Použití prostředí s více cloudy nebo více datovými centry je užitečné pro geograficky distribuované topologie nebo dokonce pro plán obnovy po havárii a ve skutečnosti je v dnešní době stále populárnější, proto koncept rozděleného mozku je také stále důležitější, protože riziko jeho zvýšení v tomto druhu scénáře. Musíte zabránit rozdělení mozku, abyste se vyhnuli potenciální ztrátě dat nebo nekonzistenci dat, což by mohlo být pro firmu velký problém.
V tomto blogu uvidíme, co je rozdělený mozek a jak vám ClusterControl může pomoci vyhnout se tomuto důležitému problému.
Co je Split-Brain?
Ve světě PostgreSQL dochází k rozdělení mozku, když je současně k dispozici více než jeden primární uzel (bez jakéhokoli nástroje třetí strany pro prostředí s více mastery), který umožňuje aplikaci zapisovat v obou uzlech. V tomto případě budete mít různé informace o každém uzlu, což generuje nekonzistenci dat v clusteru. Oprava tohoto problému může být obtížná, protože musíte sloučit data, což někdy není možné.
PostgreSQL Split-Brain v multi-cloudové topologii
Předpokládejme, že máte následující multi-cloudovou topologii pro PostgreSQL (což je v dnešní době docela běžná topologie):
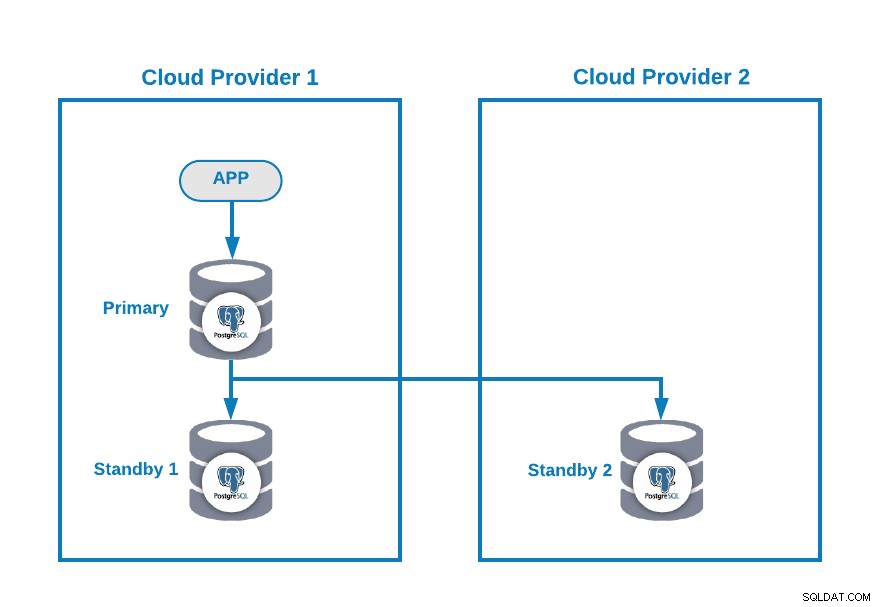
Toto prostředí můžete samozřejmě vylepšit například přidáním Aplikační server v Cloud Provider 2, ale v tomto případě použijme tuto základní konfiguraci.
Pokud je váš primární uzel mimo provoz, jeden z pohotovostních uzlů by měl být povýšen jako nový primární a měli byste změnit IP adresu ve své aplikaci, abyste mohli používat tento nový primární uzel.
Existují různé způsoby, jak to provést automaticky. Můžete například použít virtuální IP adresu přiřazenou vašemu primárnímu uzlu a monitorovat jej. Pokud selže, propagujte jeden z pohotovostních uzlů a migrujte virtuální IP adresu na tento nový primární uzel, takže nemusíte ve své aplikaci nic měnit, a to lze provést pomocí vlastního skriptu nebo nástroje.
V tuto chvíli nemáte žádný problém, ale... pokud se váš starý primární uzel vrátí, musíte se ujistit, že nebudete mít dva primární uzly ve stejném clusteru současně .
Nejběžnější metody, jak se této situaci vyhnout, jsou:
- STONITH:Shoot the Other Node In The Head.
- SMITH:Shoot Myself In The Head.
PostgreSQL neposkytuje žádný způsob, jak tento proces automatizovat. Musíte to udělat sami.
