 1000000 * 0,0000011 =2,93439
Níže je uveden vzorec zpětného inženýrství pro náklady operátora Stream Aggregate:
0,000008 + @numrows * 0,0000006 + @numgroups * 0,0000005
Například pro Dotaz 1 máme 1 000 000 řádků a 5 skupin, takže odhadovaná cena je 0,6000105.
Sloučením nákladů dvou operátorů je zde vzorec pro celkovou cenu plánu:
0,002549259259259 + @numpages * 0,000740740740741 + @numrows * 0,0000017 + @numgroups * 0,0000005
Pro Dotaz 1 s 2473 stránkami, 1 000 000 řádky a 5 skupinami získáte:
0,002549259259259 + 2473 * 0,000740740740741 + 1000000 * 0,0000017 + 5 * 0,0000005 =3,5344
To odpovídá tomu, co ukazuje obrázek 1 jako odhadované náklady na dotaz 1.
Pokud byste se spoléhali na odhadovaný počet řádků na stránku, váš vzorec by byl:
0,002549259259259 + STROP(1e0 * @numrows / @rowsperpage) * 0,000740740740741 + @numrows * 0,0000017 + @numgroups * 0,0000005
Například pro Dotaz 1 s 1 000 000 řádky, 404 řádky na stránku a 5 skupinami jsou odhadované náklady:
0,002549259259259 + STROP (1e0 * 1000000 / 404) * 0,000740740740741 + 1000000 * 0,0000017 + 5 * 0,000005,000005,6 =<6005.05
Jako cvičení můžete v našem vzorci použít čísla pro Dotaz 2 (1 000 000 řádků, 385 řádků na stránku, 500 skupin) a Dotaz 3 (1 000 000 řádků, 289 řádků na stránku, 20 000 skupin) a uvidíte, že výsledky odpovídají Obrázek 1 ukazuje.
Ladění dotazů s přepisováním dotazů
Výchozí předobjednaná strategie Stream Aggregate pro výpočet MIN/MAX agregátu na skupinu se opírá o uspořádané skenování podpůrného krycího indexu (nebo nějakou jinou předběžnou aktivitu, která vysílá objednané řádky). Alternativní strategií s podpůrným krycím indexem by bylo provedení hledání indexu pro skupinu. Zde je popis pseudoplánu založeného na takové strategii pro dotaz, který seskupuje podle grpcol a aplikuje MAX(aggcol):
set @curgrpcol =grpcol z prvního řádku získaného skenováním indexu, seřazený dopředu; zatímco konec indexu není dosažen,začněte set @curagg =aggcol z řádku získaného vyhledáváním do posledního bodu, kde grpcol =@curgrpcol, seřazeno pozpátku; emitovat řádek (@curgrpcol, @curagg); nastavit @curgrpcol =grpcol z řádku napravo od posledního řádku pro aktuální skupinu;konec;
Pokud se nad tím zamyslíte, výchozí strategie založená na skenování je optimální, když má sada seskupení nízkou hustotu (velký počet skupin, v průměru malý počet řádků na skupinu). Strategie založená na hledání je optimální, když má sada seskupení vysokou hustotu (malý počet skupin, v průměru s velkým počtem řádků na skupinu). Obrázek 2 ukazuje obě strategie a ukazuje, kdy je každá optimální.
