
Je to úterý v měsíci – víte, to, kdy se koná bloková párty bloggerů známá jako T-SQL Tuesday. Tento měsíc ho pořádá Russ Thomas (@SQLJudo) a jeho tématem je „Volání všech tunerů a převodových hlav“. Budu se zde zabývat problémem souvisejícím s výkonem, i když se omlouvám, že to nemusí být zcela v souladu s pokyny, které Russ stanovil ve své pozvánce (nebudu používat nápovědu, příznaky trasování ani průvodce plánem) .
Minulý týden jsem na SQLBits předvedl prezentaci o spouštěčích a náhodou se jí zúčastnil můj dobrý přítel a kolega MVP Erland Sommarskog. V jednu chvíli jsem navrhl, že před vytvořením nového spouštěče v tabulce byste měli zkontrolovat, zda již nějaké spouštěče existují, a zvážit zkombinování logiky místo přidání dalšího spouštěče. Moje důvody byly primárně pro udržovatelnost kódu, ale také pro výkon. Erland se zeptal, jestli jsem někdy zkoušel, jestli existuje nějaká dodatečná režie při spouštění několika spouště pro stejnou akci, a musel jsem přiznat, že ne, neudělal jsem nic rozsáhlého. Takže to teď udělám.
V AdventureWorks2014 jsem vytvořil jednoduchou sadu tabulek, které v podstatě představují sys.all_objects (~2 700 řádků) a sys.all_columns (~9 500 řádků). Chtěl jsem změřit vliv různých přístupů k aktualizaci obou tabulek na pracovní zátěž – v podstatě máte uživatele, kteří aktualizují tabulku sloupců, a pomocí spouštěče aktualizujete jiný sloupec ve stejné tabulce a několik sloupců v tabulce objektů.
- T1:Základní úroveň :Předpokládejme, že můžete ovládat veškerý přístup k datům prostřednictvím uložené procedury; v tomto případě lze aktualizace pro obě tabulky provádět přímo, bez potřeby spouštěčů. (V reálném světě to není praktické, protože přímý přístup k tabulkám nelze spolehlivě zakázat.)
- T2:Jediný spouštěč proti jiné tabulce :Předpokládejme, že můžete řídit příkaz aktualizace vůči ovlivněné tabulce a přidat další sloupce, ale aktualizace sekundární tabulky je třeba implementovat pomocí spouštěče. Všechny tři sloupce aktualizujeme jedním příkazem.
- T3:Jediný spouštěč proti oběma tabulkám :V tomto případě máme spouštěč se dvěma příkazy, jedním, který aktualizuje druhý sloupec v dotčené tabulce, a jedním, který aktualizuje všechny tři sloupce v sekundární tabulce.
- T4:Jediný spouštěč proti oběma tabulkám :Stejně jako T3, ale tentokrát máme spouštěč se čtyřmi příkazy, z nichž jeden aktualizuje druhý sloupec v dotčené tabulce a příkaz pro každý sloupec aktualizovaný v sekundární tabulce. To může být způsob, jakým se to řeší, pokud jsou požadavky přidávány v průběhu času a samostatný příkaz je považován za bezpečnější z hlediska regresního testování.
- T5:Dvě spouštěče :Jeden spouštěč aktualizuje pouze postiženou tabulku; druhý používá jeden příkaz k aktualizaci tří sloupců v sekundární tabulce. Může to být způsob, jakým se to dělá, pokud si ostatních spouštěčů nevšimnete nebo pokud je zakázáno je upravovat.
- T6:Čtyři spouštěče :Jeden spouštěč aktualizuje pouze postiženou tabulku; ostatní tři aktualizují každý sloupec v sekundární tabulce. Opět to může být způsob, jakým se to dělá, pokud nevíte, že existují další spouštěče, nebo pokud se bojíte dotknout ostatních spouštěčů kvůli obavám z regrese.
