V odklonu od své série „ladění výkonu po kolena“ bych rád probral, jak se vám za určitých okolností může vkrádat fragmentace indexu.
Co je fragmentace indexu?
Většina lidí si pod pojmem „fragmentace indexu“ představí problém, kdy jsou listové stránky indexu mimo pořadí – listová stránka indexu s další klíčovou hodnotou není ta, která v datovém souboru fyzicky sousedí s právě zkoumanou listovou stránkou indexu. . Tomu se říká logická fragmentace (a někteří lidé tomu říkají externí fragmentace – matoucí termín, který nemám rád).
K logické fragmentaci dochází, když je listová stránka indexu plná a je na ní potřeba místo, buď pro vložení, nebo pro prodloužení existujícího záznamu (z aktualizace sloupce s proměnnou délkou). V takovém případě Storage Engine vytvoří novou prázdnou stránku a přesune 50 % řádků (obvykle, ale ne vždy) z celé stránky na novou stránku. Tato operace vytvoří prostor na obou stránkách, což umožní vložení nebo aktualizaci pokračovat, a nazývá se rozdělení stránky. Existují zajímavé patologické případy zahrnující opakované dělení stránky z jedné operace a dělení stránek, které kaskádovitě stoupá na úrovně indexu, ale ty jsou nad rámec tohoto příspěvku.
Když dojde k rozdělení stránky, obvykle to způsobí logickou fragmentaci, protože je vysoce nepravděpodobné, že by nová stránka, která je přidělena, fyzicky sousedila s tou, která se rozděluje. Když má index hodně logické fragmentace, skenování indexu se zpomalí, protože fyzické čtení potřebných stránek nelze provádět tak efektivně (pomocí vícestránkového čtení „napřed), když listové stránky nejsou uloženy v datovém souboru v pořadí. .
To je základní definice fragmentace indexu, ale existuje i druhý druh fragmentace indexu, který většina lidí nezvažuje:nízká hustota stránek (někdy to nazývám opět interní fragmentace, což je matoucí termín, který nemám rád).
Hustota stránky je měřítkem toho, kolik dat je uloženo na listové stránce indexu. Když dojde k rozdělení stránky s obvyklým případem 50/50, každá listová stránka (rozdělující a nová) bude mít hustotu pouze 50 %. Čím nižší je hustota stránek, tím více prázdného místa je v indexu, a tím více místa na disku a paměti fondu vyrovnávací paměti můžete považovat za plýtvání. O tomto problému jsem napsal blog před několika lety a můžete si o něm přečíst zde.
Nyní, když jsem uvedl základní definici dvou druhů fragmentace indexu, budu je souhrnně nazývat jednoduše „fragmentace“.
Po zbytek tohoto příspěvku bych rád probral tři případy, kdy se klastrované indexy mohou fragmentovat, i když se vyhýbáte operacím, které by fragmentaci evidentně způsobily (tj. náhodné vkládání a aktualizace záznamů jsou delší).
Fragmentace z mazání
"Jak může odstranění z listové stránky seskupeného indexu způsobit rozdělení stránky?" možná se ptáte. Za normálních okolností nebude (a pár minut jsem o tom seděl a přemýšlel, abych se ujistil, že nejde o nějaký podivný patologický případ! Ale viz část níže…) Smazání však může způsobit postupné snižování hustoty stránek.
Představte si případ, kdy má seskupený index hodnotu klíče identity bigint, takže vložky půjdou vždy na pravou stranu indexu a nikdy, nikdy nebudou vloženy do dřívější části indexu (pokud někdo nemůže znovu nastavit hodnotu identity – potenciálně velmi problematické!). Nyní si představte, že pracovní zátěž odstraní z tabulky záznamy, které již nejsou vyžadovány, a poté úloha vyčištění duchů na pozadí znovu získá místo na stránce a uvolní se.
Při absenci jakýchkoliv náhodných vložení (v našem scénáři nemožné, pokud někdo znovu nezasévá identitu nebo neurčí hodnotu klíče, která se má použít po povolení SET IDENTITY INSERT pro tabulku), žádné nové záznamy nikdy nevyužijí prostor, který byl uvolněn z odstraněných záznamů. To znamená, že průměrná hustota stránek dřívějších částí seskupeného indexu se bude neustále snižovat, což povede ke zvýšení množství plýtvaného místa na disku a paměti vyrovnávací paměti, jak jsem popsal dříve.
