K tomuto příspěvku jsou připojeny „řetězce:z dobrého důvodu. Prozkoumáme hluboko do SQL VARCHAR, datového typu, který pracuje s řetězci.
Toto je také „jen pro vaše oči“, protože bez provázků nebudou naše oči číst a užívat si žádné blogové příspěvky, webové stránky, návody ke hrám, recepty se záložkami a mnoho dalšího. Každý den se zabýváme milionem strun. Jako vývojáři jsme tedy vy a já zodpovědní za to, abychom tento druh dat efektivně ukládali a měli k nim přístup.
S ohledem na to se budeme zabývat tím, co je pro úložiště a výkon nejdůležitější. Zadejte pro tento typ dat, co dělat a co ne.
Ale předtím je VARCHAR pouze jedním z typů řetězců v SQL. Čím se liší?
Co je VARCHAR v SQL? (s příklady)
VARCHAR je datový typ řetězce nebo znaku různé velikosti. Můžete s ním ukládat písmena, čísla a symboly. Počínaje SQL Serverem 2019 můžete při použití řazení s podporou UTF-8 používat celou řadu znaků Unicode.
Sloupce nebo proměnné VARCHAR můžete deklarovat pomocí VARCHAR[(n)], kde n znamená velikost řetězce v bajtech. Rozsah hodnot pro n je 1 až 8000. To je mnoho znakových dat. Ale ještě více to můžete deklarovat pomocí VARCHAR(MAX), pokud potřebujete gigantický řetězec až 2 GB. To je dost velké pro váš seznam tajemství a soukromých věcí ve vašem deníku! Všimněte si však, že jej můžete deklarovat i bez velikosti, a pokud tak učiníte, výchozí je 1.
Uveďme příklad.
DECLARE @actor VARCHAR(20) = 'Robert Downey Jr.';
DECLARE @movieCharacter VARCHAR(10) = 'Iron Man';
DECLARE @movie VARCHAR = 'Avengers';
SELECT @actor, @movieCharacter, @movie
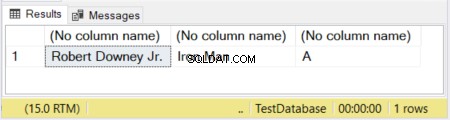
Na obrázku 1 mají první 2 sloupce definované velikosti. Třetí sloupec je ponechán bez velikosti. Takže slovo „Avengers“ je zkráceno, protože VARCHAR bez deklarované velikosti má výchozí hodnotu 1 znak.
Nyní zkusme něco velkého. Mějte však na paměti, že spuštění tohoto dotazu bude chvíli trvat – 23 sekund na mém notebooku.
-- This will take a while
DECLARE @giganticString VARCHAR(MAX);
SET @giganticString = REPLICATE(CAST('kage bunshin no jutsu' AS VARCHAR(MAX)),100000000)
SELECT DATALENGTH(@giganticString)
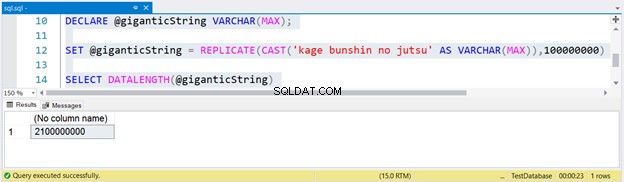
Abychom vytvořili obrovský řetězec, replikovali jsme kage bunshin no jutsu 100 milionůkrát. Všimněte si CAST v rámci REPLICATE. Pokud řetězcový výraz nepřenesete na VARCHAR(MAX), bude výsledek zkrácen pouze na 8000 znaků.
Ale jak je SQL VARCHAR ve srovnání s jinými datovými typy řetězců?
Rozdíl mezi CHAR a VARCHAR v SQL
Ve srovnání s VARCHAR je CHAR znakovým datovým typem s pevnou délkou. Bez ohledu na to, jak malou nebo velkou hodnotu vložíte do proměnné CHAR, konečná velikost je velikost proměnné. Podívejte se na srovnání níže.