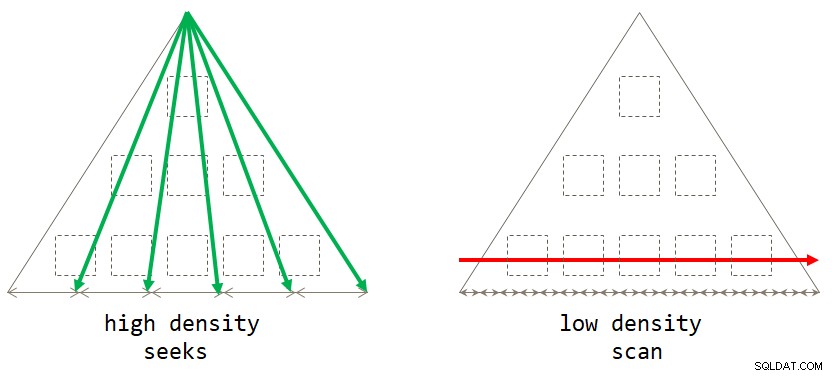 Obrázek 2:Optimální strategie na základě hustoty seskupení
Obrázek 2:Optimální strategie na základě hustoty seskupení
Dokud řešení napíšete ve formě seskupeného dotazu, SQL Server bude v současné době zvažovat pouze strategii skenování. To se vám bude hodit, když má sada seskupení nízkou hustotu. Když máte vysokou hustotu, abyste získali strategii hledání, budete muset použít přepsání dotazu. Jedním ze způsobů, jak toho dosáhnout, je dotaz na tabulku, která obsahuje skupiny, a k získání agregace použít skalární agregační poddotaz proti hlavní tabulce. Například pro výpočet maximálního data objednávky pro každého odesílatele byste použili následující kód:
SELECT shipperid, ( SELECT TOP (1) O.orderdate FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid ORDER BY O.orderdate DESC ) AS maxod FROM dbo.Shippers AS S;
Pokyny pro indexování pro hlavní tabulku jsou stejné jako pokyny pro podporu výchozí strategie. Tyto indexy již máme pro tři výše uvedené úkoly. Pravděpodobně byste také chtěli podpůrný index pro sloupce seskupovací sady v tabulce obsahující skupiny, abyste minimalizovali I/O náklady oproti této tabulce. K vytvoření takových podpůrných indexů pro naše tři úkoly použijte následující kód:
VYTVOŘIT INDEX idx_sid NA dbo.Shippers(shipperid);VYTVOŘIT INDEX idx_eid NA dbo.Employees(empid);VYTVOŘIT INDEX idx_cid NA dbo.Customers(custid);
Jedním malým problémem však je, že řešení založené na poddotazu není přesným logickým ekvivalentem řešení založeného na seskupeném dotazu. Pokud máte skupinu bez přítomnosti v hlavní tabulce, první skupina vrátí skupinu s NULL jako agregaci, zatímco druhá nevrátí skupinu vůbec. Jednoduchým způsobem, jak dosáhnout skutečného logického ekvivalentu seskupeného dotazu, je vyvolat poddotaz pomocí operátoru CROSS APPLY v klauzuli FROM namísto použití skalárního poddotazu v klauzuli SELECT. Pamatujte, že CROSS APPLY nevrátí levý řádek, pokud použitý dotaz vrátí prázdnou sadu. Zde jsou tři dotazy na řešení implementující tuto strategii pro naše tři úkoly spolu s jejich statistikami výkonu:
-- Dotaz 4 -- Odhadovaná cena podstromu:0,0072299 -- logické čtení:2 + 15, CPU čas:0 ms, uplynulý čas:43 ms SELECT S.shipperid, A.orderdate AS maxod FROM dbo.Shippers AS S POUŽÍT KŘÍŽEM ( SELECT TOP (1) O.orderdate FROM dbo. Orders AS O WHERE O.shipperid =S.shipperid ORDER BY O.orderdate DESC ) JAKO A; -- Dotaz 5 -- Odhadovaná cena podstromu:0,089694 -- logická čtení:2 + 1620, čas CPU:0 ms, uplynulý čas:148 ms VYBRAT E.empid, A.orderdate AS maxod OD dbo.Zaměstnanci JAK POUŽÍT KŘÍŽEM SELECT TOP (1) O.orderdate FROM dbo.Orders AS O WHERE O.empid =E.empid ORDER BY O.orderdate DESC ) AS A; -- Dotaz 6 -- Odhadovaná cena podstromu:3,5227 -- logická čtení:45 + 63777, čas CPU:171 ms, uplynulý čas:306 ms SELECT C.custid, A.orderdate AS maxod FROM dbo.Customers AS CROSS APPLY SELECT TOP (1) O.orderdate FROM dbo.Orders AS O WHERE O.custid =C.custid ORDER BY O.orderdate DESC ) AS A;
Plány pro tyto dotazy jsou znázorněny na obrázku 3.
