
Indexy SQL Server se používají k rychlejšímu načítání dat a ke snížení úzkých míst ovlivňujících kritické zdroje. Indexy v databázové tabulce slouží jako technika optimalizace výkonu. Možná se divíte – jak indexy zvyšují výkon dotazů? Existují věci jako dobré a špatné indexy? Předpokládejme, že máte tabulku s 50 sloupci, je dobrý nápad vytvořit indexy pro každý ze sloupců? Pokud vytvoříme více indexů, pomůže to rychlejšímu běhu SQL dotazů?
Všechno jsou skvělé otázky, ale než se do toho pustíme, je nezbytné vědět, proč mohou být indexy vůbec vyžadovány.
Představte si, že navštívíte městskou knihovnu, která má sbírku tisíců knih. Hledáte konkrétní knihu, ale jak ji najdete? Pokud byste prošli každou knihu v každém stojanu, mohlo by to trvat dny, než ji najdete. Totéž platí pro databázi, když hledáte záznam z milionů řádků uložených v tabulce.
Index SQL Server je tvarován ve formátu B-Strom, který se skládá z kořenového uzlu nahoře a listového uzlu dole. V našem příkladu knih z knihovny uživatel zadá dotaz na vyhledání knihy s ID 391. V tomto případě začne dotazovací stroj procházet z kořenového uzlu a přesune se do listového uzlu.
Kořenový uzel –> Mezilehlý uzel –> Listový uzel.
Dotazový stroj hledá referenční stránku na střední úrovni. V tomto příkladu se první mezilehlý uzel skládá z ID knih od 1 do 500 a druhý mezilehlý uzel se skládá z 501-1000.
Na základě mezilehlého uzlu projde dotazovací modul B-strom a hledá odpovídající mezilehlý uzel a listový uzel. Tento listový uzel se může skládat ze skutečných dat nebo může ukazovat na stránku skutečných dat na základě typu indexu. Na obrázku níže vidíme, jak procházet index a hledat data pomocí indexů SQL Server. V tomto případě SQL Server nemusí procházet každou stránku, číst ji a hledat konkrétní obsah ID knihy.
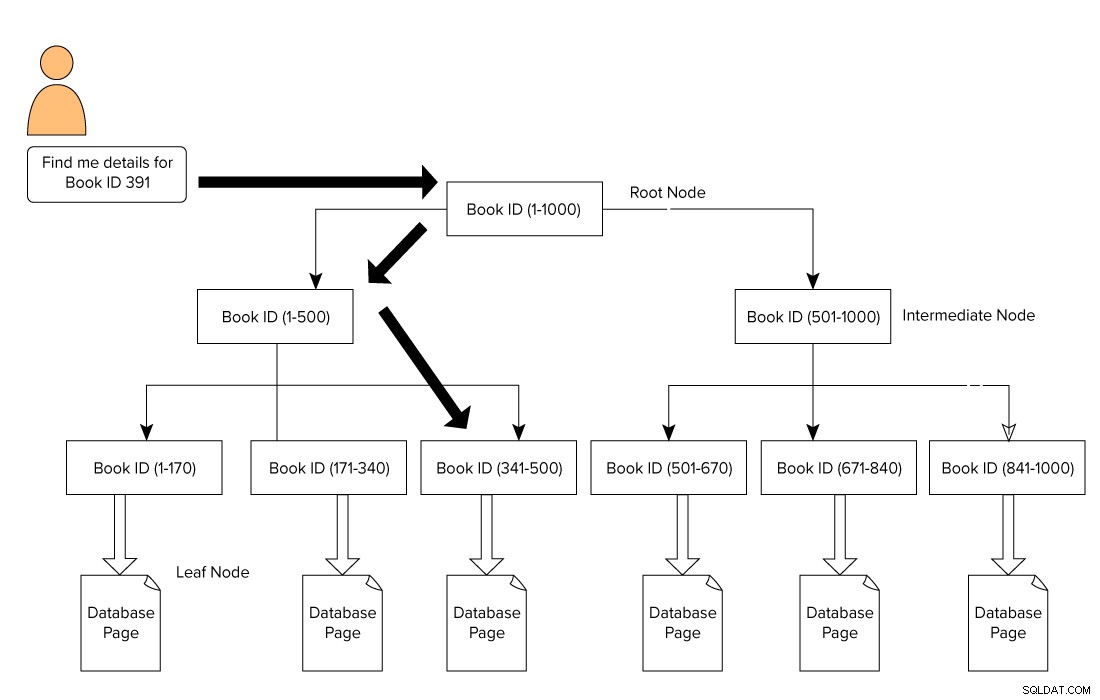
Dopady indexů na výkon SQL Server
V předchozím příkladu knihovny jsme zkoumali potenciální dopady na výkon indexu. Podívejme se na výkon dotazů s indexem a bez něj.