DECLARE @tvSeriesTitle1 VARCHAR(20) = 'The Mandalorian';
DECLARE @tvSeriesTitle2 CHAR(20) = 'The Mandalorian';
SELECT DATALENGTH(@tvSeriesTitle1) AS VarcharValue,
DATALENGTH(@tvSeriesTitle2) AS CharValue
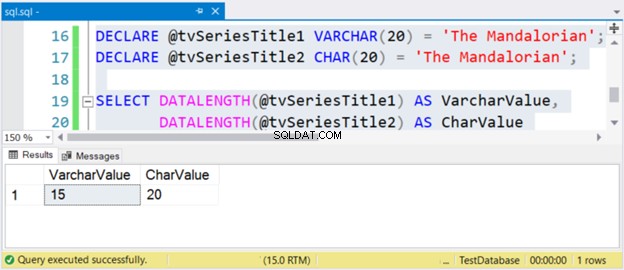
Velikost řetězce „The Mandalorian“ je 15 znaků. Tedy VarcharValue sloupec to správně odráží. Nicméně CharValue zachovává si velikost 20 – je vyplněna 5 mezerami vpravo.
SQL VARCHAR vs NVARCHAR
Při porovnávání těchto datových typů mě napadají dvě základní věci.
Za prvé je to velikost v bajtech. Každý znak v NVARCHAR má dvojnásobnou velikost než VARCHAR. NVARCHAR(n) je pouze od 1 do 4000.
Potom znaky, které může uložit. NVARCHAR může ukládat vícejazyčné znaky, jako je korejština, japonština, arabština atd. Pokud plánujete do databáze uložit texty korejského K-Popu, je tento typ dat jednou z vašich možností.
Podívejme se na příklad. Budeme používat K-popovou skupinu 세븐틴 nebo Seventeen v angličtině.
DECLARE @kpopGroupKorean NVARCHAR(5) = N'세븐틴';
SELECT @kpopGroupKorean AS KPopGroup,
DATALENGTH(@kpopGroupKorean) AS SizeInBytes,
LEN(@kpopGroupKorean) AS [NoOfChars]
Výše uvedený kód vypíše hodnotu řetězce, jeho velikost v bajtech a počet znaků. Pokud se nejedná o znaky Unicode, počet znaků se rovná velikosti v bajtech. Ale není tomu tak. Podívejte se na obrázek 4 níže.
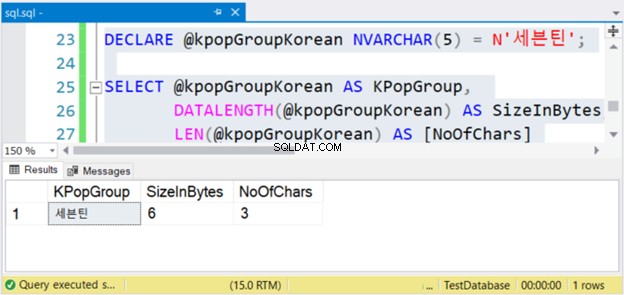
Vidět? Pokud má NVARCHAR 3 znaky, je velikost v bajtech dvojnásobná. Ale ne s VARCHAR. Totéž platí, pokud používáte anglické znaky.
Ale co NCHAR? NCHAR je protějšek CHAR pro znaky Unicode.
SQL Server VARCHAR s podporou UTF-8
VARCHAR s podporou UTF-8 je možný na úrovni serveru, databáze nebo sloupce tabulky změnou informací o řazení. Použité řazení by mělo podporovat UTF-8.