Odstranění může způsobit fragmentaci, pokud hustotu stránky považujete za součást „fragmentace“.
Fragmentace z izolace snímků
SQL Server 2005 zavedl dvě nové úrovně izolace:izolaci snímku a izolaci snímku s potvrzením čtení. Tyto dva mají mírně odlišnou sémantiku, ale v zásadě umožňují dotazům zobrazit databázi v určitém okamžiku a pro výběry bez kolize. To je obrovské zjednodušení, ale pro mé účely to stačí.
K usnadnění těchto úrovní izolace zavedl vývojový tým společnosti Microsoft, který jsem vedl, mechanismus zvaný verzování. Správa verzí funguje tak, že kdykoli se záznam změní, verze záznamu před změnou se zkopíruje do úložiště verzí v databázi tempdb a změněný záznam získá 14bajtovou značku pro správu verzí, která se přidá na její konec. Značka obsahuje ukazatel na předchozí verzi záznamu a časové razítko, které lze použít k určení správné verze záznamu pro konkrétní dotaz ke čtení. Opět velmi zjednodušeno, ale zajímá nás pouze přidání 14 bajtů.
Kdykoli se tedy záznam změní, když je v platnosti některá z těchto úrovní izolace, může se rozšířit o 14 bajtů, pokud pro záznam již neexistuje značka pro správu verzí. Co když na listové stránce indexu není dostatek místa pro dalších 14 bajtů? Správně, dojde k rozdělení stránky, což způsobí fragmentaci.
Možná si myslíte, že je to velký problém, protože záznam se stejně mění, takže pokud by se stejně měnila velikost, pravděpodobně by došlo k rozdělení stránky. Ne – tato logika platí pouze v případě, že změna záznamu měla zvětšit velikost sloupce s proměnnou délkou. Značka pro správu verzí bude přidána, i když bude aktualizován sloupec s pevnou délkou!
To je pravda – když je ve hře verzování, aktualizace sloupců s pevnou délkou mohou způsobit rozšíření záznamu, což může způsobit rozdělení stránky a fragmentaci. Ještě zajímavější je, že odstranění přidá také 14bajtovou značku, takže odstranění v seskupeném indexu může způsobit rozdělení stránky, když se používá verzování!
Pointa je, že povolení obou forem izolace snímků může vést k tomu, že náhle začne docházet k fragmentaci v seskupených indexech, kde dříve nebyla žádná možnost fragmentace.
Fragmentace z čitelných sekundárních souborů
Poslední případ, který chci probrat, je použití čitelných sekundárních souborů, což je součást funkce skupiny dostupnosti, která byla přidána do SQL Server 2012.
Když povolíte čitelný sekundární prvek, všechny dotazy, které provedete proti sekundární replice, se převedou na použití izolace snímků pod krytem. Tím se zabrání tomu, aby dotazy blokovaly neustálé přehrávání záznamů protokolu z primární repliky, protože kód pro obnovení získává zámky, jak to jde.
K tomu je třeba, aby na záznamech na sekundární replice byly 14bajtové značky pro správu verzí. Nastal problém, protože všechny repliky musí být identické, aby přehrání protokolu fungovalo. No, ne tak docela. Obsah značek pro správu verzí není relevantní, protože se používá pouze v instanci, která je vytvořila. Sekundární replika však nemůže přidávat značky pro správu verzí, čímž se záznamy prodlužují, protože by to změnilo fyzické rozvržení záznamů na stránce a přerušilo přehrávání protokolu. Pokud by tam už byly značky pro správu verzí, mohlo by to využít prostor, aniž by cokoli porušilo.
Takže přesně to se stane. Storage Engine zajišťuje, že všechny potřebné verzovací značky pro sekundární repliku již existují, a to jejich přidáním do primární repliky!
