
V předchozím článku jsme prozkoumali požadavky na index serveru SQL Server a hlediska výkonu. Pokud jde o výkon databáze, ladění výkonu je bezpochyby jednou z nejdůležitějších a nejsložitějších funkcí. Skládá se z mnoha různých oblastí, jako je optimalizace dotazů SQL, ladění indexů a ladění systémových prostředků, přičemž všechny tyto oblasti je třeba provést správně, aby bylo možné rychle úspěšně načíst data.
Existuje několik důležitých oblastí, které je třeba zvážit, pokud jde o indexy SQL Server, protože mohou mít významný dopad jak na vaše úsilí o ladění výkonu, tak na celkový výkon databáze. Níže jsou uvedeny některé podrobnosti o každé z nich a jejich kritických rolích.
Osvědčené postupy indexování SQL Server
1. Pochopte, jak návrh databáze ovlivňuje indexy SQL Server
Požadavky na indexování se mezi databázemi pro online zpracování transakcí (OLTP) a online analytické zpracování (OLAP) liší.
V databázi OLTP uživatelé často provádějí operace čtení a zápisu, vkládají nová data a upravují stávající data. Používají dotazy jazyka pro manipulaci s daty (Insert, Update, Delete) spolu s příkazy Select pro získávání a úpravy dat. U databází OLTP je nejlepší vytvořit indexy ve vybraném sloupci tabulky. Více indexů může mít negativní dopad na výkon a zatěžovat systémové prostředky. Místo toho se doporučuje vytvořit minimální počet indexů, které mohou splnit vaše požadavky na indexování. Na druhou stranu v OLAP databázích používáte většinou příkazy Select k získávání dat pro další analytické účely. V tomto případě můžete přidat více indexů s více klíčovými sloupci na index. Můžete také využít indexy columnstore pro rychlejší načítání dat v dotazech na datový sklad
2. Vytvářejte indexy pro své požadavky na pracovní vytížení
Při vytváření nové tabulky v databázi nepřidávejte indexy jen slepě. Někdy na něj vývojáři vloží jeden seskupený index a několik neklastrovaných indexů, aniž by hledali dotazy, které tyto indexy používají. Může existovat index, který nesplňuje požadavek na optimalizaci dotazů; proto byste měli správně analyzovat své pracovní zatížení a dotazy SQL (uložené procedury, funkce, pohledy a dotazy ad-hoc). Pracovní zátěž můžete zachytit pomocí SQL profileru, rozšířených událostí a dynamických pohledů správy a poté vytvořit indexy pro optimalizaci dotazů náročných na zdroje.
3. Vytvářejte indexy pro nejčastěji a nejčastěji používané dotazy
Je důležité seskupit pracovní zátěže pro nejpoužívanější dotazy ve vašem systému. Vytvořením nejlepších indexů pro tyto dotazy to bude nejméně zatěžovat váš systém.
4. Použít doporučené postupy pro sloupec indexového klíče serveru SQL Server
Vzhledem k tomu, že v tabulce můžete mít více sloupců, zde je několik úvah o sloupcích indexového klíče.
- Sloupce s textem, obrázkem, ntextem, varchar(max), nvarchar(max) a varbinary(max) nelze použít ve sloupcích indexového klíče.
- Ve sloupci indexového klíče se doporučuje použít celočíselný datový typ. Má nízké nároky na prostor a funguje efektivně. Z tohoto důvodu budete chtít vytvořit sloupec primárního klíče, obvykle s celočíselným datovým typem.
- Datový typ XML můžete použít pouze v indexu XML.
- Měli byste zvážit vytvoření primárního klíče pro sloupec s jedinečnými hodnotami. Pokud tabulka nemá žádné sloupce jedinečných hodnot, můžete definovat sloupec identity pro celočíselný datový typ. Primární klíč také vytváří seskupený index pro distribuci řádků.
- Za užitečného kandidáta na klíč indexu můžete považovat sloupec s hodnotami Unique a Not NULL.
