Když se podíváme na výkon dotazů, existuje mnoho skvělých zdrojů informací v rámci SQL Server a jedním z mých oblíbených je samotný plán dotazů. V několika posledních verzích, zejména počínaje SQL Serverem 2012, každá nová verze obsahovala více podrobností v plánech provádění. Zatímco seznam vylepšení neustále roste, zde je několik atributů, které jsem považoval za cenné:
- NonParallelPlanReason (SQL Server 2012)
- Diagnostika rozšíření zbytkového predikátu (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016 SP1)
- Diagnostika rozlití tempdb (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016)
- Příznaky trasování povoleny (SQL Server 2012 SP4, SQL Server 2014 SP2, SQL Server 2016 SP1)
- Statistiky provádění dotazu operátora (SQL Server 2014 SP2, SQL Server 2016)
- Maximální povolená paměť pro jeden dotaz (SQL Server 2014 SP2, SQL Server 2016 SP1)
Chcete-li zobrazit, co existuje pro jednotlivé verze SQL Server, navštivte stránku Showplan Schema, kde najdete schéma pro každou verzi od SQL Server 2005.
I když mám všechna tato data navíc ráda, je důležité si uvědomit, že některé informace jsou relevantnější pro skutečný plán provádění než pro odhadovaný (např. informace o úniku tempdb). Některé dny můžeme zachytit a použít skutečný plán pro odstraňování problémů, jindy musíme použít odhadovaný plán. Velmi často získáváme tento odhadovaný plán – plán, který byl potenciálně použit pro problematické spouštění – z mezipaměti plánu SQL Serveru. A tahání jednotlivých plánů je vhodné při ladění konkrétního dotazu nebo sady či dotazů. Ale co když chcete nápady, kam zaměřit své ladění, pokud jde o vzory?
Mezipaměť plánu SQL Serveru je úžasným zdrojem informací, pokud jde o ladění výkonu, a nemám na mysli pouze odstraňování problémů a snahu porozumět tomu, co v systému běží. V tomto případě mluvím o těžbě informací ze samotných plánů, které se nacházejí v sys.dm_exec_query_plan, uložené jako XML ve sloupci query_plan.
Když tato data zkombinujete s informacemi ze sys.dm_exec_sql_text (takže můžete snadno zobrazit text dotazu) a sys.dm_exec_query_stats (statistiky provádění), můžete najednou začít hledat nejen ty dotazy, které jsou nejtěžší nebo spouštěné nejčastěji, ale ty plány, které obsahují konkrétní typ spojení nebo skenování indexu, nebo ty, které mají nejvyšší náklady. To se běžně nazývá těžba mezipaměti plánu a existuje několik blogových příspěvků, které hovoří o tom, jak to udělat. Můj kolega Jonathan Kehayias říká, že nenávidí psát XML, ale má několik příspěvků s dotazy na těžbu mezipaměti plánu:
- Ladění „prahové hodnoty pro paralelismus“ z mezipaměti plánu
- Nalezení implicitních konverzí sloupců v mezipaměti plánu
- Zjištění, které dotazy v mezipaměti plánu používají konkrétní index
- Procházení mezipaměti plánů SQL:Hledání chybějících indexů
- Nalezení klíčových vyhledávání v mezipaměti plánu
Pokud jste nikdy nezkoumali, co je v mezipaměti vašeho plánu, jsou dotazy v těchto příspěvcích dobrým začátkem. Mezipaměť plánu má však svá omezení. Je například možné provést dotaz a plán nenechat přejít do mezipaměti. Pokud máte například povolenou možnost optimalizace pro pracovní zátěže adhoc, pak se při prvním spuštění uloží do mezipaměti plánu kompilovaný útržek plánu, nikoli celý zkompilovaný plán. Ale největší výzvou je, že mezipaměť plánu je dočasná. Na serveru SQL Server existuje mnoho událostí, které mohou zcela vymazat mezipaměť plánu nebo ji vymazat pro databázi, a plány mohou být zastaralé, pokud se nepoužívají, nebo mohou být odstraněny po rekompilaci. Abyste tomu zabránili, musíte se obvykle buď pravidelně dotazovat na mezipaměť plánu, nebo naplánovat snímek obsahu do tabulky.
To se mění v SQL Server 2016 s Query Store.
