Ačkoli přicházejí s mnoha omezeními a některými důležitými implementačními upozorněními, indexované pohledy jsou stále velmi výkonnou funkcí SQL Server, pokud jsou správně použity za správných okolností. Jedním z běžných způsobů použití je poskytnout předem agregovaný pohled na podkladová data, což uživatelům dává možnost dotazovat se přímo na výsledky, aniž by jim vznikaly náklady na zpracování podkladových spojení, filtrů a agregací pokaždé, když je dotaz spuštěn.
Přestože nové funkce Enterprise Edition, jako je sloupcové úložiště a zpracování v dávkovém režimu, změnily výkonnostní charakteristiky mnoha velkých dotazů tohoto typu, stále neexistuje rychlejší způsob, jak získat výsledek, než se úplně vyhnout veškerému základnímu zpracování, bez ohledu na to, jak efektivní je toto zpracování. se mohl stát.
Než byly do produktu přidány indexované pohledy (a jejich omezenější příbuzní, počítané sloupce), databázoví profesionálové někdy napsali složitý kód s více spouštěči, aby prezentovali výsledky důležitého dotazu ve skutečné tabulce. Tento druh uspořádání je notoricky obtížné dosáhnout za všech okolností správně, zvláště tam, kde jsou časté souběžné změny podkladových dat.
Funkce indexovaných pohledů toto vše značně usnadňuje, pokud je to rozumně a správně aplikováno. Databázový stroj se postará o vše potřebné k zajištění toho, aby data načtená z indexovaného zobrazení vždy odpovídala podkladovým datům dotazu a tabulky.
Přírůstková údržba
SQL Server udržuje data indexovaného zobrazení synchronizovaná s podkladovým dotazem tím, že automaticky aktualizuje indexy zobrazení přiměřeně vždy, když se data v základních tabulkách změní. Náklady na tuto údržbu nese proces měnící základní data. Další operace potřebné k údržbě indexů zobrazení jsou tiše přidány do prováděcího plánu pro původní operaci vložení, aktualizace, odstranění nebo sloučení. Na pozadí se SQL Server také stará o jemnější problémy týkající se izolace transakcí, například zajištění správného zpracování transakcí spuštěných pod snímkem nebo izolace potvrzeného snímku čtení.
Vytvoření dalších operací plánu provádění potřebných ke správnému udržování indexů zobrazení není triviální záležitostí, jak ví každý, kdo se pokusil o implementaci „souhrnné tabulky udržované spouštěcím kódem“. Složitost úkolu je jedním z důvodů, proč indexované pohledy mají tolik omezení. Omezení podporované plochy na vnitřní spojení, projekce, výběry (filtry) a agregáty SUM a COUNT_BIG značně snižuje složitost implementace.
Indexovaná zobrazení jsou udržována přírůstkově . To znamená, že procesor dotazů určuje čistý účinek změn základní tabulky na pohled a aplikuje pouze změny nezbytné k aktualizaci pohledu. V jednoduchých případech dokáže vypočítat potřebné delty pouze ze změn základní tabulky a dat aktuálně uložených v pohledu. Tam, kde definice pohledu obsahuje spojení, bude muset část prováděcího plánu pro údržbu indexovaného pohledu také přistupovat ke spojeným tabulkám, ale to lze obvykle provést efektivně, za předpokladu vhodných indexů základní tabulky.
Pro další zjednodušení implementace používá SQL Server vždy stejný základní tvar plánu (jako výchozí bod) k implementaci operací údržby indexovaného zobrazení. Normální funkce poskytované optimalizátorem dotazů se používají ke zjednodušení a optimalizaci standardního tvaru údržby podle potřeby. Nyní se obrátíme na příklad, který pomůže tyto koncepty spojit.
