Benchmarky jsou jednou z činností, které provádějí správci databází. Spouštíte je, abyste viděli, jak se chová váš hardware, spouštíte je, abyste viděli, jak vaše aplikace a databáze spolupracují pod tlakem. Spouštíte je v mnoha různých situacích. Pojďme si o nich trochu promluvit, jaké jsou výzvy, kterým budete čelit, jakým problémům byste se měli vyhnout.
Typy srovnávacích testů
Každý benchmark je jiný. Slouží různým účelům a je třeba to vzít v úvahu, když je plánujete provozovat. Obecně lze definovat dva hlavní typy benchmarků:syntetický benchmark a, říkejme tomu, benchmark „reálného světa“.
Syntetické benchmarky jsou obvykle nástroje, které simulují určitý druh pracovní zátěže. Může to být zátěž OLTP jako v případě Sysbench, může to být nějaký „standardní“ benchmark jako v TPC-C nebo TPC-H. Obvykle jde o to, že takový benchmark simuluje nějaký druh pracovní zátěže a může být užitečný, pokud se vaše pracovní zátěž v reálném světě bude řídit stejným vzorem. Lze jej také použít k určení toho, jak vaše kombinace hardwaru a konfigurace databáze spolupracuje při daném typu zátěže. Výhody syntetických benchmarků jsou celkem jasné. Můžete je spustit všude, nezávisí na nějakém konkrétním nastavení nebo návrhu schématu. Ano, ale přicházejí s nástroji, jak vše nastavit z prázdného databázového serveru. Hlavní nevýhodou je, že to není vaše pracovní náplň. Pokud se chystáte spouštět testy OLTP pomocí Sysbench, musíte mít na paměti, že vaše aplikace nikdy nebude Sysbench. Může také spouštět zátěž OLTP, ale mix dotazů se bude lišit. Nikdy, za žádných okolností vám syntetický benchmark přesně neřekne, jak se bude vaše aplikace chovat na daném mixu hardwaru/konfigurace.
Na druhém konci spektra máme, čemu jsme říkali, benchmarky „reálného světa“. To, co zde máme na mysli, je benchmark, který používá datovou sadu a dotazy související s vaší aplikací. Ne vždy má úplný soubor dat a úplný mix dotazů. Možná se budete chtít zaměřit na některé části vaší aplikace, ale hlavní myšlenkou za tím je, že chcete porozumět přesným interakcím mezi aplikací, hardwarem a konfigurací databáze, ať už obecně nebo v některých konkrétních aspektech.
Jak jsme zmínili výše, máme dva hlavní, různé typy benchmarků, ale přesto mají některé společné věci, které musíte vzít v úvahu při pokusu o spuštění benchmarků.
-
Rozhodněte se, co chcete testovat
Za prvé, benchmarking kvůli spouštění benchmarků je nesmyslný. Musí být navržen tak, aby skutečně něčeho dosáhl. Co chcete z benchmarkového běhu získat? Chcete vyladit dotazy? Chcete vyladit konfiguraci? Chcete posoudit škálovatelnost vašeho zásobníku? Chcete svůj stoh připravit na vyšší zátěž? Chcete provést obecné nastavení konfigurace pro nový projekt? Chcete určit nejlepší nastavení pro váš hardware? To jsou příklady cílů, kterých byste mohli chtít dosáhnout. Každý z nich bude vyžadovat jiný přístup a jiné nastavení benchmarku.
-
Proveďte jednu změnu po druhé
Ať už testujete a ladíte cokoli, je nanejvýš důležité, abyste vždy provedli pouze jednu změnu konfigurace. To je opravdu kritické. Účelem benchmarku je poskytnout vám určitou představu o výkonu. Dotazy za sekundu, latence, 99 percentil, to vše vám říká, jak rychle můžete provádět dotazy a jak stabilní a předvídatelné je pracovní zatížení. Je snadné zjistit, zda změna, kterou jste provedli v konfiguraci, hardwaru nebo mixu dotazů, něco změnila:metriky z benchmarku budou vypadat jinak. Jde o to, že pokud provedete několik změn současně, neexistuje způsob, jak zjistit, která z nich je zodpovědná za celkový výsledek. Může to jít ještě dál. Řekněme, že jste změnili dvě hodnoty v konfiguraci databáze. Hodnota A a B. Celkové zlepšení je 20 %, což je docela dobré na pouhou změnu konfigurace. Pod kapotou však změna na hodnotu A přinesla zlepšení o 30 %, zatímco další změna na hodnotu B ji nastavila zpět na 20 %. U více změn současně můžete pozorovat pouze jejich společný dopad, toto není způsob, jak správně určit výsledek každé jednotlivé změny, kterou jste provedli. Jistě, výrazně to prodlužuje čas, který strávíte spuštěním benchmarku, ale je to tak.
