Chcete-li efektivně provozovat jakoukoli databázi, musíte mít přehled o výkonu databáze. To nemusí být zřejmé, když je vše v pořádku, ale jakmile se něco pokazí, přístup k informacím může pomoci rychle a správně diagnostikovat problém.
Všechny databáze zpřístupňují uživatelům některá ze svých interních stavových dat. V MySQL můžete tato data získat většinou spuštěním 'SHOW STATUS' a 'SHOW GLOBAL STATUS', spuštěním 'SHOW ENGINE INNODB STATUS', kontrolou tabulek information_schema a v novějších verzích dotazem na tabulky performance_schema.

Tyto metody nejsou zdaleka vhodné v každodenním provozu, a proto jsou oblíbená různá řešení monitorování a trendů. Nástroje jako Nagios/Icinga jsou navrženy tak, aby sledovaly hostitele/služby a upozornily, když se služba dostane mimo přijatelný rozsah. Další nástroje, jako jsou Cacti a Munin, poskytují grafický pohled na informace o hostiteli/službě a poskytují historický kontext výkonu a použití. ClusterControl kombinuje tyto dva typy monitorování, takže se podíváme na informace, které poskytuje, a na to, jak bychom je měli interpretovat.
Pokud používáte Galera Cluster (MySQL Galera Cluster by Codership nebo MariaDB Cluster nebo Percona XtraDB Cluster), možná jste si všimli následující sekce na kartě „Přehled“ ClusterControl:
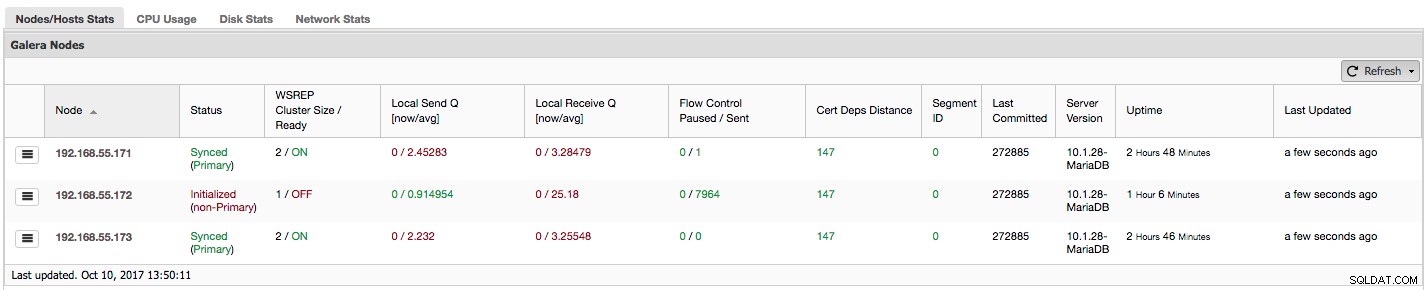
Podívejme se krok za krokem, jaký druh dat zde máme.
První sloupec obsahuje seznam uzlů s jejich IP adresami – k tomu není moc co říci.
Druhý sloupec je zajímavější – popisuje stav uzlu (wsrep_local_state_comment postavení). Uzel může být v různých stavech:
- Inicializováno – Uzel je v provozu, ale není součástí clusteru. Může to být způsobeno například problémy se sítí;
- Připojování – uzel se právě připojuje ke clusteru a buď přijímá nebo požaduje přenos stavu od jednoho z dalších uzlů;
- Donor/Desynced – uzel slouží jako dárce nějakému jinému uzlu, který se připojuje ke clusteru;
- Připojeno – uzel je připojen ke clusteru, ale je zaneprázdněn doháněním potvrzených sad zápisu;
- Synchronizováno – uzel funguje normálně.
Ve stejném sloupci v závorce je stav clusteru (wsrep_cluster_status postavení). Může mít tři různé stavy:
- Primární – Komunikace mezi uzly funguje a je přítomno kvorum (většina uzlů je k dispozici)
- Neprimární – uzel byl součástí shluku, ale z nějakého důvodu ztratil kontakt se zbytkem shluku. V důsledku toho je tento uzel považován za neaktivní a nebude přijímat dotazy
- Odpojeno – Uzel nemohl navázat skupinovou komunikaci.
"WSREP Cluster Size / Ready" nám říká o velikosti clusteru, jak ji vidí uzel, a zda je uzel připraven přijímat dotazy. Neprimární komponenty vytvářejí cluster o velikosti 1 a připravenost na wsrep je VYPNUTÁ.