Příklad 1 – Vložení jednoho řádku
Předpokládejme, že máme následující jednoduchou tabulku a indexované zobrazení:
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
SumValue = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
T1.GroupID BETWEEN 1 AND 5
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); Po spuštění tohoto skriptu vypadají data ve vzorové tabulce takto:

A indexované zobrazení obsahuje:

Nejjednodušší příklad plánu údržby indexovaného zobrazení pro toto nastavení nastane, když do základní tabulky přidáme jeden řádek:
INSERT dbo.T1
(GroupID, Value)
VALUES
(3, 6); Prováděcí plán pro tuto vložku je uveden níže:
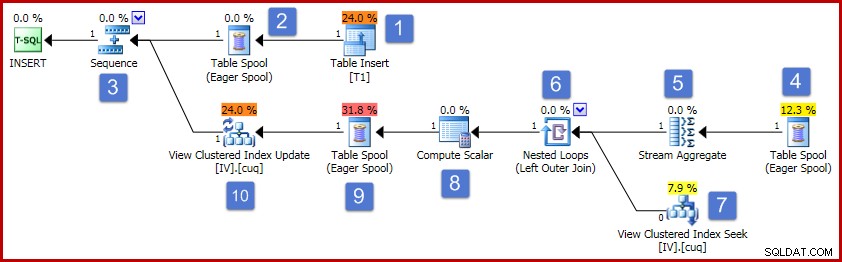
Podle čísel v diagramu postupuje činnost tohoto prováděcího plánu následovně:
- Operátor vložení tabulky přidá nový řádek do základní tabulky. Toto je jediný operátor plánu spojený s vložkou základní tabulky; všichni zbývající operátoři se zabývají údržbou indexovaného zobrazení.
- Služba Eager Table Spool ukládá vložená data řádků do dočasného úložiště.
- Operátor sekvence zajišťuje, že horní větev plánu bude dokončena před aktivací další větve v sekvenci. V tomto speciálním případě (vložení jednoho řádku) by bylo platné odstranit sekvenci (a cívky na pozicích 2 a 4) a přímo propojit vstup Stream Aggregate s výstupem Table Insert. Tato možná optimalizace není implementována, takže sekvence a cívky zůstávají.
- Tato fronta tabulek Eager je přidružena k zařazování na pozici 2 (má vlastnost ID primárního uzlu, která toto propojení explicitně poskytuje). Spool přehrává řádky (v tomto případě jeden řádek) ze stejného dočasného úložiště zapsaného primární cívkou. Jak bylo uvedeno výše, cívky a pozice 2 a 4 jsou zbytečné a fungují jednoduše proto, že existují v obecné šabloně pro údržbu indexovaného zobrazení.
- Stream Aggregate vypočítá součet dat sloupce Hodnota ve vložené sadě a spočítá počet řádků přítomných na skupinu klíčů zobrazení. Výstupem jsou přírůstková data potřebná k udržení synchronizace zobrazení se základními daty. Všimněte si, že Stream Aggregate nemá prvek Seskupit podle, protože optimalizátor dotazů ví, že se zpracovává pouze jedna hodnota. Optimalizátor však nepoužije podobnou logiku k nahrazení agregací projekcemi (součet jedné hodnoty je pouze samotnou hodnotou a počet bude vždy jedna pro vložení jednoho řádku). Výpočet agregací součtu a počtu pro jeden řádek dat není nákladná operace, takže této zmeškané optimalizace není třeba se příliš znepokojovat.
- Spojení spojuje každou vypočítanou přírůstkovou změnu s existujícím klíčem v indexovaném zobrazení. Spojení je vnější spojení, protože nově vložená data nemusí odpovídat žádným existujícím datům v pohledu.
- Tento operátor vyhledá v zobrazení řádek, který má být upraven.