Předpokládejme, že potřebujeme data pro [SalesOrderID] 56958 z tabulky [SalesOrderDetail_Demo].
VYBERTE *
Z [AdventureWorks].[Sales].[SalesOrderDetail_Demo]
kde SalesOrderID=56958
Tato tabulka nemá žádné indexy. Tabulka bez jakýchkoli indexů se na serveru SQL Server nazývá tabulka haldy.
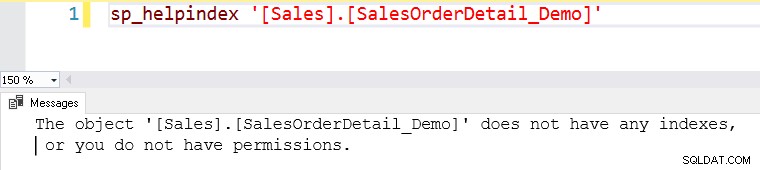
Odtud byste chtěli spustit výše uvedený výběrový příkaz a zobrazit skutečný plán provádění. Tato tabulka má 121317 záznamů. Provádí prohledávání tabulky, což znamená, že čte všechny řádky v tabulce, aby našel konkrétní [SalesOrderID].
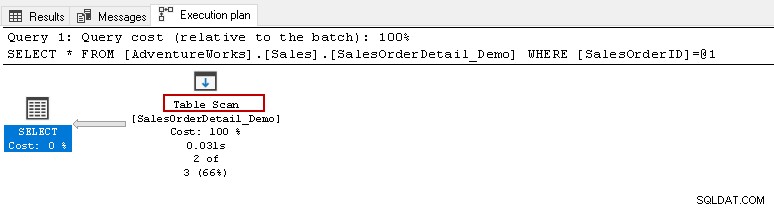
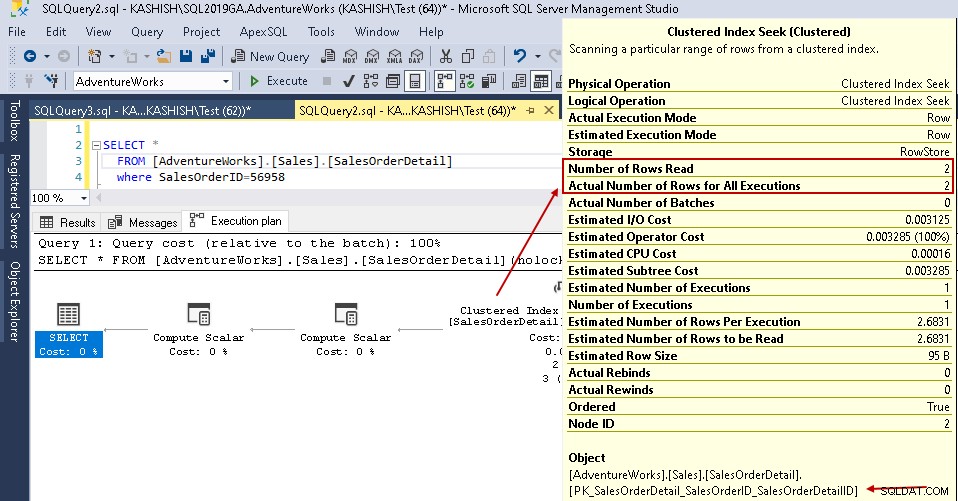
Když najedete kurzorem na ikonu Table Scan, zobrazí se, že skutečná sada výsledků obsahuje 2 řádky, ale pro tento účel přečte všechny řádky v této tabulce.
