Potvrzení čtení je druhé nejslabší ze čtyř úrovní izolace definovaných standardem SQL. Nicméně je to výchozí úroveň izolace pro mnoho databázových strojů, včetně SQL Serveru. Tento příspěvek ze série o úrovních izolace a vlastnostech ACID transakcí se zabývá logickými a fyzickými zárukami, které skutečně poskytuje izolace potvrzená čtením.
Logické záruky
Standard SQL vyžaduje, aby transakce spuštěná v izolaci potvrzení o čtení byla pouze pro čtení potvrzeno data. Tento požadavek vyjadřuje zákazem fenoménu souběžnosti známého jako nečisté čtení. Nečisté čtení nastane, když transakce čte data, která byla zapsána jinou transakcí, před dokončením této druhé transakce. Dalším způsobem, jak to vyjádřit, je říci, že ke špinavému čtení dochází, když transakce čte nepotvrzená data.
Standard také zmiňuje, že transakce běžící v izolaci potvrzené čtením se může setkat s fenoménem souběžnosti známým jako neopakovatelné čtení a fantomy . Ačkoli mnoho knih vysvětluje tyto jevy tak, že transakce jsou schopny vidět změněné nebo nové datové položky, pokud jsou data následně znovu načtena, toto vysvětlení může posílit omylnou představu že k jevu souběžnosti může dojít pouze uvnitř explicitní transakce, která obsahuje více příkazů. Není tomu tak. Jednoduché prohlášení bez explicitní transakce je stejně zranitelný vůči neopakovatelnému čtení a fantomovým jevům, jak brzy uvidíme.
To je v podstatě vše, co norma říká k tématu izolace potvrzené čtením. Na první pohled se zdá, že čtení pouze odevzdaných dat je docela dobrou zárukou rozumného chování, ale ďábel se jako vždy skrývá v detailech. Jakmile začnete hledat potenciální mezery v této definici je příliš snadné najít případy, kdy naše transakce potvrzené čtením nemusí přinést výsledky, které bychom očekávali. Znovu je probereme podrobněji za chvíli nebo dva.
Odlišné fyzické implementace
Existují alespoň dvě věci, které znamenají, že pozorované chování úrovně izolace potvrzeného čtení může být na různých databázových strojích zcela odlišné. Zaprvé, standardní požadavek SQL na pouze čtení potvrzených dat není nutně znamená, že potvrzená data načtená transakcí budou naposledy potvrzená data.
Databázový stroj může číst potvrzenou verzi řádku z jakéhokoli bodu v minulosti a stále splňují standardní definici SQL. Několik populárních databázových produktů implementuje izolaci potvrzeného čtení tímto způsobem. Výsledky dotazů získané v rámci této implementace izolace potvrzení o čtení mohou být svévolně zastaralé ve srovnání s aktuálním potvrzeným stavem databáze. Toto téma, jak se vztahuje na SQL Server, pokryjeme v dalším příspěvku v seriálu.
Druhá věc, na kterou chci upozornit, je, že standardní definice SQL ne zabránit konkrétní implementaci v poskytování další ochrany s souběžným efektem kromě zabránění nepravdivému čtení . Norma pouze uvádí, že nečisté čtení není povoleno, nevyžaduje, aby byly povoleny jiné jevy souběžnosti. na jakékoli dané úrovni izolace.
Aby bylo jasno v tomto druhém bodě, databázový stroj vyhovující standardům by mohl implementovat všechny úrovně izolace pomocí serializovatelných chování, pokud se tak rozhodne. Některé velké komerční databázové stroje také poskytují implementaci čtení potvrzené, která jde mnohem dál, než je pouhé zabránění nečistému čtení (ačkoli žádný nezachází tak daleko, že poskytuje úplnou izolaci v ACID smysl toho slova).
Kromě toho u několika oblíbených produktů přečtěte si izolace je nejnižší dostupná úroveň izolace; jejich implementace read uncommitted izolace jsou přesně stejné jako čtení potvrzené. Standard to umožňuje, ale tyto druhy rozdílů zvyšují složitost již tak obtížného úkolu migrace kódu z jedné platformy na druhou. Když mluvíme o chování na úrovni izolace, je obvykle důležité specifikovat také konkrétní platformu.