Když má uživatelská databáze povoleno úložiště dotazů, text a plány pro dotazy prováděné proti této databázi jsou zachyceny a uchovány v interních tabulkách. Spíše než dočasný pohled na to, co se aktuálně provádí, máme dlouhodobý obrázek toho, co bylo dříve spuštěno. Množství uchovávaných dat je určeno nastavením CLEANUP_POLICY, které je výchozí na 30 dní. Ve srovnání s mezipamětí plánu, která může představovat jen několik hodin provádění dotazu, data Query Store mění hru.
Zvažte scénář, kdy provádíte analýzu indexů – některé indexy se nepoužívají a máte některá doporučení od chybějících indexových DMV. Chybějící indexové DMV neposkytují žádné podrobnosti o tom, jaký dotaz vygeneroval chybějící doporučení indexu. Můžete se dotazovat na mezipaměť plánu pomocí dotazu z Jonathanova příspěvku Hledání chybějících indexů. Pokud to provedu proti své lokální instanci SQL Serveru, dostanu několik řádků výstupu souvisejících s některými dotazy, které jsem spustil dříve.

Mohu otevřít plán v Průzkumníku plánů a vidím, že na operátoru SELECT je varování, které se týká chybějícího indexu:
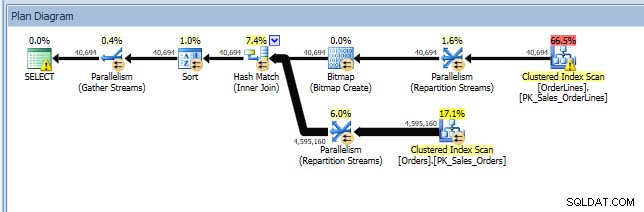
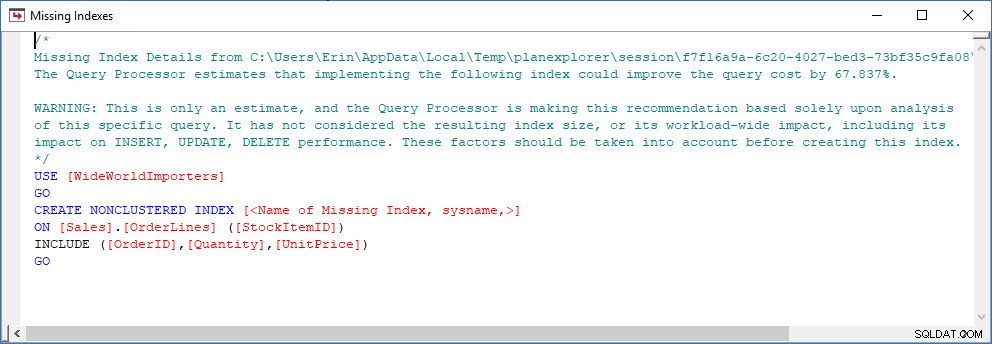
To je skvělý začátek, ale můj výstup opět závisí na tom, co je v mezipaměti. Mohu vzít Jonathanův dotaz a upravit jej pro Query Store, pak jej spustit v mé demo databázi WideWorldImporters:
USE WideWorldImporters;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT TRY_CONVERT(XML, [qsp].[query_plan]) AS [query_plan]
FROM sys.query_store_plan [qsp]) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1;
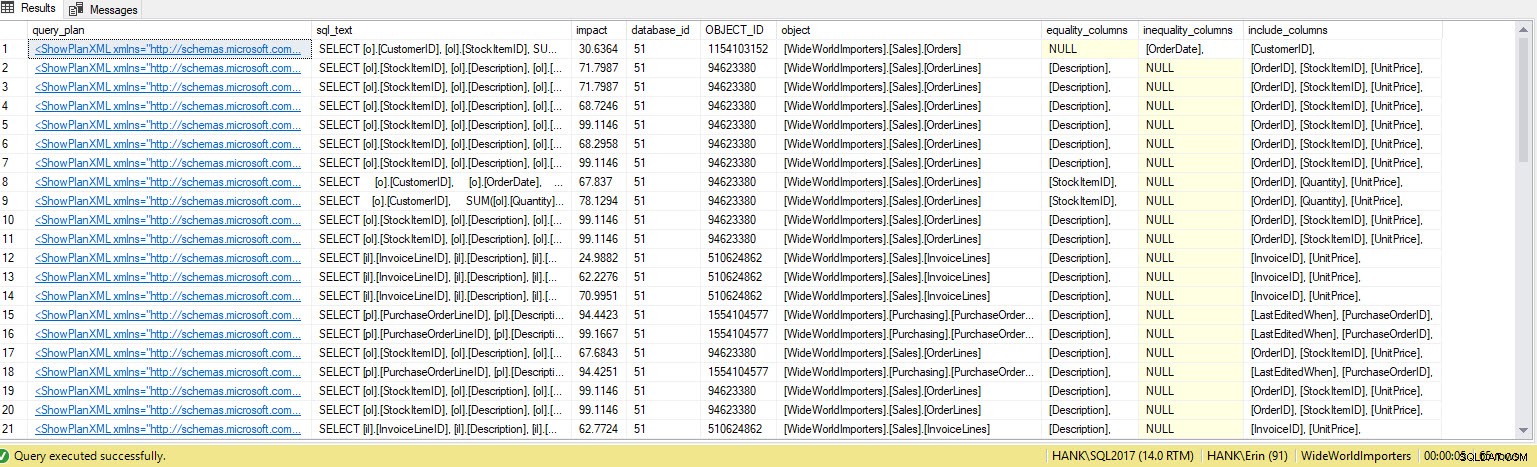
Ve výstupu dostávám mnohem více řádků. Data úložiště dotazů opět představují širší pohled na dotazy prováděné proti systému a použití těchto dat nám poskytuje komplexní metodu nejen k určení toho, které indexy chybí, ale také jaké dotazy by tyto indexy podporovaly. Odtud se můžeme ponořit hlouběji do Query Store a podívat se na metriky výkonu a frekvenci provádění, abychom porozuměli dopadu vytvoření indexu a rozhodli se, zda se dotaz spouští dostatečně často, aby zaručil index.
Pokud nepoužíváte Query Store, ale používáte SentryOne, můžete stejné informace vytěžit z databáze SentryOne. Plán dotazů je uložen v tabulce dbo.PerformanceAnalysisPlan v komprimovaném formátu, takže dotaz, který používáme, je podobnou variantou jako výše, ale všimnete si, že je také použita funkce DECOMPRESS:
USE SentryOne;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT -- need to decompress the gzipped xml here:
CONVERT(xml, CONVERT(nvarchar(max), CONVERT(varchar(max), DECOMPRESS(PlanTextGZ)))) AS [query_plan]
FROM dbo.PerformanceAnalysisPlan) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1; Na jednom systému SentryOne jsem měl následující výstup (a samozřejmě kliknutím na kteroukoli z hodnot query_plan se otevře grafický plán):

Několik výhod, které SentryOne nabízí oproti Query Store, je, že nemusíte povolit tento typ shromažďování na databázi a monitorovaná databáze nemusí podporovat požadavky na úložiště, protože všechna data jsou uložena v úložišti. Tyto informace můžete také zachytit ve všech podporovaných verzích SQL Server, nejen v těch, které podporují Query Store. Všimněte si však, že SentryOne shromažďuje pouze dotazy, které překračují prahové hodnoty, jako je doba trvání a čtení. Tyto výchozí prahové hodnoty můžete vyladit, ale je to jedna z věcí, které je třeba si uvědomit při těžbě databáze SentryOne:ne všechny dotazy mohou být shromažďovány. Kromě toho funkce DECOMPRESS není k dispozici až do SQL Server 2016; pro starší verze SQL Serveru budete chtít:
- Zálohujte databázi SentryOne a obnovte ji na SQL Server 2016 nebo novějším, abyste spustili dotazy;
- bcp data z tabulky dbo.PerformanceAnalysisPlan a importujte je do nové tabulky v instanci SQL Server 2016;
- dotaz na databázi SentryOne prostřednictvím propojeného serveru z instance SQL Server 2016; nebo,
- dotazujte se na databázi z kódu aplikace, který může po dekompresi analyzovat konkrétní věci.
Se SentryOne máte možnost těžit nejen mezipaměť plánu, ale také data uchovávaná v úložišti SentryOne. Pokud používáte SQL Server 2016 nebo vyšší a máte povoleno úložiště dotazů, můžete tyto informace také najít v sys.query_store_plan . Nejste omezeni pouze na tento příklad hledání chybějících indexů; všechny dotazy z ostatních Jonathanových příspěvků mezipaměti plánu lze upravit tak, aby je bylo možné použít k dolování dat ze SentryOne nebo z Query Store. Dále, pokud jste dostatečně obeznámeni s XQuery (nebo jste ochotni se učit), můžete použít schéma Showplan Schema, abyste zjistili, jak analyzovat plán, abyste našli požadované informace. To vám dává možnost najít vzory a anti-vzory ve vašich plánech dotazů, které může váš tým opravit, než se stanou problémem.