- Počet přečtených řádků:121317
- Skutečný počet řádků pro provedení:2
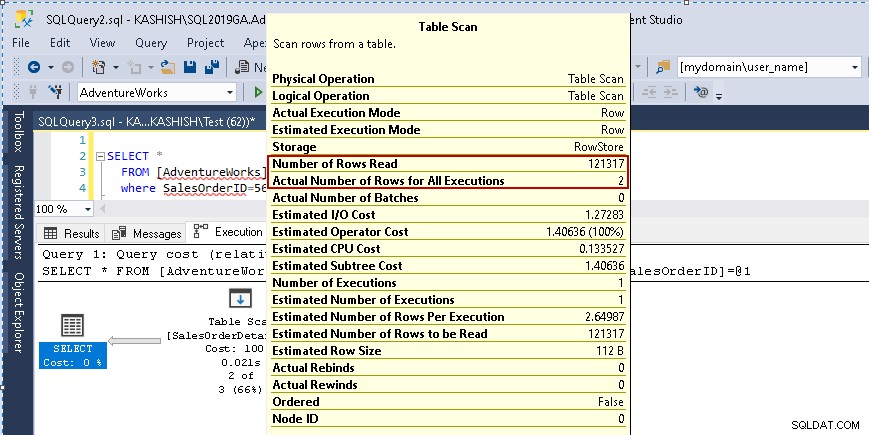
Nyní si představte tabulku s miliony nebo miliardami řádků. Není dobrým zvykem procházet všechny záznamy v tabulce a filtrovat několik řádků. V rozsáhlém databázovém systému pro zpracování online transakcí (OLTP) nevyužívá efektivně zdroje serveru (CPU, IO, paměť), takže uživatel může čelit problémům s výkonem.
Nyní spusťte výše uvedený příkaz select s tabulkou s indexy. Tato tabulka má seskupený index primárního klíče a dva indexy bez klastrů ve sloupcích [ProductID] a [rowguid]. Později si povíme o různých typech indexů v SQL Server.
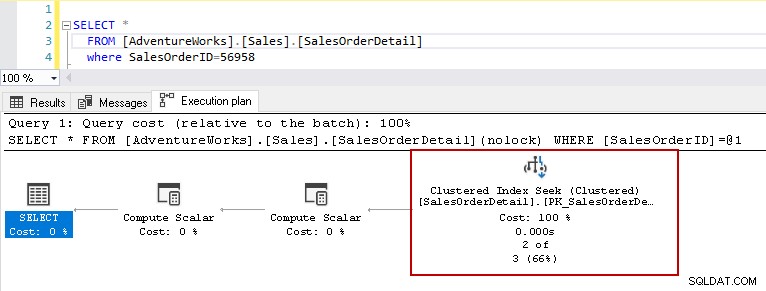
Pokud nyní znovu spustíte příkaz select se stejným predikátem, plán provádění zobrazí problém s výkonem. Optimalizátor dotazů se rozhodne použít clusterované vyhledávání indexu namísto skenování clusteru indexu.
V podrobnostech hledání seskupeného indexu ukazuje, že optimalizátor dotazů přesně přečetl řádky, které dal ve výstupu.
Abychom vám poskytli srovnávací analýzu, porovnejme plán provádění s indexem SQL Server a bez něj. Další informace naleznete v článku Jak porovnat plány provádění dotazů SQL Shack v článku SQL Server 2016.