Podívejme se na snímek obrazovky výše a uvidíme, co nám říká o Galeře. Můžeme vidět tři uzly. Dva z nich (192.168.55.171 a 192.168.55.173) jsou naprosto v pořádku, oba jsou „synchronizované“ a cluster je ve stavu „Primární“. Cluster se aktuálně skládá ze dvou uzlů. Uzel 192.168.55.172 je „inicializovaný“ a tvoří „neprimární“ komponentu. Znamená to, že tento uzel ztratil spojení s clusterem – pravděpodobně došlo k nějakým problémům se sítí (ve skutečnosti jsme použili iptables k zablokování provozu do tohoto uzlu z 192.168.55.171 i 192.168.55.173).
V tuto chvíli se musíme trochu zastavit a popsat, jak Galera Cluster interně funguje. Nebudeme zabíhat do přílišných podrobností, protože to není v rozsahu tohoto blogového příspěvku, ale k pochopení důležitosti dat uvedených v dalších sloupcích jsou zapotřebí určité znalosti.
Galera je "virtuálně" synchronní, multi-master cluster. Znamená to, že byste měli očekávat, že se data budou mezi uzly přenášet „virtuálně“ ve stejnou dobu (už žádné otravné problémy se zaostávajícími podřízenými zařízeními) a že můžete zapisovat do libovolného uzlu v clusteru (už žádné otravné problémy s povýšením podřízeného na master ). Aby toho dosáhla, Galera používá writesets - atomickou sadu změn, které jsou replikovány napříč clusterem. Zápisová sada může obsahovat několik změn řádků a další potřebné informace, jako jsou data týkající se zamykání.
Jakmile klient vydá COMMIT, ale předtím, než MySQL skutečně něco potvrdí, je vytvořena sada zápisů a odeslána všem uzlům v clusteru k certifikaci. Všechny uzly zkontrolují, zda je možné provést změny nebo ne (protože změny mohou kolidovat s jinými zápisy prováděnými mezitím přímo na jiném uzlu). Pokud ano, data jsou skutečně potvrzena MySQL, pokud ne, provede se rollback.
Co je důležité si zapamatovat, je fakt, že uzly, podobné jako slave v běžné replikaci, mohou fungovat jinak – některé mohou mít lepší hardware než jiné, některé mohou být více zatížené než jiné. Galera však vyžaduje, aby zpracovávali sady zápisů krátkým a rychlým způsobem, aby byla zachována „virtuální“ synchronizace. Musí existovat mechanismus, který dokáže omezit replikaci a umožnit pomalejším uzlům držet krok se zbytkem clusteru.