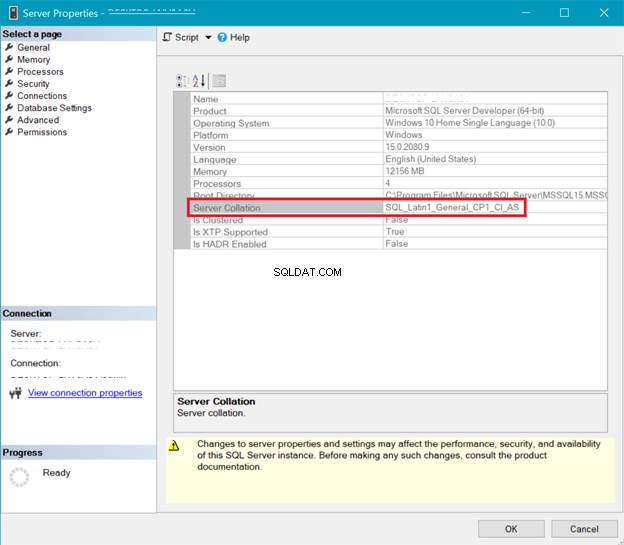
ŘÁDENÍ SERVERU SQL
Obrázek 5 představuje okno v SQL Server Management Studio, které ukazuje řazení serveru.
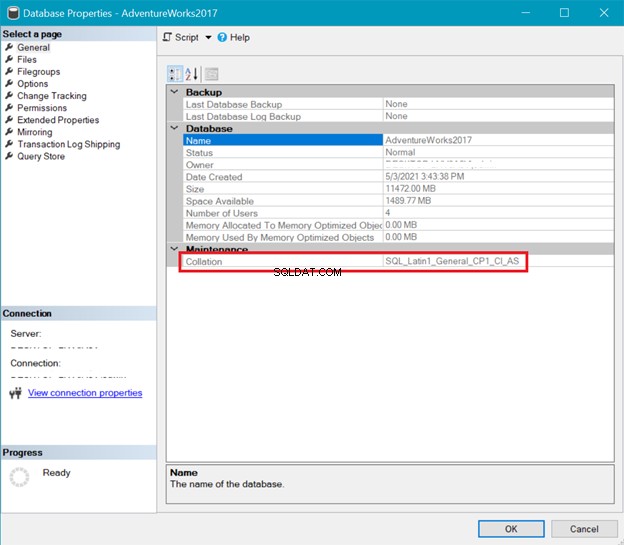
ŘÁDÁNÍ DATABÁZÍ
Obrázek 6 mezitím ukazuje seřazení AdventureWorks databáze.
SOUBOR SLOUPCE TABULKY
Jak server, tak databáze uvedené výše ukazují, že UTF-8 není podporováno. Porovnávací řetězec by měl obsahovat _UTF8 pro podporu UTF-8. Stále však můžete používat podporu UTF-8 na úrovni sloupců tabulky. Viz příklad.
CREATE TABLE SeventeenMemberList
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
KoreanName VARCHAR(20) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL,
EnglishName VARCHAR(20) NOT NULL
)
Výše uvedený kód má Latin1_General_100_BIN2_UTF8 řazení pro KoreanName sloupec. Ačkoli VARCHAR a nikoli NVARCHAR, tento sloupec bude přijímat znaky korejského jazyka. Pojďme vložit nějaké záznamy a pak je zobrazit.
INSERT INTO SeventeenMemberList
(KoreanName, EnglishName)
VALUES
(N'에스쿱스','S.Coups')
,(N'원우','Wonwoo')
,(N'민규','Mingyu')
,(N'버논','Vernon')
,(N'우지','Woozi')
,(N'정한','Jeonghan')
,(N'조슈아','Joshua')
,(N'도겸','DK')
,(N'승관','Seungkwan')
,(N'호시','Hoshi')
,(N'준','Jun')
,(N'디에잇','The8')
,(N'디노','Dino')
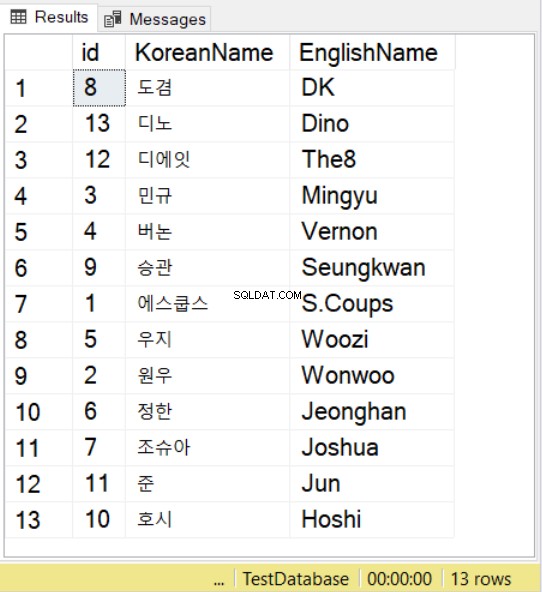
SELECT * FROM SeventeenMemberList
ORDER BY KoreanName
COLLATE Latin1_General_100_BIN2_UTF8
Používáme jména ze skupiny Seventeen K-pop s korejskými a anglickými protějšky. Všimněte si, že u korejských znaků musíte před hodnotu uvést N , stejně jako to, co děláte s hodnotami NVARCHAR.