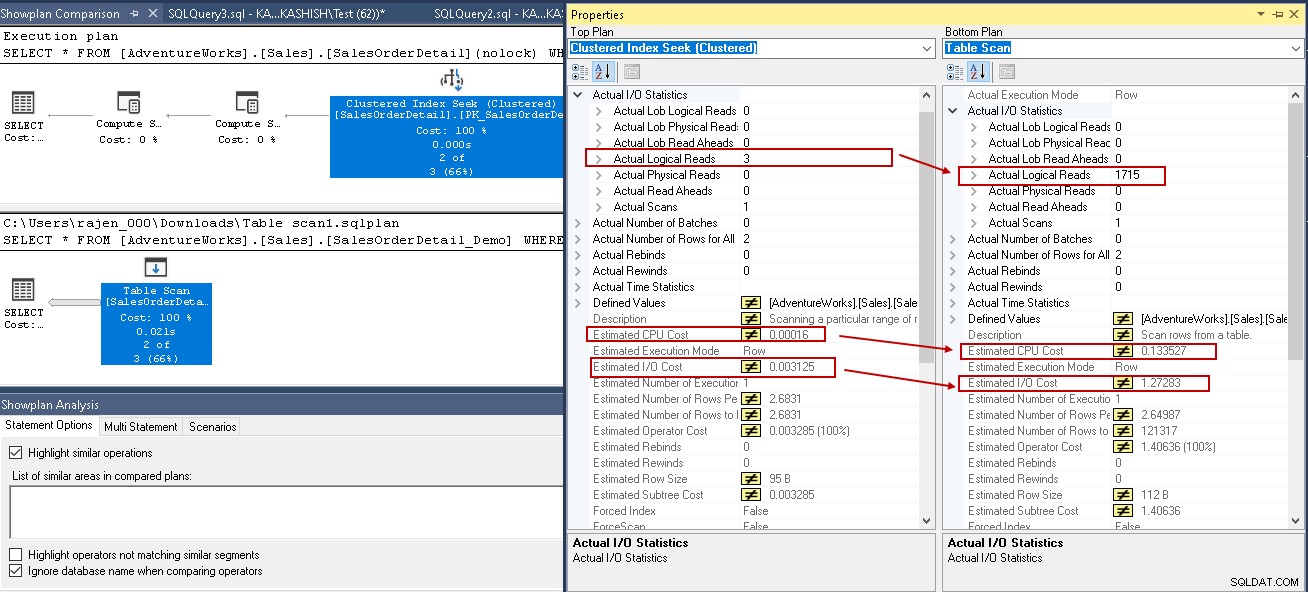
V tomto příkladu se podívejte na zvýrazněné hodnoty při hledání clusteru indexu a prohledávání tabulky:
- Logické čtení:Databázový stroj SQL Server načte stránku z mezipaměti a způsobí logické čtení. Níže vidíme, že logická čtení se po vytvoření indexu sníží z 1715 na 3.
- Odhadovaná cena CPU také klesá z 0,133527 na 0,00016
- Odhadované IO náklady poklesly z 1,27283 na 0,003125
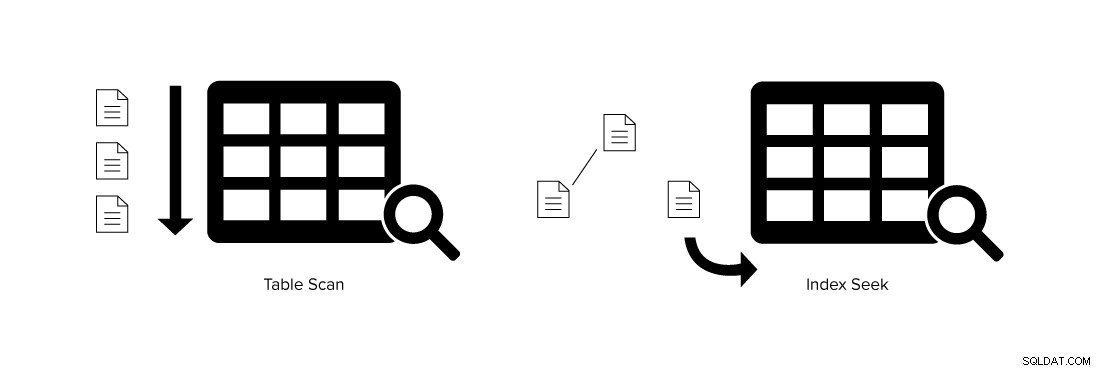
Níže uvedený obrázek ukazuje rozdíl mezi prohledáváním tabulky a vyhledáváním indexu.