- Compute Scalar má dvě důležité povinnosti. Nejprve určí, zda každá přírůstková změna ovlivní existující řádek v pohledu, nebo zda bude nutné vytvořit nový řádek. Provádí to kontrolou, zda vnější spojení vytvořilo z pohledové strany spojení nulu. Naše vzorová příloha je pro skupinu 3, která aktuálně v pohledu neexistuje, takže bude vytvořen nový řádek. Druhou funkcí Compute Scalar je výpočet nových hodnot pro sloupce zobrazení. Pokud má být do pohledu přidán nový řádek, je to jednoduše výsledek přírůstkového součtu z agregátu streamů. Pokud má být aktualizován existující řádek v pohledu, nová hodnota je stávající hodnota v řádku pohledu plus přírůstkový součet z Agregátu toku.
- Tato cívka Eager Table Spool je určena pro Halloweenskou ochranu. Je vyžadována pro správnost, když operace vložení ovlivňuje tabulku, na kterou se také odkazuje na straně dotazu pro přístup k datům. Technicky to není vyžadováno, pokud operace údržby jednoho řádku povede k aktualizaci existujícího řádku zobrazení, ale přesto zůstane v plánu.
- Konečný operátor v plánu je označen jako Operátor aktualizace, ale provede buď vložení nebo aktualizaci pro každý řádek, který obdrží, v závislosti na hodnotě sloupce „kód akce“ přidaného výpočetním skalárem v uzlu 8. Obecněji řečeno, tento aktualizační operátor je schopen vkládat, aktualizovat a mazat.
Je tam docela dost podrobností, abych to shrnula:
- Údaje agregovaných skupin se mění podle jedinečného seskupeného klíče zobrazení. Vypočítá čistý účinek změn základní tabulky na každý sloupec na klíč.
- Vnější spojení připojuje přírůstkové změny podle klíče k existujícím řádkům v pohledu.
- Výpočetní skalár vypočítá, zda má být do zobrazení přidán nový řádek, nebo zda má být aktualizován stávající řádek. Vypočítá konečné hodnoty sloupců pro operaci vložení nebo aktualizace zobrazení.
- Operátor aktualizace zobrazení vloží nový řádek nebo aktualizuje stávající podle pokynů kódu akce.
Příklad 2 – Víceřádkové vložení
Věřte tomu nebo ne, plán provádění vložení jednořádkové základní tabulky diskutovaný výše podléhal řadě zjednodušení. Přestože některé možné další optimalizace byly vynechány (jak bylo uvedeno), optimalizátoru dotazů se přesto podařilo odstranit některé operace z obecné šablony údržby indexovaného zobrazení a snížit složitost ostatních.
Několik z těchto optimalizací bylo povoleno, protože jsme vkládali pouze jeden řádek, ale jiné byly povoleny, protože optimalizátor viděl doslovné hodnoty přidávané do základní tabulky. Optimalizátor například viděl, že vložená hodnota skupiny by předala predikát v klauzuli WHERE pohledu.
Pokud nyní vložíme dva řádky s hodnotami "skrytými" v lokálních proměnných, dostaneme trochu složitější plán:
DECLARE
@Group1 integer = 4,
@Value1 integer = 7,
@Group2 integer = 5,
@Value2 integer = 8;
INSERT dbo.T1
(GroupID, Value)
VALUES
(@Group1, @Value1),
(@Group2, @Value2);
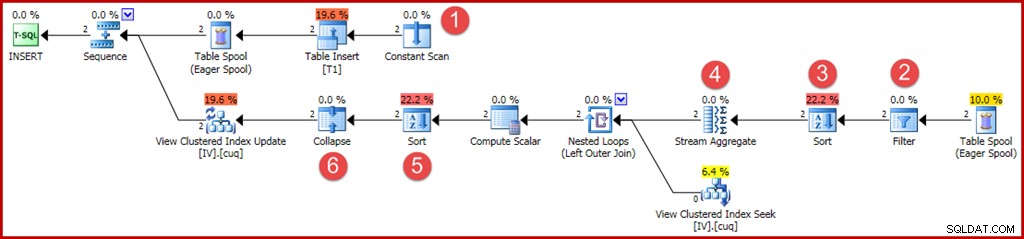
Nové nebo změněné operátory jsou označeny jako dříve:
- Konstantní skenování poskytuje hodnoty, které se mají vložit. Dříve umožňovala optimalizace pro jednořádkové vložky tento operátor vynechat.
