Kolem tématu štěpení strun se vždy rozvinou některé zajímavé diskuse. Doufám, že ve dvou předchozích příspěvcích na blogu „Rozdělit řetězce správným způsobem – nebo další nejlepší způsob“ a „Rozdělení řetězců:Následná akce“ jsem ukázal, že hledání „nejvýkonnější“ funkce rozdělení T-SQL je neplodné. . Když je rozdělení skutečně nutné, vždy vyhraje CLR a další nejlepší možnost se může lišit v závislosti na aktuálním úkolu. Ale v těchto příspěvcích jsem naznačil, že rozdělení na straně databáze nemusí být v první řadě nutné.
SQL Server 2008 zavedl parametry s hodnotou tabulky, způsob, jak předat „tabulku“ z aplikace do uložené procedury, aniž byste museli sestavovat a analyzovat řetězec, serializovat do XML nebo se zabývat jakoukoli z těchto metod dělení. Tak jsem si myslel, že zkontroluji, jak si tato metoda stojí v porovnání s vítězem našich předchozích testů – protože to může být životaschopná možnost, ať už můžete použít CLR nebo ne. (Nejlepší bibli o TVP najdete v obsáhlém článku kolegy SQL Server MVP Erlanda Sommarskoga.)
Testy
Pro tento test budu předstírat, že máme co do činění se sadou řetězců verzí. Představte si aplikaci C#, která předává sadu těchto řetězců (řekněme, které byly shromážděny od skupiny uživatelů) a my potřebujeme porovnat verze s tabulkou (řekněme, která označuje vydání služeb, která jsou použitelná pro konkrétní sadu verzí). Je zřejmé, že skutečná aplikace by měla více sloupců, ale jen proto, aby vytvořila určitý objem a stále udržovala tabulku hubenou (také používám NVARCHAR, protože to vyžaduje funkce CLR split a chci odstranit jakoukoli nejednoznačnost kvůli implicitní konverzi) :
CREATE TABLE dbo.VersionStrings(left_post NVARCHAR(5), right_post NVARCHAR(5)); CREATE CLUSTERED INDEX x ON dbo.VersionStrings(left_post, right_post); ;WITH x AS ( SELECT lp = CONVERT(DECIMAL(4,3), RIGHT(RTRIM(s1.[object_id]), 3)/1000.0) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ) INSERT dbo.VersionStrings ( left_post, right_post ) SELECT lp - CASE WHEN lp >= 0.9 THEN 0.1 ELSE 0 END, lp + (0.1 * CASE WHEN lp >= 0.9 THEN -1 ELSE 1 END) FROM x;
Nyní, když jsou data na svém místě, další věc, kterou musíme udělat, je vytvořit uživatelsky definovaný typ tabulky, který pojme sadu řetězců. Počáteční typ tabulky pro tento řetězec je docela jednoduchý:
CREATE TYPE dbo.VersionStringsTVP AS TABLE (VersionString NVARCHAR(5));
Pak potřebujeme několik uložených procedur, abychom přijali seznamy z C#. Pro jednoduchost opět provedeme počítání, abychom měli jistotu, že provedeme kompletní skenování, a počítání v aplikaci budeme ignorovat:
CREATE PROCEDURE dbo.SplitTest_UsingCLR
@list NVARCHAR(MAX)
AS
BEGIN
SET NOCOUNT ON;
SELECT c = COUNT(*)
FROM dbo.VersionStrings AS v
INNER JOIN dbo.SplitStrings_CLR(@list, N',') AS s
ON s.Item BETWEEN v.left_post AND v.right_post;
END
GO
CREATE PROCEDURE dbo.SplitTest_UsingTVP
@list dbo.VersionStringsTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
SELECT c = COUNT(*)
FROM dbo.VersionStrings AS v
INNER JOIN @list AS l
ON l.VersionString BETWEEN v.left_post AND v.right_post;
END
GO Všimněte si, že TVP předaný do uložené procedury musí být označen jako READONLY – v současné době neexistuje způsob, jak provést DML na datech, jako byste to udělali u proměnné tabulky nebo dočasné tabulky. Erland však předložil velmi oblíbený požadavek, aby Microsoft učinil tyto parametry flexibilnějšími (a jeho argumentem je zde spousta hlubšího náhledu).