- Měli byste vytvořit index založený na predikátech v klauzuli Where. Můžete například zvážit sloupce použité v klauzuli Where, spojení SQL, jako, seřadit podle, seskupit podle predikátů atd.
- Tabulky byste měli spojit způsobem, který sníží počet řádků pro zbytek dotazu. To pomůže optimalizátoru dotazů připravit plán provádění s minimálními systémovými prostředky.
- Pokud pro klíč indexu používáte více sloupců, je také důležité zvážit jejich pozici v klíči indexu.
- Měli byste také zvážit použití zahrnutých sloupců v indexech.
5. Analyzujte distribuci dat ve sloupcích indexu SQL Server
Měli byste prozkoumat distribuci dat ve sloupcích klíče indexu serveru SQL Server. Sloupec s nejedinečnými hodnotami může způsobit zpoždění při načítání dat a vést k dlouhotrvající transakci. Distribuci dat můžete analyzovat pomocí histogramu ve statistice.
6. Použijte pořadí řazení dat
Měli byste také zvážit požadavky na třídění dat ve vašich dotazech a indexech. Ve výchozím nastavení SQL Server řadí data v indexu vzestupně. Předpokládejme, že vytvoříte index ve vzestupném pořadí, ale vaše dotazy používají klauzuli Order By k seřazení dat v sestupném pořadí.
Podívejte se například na skutečný plán provádění následujícího dotazu.
SELECT [SalesOrderID],
[UnitPrice]
FROM [AdventureWorks].[Sales].[SalesOrderDetail]
ORDER BY UnitPrice DESC,
SalesOrderID ASC;
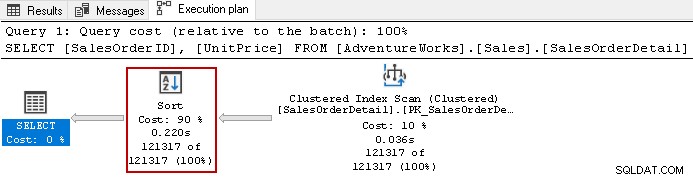
Používá nákladný operátor řazení s celkovými 90% náklady v tomto dotazu. Rozhodli jsme se vytvořit neklastrovaný index na [UnitPrice] a [SalesOrderID]. Používá výchozí pořadí řazení pro oba sloupce v indexu.
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice
ON [AdventureWorks].[Sales].[SalesOrderDetail]
(UnitPrice ASC, SalesOrderID ASC);
Znovu jsme spustili příkaz Select a optimalizátor dotazů stále používá operátor řazení. Může použít index bez klastrů, ale k přípravě výsledku třídí data.
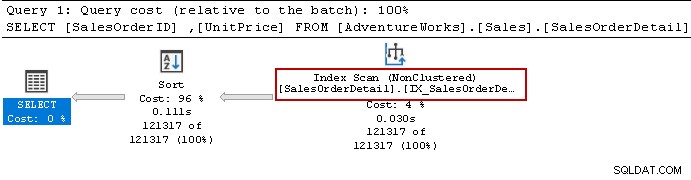
Pojďme znovu vytvořit index pomocí následujícího dotazu. Tentokrát seřadí data v sestupném pořadí podle [Jednotková cena] v definici indexu.
DROP INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail];
Go CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail](UnitPrice DESC, SalesOrderID ASC);
Go
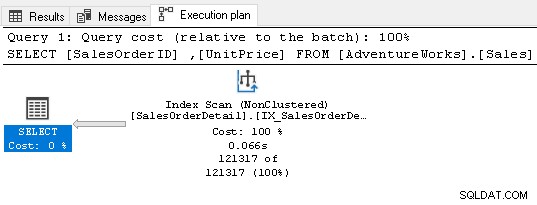
Nyní nevyžaduje žádný operátor řazení, protože index splňuje požadavky na dotaz.
7. Použijte cizí klíče pro index SQL Server
Měli byste vytvořit index na sloupcích cizích klíčů. Je vhodné vytvořit na cizím klíči seskupený index, aby se zlepšil výkon dotazů.