- Nyní je vyžadován explicitní operátor filtru, který kontroluje, zda skupiny vložené do základní tabulky odpovídají klauzuli WHERE v zobrazení. Oba nové řádky testem projdou, ale optimalizátor nevidí hodnoty v proměnných, aby to věděl předem. Navíc by nebylo bezpečné uložit do mezipaměti plán, který tento filtr přeskočil, protože budoucí opětovné použití plánu by mohlo mít v proměnných jiné hodnoty.
- Nyní je vyžadováno řazení, aby se zajistilo, že řádky dorazí do agregátu streamů ve skupinovém pořadí. Řazení bylo dříve odstraněno, protože nemá smysl řadit jeden řádek.
- Stream Aggregate má nyní vlastnost „seskupit podle“, která odpovídá jedinečnému seskupenému klíči zobrazení.
- Toto řazení je vyžadováno pro zobrazení řádků v pořadí klíčů zobrazení a kódu akce, které je nutné pro správnou funkci operátoru Collapse. Sort je plně blokující operátor, takže již není potřeba Eager Table Spool pro Halloween Protection.
- Nový operátor Collapse kombinuje sousední vložení a odstranění na stejné hodnotě klíče do jediné operace aktualizace. Tento operátor není ve skutečnosti vyžadován v tomto případě proto, že nelze generovat žádné kódy akcí mazání (pouze vkládání a aktualizace). Zdá se, že jde o nedopatření, nebo možná o něco ponechaného z bezpečnostních důvodů. Automaticky generované části plánu aktualizačních dotazů mohou být extrémně složité, takže je těžké je s jistotou zjistit.
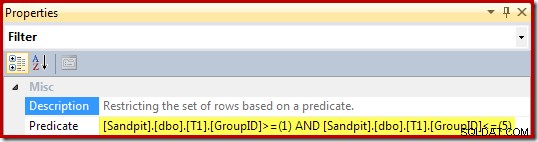
Vlastnosti filtru (odvozeného z klauzule WHERE pohledu) jsou:
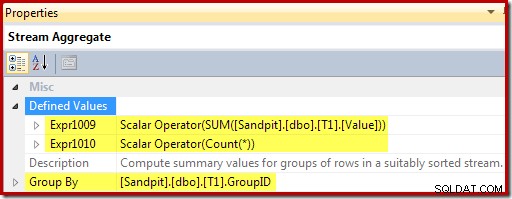
Stream Aggregate seskupuje podle klíče zobrazení a počítá součet a počet agregací na skupinu:
Compute Scalar identifikuje akci, která se má provést na řádku (v tomto případě vložit nebo aktualizovat), a vypočítá hodnotu, která se má vložit nebo aktualizovat v zobrazení:
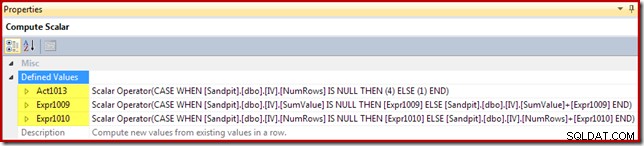
Kód akce je označen štítkem výrazu [Act1xxx]. Platné hodnoty jsou 1 pro aktualizaci, 3 pro odstranění a 4 pro vložení. Tento akční výraz má za následek vložení (kód 4), pokud nebyl v pohledu nalezen žádný odpovídající řádek (tj. vnější spojení vrátilo hodnotu null pro sloupec NumRows). Pokud byl nalezen odpovídající řádek, kód akce je 1 (aktualizace).
Všimněte si, že NumRows je název přidělený požadovanému sloupci COUNT_BIG(*) v zobrazení. V plánu, který by mohl vést k odstranění z pohledu, výpočetní skalár zjistí, kdy se tato hodnota stane nulou (žádné řádky pro aktuální skupinu) a vygeneruje kód akce odstranění (3).