Krása zde spočívá v tom, že SQL Server se již nemusí vůbec potýkat s rozdělováním řetězce – ani v T-SQL, ani při jeho předávání CLR – protože je již v nastavené struktuře, kde exceluje.
Dále konzolová aplikace C#, která provádí následující:
- Přijímá číslo jako argument označující, kolik prvků řetězce by mělo být definováno
- Vytvoří řetězec CSV z těchto prvků pomocí StringBuilderu, který se předá uložené proceduře CLR
- Vytvoří DataTable se stejnými prvky, které se předají uložené proceduře TVP
- Před voláním příslušných uložených procedur také otestuje režii převodu řetězce CSV na DataTable a naopak.
Kód aplikace C# najdete na konci článku. Umím hláskovat C#, ale v žádném případě nejsem guru; Jsem si jistý, že tam můžete najít neefektivity, které mohou způsobit, že kód bude fungovat o něco lépe. Ale jakékoli takové změny by měly ovlivnit celou sadu testů podobným způsobem.
Spustil jsem aplikaci 10krát pomocí 100, 1 000, 2 500 a 5 000 prvků. Výsledky byly následující (toto ukazuje průměrnou dobu trvání v sekundách v průběhu 10 testů):
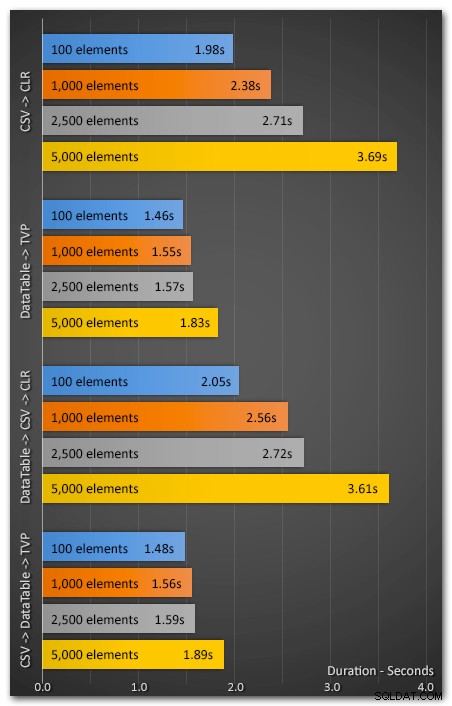
Výkon stranou…
Kromě jasného rozdílu ve výkonu mají TVP ještě jednu výhodu – typy tabulek se nasazují mnohem jednodušeji než sestavy CLR, zejména v prostředích, kde bylo CLR zakázáno z jiných důvodů. Doufám, že překážky bránící CLR postupně mizí a nové nástroje činí zavádění a údržbu méně bolestivou, ale pochybuji, že snadné počáteční nasazení pro CLR bude někdy snazší než nativní přístupy.
Na druhou stranu, kromě omezení pouze pro čtení, jsou typy tabulek jako typy aliasů v tom, že je obtížné je následně upravit. Pokud chcete změnit velikost sloupce nebo přidat sloupec, neexistuje žádný příkaz ALTER TYPE, a abyste mohli typ DROP a znovu vytvořit, musíte nejprve odstranit odkazy na typ ze všech procedur, které jej používají. . Pokud bychom tedy například ve výše uvedeném případě potřebovali zvýšit sloupec VersionString na NVARCHAR(32), museli bychom vytvořit fiktivní typ a upravit uloženou proceduru (a jakoukoli jinou proceduru, která ji používá):
CREATE TYPE dbo.VersionStringsTVPCopy AS TABLE (VersionString NVARCHAR(32)); GO ALTER PROCEDURE dbo.SplitTest_UsingTVP @list dbo.VersionStringsTVPCopy READONLY AS ... GO DROP TYPE dbo.VersionStringsTVP; GO CREATE TYPE dbo.VersionStringsTVP AS TABLE (VersionString NVARCHAR(32)); GO ALTER PROCEDURE dbo.SplitTest_UsingTVP @list dbo.VersionStringsTVP READONLY AS ... GO DROP TYPE dbo.VersionStringsTVPCopy; GO
(Nebo alternativně zrušte proceduru, zrušte typ, znovu vytvořte typ a znovu vytvořte proceduru.)
