Ve svém předchozím příspěvku v této sérii jsem ukázal, že ne všechny scénáře dotazů mohou těžit z technologií In-Memory OLTP. Ve skutečnosti může mít používání Hekaton v určitých případech použití skutečně škodlivý vliv na výkon (kliknutím zvětšíte):

Profil sledování výkonu během provádění uložené procedury
V tomto scénáři jsem však mohl naskládat balíček proti Hekatonovi dvěma způsoby:
- Typ tabulky optimalizované pro paměť, který jsem vytvořil, měl počet segmentů 256, ale pro porovnání jsem předal až 2 000 hodnot. V novějším příspěvku na blogu od týmu SQL Server vysvětlili, že nadměrné dimenzování počtu segmentů je lepší než jeho poddimenzování – něco, co jsem obecně věděl, ale neuvědomil jsem si, že má také významný vliv na proměnné tabulky:Keep mějte na paměti, že pro hash index by měl být bucket_count přibližně 1-2X počtu očekávaných jedinečných indexových klíčů. Nadměrná velikost je obvykle lepší než poddimenzování:pokud někdy vložíte do proměnných pouze 2 hodnoty, ale někdy vložíte až 1000 hodnot, je obvykle lepší zadat
BUCKET_COUNT=1000.O skutečném důvodu toho výslovně nehovoří a jsem si jist, že existuje spousta technických podrobností, do kterých bychom se mohli ponořit, ale normativní pokyny se zdají být příliš velké.
- Primárním klíčem byl index hash ve dvou sloupcích, zatímco parametr s hodnotou tabulky se pokoušel o shodu hodnot pouze v jednom z těchto sloupců. Zcela jednoduše to znamenalo, že nebylo možné použít hash index. Tony Rogerson to vysvětluje trochu podrobněji v nedávném příspěvku na blogu:Hash se generuje ve všech sloupcích obsažených v indexu, musíte také zadat všechny sloupce v indexu hash ve výrazu kontroly rovnosti, jinak index nelze použít. .
Dříve jsem to neukázal, ale všimněte si, že plán proti tabulce optimalizované pro paměť s dvousloupcovým hash indexem ve skutečnosti provádí skenování tabulky, spíše než hledání indexu, které byste mohli očekávat proti neshlukovanému hash indexu (protože hlavní sloupec byl
SalesOrderID):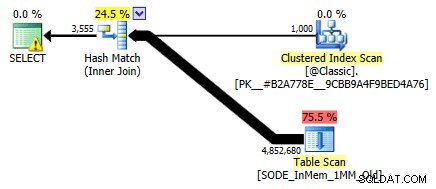
Plán dotazů zahrnující tabulku v paměti se dvěma sloupci hash indexPřesněji řečeno, v hash indexu přední sloupec neznamená kopec fazolí sám o sobě; hash se stále shoduje ve všech sloupcích, takže to vůbec nefunguje jako tradiční index B-stromu (s tradičním indexem může být predikát zahrnující pouze úvodní sloupec stále velmi užitečný při eliminaci řádků).
Co dělat?
Nejprve jsem vytvořil sekundární hash index pouze pro SalesOrderID sloupec. Příklad jedné takové tabulky s milionem kýblů:
VYTVOŘIT TABULKU [dbo].[SODE_InMem_1MM]( [SalesOrderID] [int] NOT NULL, [SalesOrderDetailID] [int] NOT NULL, [CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL, [ProductID] [int] NOT NULL, [Special OfferID] [int] NOT NULL, [UnitPrice] [peníze] NOT NULL, [UnitPriceDiscount] [peníze] NOT NULL, [LineTotal] [numerický](38, 6) NOT NULL, [rowguid] [uniqueidentifier] NOT NULL, [ModifiedDate] [datetime] NOT NULL PRIMÁRNÍ KLÍČ NEZAHRNUTÝ HASH ( [SalesOrderID], [SalesOrderDetailID] ) WITH (BUCKET_COUNT =1048576), /* Iu přidané toto sekundární index:*/ INDEX x NONCLUSTERED HASH ( [SalesOrderID] ) WITH (BUCKET_COUNT =1048576) /* Použil jsem stejný počet segmentů k minimalizaci testovacích permutací */ ) WITH (MEMORY_OPTIMIZED =ON, DURABILITY =SCHEMA_pre_DATA);Pamatujte, že naše typy tabulek jsou nastaveny takto:
CREATE TYPE dbo.ClassicTVP AS TABLE( Item INT PRIMARY KEY); CREATE TYPE dbo.InMemoryTVP AS TABLE( Item INT NOT NULL PRIMAR KEY NENCLUSTERED HASH WITH (BUCKET_COUNT =256)) WITH (MEMORY_OPTIMIZED =ON);Jakmile naplním nové tabulky daty a vytvořím novou uloženou proceduru, která bude odkazovat na nové tabulky, plán, který dostaneme, správně zobrazuje hledání indexu proti indexu hash s jedním sloupcem:
Vylepšený plán pomocí jednosloupcového hash indexuCo by to ale ve skutečnosti znamenalo pro výkon? Znovu jsem provedl stejnou sadu testů – dotazy proti této tabulce s počty segmentů 16 000, 131 000 a 1 MM; použití klasických i in-memory TVP s hodnotami 100, 1 000 a 2 000; a v případě in-memory TVP pomocí tradiční uložené procedury i nativně zkompilované uložené procedury. Zde je návod, jak probíhal výkon pro 10 000 iterací na kombinaci:
Profil výkonu pro 10 000 iterací oproti indexu hash s jedním sloupcem, pomocí TVP s 256 kbelíkyMožná si myslíte, že ten výkonnostní profil nevypadá tak skvěle; naopak je mnohem lepší než můj předchozí test minulý měsíc. To jen ukazuje, že počet segmentů pro tabulku může mít obrovský dopad na schopnost serveru SQL Server efektivně používat index hash. V tomto případě použití počtu segmentů 16K zjevně není optimální pro žádný z těchto případů a s rostoucím počtem hodnot v TVP se to exponenciálně zhoršuje.