Zbývající výrazy udržují součet a počítají agregace v pohledu. Všimněte si však, že štítky výrazů [Expr1009] a [Expr1010] nejsou nové; odkazují na štítky vytvořené Stream Aggregate. Logika je přímočará:pokud nebyl nalezen odpovídající řádek, nová hodnota, kterou chcete vložit, je pouze hodnota vypočítaná v agregaci. Pokud byl v zobrazení nalezen odpovídající řádek, aktualizovaná hodnota je aktuální hodnota v řádku plus přírůstek vypočítaný agregací.
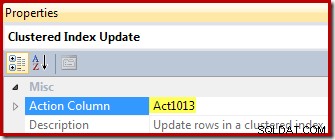
Nakonec operátor aktualizace zobrazení (zobrazený jako aktualizace klastrového indexu v SSMS) zobrazí odkaz na sloupec akce ([Act1013] definovaný výpočetním skalárem):
Příklad 3 – Víceřádková aktualizace
Zatím jsme se dívali pouze na vložky do základní tabulky. Prováděcí plány pro odstranění jsou velmi podobné, pouze s několika drobnými rozdíly v podrobných výpočtech. Tento další příklad se proto přesune k pohledu na plán údržby pro aktualizaci základní tabulky:
DECLARE
@Group1 integer = 1,
@Group2 integer = 2,
@Value integer = 1;
UPDATE dbo.T1
SET Value = Value + @Value
WHERE GroupID IN (@Group1, @Group2); Stejně jako dříve tento dotaz používá proměnné ke skrytí doslovných hodnot před optimalizátorem, což zabraňuje použití některých zjednodušení. Je také pečlivé aktualizovat dvě samostatné skupiny, aby se zabránilo ovlivnění optimalizací, které lze použít, když optimalizátor zná pouze jednu skupinu (jeden řádek indexovaného pohledu). Popisovaný plán provádění pro aktualizační dotaz je níže:
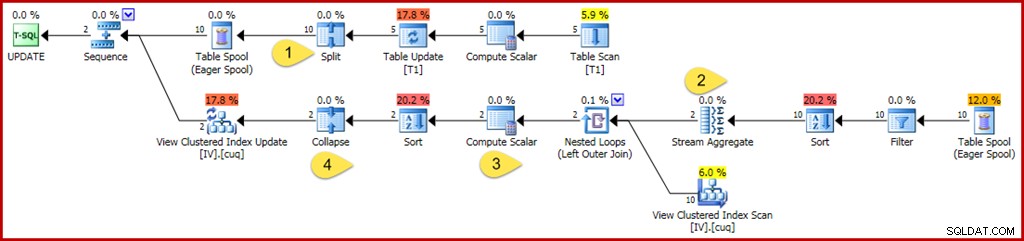
Změny a zajímavosti jsou:
- Nový operátor Split změní každou aktualizaci řádku základní tabulky na samostatnou operaci odstranění a vložení. Každý řádek aktualizace je rozdělen do dvou samostatných řádků, čímž se zdvojnásobí počet řádků za tímto bodem v plánu. Rozdělení je součástí vzoru rozdělení-třídění-sbalení potřebného k ochraně proti nesprávným přechodným chybám narušení jedinečného klíče.
- Agregace proudů je upravena tak, aby zohledňovala příchozí řádky, které mohou specifikovat odstranění nebo vložení (kvůli rozdělení a určenému sloupcem s kódem akce v řádku). Řádek vložení přispívá k původní hodnotě v souhrnných souhrnech; znaménko je obrácené pro řádky akce odstranění. Podobně agregace počtu řádků zde počítá vložené řádky jako +1 a smazané řádky jako –1.