Poté, když použijete SELECT s ORDER BY, můžete také použít řazení. Můžete to pozorovat na příkladu výše. To se bude řídit pravidly řazení pro zadané řazení.
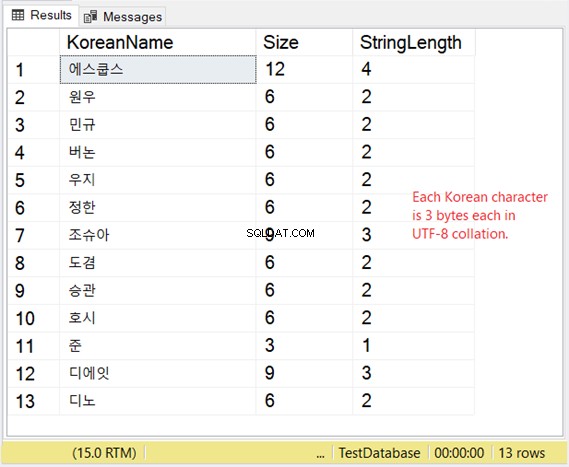
ULOŽENÍ VARCHAR S PODPOROU UTF-8
Ale jak je to s ukládáním těchto postav? Pokud očekáváte 2 bajty na znak, čeká vás překvapení. Podívejte se na obrázek 8.
Pokud vám tedy na úložišti hodně záleží, zvažte při používání VARCHAR s podporou UTF-8 níže uvedenou tabulku.
| Postavy | Velikost v bajtech |
| Ascii 0 – 127 | 1 |
| Písmo založené na latince a řečtina, cyrilice, koptština, arménština, hebrejština, arabština, syrština, tana a n’ko | 2 |
| Východoasijské písmo jako čínština, korejština a japonština | 3 |
| Znaky v rozsahu 010000–10FFFF | 4 |
Náš korejský příklad je východoasijský skript, takže má 3 bajty na znak.
Nyní, když jsme skončili s popisem a porovnáváním VARCHAR s jinými typy řetězců, pojďme se nyní zabývat tím, co dělat a co nedělat
Jak používat VARCHAR na serveru SQL Server
1. Zadejte velikost
Co by se mohlo pokazit bez určení velikosti?
ZKRÁCENÍ STRING
Pokud se zadávání velikosti ztratíte, dojde ke zkrácení řetězce. Takový příklad jste již viděli dříve.
VLIV NA SKLADOVÁNÍ A VÝKON
Dalším aspektem je úložiště a výkon. Potřebujete pouze nastavit správnou velikost dat, ne více. Ale jak to můžeš vědět? Chcete-li se v budoucnu vyhnout zkrácení, můžete jej nastavit na největší velikost. To je VARCHAR(8000) nebo dokonce VARCHAR(MAX). A 2 bajty budou uloženy tak, jak jsou. To samé s 2GB. Záleží na tom?
Odpověď nás zavede ke konceptu, jak SQL Server ukládá data. Mám další článek, který to podrobně vysvětluje s příklady a ilustracemi.
Stručně řečeno, data jsou uložena na stránkách o velikosti 8 kB. Když řádek dat překročí tuto velikost, SQL Server jej přesune do jiné alokační jednotky stránky s názvem ROW_OVERFLOW_DATA.