Pokud vím, SQL Server je mezi hlavními komerčními databázovými stroji jedinečný tím, že poskytuje dva implementace úrovně izolace potvrzeného čtení, každá s velmi odlišným fyzickým chováním. Tento příspěvek pokrývá první z nich, uzamykání číst odevzdaně.
Zamykání serveru SQL Read Committed
Pokud je volba databáze READ_COMMITTED_SNAPSHOT je OFF , SQL Server používá uzamykání implementace úrovně izolace potvrzeného čtení, kde se používají sdílené zámky, aby se zabránilo souběžné transakci v souběžné úpravě dat, protože úprava by vyžadovala exkluzivní zámek, který není kompatibilní se sdíleným zámkem.
Klíčový rozdíl mezi uzamčením SQL Serveru pro čtení potvrzené a zamykáním opakovatelného čtení (které také přijímá sdílené zámky při čtení dat) je ten, že čtení potvrzené uvolňuje sdílený zámek co nejdříve , zatímco opakovatelné čtení drží tyto zámky až do konce přiložené transakce.
Když uzamčení potvrzeného čtení získá zámky na úrovni granularity řádku, sdílený zámek přijatý na řádku se uvolní při převzetí sdíleného zámku na dalším řádku . Při granularitě stránky se zámek sdílené stránky uvolní při přečtení prvního řádku na další stránce a tak dále. Pokud není s dotazem poskytnuta nápověda k uzamčení granularity, databázový stroj rozhodne, s jakou úrovní granularity začít. Všimněte si, že s radami ohledně zrnitosti se zachází pouze jako s návrhy enginu, zpočátku však může být přijat méně podrobný zámek, než je požadováno. Zámky mohou být také eskalovány během provádění z úrovně řádku nebo stránky na úroveň oddílu nebo tabulky v závislosti na konfiguraci systému.
Zde je důležité, že sdílené zámky jsou obvykle drženy pouze velmi krátkou dobu během provádění příkazu. Abychom explicitně vyřešili jednu běžnou mylnou představu, uzamčení potvrzeného čtení není podržte sdílené zámky až do konce příkazu.
Uzamykání chování zavázaného čtení
Krátkodobé sdílené zámky používané implementací SQL Server locking pro čtení poskytují jen velmi málo záruk běžně očekávaných od databázových transakcí programátory T-SQL. Zejména příkaz spuštěný pod uzamčením přečtení potvrzeno izolace:
- Může se stejný řádek setkat vícekrát;
- Může zcela vynechat některé řádky; a
- Ne poskytují časové zobrazení dat
Tento seznam se může zdát spíše jako popis podivného chování, které si můžete více spojovat s použitím NOLOCK rady, ale všechny tyto věci skutečně mohou a stávají se při použití zamykání izolace potvrzené čtením.
Příklad
Zvažte jednoduchý úkol počítání řádků v tabulce pomocí zřejmého dotazu s jedním příkazem. Při zamykání izolace potvrzeného čtení s granularitou zamykání řádků náš dotaz vezme sdílený zámek na prvním řádku, přečte jej, uvolní sdílený zámek, přesune se na další řádek a tak dále, dokud nedosáhne konce struktury, kterou čte. Pro účely tohoto příkladu předpokládejme, že náš dotaz čte indexový b-strom ve vzestupném pořadí klíčů (ačkoli by mohl stejně dobře použít sestupné pořadí nebo jakoukoli jinou strategii).