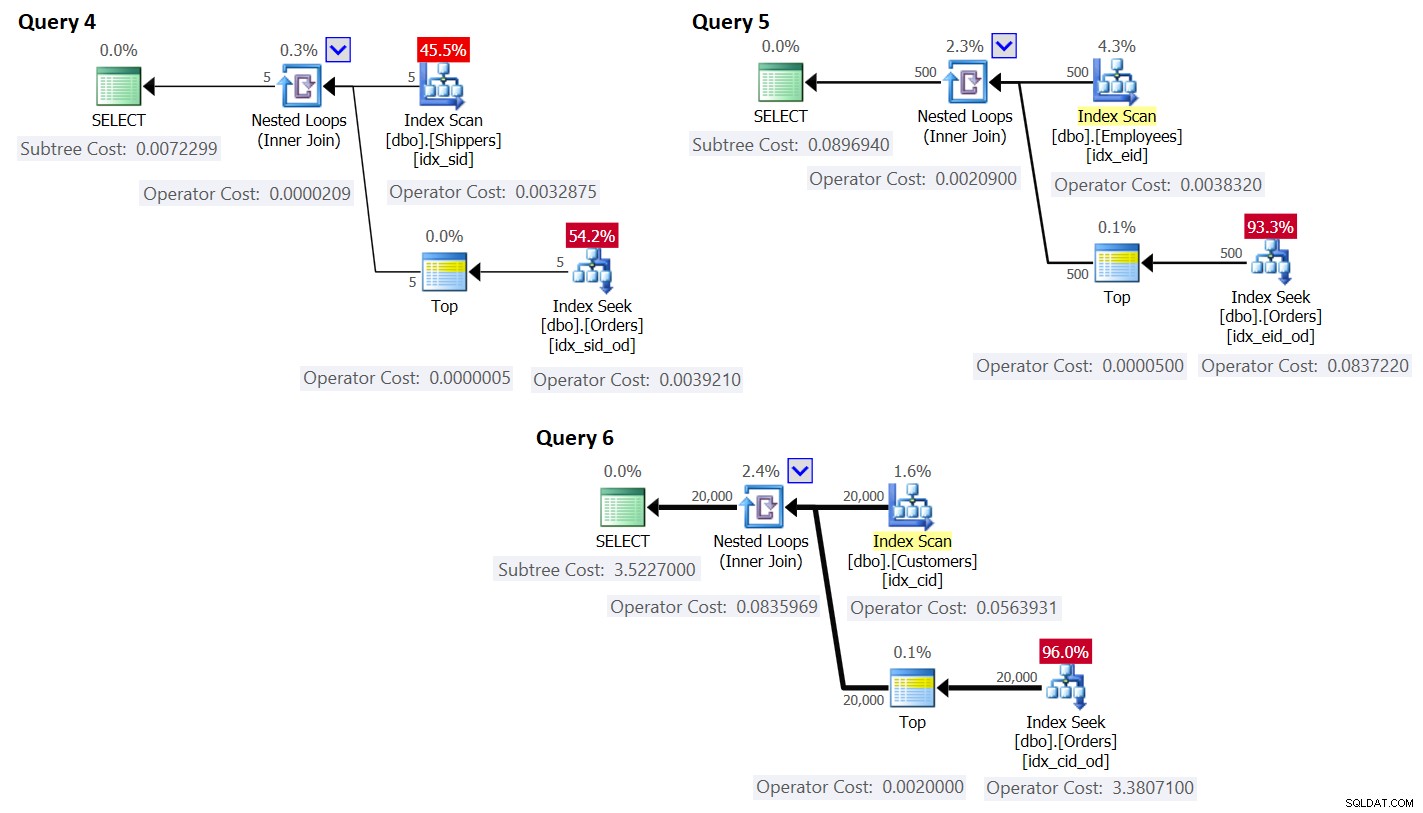 Obrázek 3:Plány pro dotazy s přepsáním
Obrázek 3:Plány pro dotazy s přepsáním
Jak vidíte, skupiny se získávají skenováním indexu v tabulce skupin a agregace se získává aplikací hledání v indexu v hlavní tabulce. Čím vyšší je hustota sady seskupení, tím optimálnější je tento plán ve srovnání s výchozí strategií pro seskupený dotaz.
Stejně jako jsme to udělali dříve u výchozí strategie skenování, odhadneme počet logických čtení a naplánujeme náklady na strategii vyhledávání. Odhadovaný počet logických čtení je počet čtení pro jedno provedení operátoru Index Scan, který načte skupiny, plus čtení pro všechna provedení operátoru Index Seek.
Odhadovaný počet logických čtení pro operátor Index Scan je zanedbatelný ve srovnání s hledáním; stále je to STROP (1e0 * @numgroups / @rowsperpage). Vezměte si jako příklad dotaz 4; řekněme, že index idx_sid se vejde asi 600 řádků na listovou stránku (skutečný počet závisí na skutečných hodnotách shipperid, protože datový typ je VARCHAR(5)). S 5 skupinami se všechny řádky vejdou na jednu listovou stránku. Pokud byste měli 5 000 skupin, vešly by se na 9 stránek.