8. Mějte na paměti úvahy o úložišti indexů SQL Serveru
Ukládání indexů je také užitečným aspektem, který je třeba zvážit. SQL Server vytvoří všechny indexy ve stejné skupině souborů v tabulce. Můžete zvážit samostatnou skupinu souborů pro indexy a oddělit fyzický soubor na samostatném disku. Tím se zvýší výkon a propustnost IO.
Podobně můžete použít rozdělení tabulek k rozdělení dat na více disků a skupin souborů. Pro tyto oddíly tabulky můžete navrhnout dělené indexy, abyste zlepšili souběžný přístup k datům.
Další možností je definovat FILLFACTOR při vytváření nebo přestavbě indexu. FILLFACTOR definuje volné místo na datových stránkách listového uzlu. Je to užitečné pro další vkládání dat. Pokud jsou vaše data statická a často se nemění, můžete zvážit vysokou hodnotu FILLFACTOR. Na druhou stranu, pro často se měnící data si můžete ponechat dostatek prostoru pro vkládání nových dat.
9. Najděte chybějící indexy
Někdy získáte informace o chybějícím indexu SQL Server v plánu provádění dotazu. Můžete také spustit pohledy dynamické správy a najít tyto chybějící indexy. Tyto indexy byste neměli slepě vytvářet. Je to pouze návrh optimalizátoru dotazů, ale nezohledňuje stávající index nebo vaše požadavky na pracovní zátěž. Může také obsahovat více sloupců v definici indexu, proto si před jeho implementací přečtěte tyto návrhy.
10. Vždy vytvořte seskupený index před neshlukovaným indexem
Obecně platí, že před vytvářením neklastrovaných indexů byste měli vytvořit seskupený index. Pokud tabulka nemá index, neseskupený index se skládá z identifikátorů řádků. Jakmile vytvoříte seskupený index, SQL Server potřebuje znovu sestavit tyto neklastrované indexy, aby mohly místo identifikátorů řádků odkazovat na klíč seskupeného indexu.
11. Sledujte údržbu indexu a aktualizujte statistiky
Níže je uvedeno několik oblastí údržby, které je třeba sledovat, pokud jde o indexy SQL Server.
- Odstranit fragmentaci indexu :Měli byste pravidelně kontrolovat interní a externí fragmentace, zejména u tabulek s vysokými transakcemi. Vaše dotazy mohou reagovat pomalu, i když máte správné indexy pro vaše úlohy. Silně fragmentovaný index může snížit výkon, protože vyžaduje další IO. Můžete provést reorganizaci nebo znovu sestavit index na základě hodnot jeho fragmentace. Obvykle byste měli index znovu sestavit, pokud má fragmentaci větší než 30 %, a reorganizovat jej, pokud má fragmentaci menší než 30 %.
- Odstranění nepoužívaných indexů: Vždy byste měli zkontrolovat nepoužívané (nečinné) indexy ve vaší databázi, protože optimalizátor dotazů je musí vzít v úvahu pro každý dotaz. Nepoužitý index také spotřebovává úložiště a zvyšuje režii údržby.
- Aktualizace statistik: Statistiky byste měli pravidelně aktualizovat, i když jste v konfiguraci databáze nastavili statistiku automatických aktualizací. Pokud nejsou statistiky indexu aktualizovány, může optimalizátor dotazů připravit špatný plán provádění. Můžete naplánovat úlohu agenta tak, aby po pracovní době aktualizovala statistiky SQL Server pomocí úplné kontroly.
Další informace o tomto tématu naleznete v části Údržba indexu SQL.
Použití doporučených postupů indexování SQL Server
Ačkoli není vždy přímočarý způsob, jak navrhnout optimální index SQL Server, použití doporučení uvedených v tomto příspěvku vám pomůže orientovat se v různých požadavcích na indexování, se kterými se setkáte u každého typu databáze a jejího zatížení. Tyto osvědčené postupy vám pomohou optimalizovat vaše indexy, abyste zlepšili výkon databáze a zajistili hladší proces ladění výkonu.