Od pouze jeden řádek je v kterýkoli daný okamžik uzamčen sdílením, je jasně možné, že souběžné transakce upraví odemčené řádky v indexu, kterým prochází náš dotaz. Pokud tyto souběžné úpravy změní hodnoty klíče indexu, způsobí pohyb řádků ve struktuře indexu. S ohledem na tuto možnost níže uvedený diagram ilustruje dva problematické scénáře, které mohou nastat:
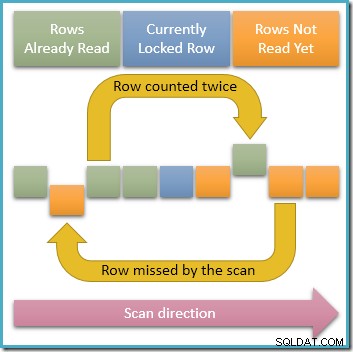
Šipka nahoře ukazuje řádek, který jsme již započítali a jehož klíč indexu byl současně upraven tak, aby se řádek posunul před aktuální pozici skenování v indexu, což znamená, že řádek bude započítán dvakrát . Druhá šipka ukazuje řádek, který se při skenování ještě nesetkal, a pohybuje se za pozicí skenování, což znamená, že řádek nebude započítán vůbec.
Nejde o zobrazení v určitém časovém okamžiku
Předchozí část ukázala, jak může zamykání read commited vynechat data úplně nebo započítat stejnou položku vícekrát (více než dvakrát, pokud máme smůlu). Třetí odrážka v seznamu neočekávaného chování uváděla, že zamykání potvrzeného čtení také neposkytuje časový pohled na data.
Odůvodnění tohoto prohlášení by nyní mělo být snadno pochopitelné. Náš dotaz na počítání by například mohl snadno číst data, která byla vložena souběžnými transakcemi poté, co se náš dotaz začal provádět. Stejně tak data, která náš dotaz vidí, mohou být změněna souběžnou aktivitou po spuštění našeho dotazu a před jeho dokončením. A konečně, data, která jsme přečetli a spočítali, mohou být smazána souběžnou transakcí před dokončením našeho dotazu.
Je zřejmé, že data zobrazená příkazem nebo transakcí spuštěnou v uzamčené izolaci potvrzení o čtení neodpovídají žádnému jednotlivému stavu databáze v jakémkoli konkrétním čase . Data, se kterými se setkáváme, mohou klidně pocházet z různých časových okamžiků, přičemž jediným společným faktorem je, že každá položka představovala poslední potvrzenou hodnotu těchto dat v době, kdy byla přečtena (i když se od té doby mohla změnit nebo zmizet).
Jak vážné jsou tyto problémy?
To vše se může zdát jako pěkně špinavá situace, pokud jste zvyklí uvažovat o svých dotazech s jedním příkazem a explicitních transakcích jako o logickém provedení okamžitě nebo jako běžící proti jedinému potvrzenému stavu databáze v okamžiku použití výchozí úroveň izolace SQL Server. Rozhodně to dobře nezapadá do konceptu izolace ve smyslu ACID.
Vzhledem ke zjevné slabosti záruk poskytovaných uzamčením izolace potvrzené čtením se můžete začít divit, jak jaké vašeho produkčního kódu T-SQL někdy fungoval správně! Samozřejmě můžeme akceptovat, že použití úrovně izolace pod serializovatelnou znamená, že se vzdáváme úplné izolace ACID transakcí výměnou za další potenciální výhody, ale jak vážné můžeme očekávat, že tyto problémy budou v praxi?
Chybějící a dvakrát započítané řádky
Tyto první dva problémy v podstatě spoléhají na klíče měnící souběžnou aktivitu ve struktuře indexu, kterou právě skenujeme. Všimněte si, že skenování zde zahrnuje část skenování částečného rozsahu hledání indexu , stejně jako známé neomezené prohledávání indexů nebo tabulek.
Pokud (rozsah) skenujeme indexovou strukturu, jejíž klíče nejsou obvykle modifikovány žádnou souběžnou aktivitou, tyto první dva problémy by neměly být příliš praktickým problémem. Je však obtížné si tím být jisti, protože plány dotazů se mohou změnit a používat jinou metodu přístupu a nový prohledávaný index může obsahovat nestálé klíče.
Musíme také mít na paměti, že mnoho produkčních dotazů skutečně potřebuje přibližný nebo stejně nejlepší odpověď na některé typy otázek. Skutečnost, že některé řádky chybí nebo jsou započítány dvakrát, nemusí v širším schématu příliš záležet. V systému s mnoha souběžnými změnami může být dokonce obtížné ujistit se, že výsledek byl nepřesné, vzhledem k tomu, že se data tak často mění. V takové situaci může být pro účely spotřebitele dat dost dobrá zhruba správná odpověď.