Odhadovaný počet logických čtení pro všechna provedení operátoru Index Seek je @numgroups * @indexdepth. Hloubku indexu lze vypočítat takto:
STROP(LOG(CEILING(1e0 * @počet řádků / @řádkůsperleafpage), @řádkynelístky)) + 1
Pokud použijeme jako příklad Dotaz 4, řekněme, že se nám vejde asi 404 řádků na listovou stránku indexu idx_sid_od a asi 352 řádků na nelistovou stránku. Skutečná čísla budou opět záviset na skutečných hodnotách uložených ve sloupci shipperid, protože jeho datový typ je VARCHAR(5)). Pro odhady nezapomeňte, že můžete použít výpočty popsané zde. S dostupnými dobrými reprezentativními ukázkovými daty můžete pomocí následujícího dotazu zjistit počet řádků, které se vejdou na listové a nelistové stránky daného indexu:
SELECT CASE P.index_level WHEN 0 THEN 'leaf' WHEN 1 THEN 'nonleaf' END AS pagetype, FLOOR(8096 / (P.avg_record_size_in_bytes + 2)) AS rowsperpage FROM (SELECT * FROM sys.indexes WHERE object_id =('dbo.Orders') AND name ='idx_sid_od') PŘI PŘIHLÁŠENÍ sys.dm_db_index_physical_stats (DB_ID('PerformanceV3'), I.object_id, I.index_id, NULL, 'DETAILED') JAK P KDE
Mám následující výstup:
pagetype rowsperpage -------- ---------------------- list 404 nonleaf 352
S těmito čísly je hloubka indexu vzhledem k počtu řádků v tabulce:
STROP(LOG(STROP(1e0 * @číslo / 404), 352)) + 1
S 1 000 000 řádky v tabulce to znamená hloubku indexu 3. Při přibližně 50 milionech řádků se hloubka indexu zvýší na 4 úrovně a při přibližně 17,62 miliardách řádků se zvýší na 5 úrovní.
V každém případě, s ohledem na počet skupin a počet řádků, za předpokladu výše uvedeného počtu řádků na stránku, vypočítá následující vzorec odhadovaný počet logických čtení pro dotaz 4:
STROP(1e0 * @číslové skupiny / 600) + @číslové skupiny * (STROP(LOG(STROP(1e0 * @číslice / 404), 352)) + 1)
Například s 5 skupinami a 1 000 000 řádky získáte celkem pouze 16 čtení! Připomeňme, že výchozí strategie založená na skenování pro seskupený dotaz zahrnuje tolik logických čtení jako CEILING(1e0 * @počet řádků / @rowsperpage). Použijeme-li jako příklad Dotaz 1 a předpokládáme-li přibližně 404 řádků na listovou stránku indexu idx_sid_od, při stejném počtu řádků 1 000 000 získáte přibližně 2 476 čtení. Zvyšte počet řádků v tabulce o faktor 1 000 až 1 000 000 000, ale počet skupin ponechte pevný. Počet čtení požadovaných u strategie hledání se změní velmi málo na 21, zatímco počet čtení požadovaných se strategií skenování se lineárně zvyšuje na 2 475 248.
Krása strategie hledání spočívá v tom, že pokud je počet skupin malý a pevný, má téměř konstantní měřítko s ohledem na počet řádků v tabulce. Je to proto, že počet vyhledávání je určen počtem skupin a hloubka indexu se vztahuje k počtu řádků v tabulce logaritmickým způsobem, kde základem protokolu je počet řádků, které se vejdou na nelistovou stránku. Naopak strategie založená na skenování má lineární měřítko s ohledem na počet zahrnutých řádků.
Obrázek 4 ukazuje počet čtení odhadovaný pro dvě strategie, použité Dotazem 1 a Dotazem 4, daný pevným počtem skupin 5 a různým počtem řádků v hlavní tabulce.
