Failover je schopnost systému pokračovat v práci, i když dojde k nějakému selhání. To naznačuje, že funkce systému přebírají sekundární komponenty, pokud primární komponenty selžou nebo pokud je to potřeba. Pokud to tedy převedete do multicloudového prostředí PostgreSQL, znamená to, že když váš primární uzel selže (nebo jiný důvod, jak zmíníme v další části) u vašeho primárního poskytovatele cloudu, musíte být schopni propagovat pohotovostní uzel. v sekundárním, abyste udrželi systémy v chodu.
Všeobecně platí, že všichni poskytovatelé cloudu vám poskytují možnost převzetí služeb při selhání u stejného poskytovatele cloudu, ale může se stát, že budete potřebovat převzetí služeb při selhání k jinému poskytovateli cloudu. Samozřejmě to můžete udělat ručně, ale můžete také použít některé z funkcí ClusterControl, jako je automatické přepnutí při selhání nebo podpora slave akce, aby to bylo přátelské a snadné.
V tomto blogu uvidíte, proč byste měli potřebovat převzetí služeb při selhání, jak to provést ručně a jak pro tento úkol použít ClusterControl. Budeme předpokládat, že máte spuštěnou instalaci ClusterControl a máte již vytvořený databázový cluster u dvou různých poskytovatelů cloudu.
K čemu se používá převzetí služeb při selhání?
Existuje několik možných použití převzetí služeb při selhání.
Hlavní selhání
Pokud je váš primární uzel mimo provoz nebo i když má váš hlavní poskytovatel cloudu nějaké problémy, musíte převzít převzetí služeb při selhání, abyste zajistili dostupnost systému. V tomto případě může být nutné mít k dispozici automatický způsob, jak zkrátit prostoje.
Migrace
Pokud chcete migrovat své systémy od jednoho poskytovatele cloudu k jinému a minimalizovat tak prostoje, můžete použít převzetí služeb při selhání. Repliku můžete vytvořit u sekundárního poskytovatele cloudu, a jakmile bude synchronizována, musíte systém zastavit, propagovat repliku a převzetí služeb při selhání, než svůj systém nasměrujete na nový primární uzel v sekundárním poskytovateli cloudu.
Údržba
Pokud potřebujete provést nějakou úlohu údržby na primárním uzlu PostgreSQL, můžete povýšit svou repliku, provést úlohu a přestavět svůj starý primární uzel jako pohotovostní uzel.
Potom můžete povýšit staré primární a zopakovat proces přestavby na pohotovostním uzlu a vrátit se do původního stavu.
Tímto způsobem můžete pracovat na svém serveru, aniž byste riskovali, že budete offline nebo ztratíte informace při provádění jakékoli úlohy údržby.
Upgrady
Je možné upgradovat verzi PostgreSQL (od PostgreSQL 10) nebo dokonce upgradovat operační systém pomocí logické replikace s nulovými prostoji, jak to lze provést s jinými motory.
Postup by byl stejný jako při migraci na nového poskytovatele cloudu, pouze by vaše replika byla v novější verzi PostgreSQL nebo OS a musíte použít logickou replikaci, protože nemůžete používat streamování replikace mezi různými verzemi.
Failover není jen o databázi, ale také o aplikaci. Jak poznají, ke které databázi se mají připojit? Pravděpodobně nebudete muset upravovat svou aplikaci, protože to pouze prodlouží váš výpadek, takže můžete nakonfigurovat nástroj pro vyrovnávání zatížení, který když je váš primární uzel mimo provoz, automaticky ukáže na server, který byl povýšen.
Jedna instance nástroje Load Balancer není nejlepší možností, protože se může stát jediným bodem selhání. Proto můžete také implementovat převzetí služeb při selhání pro Load Balancer pomocí služby, jako je Keepalived. Tímto způsobem, pokud máte problém s primárním Load Balancerem, Keepalived migruje virtuální IP do vašeho sekundárního Load Balanceru a vše bude fungovat transparentně.
Další možností je použití DNS. Povýšením pohotovostního uzlu u sekundárního poskytovatele cloudu přímo upravíte IP adresu názvu hostitele, která ukazuje na primární uzel. Tímto způsobem se vyhnete nutnosti upravovat vaši aplikaci, a přestože to nelze provést automaticky, je to alternativa, pokud nechcete implementovat nástroj pro vyrovnávání zatížení.
Jak ručně převzít PostgreSQL při selhání
Před provedením ručního převzetí služeb při selhání musíte zkontrolovat stav replikace. Je možné, že když potřebujete převzetí služeb při selhání, pohotovostní uzel není aktuální kvůli selhání sítě, vysoké zátěži nebo jinému problému, takže se musíte ujistit, že váš pohotovostní uzel má všechny (nebo téměř všechny) informace. Pokud máte více než jeden pohotovostní uzel, měli byste také zkontrolovat, který z nich je nejpokročilejší, a zvolit jej pro převzetí služeb při selhání.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Když vyberete nový primární uzel, můžete nejprve spustit příkaz pg_lsclusters a získat informace o clusteru:
$ pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
12 main 5432 online,recovery postgres /var/lib/postgresql/12/main log/postgresql-%Y-%m-%d_%H%M%S.logPotom stačí spustit příkaz pg_ctlcluster s akcí povýšení:
$ pg_ctlcluster 12 main promoteMísto předchozího příkazu můžete příkaz pg_ctl spustit tímto způsobem:
$ /usr/lib/postgresql/12/bin/pg_ctl promote -D /var/lib/postgresql/12/main/
waiting for server to promote.... done
server promotedPotom bude váš pohotovostní uzel povýšen na primární a můžete jej ověřit spuštěním následujícího dotazu v novém primárním uzlu:
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Pokud je výsledek „f“, je to váš nový primární uzel.
Nyní musíte změnit IP adresu primární databáze ve své aplikaci, Load Balancer, DNS nebo implementaci, kterou používáte, což, jak jsme zmínili, ruční změna prodlouží prostoje. Musíte se také ujistit, že vaše připojení mezi možnými poskytovateli funguje správně, aplikace může přistupovat k novému primárnímu uzlu, uživatel aplikace má oprávnění k přístupu od jiného poskytovatele cloudu a měli byste znovu vytvořit pohotovostní uzel(y) v vzdáleného nebo dokonce u místního poskytovatele cloudu pro replikaci z nového primárního, jinak nebudete mít v případě potřeby novou možnost převzetí služeb při selhání.
Jak překonat selhání PostgreSQL pomocí ClusterControl
ClusterControl má řadu funkcí souvisejících s replikací PostgreSQL a automatickým převzetím služeb při selhání. Budeme předpokládat, že máte nainstalovaný server ClusterControl a ten spravuje vaše prostředí Multi-Cloud PostgreSQL.
S ClusterControl můžete přidat tolik uzlů v pohotovostním režimu nebo uzlů Load Balancer, kolik potřebujete, bez jakéhokoli omezení IP sítě. To znamená, že není nutné, aby pohotovostní uzel byl ve stejné síti primárního uzlu nebo dokonce u stejného poskytovatele cloudu. Pokud jde o převzetí služeb při selhání, ClusterControl vám to umožňuje ručně nebo automaticky.
Ruční převzetí služeb při selhání
Chcete-li provést ruční převzetí služeb při selhání, přejděte do ClusterControl -> Vyberte Cluster -> Nodes a v Node Actions jednoho z vašich pohotovostních uzlů vyberte "Promote Slave".
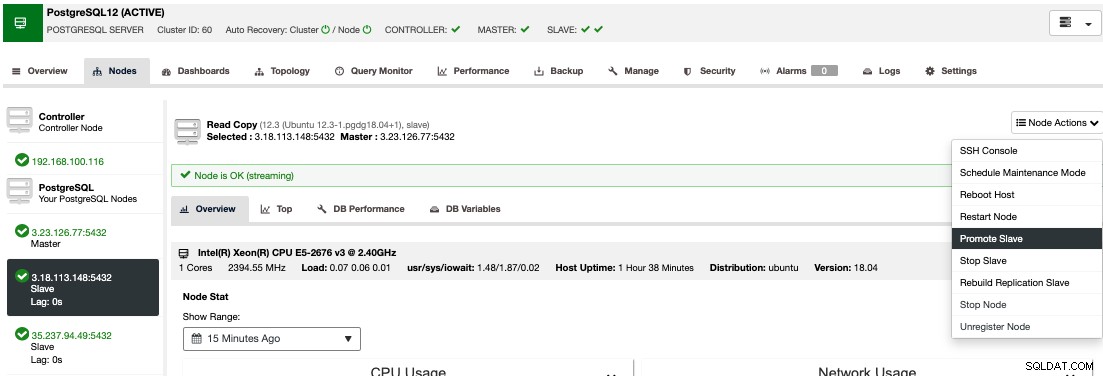
Tímto způsobem se váš pohotovostní uzel po několika sekundách stane primárním, a to, co bylo dříve vaším primárním, se přepne na pohotovostní. Pokud tedy vaše replika byla u jiného poskytovatele cloudu, váš nový primární uzel tam bude a bude fungovat.
Automatické převzetí služeb při selhání
V případě automatického převzetí služeb při selhání zjistí ClusterControl selhání v primárním uzlu a jako nový primární uzel povýší pohotovostní uzel s nejaktuálnějšími daty. Funguje také na zbývajících pohotovostních uzlech, aby se replikovaly z tohoto nového primárního.