Žádný časový okamžik
Třetí otázka (otázka takzvaného „konzistentního“ pohledu na data v určitém časovém okamžiku) se rovněž týká stejného druhu úvah. Pro účely hlášení, kde nesrovnalosti mají tendenci vést k nepříjemným otázkám ze strany spotřebitelů dat, je často vhodnější zobrazení snímku. V jiných případech může být druh nesrovnalostí vyplývající z nedostatku časového pohledu na data dobře tolerovatelný.
Problémové scénáře
Existuje také spousta případů, kdy uvedené obavy budou být důležitý. Pokud například napíšete kód, který vynucuje obchodní pravidla v T-SQL musíte být opatrní, abyste vybrali úroveň izolace (nebo provedli jinou vhodnou akci), aby byla zaručena správnost. Mnoho obchodních pravidel lze vynutit pomocí cizích klíčů nebo omezení, kde složitosti výběru úrovně izolace za vás automaticky zpracovává databázový stroj. Jako obecné pravidlo použijte vestavěnou sadu deklarativní integrity vlastnosti je lepší než vytváření vlastních pravidel v T-SQL.
Existuje další široká třída dotazů, která zcela nevynucuje obchodní pravidlo per se , což však může mít neblahé důsledky při spuštění na výchozí úrovni izolace zamykání pro čtení potvrzené. Tyto scénáře nejsou vždy tak zřejmé jako často uváděné příklady převodů peněz mezi bankovními účty nebo zajištění toho, aby zůstatek na řadě propojených účtů nikdy neklesl pod nulu. Zvažte například následující dotaz, který identifikuje faktury po splatnosti jako vstup do nějakého procesu, který rozesílá přísně formulované upomínky:
INSERT dbo.OverdueInvoices
SELECT I.InvoiceNumber
FROM dbo.Invoices AS INV
WHERE INV.TotalDue >
(
SELECT SUM(P.Amount)
FROM dbo.Payments AS P
WHERE P.InvoiceNumber = I.InvoiceNumber
); Je zřejmé, že bychom nechtěli posílat dopis někomu, kdo svou fakturu ve splátkách plně zaplatil, jednoduše proto, že souběžná aktivita databáze v době, kdy probíhal náš dotaz, znamenala, že jsme vypočítali nesprávnou částku přijatých plateb. Skutečné dotazy na skutečné produkční systémy jsou samozřejmě často mnohem složitější než jednoduchý příklad výše.
Chcete-li to pro dnešek dokončit, podívejte se na následující dotaz a zjistěte, zda dokážete zjistit, kolik příležitostí existuje, aby se stalo něco nezamýšleného, pokud je několik takových dotazů spuštěno souběžně na úrovni izolace zamykání potvrzeného čtení (možná zatímco jiné nesouvisející transakce také upravují tabulku Případy):
-- Allocate the oldest unallocated case ID to
-- the current case worker, while ensuring
-- the worker never has more than three
-- active cases at once.
UPDATE dbo.Cases
SET WorkerID = @WorkerID
WHERE
CaseID =
(
-- Find the oldest unallocated case ID
SELECT TOP (1)
C2.CaseID
FROM dbo.Cases AS C2
WHERE
C2.WorkerID IS NULL
ORDER BY
C2.DateCreated DESC
)
AND
(
SELECT COUNT_BIG(*)
FROM dbo.Cases AS C3
WHERE C3.WorkerID = @WorkerID
) < 3; Jakmile začnete hledat všechny malé způsoby, jak se může dotaz na této úrovni izolace pokazit, může být těžké ho zastavit. Mějte na paměti dříve zmíněná upozornění týkající se skutečné potřeby zcela izolovaných a v určitém okamžiku přesných výsledků. Je naprosto v pořádku mít dotazy, které vracejí dostatečně dobré výsledky, pokud jste si vědomi kompromisů, kterých se dopouštíte pomocí read commited.
Příště
Další část této série se zabývá druhou fyzickou implementací izolace potvrzení o čtení dostupné na serveru SQL Server, izolace snímku potvrzení o čtení.
[ Viz rejstřík pro celou sérii ]