Zde jsou zdrojová data, kterými se zabýváme:
-- sys.all_objects: SELECT * INTO dbo.src FROM sys.all_objects; CREATE UNIQUE CLUSTERED INDEX x ON dbo.src([object_id]); GO -- sys.all_columns: SELECT * INTO dbo.tr1 FROM sys.all_columns; CREATE UNIQUE CLUSTERED INDEX x ON dbo.tr1([object_id], column_id); -- repeat 5 times: tr2, tr3, tr4, tr5, tr6
Nyní pro každý ze 6 testů spustíme aktualizace 1000krát a změříme dobu
T1:Základní úroveň
Toto je scénář, kdy máme to štěstí, že se vyhneme spouštěcím mechanismům (opět ne příliš realistické). V tomto případě budeme měřit čtení a trvání této dávky. Vložil jsem /*real*/ do textu dotazu, abych mohl snadno stáhnout statistiky pouze pro tyto příkazy, a ne pro jakékoli příkazy ze spouštěčů, protože metriky se nakonec shrnou do příkazů, které vyvolávají spouštěče. Všimněte si také, že skutečné aktualizace, které provádím, ve skutečnosti nedávají žádný smysl, takže ignorujte, že nastavuji řazení na název serveru/instance a principal_id objektu na aktuální relace session_id .
UPDATE /*real*/ dbo.tr1 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; UPDATE /*real*/ s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID FROM dbo.src AS s INNER JOIN dbo.tr1 AS t ON s.[object_id] = t.[object_id] WHERE t.name LIKE '%s%'; GO 1000
T2:Jediný spouštěč
K tomu potřebujeme následující jednoduchý trigger, který aktualizuje pouze dbo.src :
CREATE TRIGGER dbo.tr_tr2
ON dbo.tr2
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = SUSER_ID()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Pak naše dávka potřebuje pouze aktualizovat dva sloupce v primární tabulce:
UPDATE /*real*/ dbo.tr2 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; GO 1000
T3:Jediný trigger proti oběma tabulkám
Pro tento test náš spouštěč vypadá takto:
CREATE TRIGGER dbo.tr_tr3
ON dbo.tr3
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr3 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO A nyní dávka, kterou testujeme, musí pouze aktualizovat původní sloupec v primární tabulce; druhý je ovládán spouštěčem:
UPDATE /*real*/ dbo.tr3 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T4:Jediný trigger proti oběma tabulkám
Je to jako T3, ale spouštěč má nyní čtyři příkazy:
CREATE TRIGGER dbo.tr_tr4
ON dbo.tr4
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr4 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Testovací dávka je nezměněna:
UPDATE /*real*/ dbo.tr4 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T5:Dva spouštěče
Zde máme jeden spouštěč pro aktualizaci primární tabulky a jeden spouštěč pro aktualizaci sekundární tabulky:
CREATE TRIGGER dbo.tr_tr5_1
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr5 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr5_2
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Testovací dávka je opět velmi základní:
UPDATE /*real*/ dbo.tr5 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T6:Čtyři spouštěče
Tentokrát máme spouštěč pro každý sloupec, který je ovlivněn; jeden v primární tabulce a tři v sekundárních tabulkách.
CREATE TRIGGER dbo.tr_tr6_1
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr6 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_2
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_3
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_4
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO A testovací dávka:
UPDATE /*real*/ dbo.tr6 SET name += N'' WHERE name LIKE '%s%'; GO 1000
Měření dopadu pracovní zátěže
Nakonec jsem napsal jednoduchý dotaz proti sys.dm_exec_query_stats k měření čtení a trvání každého testu:
SELECT [cmd] = SUBSTRING(t.text, CHARINDEX(N'U', t.text), 23), avg_elapsed_time = total_elapsed_time / execution_count * 1.0, total_logical_reads FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.text LIKE N'%UPDATE /*real*/%' ORDER BY cmd;
Výsledky
Testy jsem provedl 10krát, shromáždil výsledky a zprůměroval vše. Zde je návod, jak se to porouchalo:
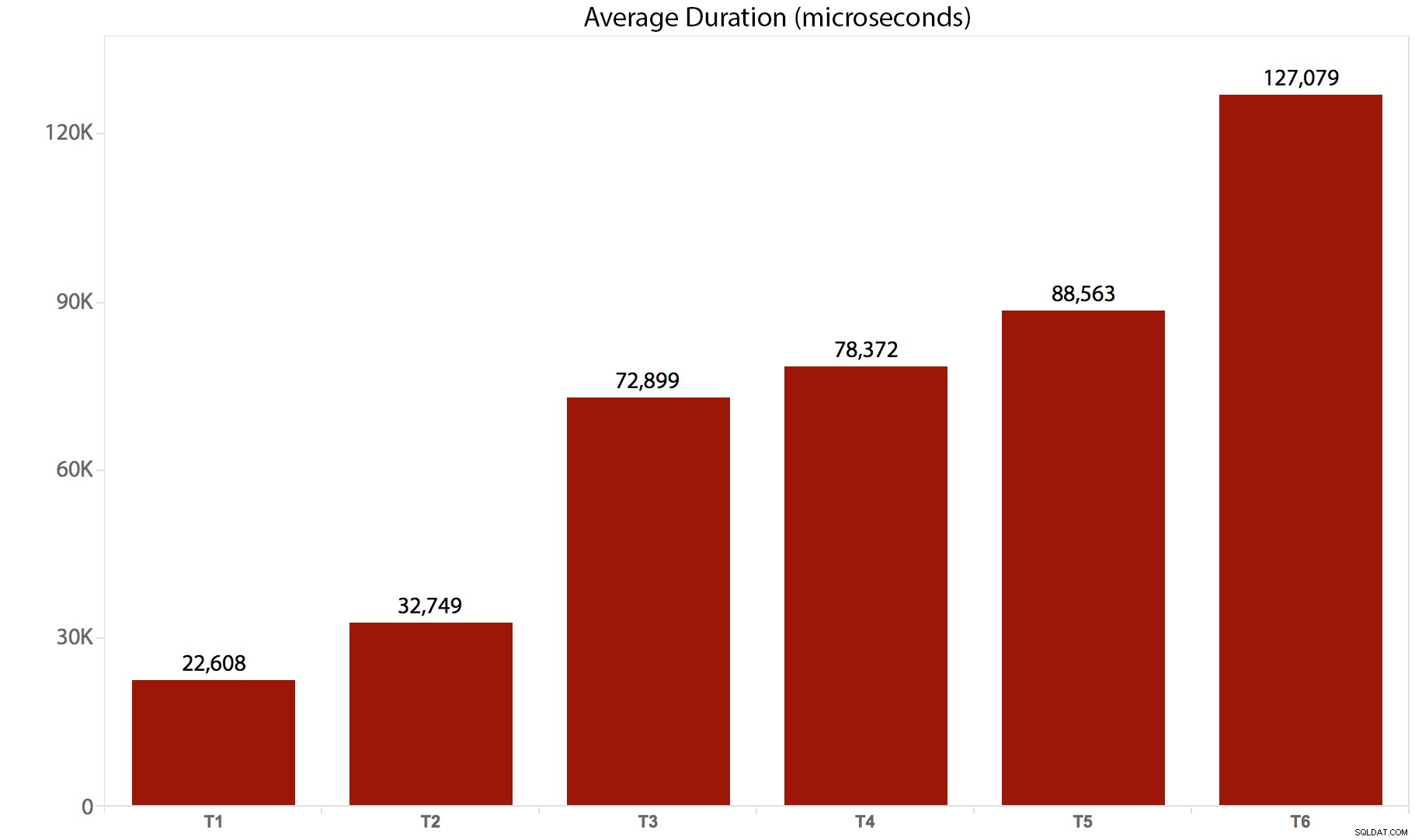
| Test/dávka | Průměrná doba trvání (mikrosekundy) | Celkový počet přečtení (8 tisíc stránek) |
|---|---|---|
| T1 :UPDATE /*real*/ dbo.tr1 … | 22 608 | 205 134 |
| T2 :UPDATE /*real*/ dbo.tr2 … | 32 749 | 11 331 628 |
| T3 :UPDATE /*real*/ dbo.tr3 … | 72 899 | 22 838 308 |
| T4 :UPDATE /*real*/ dbo.tr4 … | 78 372 | 44 463 275 |
| T5 :UPDATE /*real*/ dbo.tr5 … | 88 563 | 41 514 778 |
| T6 :UPDATE /*real*/ dbo.tr6 … | 127 079 | 100 330 753 |
A zde je grafické znázornění doby trvání:
Závěr
Je jasné, že v tomto případě existuje určitá podstatná režie pro každý spouštěč, který je vyvolán – všechny tyto dávky nakonec ovlivnily stejný počet řádků, ale v některých případech se stejné řádky dotkly vícekrát. Pravděpodobně provedu další následné testování, abych změřil rozdíl, kdy se stejného řádku nikdy nedotknete více než jednou – možná složitější schéma, kde se pokaždé musí dotknout 5 nebo 10 dalších tabulek a tyto různé příkazy by mohly být v jedné spoušti nebo ve více. Domnívám se, že rozdíly v režii budou způsobeny spíše věcmi, jako je souběžnost a počet ovlivněných řádků, než režie samotného spouštěče – ale uvidíme.
Chcete si demo vyzkoušet sami? Stáhněte si skript zde.