- Logika Compute Scalar je také upravena tak, aby odrážela, že čistý efekt změn na skupinu může vyžadovat eventuální vložení, aktualizaci nebo odstranění akce proti materializovanému pohledu. Ve skutečnosti není možné, aby tento konkrétní aktualizační dotaz vedl k vložení nebo odstranění řádku proti tomuto pohledu, ale logika potřebná k odvození je mimo aktuální možnosti uvažování optimalizátoru. Mírně odlišný aktualizační dotaz nebo definice pohledu může skutečně vést ke směsi akcí vložení, odstranění a aktualizace pohledu.
- Operátor Collapse je zvýrazněn čistě pro svou roli ve výše uvedeném vzoru rozdělení-třídění-sbalení. Všimněte si, že sbalí pouze odstranění a vložení na stejný klíč; neodpovídající smazání a vložení po sbalení jsou naprosto možné (a zcela obvyklé).
Stejně jako dříve jsou hlavními vlastnostmi operátora, na které je třeba se podívat, abyste porozuměli práci údržby indexovaného zobrazení, Filtr, Souhrnný proud, Vnější spojení a Výpočetní skalární.
Příklad 4 – Víceřádková aktualizace pomocí spojení
K dokončení přehledu plánů provádění údržby indexovaného pohledu budeme potřebovat nový vzorový pohled, který spojuje několik tabulek dohromady a obsahuje projekci ve vybraném seznamu:
CREATE TABLE dbo.E1 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E2 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E3 (g integer NULL, a integer NULL);
GO
INSERT dbo.E1 (g, a) VALUES (1, 1);
INSERT dbo.E2 (g, a) VALUES (1, 1);
INSERT dbo.E3 (g, a) VALUES (1, 1);
GO
CREATE VIEW dbo.V1
WITH SCHEMABINDING
AS
SELECT
g = E1.g,
sa1 = SUM(ISNULL(E1.a, 0)),
sa2 = SUM(ISNULL(E2.a, 0)),
sa3 = SUM(ISNULL(E3.a, 0)),
cbs = COUNT_BIG(*)
FROM dbo.E1 AS E1
JOIN dbo.E2 AS E2
ON E2.g = E1.g
JOIN dbo.E3 AS E3
ON E3.g = E2.g
WHERE
E1.g BETWEEN 1 AND 5
GROUP BY
E1.g;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.V1 (g); Aby byla zajištěna správnost, jedním z požadavků indexovaného zobrazení je, že souhrnný souhrn nemůže pracovat s výrazem, který by mohl být vyhodnocen jako null. Výše uvedená definice pohledu používá ke splnění tohoto požadavku ISNULL. Ukázkový aktualizační dotaz, který vytváří docela obsáhlou komponentu plánu údržby indexu, je uveden níže spolu s plánem provádění, který vytváří:
UPDATE dbo.E1
SET g = g + 1,
a = a + 1;
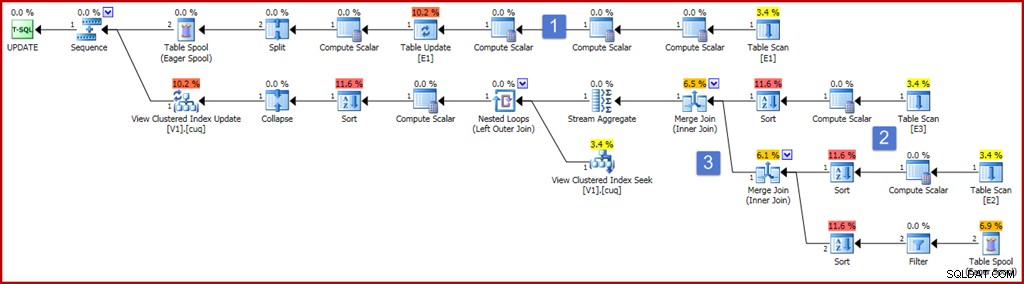
Plán teď vypadá docela velký a komplikovaný, ale většina prvků je přesně taková, jak jsme již viděli. Klíčové rozdíly jsou:
- Nejvyšší větev plánu zahrnuje řadu dalších operátorů Compute Scalar. Ty by mohly být uspořádány kompaktněji, ale v podstatě jsou přítomny proto, aby zachytily předaktualizační hodnoty sloupců bez seskupení. Výpočetní skalár nalevo od aktualizace tabulky zachycuje po aktualizaci hodnotu sloupce "a" s aplikovanou projekcí ISNULL.