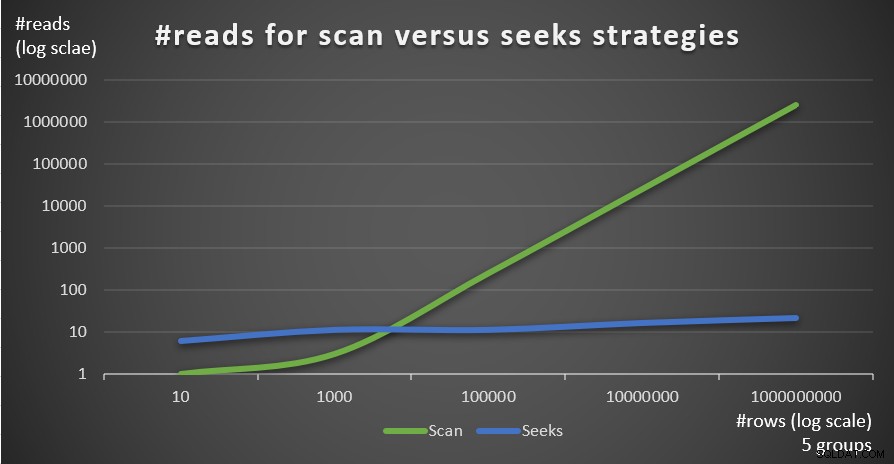 Obrázek 4:#reads pro strategie skenování versus hledání (5 skupin)
Obrázek 4:#reads pro strategie skenování versus hledání (5 skupin)
Obrázek 5 ukazuje odhadovaný počet čtení pro tyto dvě strategie, daný pevným počtem řádků 1 000 000 v hlavní tabulce a různým počtem skupin.
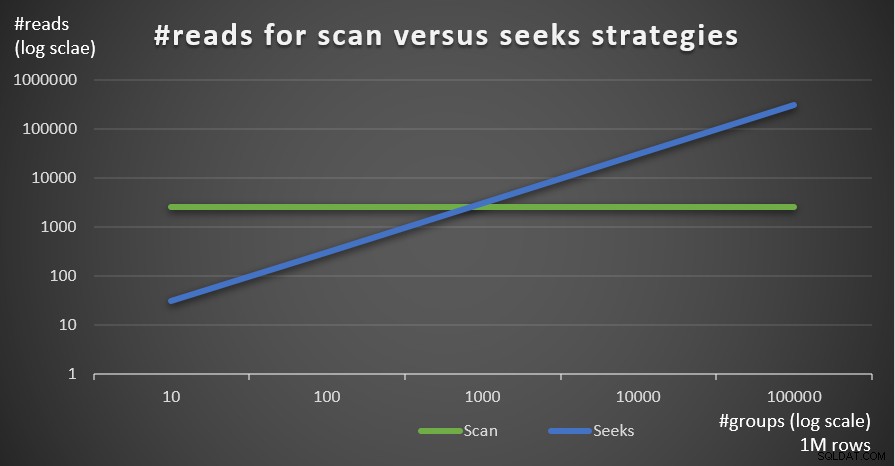 Obrázek 5:#reads pro strategie skenování versus hledání (1 milion řádků)
Obrázek 5:#reads pro strategie skenování versus hledání (1 milion řádků)
Velmi jasně vidíte, že čím vyšší je hustota seskupovací množiny (menší počet skupin) a čím větší je hlavní tabulka, tím více je preferována strategie seeks z hlediska počtu přečtení. Pokud vás zajímá, jaký vzor I/O používá každá strategie; operace hledání indexu samozřejmě provádějí náhodné I/O, zatímco operace skenování indexu provádí sekvenční I/O. Přesto je docela jasné, která strategie je v extrémnějších případech optimální.
Pokud jde o náklady na plán dotazů, opět pomocí plánu pro dotaz 4 na obrázku 3 jako příkladu jej rozdělíme na jednotlivé operátory v plánu.
Reverzně vytvořený vzorec pro cenu operátora Index Scan je:
0,002541259259259 + @numpages * 0,000740740740741 + @numgroups * 0,0000011
V našem případě s 5 skupinami, které se všechny vejdou na jednu stránku, jsou náklady:
0,002541259259259 + 1 * 0,000740740740741 + 5 * 0,0000011 =0,0032875
Cena uvedená v plánu je stejná.
Stejně jako dříve můžete odhadnout počet stránek na úrovni listu indexu na základě odhadovaného počtu řádků na stránku pomocí vzorce CEILING(1e0 * @numrows / @rowsperpage), což je v našem případě CEILING(1e0 * @ numgroups / @groupsperpage). Řekněme, že index idx_sid se vejde asi 600 řádků na listovou stránku, přičemž s 5 skupinami byste potřebovali přečíst jednu stránku. V každém případě se kalkulační vzorec pro operátor Index Scan stane:
0,002541259259259 + STROP (1e0 * @numgroups / @groupsperpage) * 0,000740740740741 + @numgroups * 0,0000011
Vzorec zpětného inženýrství pro výpočet nákladů pro operátor Nested Loops je:
@executations * 0,00000418
V našem případě to znamená:
@numgroups * 0,00000418
Pro Dotaz 4 s 5 skupinami získáte:
5 * 0,00000418 =0,0000209
Cena uvedená v plánu je stejná.