Závěr
Metoda TVP trvale předčila metodu dělení CLR a s rostoucím počtem prvků o větší procento. Dokonce i přidání režijních nákladů na převod existujícího řetězce CSV na DataTable přineslo mnohem lepší end-to-end výkon. Doufám tedy, že pokud jsem vás již nepřesvědčil, abyste opustili své techniky dělení řetězců T-SQL ve prospěch CLR, vyzval jsem vás, abyste zkusili parametry s hodnotou tabulky. Mělo by být snadné jej otestovat, i když aktuálně nepoužíváte DataTable (nebo nějaký ekvivalent).
Kód C# použitý pro tyto testy
Jak jsem řekl, nejsem žádný C# guru, takže zde pravděpodobně dělám spoustu naivních věcí, ale metodika by měla být zcela jasná.
using System;
using System.IO;
using System.Data;
using System.Data.SqlClient;
using System.Text;
using System.Collections;
namespace SplitTester
{
class SplitTester
{
static void Main(string[] args)
{
DataTable dt_pure = new DataTable();
dt_pure.Columns.Add("Item", typeof(string));
StringBuilder sb_pure = new StringBuilder();
Random r = new Random();
for (int i = 1; i <= Int32.Parse(args[0]); i++)
{
String x = r.NextDouble().ToString().Substring(0,5);
sb_pure.Append(x).Append(",");
dt_pure.Rows.Add(x);
}
using
(
SqlConnection conn = new SqlConnection(@"Data Source=.;
Trusted_Connection=yes;Initial Catalog=Splitter")
)
{
conn.Open();
// four cases:
// (1) pass CSV string directly to CLR split procedure
// (2) pass DataTable directly to TVP procedure
// (3) serialize CSV string from DataTable and pass CSV to CLR procedure
// (4) populate DataTable from CSV string and pass DataTable to TCP procedure
// ********** (1) ********** //
write(Environment.NewLine + "Starting (1)");
SqlCommand c1 = new SqlCommand("dbo.SplitTest_UsingCLR", conn);
c1.CommandType = CommandType.StoredProcedure;
c1.Parameters.AddWithValue("@list", sb_pure.ToString());
c1.ExecuteNonQuery();
c1.Dispose();
write("Finished (1)");
// ********** (2) ********** //
write(Environment.NewLine + "Starting (2)");
SqlCommand c2 = new SqlCommand("dbo.SplitTest_UsingTVP", conn);
c2.CommandType = CommandType.StoredProcedure;
SqlParameter tvp1 = c2.Parameters.AddWithValue("@list", dt_pure);
tvp1.SqlDbType = SqlDbType.Structured;
c2.ExecuteNonQuery();
c2.Dispose();
write("Finished (2)");
// ********** (3) ********** //
write(Environment.NewLine + "Starting (3)");
StringBuilder sb_fake = new StringBuilder();
foreach (DataRow dr in dt_pure.Rows)
{
sb_fake.Append(dr.ItemArray[0].ToString()).Append(",");
}
SqlCommand c3 = new SqlCommand("dbo.SplitTest_UsingCLR", conn);
c3.CommandType = CommandType.StoredProcedure;
c3.Parameters.AddWithValue("@list", sb_fake.ToString());
c3.ExecuteNonQuery();
c3.Dispose();
write("Finished (3)");
// ********** (4) ********** //
write(Environment.NewLine + "Starting (4)");
DataTable dt_fake = new DataTable();
dt_fake.Columns.Add("Item", typeof(string));
string[] list = sb_pure.ToString().Split(',');
for (int i = 0; i < list.Length; i++)
{
if (list[i].Length > 0)
{
dt_fake.Rows.Add(list[i]);
}
}
SqlCommand c4 = new SqlCommand("dbo.SplitTest_UsingTVP", conn);
c4.CommandType = CommandType.StoredProcedure;
SqlParameter tvp2 = c4.Parameters.AddWithValue("@list", dt_fake);
tvp2.SqlDbType = SqlDbType.Structured;
c4.ExecuteNonQuery();
c4.Dispose();
write("Finished (4)");
}
}
static void write(string msg)
{
Console.WriteLine(msg + ": "
+ DateTime.UtcNow.ToString("HH:mm:ss.fffff"));
}
}
}