- Nové výpočetní skalary v této oblasti plánu počítají hodnotu vytvořenou výrazem ISNULL v každé zdrojové tabulce. Obecně platí, že projekce na spojených tabulkách v pohledu zde budou reprezentovány výpočetními skalary. Řazení v této oblasti plánu jsou přítomna čistě proto, že optimalizátor zvolil strategii spojení sloučení z důvodů nákladů (nezapomeňte, že sloučení vyžaduje seřazený vstup podle klíče spojení).
- Dva operátory spojení jsou nové a jednoduše implementují spojení v definici pohledu. Tato spojení se vždy objeví před agregací proudu, která vypočítává přírůstkový účinek změn na pohled. Všimněte si, že změna základní tabulky může vést k tomu, že řádek, který dříve splňoval kritéria spojení, se již nespojí, a naopak. Všechny tyto potenciální složitosti jsou zpracovány správně (s ohledem na omezení indexovaného zobrazení) pomocí agregátu streamů, který po provedení spojení vytvoří souhrn změn na klíč zobrazení.
Poslední myšlenky
Tento poslední plán představuje v podstatě úplnou šablonu pro udržování indexovaného pohledu, i když přidání neklastrovaných indexů do pohledu by přidalo další operátory, které jsou také zařazeny do výstupu operátora aktualizace pohledu. Kromě zvláštního rozdělení (a kombinace řazení a sbalení, pokud je neshlukovaný index pohledu jedinečný) na této možnosti není nic zvláštního. Přidání výstupní klauzule do dotazu na základní tabulku může také vytvořit některé zajímavé operátory navíc, ale opět, tyto nejsou specifické pro údržbu indexovaného zobrazení jako takovou.
Abychom shrnuli úplnou celkovou strategii:
- Změny základní tabulky se použijí jako obvykle; mohou být zachyceny hodnoty před aktualizací.
- K transformaci aktualizací na páry smazat/vložit lze použít operátor rozdělení.
- Dychtivý spool ukládá informace o změnách základní tabulky do dočasného úložiště.
- Jsou přístupné všechny tabulky v zobrazení, kromě aktualizované základní tabulky (která se načítá ze zařazování).
- Projekce v pohledu jsou reprezentovány výpočetními skaláry.
- V zobrazení jsou použity filtry. Filtry mohou být vloženy do skenů nebo vyhledávání jako zbytky.
- Provedou se spojení zadaná v zobrazení.
- Souhrnný údaj vypočítá čisté přírůstkové změny seskupené podle klíče seskupeného zobrazení.
- Sada přírůstkových změn je vnější spojena s pohledem.
- Výpočetní skalár vypočítá kód akce (vložit/aktualizovat/smazat proti pohledu) pro každou změnu a vypočítá skutečné hodnoty, které mají být vloženy nebo aktualizovány. Výpočetní logika je založena na výstupu agregace a výsledku vnějšího připojení k pohledu.
- Změny jsou seřazeny podle klíče zobrazení a kódu akce a podle potřeby sbaleny do aktualizací.
- Nakonec se přírůstkové změny aplikují na samotné zobrazení.
Jak jsme viděli, běžná sada nástrojů dostupných pro optimalizátor dotazů se stále používá na automaticky generované části plánu, což znamená, že jeden nebo více výše uvedených kroků lze zjednodušit, transformovat nebo zcela odstranit. Základní tvar a fungování plánu však zůstávají nedotčeny.
Pokud jste postupovali podle příkladů kódu, můžete k vyčištění použít následující skript:
DROP VIEW dbo.V1; DROP TABLE dbo.E3, dbo.E2, dbo.E1; DROP VIEW dbo.IV; DROP TABLE dbo.T1;