Jak se vyhnout Split-Brain v PostgreSQL pomocí ClusterControl
Nyní se podívejme, jak vám ClusterControl může pomoci s tímto úkolem.
Zaprvé jej můžete použít k nasazení nebo importu prostředí PostgreSQL Multi-Cloud jednoduchým způsobem, jak můžete vidět v tomto příspěvku na blogu.
Potom můžete svou topologii vylepšit přidáním nástroje pro vyrovnávání zatížení (HAProxy), což můžete také provést pomocí ClusterControl podle tohoto blogu. Takže budete mít něco takového:
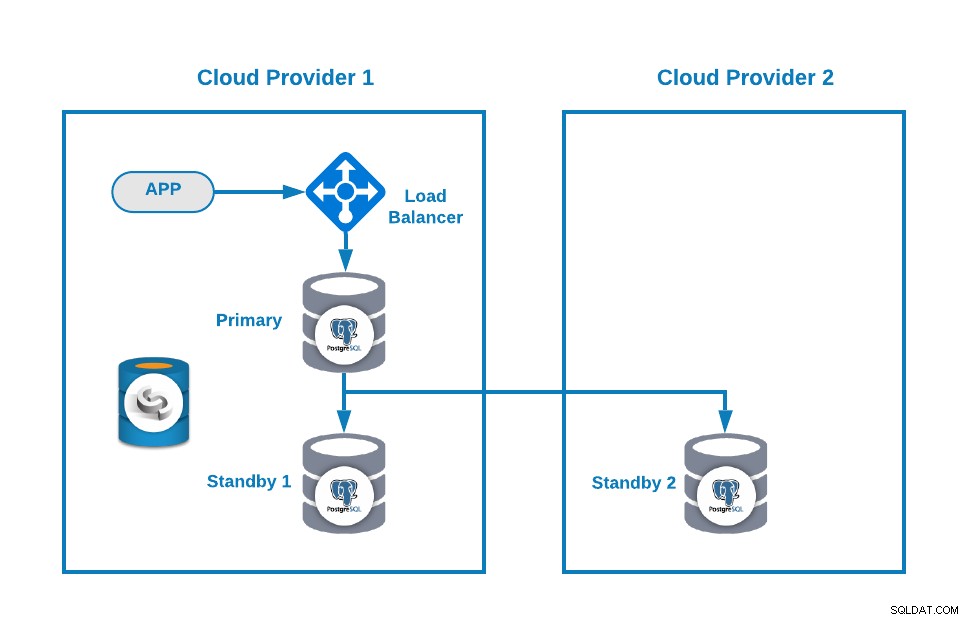
ClusterControl má funkci automatického přepnutí při selhání, která detekuje selhání hlavního serveru a podporuje pohotovostní režim uzel s nejaktuálnějšími daty jako nový primární. Také selže u zbývajících rezervních uzlů, které se replikují z nového primárního uzlu.
HAProxy je konfigurován ClusterControl se dvěma různými porty ve výchozím nastavení, jedním pro čtení-zápis a jedním pouze pro čtení. V portu pro čtení a zápis máte primární uzel jako online a ostatní uzly jako offline a na portu pouze pro čtení máte primární i pohotovostní uzel online. Tímto způsobem můžete vyvážit čtecí provoz mezi vašimi uzly, ale máte jistotu, že v době psaní bude použit port pro čtení a zápis a zápis v primárním uzlu, kterým je server, který je online.