Dobré (užitečné) indexy a špatné indexy na serveru SQL Server
Jak název napovídá, dobrý index zlepšuje výkon dotazů a minimalizuje využití zdrojů. Může index snížit výkon dotazů v SQL Server? Někdy vytváříme index na konkrétním sloupci, ale nikdy se nepoužívá. Předpokládejme, že máte index ve sloupci a že pro tento sloupec provádíte mnoho vložení a aktualizací. Pro každou aktualizaci je také vyžadována odpovídající aktualizace indexu. Pokud má vaše pracovní zátěž větší aktivitu zápisu a ve sloupci máte mnoho indexů, zpomalilo by to celkový výkon vašich dotazů. Nepoužitý index může také způsobit pomalý výkon pro vybrané příkazy. Optimalizátor dotazů používá statistiky k sestavení plánu provádění. Přečte všechny indexy a jejich vzorkování dat a na základě toho sestaví optimalizovaný plán provádění dotazů. Využití indexu můžete sledovat pomocí zobrazení dynamické správy sys.dm_db_index_usage_stats a sledovat zdroje, jako je skenování uživatelů, vyhledávání uživatelů a vyhledávání uživatelů.
Typy indexu SQL Server a úvahy
SQL Server má dva hlavní indexy – seskupený a neseskupený index. Clusterový index ukládá aktuální data v koncovém uzlu indexu. Fyzicky třídí data na datových stránkách na základě seskupeného indexového klíče. SQL Server umožňuje jeden seskupený index na tabulku. Můžete spojit více sloupců a vytvořit seskupený indexový klíč. Neklastrovaný index je logický index a má sloupec indexového klíče, který ukazuje na seskupený indexový klíč.
V SQL Serveru můžeme mít i další indexy, jako je index XML, index úložiště sloupců, prostorový index, fulltextový index, index hash atd.
Před vytvořením indexu v SQL Server byste měli zvážit následující body:
- Pracovní zátěž
- Sloupec, ve kterém je vyžadován index
- Velikost tabulky
- Vzestupné nebo sestupné pořadí dat sloupců
- Pořadí sloupců
- Typ indexu
- Faktor plnění, index bloku a pořadí řazení TempDB
Výhody, důsledky a doporučení indexu SQL Server
Indexy v databázi mohou být dvojsečná zbraň. Užitečný index SQL Server zvyšuje výkon dotazu a systému, aniž by to ovlivnilo ostatní dotazy. Na druhou stranu, pokud vytvoříte index bez jakékoli přípravy nebo zvážení, může to způsobit snížení výkonu, pomalé načítání dat a může spotřebovat kritičtější zdroje, jako je CPU, IO a paměť. Indexy také zvyšují úkoly údržby databáze. S ohledem na tyto faktory je vždy nejlepší otestovat vhodný index v předprodukčním prostředí s produkčním ekvivalentním pracovním zatížením, poté analyzovat výkon a rozhodnout, zda je nejlepší jej implementovat do produkční databáze. Existuje mnoho dalších doporučení, která je třeba vzít v úvahu. Pro další informace se podívejte na mých 11 nejlepších doporučených postupů pro indexování.