Pamatujte si, že počet segmentů TVP byl 256. Co by se tedy stalo, kdybych to zvýšil podle pokynů společnosti Microsoft? Vytvořil jsem druhý typ stolu s vhodnější velikostí kbelíku. Protože jsem testoval hodnoty 100, 1 000 a 2 000, použil jsem další mocninu 2 pro počet segmentů (2 048):
VYTVOŘTE TYP dbo.InMemoryTVP AS TABLE( Item INT NOT NULL PRIMÁRNÍ KLÍČ NENCLUSTEROVANÝ HASH WITH (BUCKET_COUNT =2048)) WITH (MEMORY_OPTIMIZED =ON);Vytvořil jsem pro to podpůrné postupy a znovu provedl stejnou baterii testů. Zde jsou profily výkonu vedle sebe:
Porovnání profilu výkonu s 256 a 2 048 segmenty TVPZměna v počtu segmentů pro typ tabulky neměla takový dopad, jaký bych očekával, vzhledem k prohlášení společnosti Microsoft o velikosti. Opravdu to nemělo vůbec žádný pozitivní účinek; ve skutečnosti to pro některé scénáře bylo o něco horší. Celkově jsou však profily výkonu pro všechny záměry a účely stejné.
Co však mělo obrovský efekt, bylo vytvoření *správného* hash indexu pro podporu vzoru dotazu. Byl jsem vděčný, že jsem mohl prokázat, že – navzdory mým předchozím testům, které naznačovaly opak – in-memory table a in-memory TVP by mohly překonat starou školu a dosáhnout stejné věci. Vezměme si nejextrémnější případ z mého předchozího příkladu, kdy tabulka měla pouze dvousloupcový hash index:
Profil výkonu pro 10 iterací oproti indexu hash se dvěma sloupciLišta úplně vpravo zobrazuje dobu trvání pouhých 10 iterací nativní uložené procedury, která se shoduje s nevhodným hash indexem – doba dotazování se pohybuje od 735 do 1 601 milisekund. Nyní se však se správným hash indexem provádějí stejné dotazy v mnohem menším rozsahu – od 0,076 milisekundy do 51,55 milisekund. Pokud vynecháme nejhorší případ (16K kbelík se počítá), je nesrovnalost ještě výraznější. Ve všech případech je to nejméně dvakrát efektivnější (alespoň z hlediska trvání) než kterákoli metoda, bez naivně kompilované uložené procedury, proti stejné tabulce optimalizované pro paměť; a stokrát lepší než kterýkoli z přístupů oproti naší staré tabulce optimalizované pro paměť s jediným, dvousloupcovým hash indexem.
Závěr
Doufám, že jsem ukázal, že při implementaci tabulek optimalizovaných pro paměť jakéhokoli typu je třeba věnovat velkou pozornost a že v mnoha případech samotné použití TVP optimalizovaného pro paměť nemusí přinést největší nárůst výkonu. Budete chtít zvážit použití nativně zkompilovaných uložených procedur, abyste za své peníze získali co největší ránu, a abyste co nejlépe škálovali, budete opravdu chtít věnovat pozornost počtu segmentů pro hash indexy ve vašich tabulkách optimalizovaných pro paměť (ale možná ne tolik pozornosti vašim typům tabulek optimalizovaných pro paměť).
Další informace o technologii In-Memory OLTP obecně naleznete v těchto zdrojích:




- Blog týmu SQL Server (Tag:Hekaton a Tag:In-Memory OLTP – nejsou kódové názvy zábavné?)
- Blog Boba Beauchemina
- Blog Klause Aschenbrennera