Podívejme se na sloupce „Local Send Q [nyní/prům.]“ a „Local Receive Q [nyní/prům.]“. Každý uzel má místní frontu pro odesílání a přijímání sad zápisu. Umožňuje paralelizovat některé zápisy a data fronty, která nemohou být zpracována najednou, pokud uzel nemůže držet krok s provozem. V ZOBRAZIT GLOBAL STATUS najdeme osm čítačů popisujících obě fronty, čtyři čítače na frontu:
- wsrep_local_send_queue - aktuální stav fronty odesílání
- wsrep_local_send_queue_min - minimum od FLUSH STATUS
- wsrep_local_send_queue_max - maximum od FLUSH STATUS
- wsrep_local_send_queue_avg - průměr od FLUSH STATUS
- wsrep_local_recv_queue - aktuální stav přijímací fronty
- wsrep_local_recv_queue_min - minimum od FLUSH STATUS
- wsrep_local_recv_queue_max - maximum od FLUSH STATUS
- wsrep_local_recv_queue_avg - průměr od FLUSH STATUS
Výše uvedené metriky jsou sjednoceny napříč uzly pod ClusterControl -> Výkon -> Stav DB:
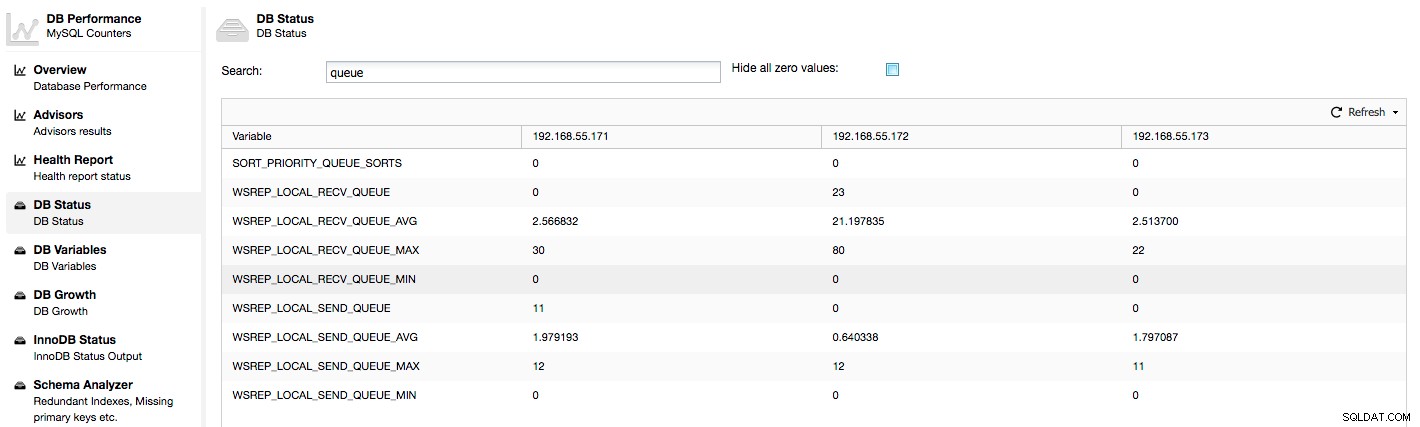
ClusterControl zobrazuje počítadla „nyní“ a „průměr“, protože jsou nejsmysluplnější jako jediné číslo (můžete také vytvářet vlastní grafy založené na proměnných popisujících aktuální stav front) . Když vidíme, že jedna z front roste, znamená to, že uzel nemůže držet krok s replikací a ostatní uzly budou muset zpomalit, aby to dohnaly. Doporučujeme prozkoumat pracovní vytížení daného uzlu – podívejte se na seznam procesů pro některé dlouho běžící dotazy, zkontrolujte statistiky OS, jako je využití procesoru a zátěž I/O. Možná je také možné přerozdělit část provozu z tohoto uzlu do zbytku clusteru.
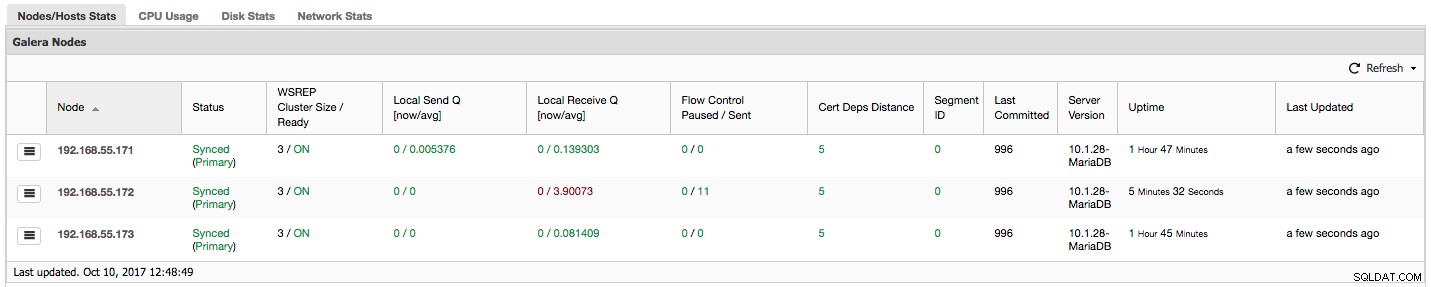
"Řízení toku pozastaveno" zobrazuje informace o procentech času, po který daný uzel musel pozastavit replikaci z důvodu příliš velkého zatížení. Když uzel nemůže držet krok s pracovní zátěží, odešle pakety řízení toku jiným uzlům a informuje je, že by měly omezit odesílání sad zápisu. Na našem snímku obrazovky máme hodnotu „0,30“ pro uzel 192.168.55.172. To znamená, že téměř 30 % času musel tento uzel pozastavit replikaci, protože nebyl schopen držet krok s rychlostí certifikace sady zápisů vyžadovanou jinými uzly (nebo jednodušeji, zasáhlo jej příliš mnoho zápisů!). Jak vidíme, „Local Receive Q [avg]“ nás na tuto skutečnost také upozorňuje.
Další sloupec „Flow Control Sent“ nám poskytuje informace o tom, kolik paketů Flow Control daný uzel odeslal do clusteru. Znovu vidíme, že je to uzel 192.168.55.172, který zpomaluje cluster.