-
Proveďte několik srovnávacích testů
Počítače jsou samy o sobě složité systémy. Mají více komponent, které se vzájemně ovlivňují:paměť, CPU, disk, síť. Pak k tomu přidejte virtualizaci, kontejnerizaci. Dále software – operační systém, aplikace, databáze. Vrstva přes vrstvu přes vrstvu přes vrstvu prvků, které spolu nějak interagují. Není snadné předvídat jeho chování. Dá se říci, že je téměř nemožné přesně předpovědět chování tak složitých systémů. To je důvod, proč spuštění jednoho benchmarku nestačí k vyvození závěrů. Co když, nevědomky, nějaký prvek, který zcela nesouvisí s tím, co chcete testovat, ovlivní celkový výkon? Vysoké zatížení jiného virtuálního počítače umístěného na stejném hostiteli. Nějaký jiný server streamuje zálohu přes síť. To může dočasně ovlivnit výkon a zkreslit výsledky benchmarku. Pokud provedete pouze jeden běh benchmarku, skončíte s nesprávnými výsledky. To je důvod, proč je osvědčeným postupem provést několik průchodů benchmarku a poté odstranit ten nejpomalejší a nejrychlejší a ostatní zprůměrovat.
-
Obrázek vydá za tisíce slov
Toto je v podstatě velmi přesný popis srovnávání. Pokud je to možné, vždy generujte grafy. V ideálním případě sledujte metriky během benchmarku tak často, jak jen můžete. Jedna sekunda granularity by měla ve většině případů stačit. Abychom se vyhnuli psaní tisíců slov, uvedeme tento příklad. Co je podle vás užitečnější? Tato sada výstupů benchmarku, které představují průměrnou QPS pro každý z 10 průchodů, každý průchod trvá 600 sekund
11650,52
11237,97
11550.16
11247.08
11177,78
11163,76
11131,47
11235.06
11235,59
11277,25
Nebo tento graf:
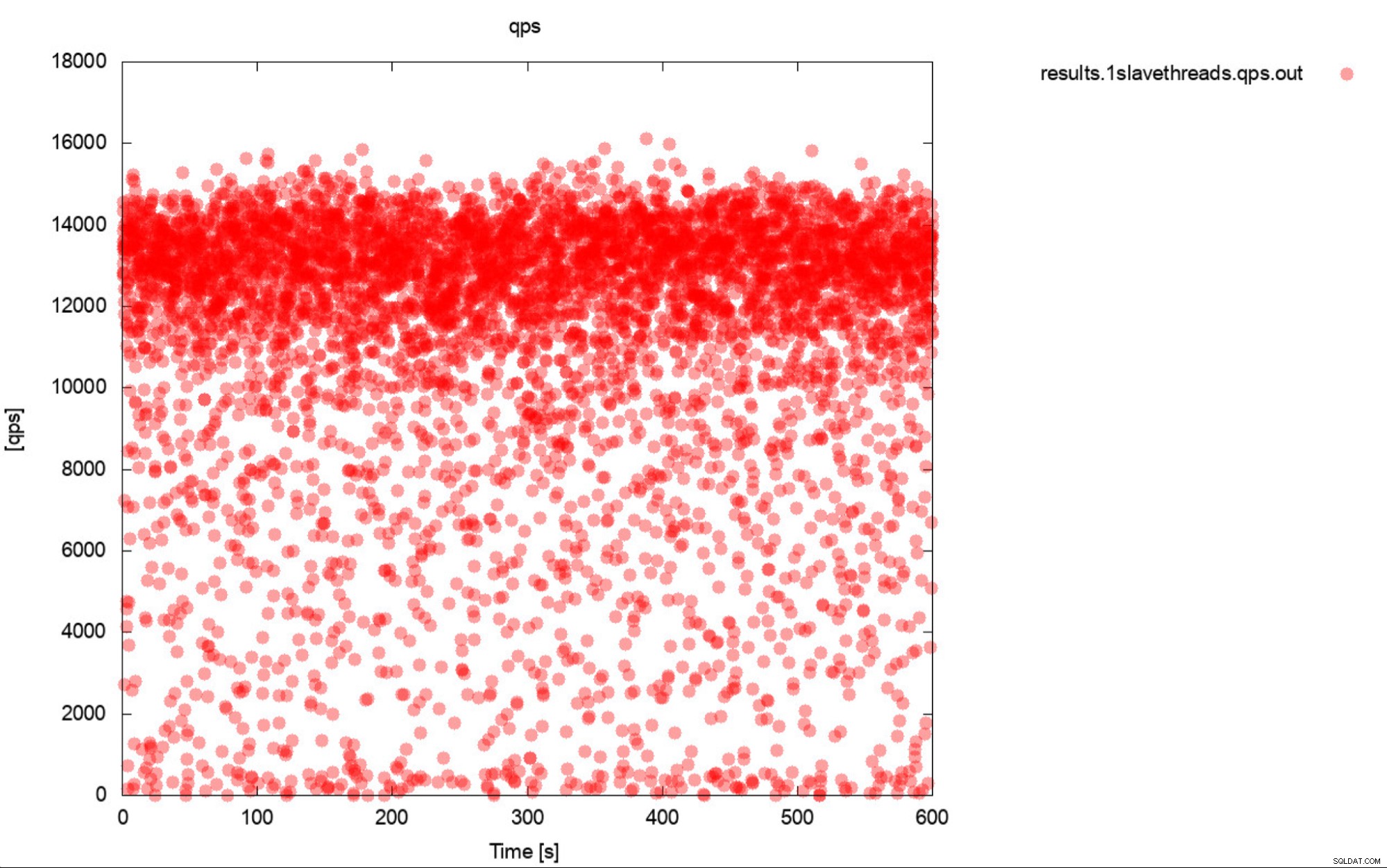
Průměrná QPS je 11 000, ale ve skutečnosti je výkon všude místo, včetně poklesů na 0 dotazů provedených během sekundy, a je to rozhodně něco, na čem chcete pracovat a zlepšovat se na produkčních systémech.