Jakmile je vytvořena čitelná sekundární replika databáze, jakákoli aktualizace záznamu v primární replice způsobí, že k záznamu bude přidán prázdný 14bajtový tag, takže 14bajtové jsou správně započítány do všech záznamů protokolu. . Značka se k ničemu nepoužívá (pokud není povolena izolace snímku na samotné primární replice), ale skutečnost, že je vytvořena, způsobí rozšíření záznamu, a pokud je stránka již plná, pak…
Ano, povolení čitelné sekundární kopie způsobí na primární replice stejný účinek, jako kdybyste na ní povolili izolaci snímků – fragmentaci.
Shrnutí
Nemyslete si, že protože se vyhýbáte používání GUID jako clusterových klíčů a vyhýbáte se aktualizaci sloupců s proměnnou délkou v tabulkách, budou vaše seskupené indexy imunní vůči fragmentaci. Jak jsem popsal výše, existují další faktory pracovní zátěže a prostředí, které mohou způsobit problémy s fragmentací ve vašich seskupených indexech, o kterých musíte vědět.
Nyní se netrhejte a nemyslete si, že byste neměli mazat záznamy, neměli byste používat izolaci snímků a neměli byste používat čitelné sekundární položky. Jen si musíte být vědomi toho, že všechny mohou způsobit fragmentaci a vědět, jak ji detekovat, odstranit a zmírnit.
SQL Sentry má skvělý nástroj, Fragmentation Manager, který můžete použít jako doplněk k Performance Advisor, který vám pomůže zjistit, kde jsou problémy s fragmentací, a pak je řešit. Možná budete překvapeni fragmentací, kterou při kontrole zjistíte! Jako rychlý příklad zde mohu vizuálně vidět – až na úrovni jednotlivých oddílů – jak velká fragmentace existuje, jak rychle k tomu došlo, jakékoli existující vzory a skutečný dopad, který to má na plýtvání pamětí v systému:
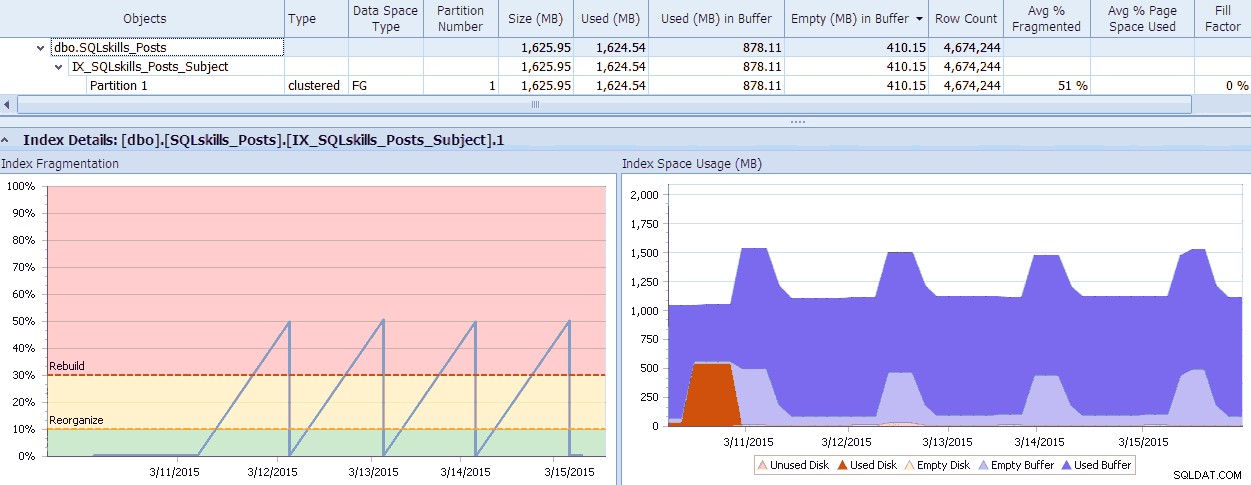 Data SQL Sentry Fragmentation Manager (kliknutím zvětšíte)
Data SQL Sentry Fragmentation Manager (kliknutím zvětšíte)
Ve svém příštím příspěvku proberu více o fragmentaci a o tom, jak ji zmírnit, aby byla méně problematická.