Co můžeme s těmito informacemi dělat? Většinou bychom měli prozkoumat, co se děje v pomalém uzlu. Zkontrolujte využití CPU, zkontrolujte výkon I/O a statistiky sítě. Tento první krok pomáhá posoudit, jakému druhu problému čelíme.
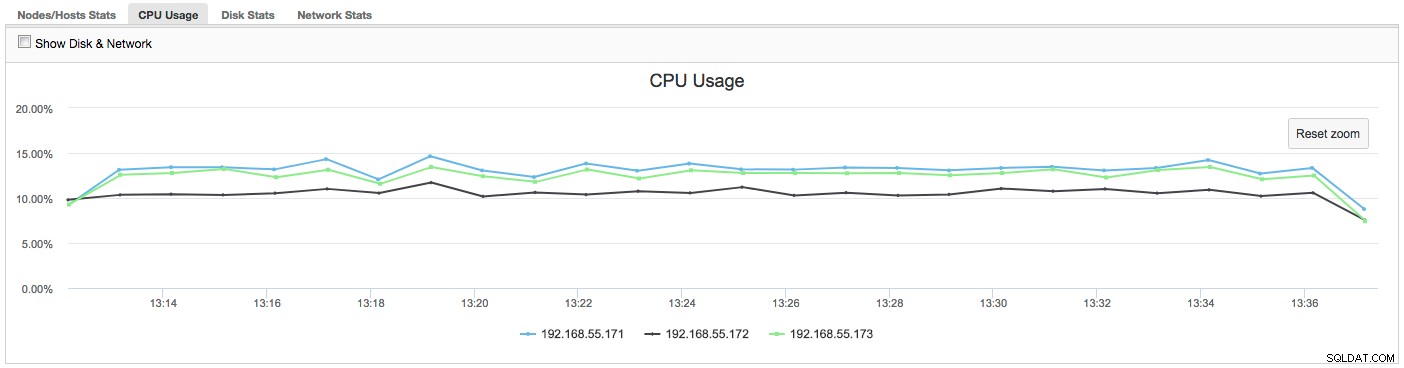
V tomto případě, jakmile přepneme na kartu Využití CPU, je jasné, že naše problémy způsobuje rozsáhlé využití CPU. Dalším krokem by bylo identifikovat viníka nahlédnutím do PROCESSLIST (Monitor dotazů -> Spuštěné dotazy -> filtrovat podle 192.168.55.172) a zkontrolovat problematické dotazy:
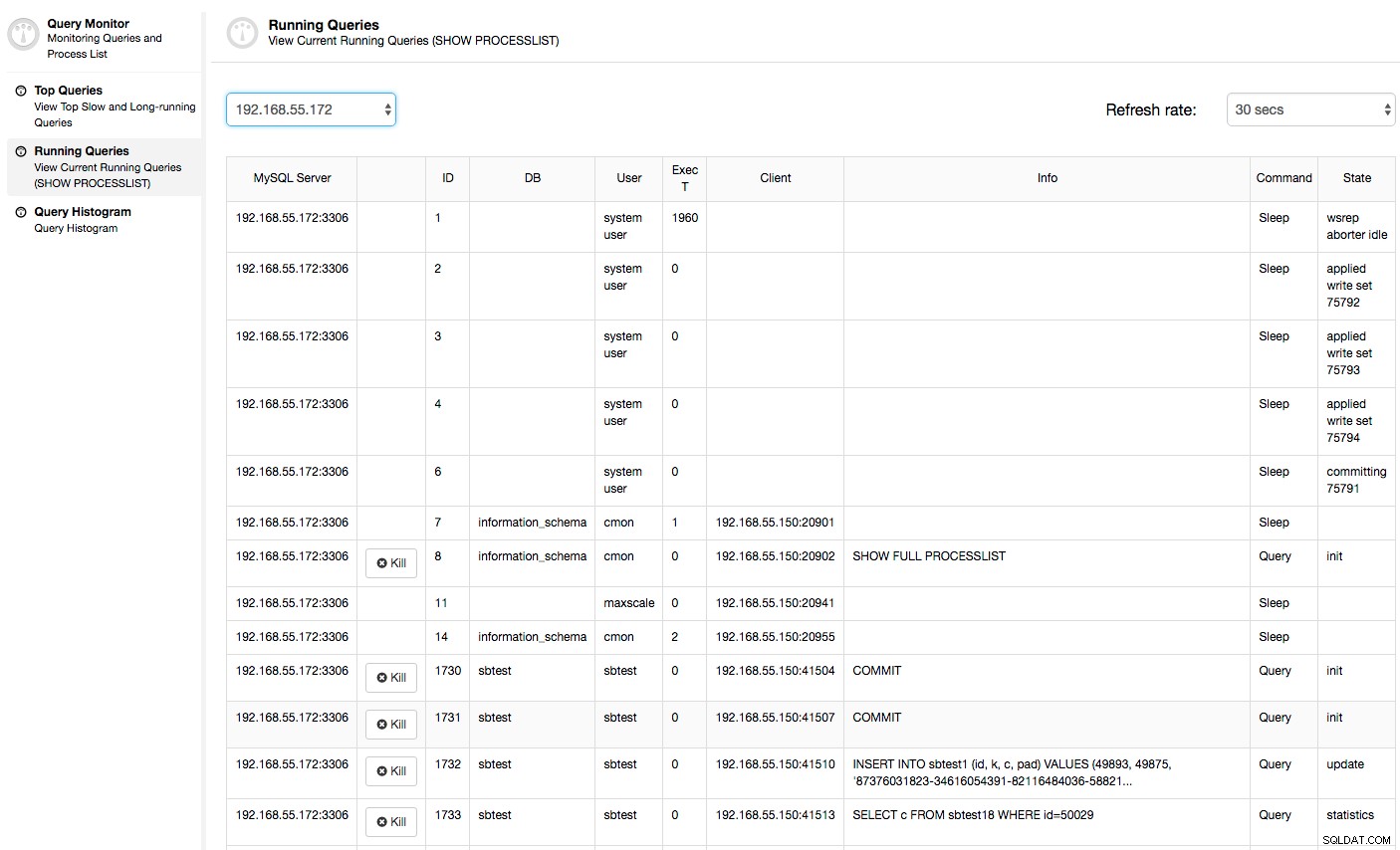
Nebo zkontrolujte procesy na uzlu ze strany operačního systému (Nodes -> 192.168.55.172 -> Top), abyste zjistili, zda zatížení není způsobeno něčím mimo Galera/MySQL.
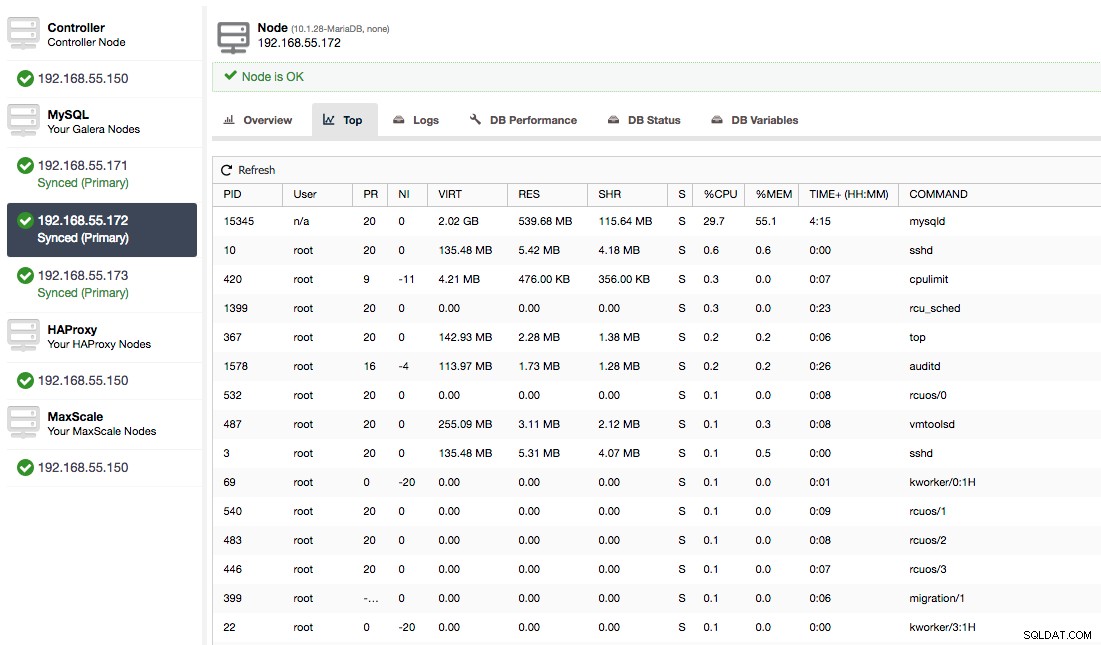
V tomto případě jsme provedli příkaz mysqld prostřednictvím cpulimit, abychom simulovali pomalé využití CPU speciálně pro proces mysqld tím, že jsme jej omezili na 30 % ze 400 % dostupného CPU (server má 4 jádra).