Vzorec kalkulace se zpětným inženýrstvím pro operátora Top je:
@executations * @toprows * 0,00000001
V našem případě to znamená:
@numgroups * 1 * 0,00000001
S 5 skupinami získáte:
5 * 0,0000001 =0,0000005
Cena uvedená v plánu je stejná.
Pokud jde o operátor Index Seek, zde jsem dostal skvělou pomoc od Paula Whitea; Díky kamaráde! Výpočet se liší pro první provedení a pro opětovné svázání (neprvní provedení, které znovu nepoužívá výsledek předchozího provedení). Stejně jako u operátora Index Scan začněme identifikací konstant nákladového modelu:
@randomio =0,003125 -- Náhodné I/O náklady @seqio =0,000740740740741 -- Sekvenční I/O náklady @cpubase =0,000157 -- CPU základní náklady @cpurow =0,0000011 -- CPU náklady na řádek
Pro jedno spuštění bez aplikovaného cíle řádku jsou I/O a CPU náklady:
Cena I/O:@randomio + (@numpages - 1e0) * @seqio =0,002384259259259 + @numpages * 0,000740740740741CPU:@cpubase + @numrows * @0001 150.00.
Protože používáme TOP (1), máme pouze jednu stránku a jeden řádek, takže náklady jsou:
Cena I/O:0,002384259259259 + 1 * 0,000740740740741 =0,003125 Náklady na CPU:0,000157 + 1 * 0,0000011 =0,0001581
Takže náklady na první spuštění operátoru Index Seek v našem případě jsou:
@firstexecution =0,003125 + 0,0001581 =0,0032831
Pokud jde o náklady na převázání, jako obvykle se skládá z nákladů na CPU a I/O. Říkejme jim @rebindcpu a @rebindio. S Dotazem 4, který má 5 skupin, máme 4 opětovné vazby (říkejme tomu @rebinds). Cena @rebindcpu je ta snadná část. Vzorec je:
@rebindcpu =@rebinds * (@cpubase + @cpurow)
V našem případě to znamená:
@rebindcpu =4 * (0,000157 + 0,0000011) =0,0006324
Část @rebindio je o něco složitější. Kalkulační vzorec zde statisticky vypočítá očekávaný počet odlišných stránek, které se očekává, že je znovu sváže pomocí vzorkování s nahrazením. Tento prvek budeme nazývat @pswr (pro různé stránky vzorkované s náhradou). Myšlenka je taková, že máme @indexdatapages počet stránek v indexu (v našem případě 2 473) a @rebinds počet rebinds (v našem případě 4). Za předpokladu, že máme stejnou pravděpodobnost, že přečteme kteroukoli danou stránku při každém opětovném navázání, kolik různých stránek se očekává, že přečteme celkem? Je to podobné, jako kdybyste měli pytel s 2 473 míčky a čtyřikrát poslepu vytáhli míček z pytle a pak ho vrátili do pytle. Statisticky, kolik různých míčků se očekává, že vytáhnete celkem? Vzorec pro to pomocí našich operandů je:
@pswr =@indexdatapages * (1e0 - POWER((@indexdatapages - 1e0) / @indexdatapages, @rebinds))
S našimi čísly získáte:
@pswr =2473 * (1e0 - POWER((2473 - 1e0) / 2473, 4)) =3,99757445099277
Dále spočítáte počet řádků a stránek, které máte v průměru na skupinu:
@grouprows =@kardinalita * @hustota@grouppages =STROP(@indexdatapages * @hustota)
V našem Dotazu 4 je mohutnost 1 000 000 a hustota 1/5 =0,2. Takže dostanete:
@grouprows =1000000 * 0,2 =200000@numpages =STROP (2473 * 0,2) =495
Poté vypočítáte I/O náklady bez filtrování (nazývejte to @io) jako:
@io =@randomio + (@seqio * (@grouppages - 1e0))
V našem případě získáte:
@io =0,003125 + (0,000740740740741 * (495 - 1e0)) =0,369050925926054
A konečně, protože hledání extrahuje pouze jeden řádek v každém opětovném svázání, vypočítáte @rebindio pomocí následujícího vzorce:
@rebindio =(1e0 / @grouprows) * ((@pswr - 1e0) * @io)
V našem případě získáte:
@rebindio =(1e0 / 200000) * ((3,99757445099277 - 1e0) * 0,369050925926054) =0,000005531288
A konečně, náklady operátora jsou:
Náklady na operátora:@firstexecution + @rebindcpu + @rebindio =0,0032831 + 0,0006324 + 0,000005531288 =0,003921031288
To je stejné jako náklady operátora Index Seek zobrazené v plánu pro Query 4.