-
Dotazy za sekundu nejsou nejdůležitější metrikou
Možná si myslíte, že dotaz za sekundu je svatý grál výkonu, protože představuje, kolik dotazů může databáze provést během jedné sekundy. Pravdou je, že to není nejdůležitější metrika, zvláště pokud mluvíme o průměrném výstupu z benchmarku. QPS představuje propustnost, ale ignoruje latenci. Můžete se pokusit odeslat velké množství dotazů, ale nakonec budete čekat, až vrátí výsledky. To není to, co uživatelé od aplikace očekávají. Uživatelé očekávají stabilní výkon. Nemusí to být bleskurychlé, ale když dokončení nějaké akce trvá sekundu, máme tendenci očekávat, že provedení této akce zabere vždy tuto 1 sekundu. Pokud to z nějakého důvodu začne trvat déle, lidé mají tendenci být nervózní. To je hlavní důvod, proč máme tendenci preferovat latenci, zejména její P99 (99. percentil) jako spolehlivější metriku. Latence nám říká, jak dlouho musela aplikace čekat na výsledek z databáze. P99 nám říká latenci, že 99 % dotazů má nižší než. Řekněme, že máme P99 100 ms, to znamená, že 99 % dotazů vrací výsledky ne pomaleji než 100 ms. Pokud vidíme nízkou latenci P99, znamená to, že téměř všechny dotazy se vracejí rychle a fungují stabilně a předvídatelně. To je něco, co naši uživatelé chtějí vidět.
-
Před vyvozením závěrů pochopte, co se děje
Poslední bod, který máme v tomto krátkém blogu, ale řekli bychom, že je nejdůležitější. Během benchmarků uvidíte různé liché a neočekávané výsledky a chování. Ještě horší je, že můžete vidět docela standardní, opakující se, ale stále chybné výsledky. Většinu z nich lze sledovat podle chování databáze nebo hardwaru. To je opravdu zásadní – než výsledek vezmete za samozřejmost, měli byste být schopni vysvětlit chování a popsat, co se stalo. Víme, že to není snadné a víme, že to opravdu vyžaduje znalosti specifické pro databázi, zejména znalosti související s databázovými vnitřnostmi. Víme, že v reálném světě se s tím lidé obvykle neobtěžují, chtějí jen získat nějaké výsledky. Jde o to, že zejména v případech, kdy se pokoušíte zlepšit výkon pomocí konfigurace nebo hardwarových vylepšení, pochopení toho, co se stalo pod kapotou, vám umožní vybrat správný způsob, jakým by vaše ladění mělo pokračovat. To také umožňuje zjistit, zda benchmark, který byl proveden, může mít nějaký smysl. Testujeme skutečně správný prvek? Příkladem může být test prováděný přes síť (protože byste nechtěli používat lokální CPU jádra databázového uzlu pro nástroj benchmark). Je docela pravděpodobné, že samotná síť a zatížení procesoru softirq budou limitujícím faktorem mnohem dříve, než byste narazili na „očekávaná“ úzká hrdla, jako je saturace procesoru. Pokud si nejste vědomi svého prostředí a jeho chování, budete měřit výkon sítě pro přenos velkých objemů dat, nikoli výkon CPU.
Jak vidíte, benchmarking není nejjednodušší věc, musíte mít určitou úroveň povědomí o tom, co se děje, měli byste mít správný plán toho, co budete dělat a co chceš testovat? V další části tohoto blogu si projdeme některé z reálných testovacích případů. Co se může pokazit, s jakými problémy se setkáme a jak se s nimi vypořádat.