Sloupec "Cert Deps Distance" nám poskytuje informace o tom, kolik sad zápisů lze v průměru použít paralelně. Zápisové sady mohou být někdy spouštěny současně – Galera toho využívá tím, že používá několik wsrep_slave_threads použít sady zápisů. Tento sloupec vám dává určitou představu, kolik podřízených vláken byste mohli při své zátěži použít. Stojí za zmínku, že nemá smysl nastavovat wsrep_slave_threads proměnná na hodnoty vyšší, než vidíte v tomto sloupci nebo v wsrep_cert_deps_distance stavová proměnná, na které je založen sloupec "Vzdálenost certifikace". Další důležitá poznámka – nemá smysl ani nastavovat wsrep_slave_threads proměnná na více než počet jader, které má váš CPU.
„ID segmentu“ – tento sloupec bude vyžadovat další vysvětlení. Segmenty jsou novou funkcí přidanou v Galera 3.0. Před touto verzí se zapisovací sady vyměňovaly mezi všemi uzly. Řekněme, že máme dvě datová centra:
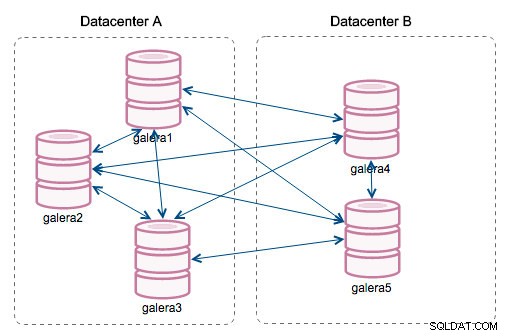
Tento druh chatování funguje v místních sítích dobře, ale WAN je jiný příběh – certifikace se zpomaluje kvůli zvýšené latenci, vznikají dodatečné náklady kvůli šířce pásma sítě používané pro přenos sad zápisu mezi každým členem clusteru.
Se zavedením „Segmentů“ se věci změnily. Uzel můžete přiřadit k segmentu úpravou wsrep_provider_options proměnnou a přidáním "gmcast.segment=x" (0, 1, 2). S uzly se stejným číslem segmentu se zachází tak, jako by byly ve stejném datovém centru propojeném lokální sítí. Náš graf se pak změní:
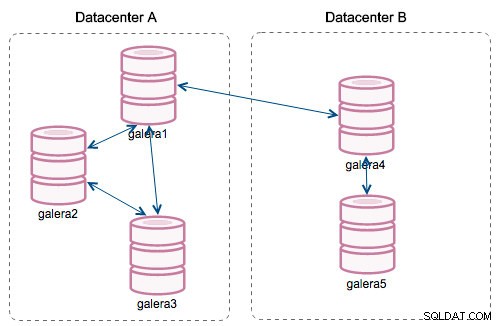
Hlavní rozdíl je v tom, že už není komunikace mezi všemi. V rámci každého segmentu ano – je to stále stejný mechanismus, ale oba segmenty komunikují pouze prostřednictvím jediného spojení mezi dvěma vybranými uzly. V případě výpadku se toto připojení automaticky přepne. Výsledkem je méně chvění sítě a menší využití šířky pásma mezi vzdálenými datovými centry. Takže v podstatě sloupec "ID segmentu" nám říká, ke kterému segmentu je uzel přiřazen.
Sloupec "Last Committed" nám poskytuje informace o pořadovém čísle sady zápisů, která byla naposledy spuštěna na daném uzlu. Může to být užitečné při určování, který uzel je nejaktuálnější, pokud je potřeba zavést cluster.
Zbývající sloupce jsou samozřejmé:Verze serveru, doba provozu uzlu a kdy byl stav aktualizován.
Jak můžete vidět, sekce "Galera Nodes" v "Nodes/Hosts Stats" na kartě "Overview" vám dává docela dobrý přehled o stavu clusteru - zda tvoří "Primární" komponentu, kolik uzlů je zdravých. , jsou u některých uzlů nějaké problémy s výkonem a pokud ano, který uzel zpomaluje cluster.
Tato sada dat je velmi užitečná při ovládání clusteru Galera, takže doufejme, že už žádné létání naslepo :-)