Nyní můžete agregovat náklady všech operátorů, abyste získali kompletní cenu plánu dotazů. Získáte:
Náklady na dotaz:0,002541259259259 + Strop (1E0 * @numgroups / @groupsperpage) * 0,000740740740741 + @NUMGroups * + ( @1) + ( @ @ @ @ @ @ @ @ @ @ @ @@NUM0 (1) + ( @@NUM (1) + ( @1). / (@počet řádků / @číslicové skupiny)) * (STROP(1e0 * @číslořádků / @řádků) * (1e0 - VÝKON ((STROP(1e0 * @počet řádků / @řádků) - 1e0) / STROP (1e0 * @číslo / @ rowsperpage), @numgroups - 1e0)) - 1e0) * (0,003125 + (0,000740740740741 * (STROP) ((@numrows / @rowsperpage) * (1e0 / @numgroups)) - 1e0)))
Po zjednodušení získáte pro naši strategii hledání následující kompletní kalkulační vzorec:
0,005666259259259 + STROP (1e0 * @numgroups / @groupsperpage) * 0,000740740740741 + @numgroups * 0,0000011 + @numgroups * 0,0001629 + 0,0001629 + (0,00016229 + ) * (1e0 - POWER((STROP(1e0 * @počet řádků / @řádková stránka) - 1e0) / STROP(1e0 * @číslořádků / @řádkovýstranka), @číslové skupiny - 1e0)) - 1e0) * (0,003125 + (0,0071407) STROP((@počet řádků / @řádková stránka) * (1e0 / @čísloskupin)) - 1e0)))
Jako příklad, pomocí T-SQL, zde je výpočet nákladů plánu dotazů s naší strategií hledání pro dotaz 4:
DECLARE @numrows AS FLOAT =1000000, @numgroups AS FLOAT =5, @rowsperpage AS FLOAT =404, @groupsperpage AS FLOAT =600; SELECT 0,005666259259259 + STROP (1e0 * @numgroups / @groupsperpage) * 0,000740740740741 + @numgroups * 0,0000011 + @numgroups * 0,0001eskupna * 0,0001e sINGnum /1029 + (0,0001e sINGnum /129 + (1e0 - POWER((STROP(1e0 * @číslo řádků / @řádková stránka) - 1e0) / STROP (1e0 * @číslořádků / @řádková stránka), @číslové skupiny - 1e0)) - 1e0) * (0,003125 + (0,0004074407) (@numrows / @rowsperpage) * (1e0 / @numgroups)) - 1e0))) AS seeksplancost;
Tento výpočet vypočítá cenu 0,0072295 pro dotaz 4. Odhadované náklady zobrazené na obrázku 3 jsou 0,0072299. To je docela blízko! Jako cvičení spočítejte náklady na Dotaz 5 a Dotaz 6 pomocí tohoto vzorce a ověřte, že se dostanete číslům blízkým číslům zobrazeným na obrázku 3.
Připomeňme, že kalkulační vzorec pro výchozí strategii založenou na skenování je (nazývejte jej Skenovat strategie):
0,002549259259259 + STROP(1e0 * @numrows / @rowsperpage) * 0,000740740740741 + @numrows * 0,0000017 + @numgroups * 0,0000005
Použijeme-li jako příklad Dotaz 1 a za předpokladu 1 000 000 řádků v tabulce, 404 řádků na stránku a 5 skupin, odhadovaná cena plánu dotazů na strategii skenování je 3,5366.
Obrázek 6 ukazuje odhadované náklady na plán dotazů pro dvě strategie, aplikované Dotazem 1 (skenování) a Dotazem 4 (hledání), za předpokladu pevného počtu skupin 5 a různého počtu řádků v hlavní tabulce.