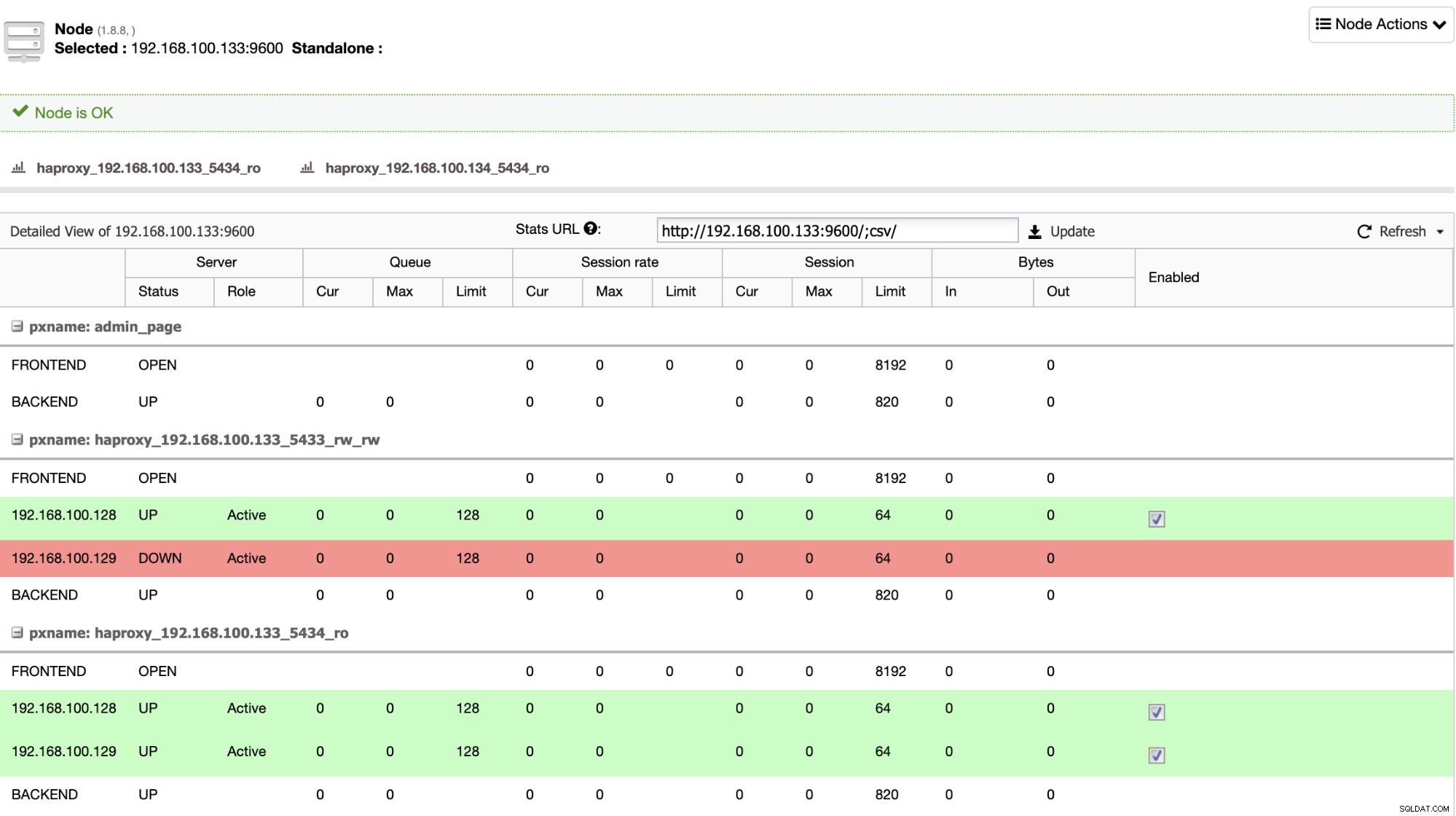
Když HAProxy zjistí, že jeden z vašich uzlů, ať už primární nebo pohotovostní, je není přístupný, automaticky jej označí jako offline a nebere jej v úvahu při odesílání provozu na něj. Tato kontrola se provádí pomocí skriptů kontroly stavu, které jsou konfigurovány ClusterControl v době nasazení. Kontrolují, zda jsou instance aktivní, zda procházejí obnovou nebo zda jsou pouze pro čtení.
Pokud se váš starý primární uzel vrátí, ClusterControl se také vyhne jeho spuštění, aby se zabránilo potenciálnímu rozdělení mozku v případě, že máte přímé připojení, které nepoužívá Load Balancer, ale můžete jej přidat do clusteru jako pohotovostního uzlu automatickým nebo ručním způsobem pomocí uživatelského rozhraní ClusterControl nebo CLI, pak jej můžete povýšit tak, aby měl stejnou topologii, jakou jste měli spuštěnou před problémem.
Závěr
Když je zapnuta možnost „Autorecovery“, ClusterControl provede toto automatické převzetí služeb při selhání a také vás upozorní na problém. Tímto způsobem se vaše systémy mohou zotavit během několika sekund bez vašeho zásahu a vyhnete se rozdělení mozku v prostředí PostgreSQL Multi-Cloud.
Své prostředí High Availability můžete také vylepšit přidáním dalších uzlů ClusterControl pomocí funkce CMON HA popsané v tomto blogu.