Předpokládejme, že máte 2bajtová data VARCHAR, která se mohou vejít do původní alokační jednotky stránky. Když uložíte řetězec větší než 8000 bajtů, data se přesunou na stránku přetečení řádků. Poté jej znovu zmenšete na menší velikost a přesune se zpět na původní stránku. Pohyb tam a zpět způsobuje velké množství I/O a omezení výkonu. Získání tohoto ze 2 stránek místo 1 vyžaduje také další I/O.
Dalším důvodem je indexování. VARCHAR(MAX) je velké NE jako indexový klíč. Mezitím VARCHAR(8000) překročí maximální velikost indexového klíče. To je 1700 bajtů pro neklastrované indexy a 900 bajtů pro klastrované indexy.
VLIV KONVERZE DAT
Ještě je tu další úvaha:konverze dat. Zkuste to s CAST bez velikosti, jako je kód níže.
SELECT
SYSDATETIMEOFFSET() AS DateTimeInput
,CAST(SYSDATETIMEOFFSET() AS VARCHAR) AS ConvertedDateTime
,DATALENGTH(CAST(SYSDATETIMEOFFSET() AS VARCHAR)) AS ConvertedLength
Tento kód provede převod data/času s informacemi o časovém pásmu na VARCHAR.
Pokud se tedy při zadávání velikosti během CAST nebo CONVERT ztratíme, výsledek je omezen pouze na 30 znaků.
Co takhle převést NVARCHAR na VARCHAR s podporou UTF-8? Podrobné vysvětlení k tomu bude později, takže pokračujte ve čtení.
2. Pokud se velikost řetězce výrazně liší
, použijte VARCHARJména z AdventureWorks databáze se liší velikostí. Jedno z nejkratších jmen je Min Su, zatímco nejdelší jméno je Osarumwense Uwaifiokun Agbonile. To je mezi 6 a 31 znaky včetně mezer. Importujme tyto názvy do 2 tabulek a porovnejme mezi VARCHAR a CHAR.
-- Table using VARCHAR
CREATE TABLE VarcharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
varcharName VARCHAR(50) NOT NULL
)
GO
CREATE INDEX IX_VarcharAsIndexKey_varcharName ON VarcharAsIndexKey(varcharName)
GO
-- Table using CHAR
CREATE TABLE CharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
charName CHAR(50) NOT NULL
)
GO
CREATE INDEX IX_CharAsIndexKey_charName ON CharAsIndexKey(charName)
GO
INSERT INTO VarcharAsIndexKey (varcharName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
INSERT INTO CharAsIndexKey (charName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
GO
Které z těch 2 jsou lepší? Pojďme zkontrolovat logická čtení pomocí níže uvedeného kódu a zkontrolovat výstup STATISTICS IO.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT id, varcharName
FROM VarcharAsIndexKey
SELECT id, charName
FROM CharAsIndexKey
SET STATISTICS IO OFF
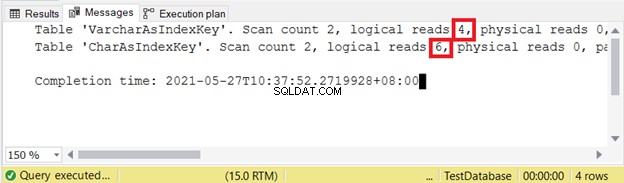
Logicky zní:
Čím méně logického čtení, tím lépe. Zde sloupec CHAR používal více než dvojnásobek protějšku VARCHAR. V tomto příkladu tedy vítězí VARCHAR.
3. Použijte VARCHAR jako indexový klíč namísto CHAR, když se hodnoty liší velikostí
Co se stalo, když byly použity jako indexové klíče? Bude na tom CHAR lépe než VARCHAR? Použijme stejná data z předchozí části a odpovězme na tuto otázku.