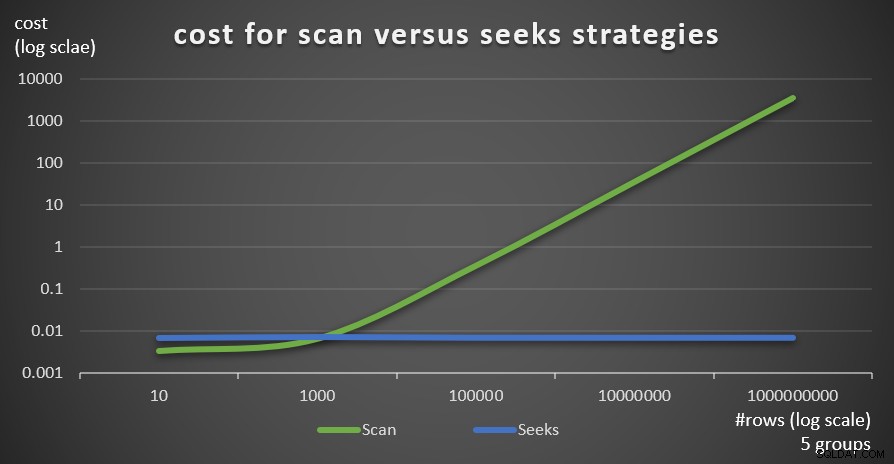 Obrázek 6:cena za strategie skenování versus hledání (5 skupin)
Obrázek 6:cena za strategie skenování versus hledání (5 skupin)
Obrázek 7 ukazuje odhadované náklady na plán dotazů pro dvě strategie, daný pevným počtem řádků v hlavní tabulce 1 000 000 a různým počtem skupin.
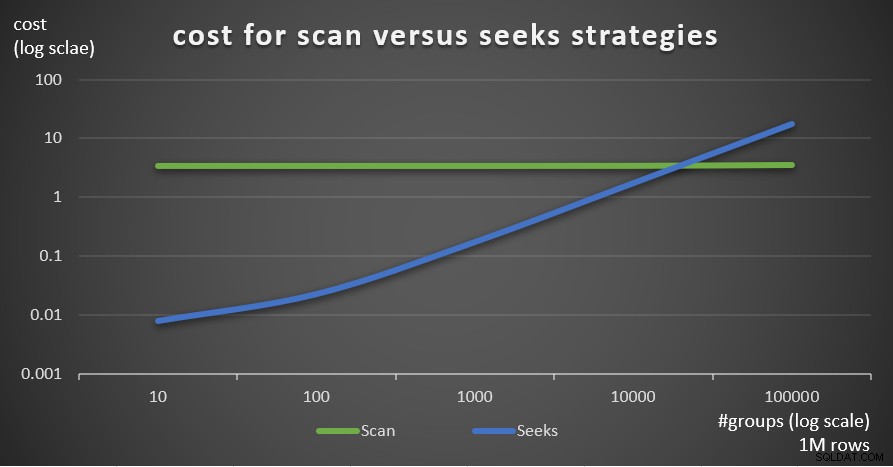 Obrázek 7:cena za strategie skenování versus hledání (1 milion řádků)
Obrázek 7:cena za strategie skenování versus hledání (1 milion řádků)
Jak je zřejmé z těchto zjištění, čím vyšší je hustota seskupení a čím více řádků v hlavní tabulce, tím optimálnější je strategie hledání ve srovnání se strategií skenování. Takže ve scénářích s vysokou hustotou se ujistěte, že vyzkoušíte řešení založené na APPLY. Mezitím můžeme doufat, že Microsoft přidá tuto strategii jako vestavěnou možnost pro seskupené dotazy.
Závěr
Tento článek uzavírá sérii pěti částí o prahových hodnotách optimalizace dotazů pro dotazy, které seskupují a agregují data. Jedním z cílů série bylo diskutovat o specifikách různých algoritmů, které může optimalizátor použít, o podmínkách, za kterých je každý algoritmus preferován, a o tom, kdy byste měli zasahovat do vlastních přepisů dotazů. Dalším cílem bylo vysvětlit proces objevování různých možností a jejich porovnávání. Je zřejmé, že stejný proces analýzy lze použít na filtrování, spojování, zobrazování oken a mnoho dalších aspektů optimalizace dotazů. Doufejme, že se nyní cítíte lépe vybaveni pro řešení ladění dotazů než dříve.