Když je zapnuta možnost „Autorecovery“, ClusterControl provede automatické převzetí služeb při selhání jako také vás upozorní na problém. Tímto způsobem se vaše systémy mohou zotavit během několika sekund a bez vašeho zásahu.
ClusterControl vám nabízí možnost nakonfigurovat whitelist/blacklist, abyste definovali, jak chcete, aby byly vaše servery brány v úvahu (či nikoli) při rozhodování o primárním kandidátovi.
ClusterControl také provádí několik kontrol procesu převzetí služeb při selhání, například ve výchozím nastavení, pokud se vám podaří obnovit starý primární uzel se selháním, nebude automaticky znovu zaveden do clusteru, ani jako primární, ani jako pohotovostní režim, budete to muset udělat ručně. Vyhnete se tak možnosti ztráty dat nebo nekonzistence v případě, že váš pohotovostní režim (který jste propagoval) byl v době selhání zpožděn. Možná budete chtít problém podrobně analyzovat, ale při jeho přidávání do clusteru byste možná přišli o diagnostické informace.
Vyvažovači zatížení
Jak jsme již zmínili dříve, Load Balancer je důležitým nástrojem, který je třeba zvážit při převzetí služeb při selhání, zejména pokud chcete v topologii databáze použít automatické převzetí služeb při selhání.
Aby bylo převzetí služeb při selhání transparentní pro uživatele i aplikaci, potřebujete mezi tím komponentu, protože nestačí propagovat nový primární uzel. K tomu můžete použít HAProxy + Keepalived.
Chcete-li implementovat toto řešení pomocí ClusterControl, přejděte na Cluster Actions -> Add Load Balancer -> HAProxy na vašem clusteru PostgreSQL. V případě, že chcete implementovat převzetí služeb při selhání pro váš Load Balancer, musíte nakonfigurovat alespoň dvě instance HAProxy a poté můžete nakonfigurovat Keepalived (Akce clusteru -> Přidat Load Balancer -> Keepalived). Další informace o této implementaci naleznete v tomto příspěvku na blogu.
Potom budete mít následující topologii:

HAProxy je ve výchozím nastavení nakonfigurován se dvěma různými porty, jedním pro čtení a zápis a jeden pouze pro čtení.
V portu pro čtení a zápis máte primární uzel online a ostatní uzly offline. V portu pouze pro čtení máte primární i pohotovostní uzel online. Tímto způsobem můžete vyvážit čtecí provoz mezi uzly. Při zápisu se použije port pro čtení a zápis, který bude ukazovat na aktuální primární uzel.

Když HAProxy zjistí, že jeden z uzlů, ať už primární nebo pohotovostní, je není přístupný, automaticky jej označí jako offline. HAProxy na něj nebude posílat žádný provoz. Tato kontrola se provádí pomocí skriptů kontroly stavu, které jsou konfigurovány ClusterControl v době nasazení. Tyto kontrolují, zda jsou instance aktivní, zda procházejí obnovením nebo jsou pouze pro čtení.
Když ClusterControl povýší nový primární uzel, HAProxy označí starý uzel jako offline (pro oba porty) a uvede povýšený uzel online do portu pro čtení a zápis. Tímto způsobem budou vaše systémy nadále normálně fungovat.
Pokud aktivní HAProxy (která má přiřazenou virtuální IP adresu, ke které se vaše systémy připojují) selže, Keepalived tuto virtuální IP automaticky migruje na pasivní HAProxy. To znamená, že vaše systémy jsou poté schopny normálně fungovat.
Replikace mezi clustery v cloudu
Chcete-li mít prostředí Multi-Cloud, můžete nad clusterem PostgreSQL použít akci ClusterControl Add Slave, ale také funkci Cluster-to-Cluster Replication. V tuto chvíli má tato funkce omezení pro PostgreSQL, které vám umožňuje mít pouze jeden vzdálený uzel, ale pracujeme na tom, abychom toto omezení brzy odstranili v budoucí verzi.
Chcete-li jej nasadit, můžete se podívat na sekci „Replikace mezi clustery v cloudu“ v tomto příspěvku na blogu.

Když je na svém místě, můžete propagovat vzdálený cluster, který vygeneruje nezávislý cluster PostgreSQL s primárním uzlem běžícím na sekundárním poskytovateli cloudu.

Takže v případě, že to budete potřebovat, budete mít spuštěn stejný cluster u nového poskytovatele cloudu během několika sekund.
Závěr
Automatický proces převzetí služeb při selhání je povinný, pokud chcete mít co nejméně prostojů, a také použití různých technologií jako HAProxy a Keepalived toto převzetí služeb při selhání zlepší.
Funkce ClusterControl, které jsme zmínili výše, vám umožní rychle přejít při selhání mezi různými poskytovateli cloudu a spravovat nastavení snadným a přátelským způsobem.
Nejdůležitější věcí, kterou je třeba vzít v úvahu před provedením procesu převzetí služeb při selhání mezi různými poskytovateli cloudu, je konektivita. Musíte se ujistit, že vaše aplikace nebo vaše databázová připojení budou fungovat jako obvykle pomocí hlavního, ale i sekundárního poskytovatele cloudu v případě selhání a z bezpečnostních důvodů musíte omezit provoz pouze ze známých zdrojů, tedy pouze mezi cloudem poskytovatelů a nepovolit to z žádného externího zdroje.