Vyžádáme si některá data a zkontrolujeme logická čtení. V tomto příkladu filtr používá indexový klíč.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT varcharName FROM VarcharAsIndexKey
WHERE varcharName = 'Sai, Adriana A'
OR varcharName = 'Rogers, Caitlin D'
SELECT charName FROM CharAsIndexKey
WHERE charName = 'Sai, Adriana A'
OR charName = 'Rogers, Caitlin D'
SET STATISTICS IO OFF
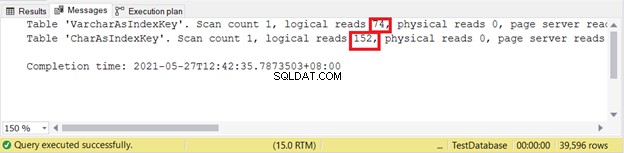
Logicky zní:
Proto jsou indexové klíče VARCHAR lepší než indexové klíče CHAR, pokud má klíč různé velikosti. Ale co takhle INSERT a UPDATE, které změní položky rejstříku?
PŘI POUŽITÍ VLOŽIT A AKTUALIZOVAT
Otestujme 2 případy a poté zkontrolujeme logická čtení jako obvykle.
SET STATISTICS IO ON
INSERT INTO VarcharAsIndexKey (varcharName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
INSERT INTO CharAsIndexKey (charName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
SET STATISTICS IO OFF
Logicky zní:
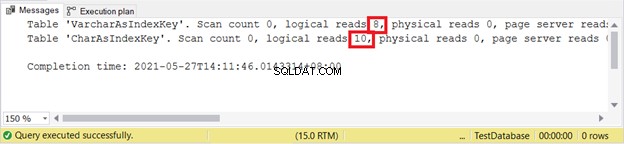
VARCHAR je stále lepší při vkládání záznamů. Co takhle AKTUALIZOVAT?
SET STATISTICS IO ON
UPDATE VarcharAsIndexKey
SET varcharName = 'Hulk'
WHERE varcharName = 'Ruffalo, Mark'
UPDATE CharAsIndexKey
SET charName = 'Hulk'
WHERE charName = 'Ruffalo, Mark'
SET STATISTICS IO OFF
Logicky zní:
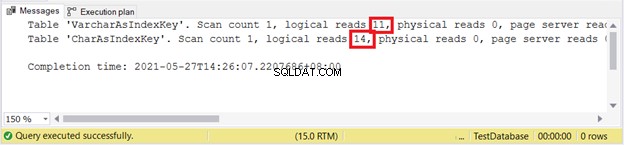
Vypadá to, že VARCHAR znovu vyhrává.
Nakonec vyhraje náš test, i když může být malý. Máte větší testovací případ, který dokazuje opak?
4. Zvažte VARCHAR s podporou UTF-8 pro vícejazyčná data (SQL Server 2019+)
Pokud vaše tabulka obsahuje kombinaci znaků Unicode a jiných, než Unicode, můžete zvážit VARCHAR s podporou UTF-8 oproti NVARCHAR. Pokud je většina znaků v rozsahu ASCII 0 až 127, může nabídnout úsporu místa ve srovnání s NVARCHAR.
Abychom pochopili, co tím myslím, pojďme srovnání.
NVARCHAR NA VARCHAR S PODPOROU UTF-8
Už jste migrovali své databáze na SQL Server 2019? Plánujete migrovat data řetězců do řazení UTF-8? Pro představu vám poskytneme příklad smíšené hodnoty japonských a nejaponských znaků.
CREATE TABLE NVarcharToVarcharUTF8
(
NVarcharValue NVARCHAR(20) NOT NULL,
VarcharUTF8 VARCHAR(45) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL
)
GO
INSERT INTO NVarcharToVarcharUTF8
(NVarcharValue, VarcharUTF8)
VALUES
(N'NARUTO-ナルト- 疾風伝',N'NARUTO-ナルト- 疾風伝'); -- NARUTO Shippûden
SELECT
NVarcharValue
,LEN(NVarcharValue) AS nvarcharNoOfChars
,DATALENGTH(NVarcharValue) AS nvarcharSizeInBytes
,VarcharUTF8
,LEN(VarcharUTF8) AS varcharNoOfChars
,DATALENGTH(VarcharUTF8) AS varcharSizeInBytes
FROM NVarcharToVarcharUTF8
Nyní, když jsou data nastavena, zkontrolujeme velikost v bajtech 2 hodnot:

Překvapení! S NVARCHAR je velikost 30 bajtů. To je 15krát více než 2 znaky. Ale při převodu na VARCHAR s podporou UTF-8 je velikost pouze 27 bajtů. Proč 27? Zkontrolujte, jak se to počítá.

9 znaků má tedy každý 1 bajt. To je zajímavé, protože u NVARCHAR mají anglická písmena také 2 bajty. Zbytek japonských znaků má každý 3 bajty.
Pokud by to byly všechny japonské znaky, 15znakový řetězec by měl 45 bajtů a také by spotřeboval maximální velikost VarcharUTF8 sloupec. Všimněte si, že velikost NVarcharValue sloupec je menší než VarcharUTF8 .
Při převodu z NVARCHAR se velikosti nemohou shodovat, nebo data nemusí sedět. Můžete se podívat na předchozí tabulku 1.
Zvažte dopad na velikost při převodu NVARCHAR na VARCHAR s podporou UTF-8.
Nepoužívat VARCHAR na SQL Server
1. Když je velikost řetězce pevná a bez hodnoty Null, použijte místo toho CHAR.
Obecným pravidlem, když je vyžadován řetězec pevné velikosti, je použít CHAR. Řídím se tím, když mám požadavek na data, který vyžaduje správně vyplněné prostory. Jinak použiji VARCHAR. Měl jsem několik případů použití, kdy jsem potřeboval vypsat řetězce pevné délky bez oddělovačů do textového souboru pro klienta.
Dále používám sloupce CHAR pouze v případě, že sloupce nebudou mít hodnotu null. Proč? Protože velikost sloupců CHAR v bajtech, když NULL je rovna definované velikosti sloupce. Přesto VARCHAR, když má NULL velikost 1 bez ohledu na to, jak velká je definovaná velikost. Spusťte níže uvedený kód a uvidíte jej sami.
DECLARE @charValue CHAR(50) = NULL;
DECLARE @varcharValue VARCHAR(1000) = NULL;
SELECT
DATALENGTH(ISNULL(@charvalue,0)) AS CharSize
,DATALENGTH(ISNULL(@varcharvalue,0)) AS VarcharSize
2. Nepoužívejte VARCHAR(n) Pokud n Překročí 8000 bajtů. Místo toho použijte VARCHAR(MAX).
Máte řetězec, který přesáhne 8000 bajtů? Nyní je čas použít VARCHAR(MAX). Ale pro nejběžnější formy dat, jako jsou jména a adresy, je VARCHAR(MAX) přehnaný a bude mít vliv na výkon. Z mé osobní zkušenosti si nepamatuji požadavek, že bych použil VARCHAR(MAX).
3. Při použití vícejazyčných znaků se serverem SQL Server 2017 a nižším. Místo toho použijte NVARCHAR.
Toto je jasná volba, pokud stále používáte SQL Server 2017 a nižší.
Sečteno a podtrženo
Datový typ VARCHAR nám dobře posloužil v mnoha aspektech. Dělalo mi to od SQL Serveru 7. Přesto někdy děláme špatná rozhodnutí. V tomto příspěvku je definován SQL VARCHAR a porovnán s jinými datovými typy řetězců s příklady. A znovu, zde jsou co dělat a co nedělat pro rychlejší databázi:
Co dělat:
- Určete velikost n ve VARCHAR[(n)], i když je to volitelné.
- Používejte jej, když se velikost řetězce výrazně liší.
- Považujte sloupce VARCHAR za indexové klíče namísto CHAR.
- A pokud nyní používáte SQL Server 2019, zvažte VARCHAR pro vícejazyčné řetězce s podporou UTF-8.
Ne:
- Nepoužívejte VARCHAR, pokud je velikost řetězce pevná a bez možnosti null.
- Nepoužívejte VARCHAR(n), pokud velikost řetězce překročí 8000 bajtů.
- Při použití SQL Server 2017 a starších nepoužívejte VARCHAR pro vícejazyčná data.
Chcete ještě něco dodat? Dejte nám vědět v sekci Komentáře. Pokud si myslíte, že to pomůže vašim přátelům vývojářům, sdílejte to prosím na svých oblíbených platformách sociálních médií.