Presto je open-source, paralelně distribuovaný, SQL engine pro zpracování velkých dat. Byl vyvinut od základů Facebookem. První interní vydání proběhlo v roce 2013 a bylo docela revolučním řešením jejich problémů s velkými daty.
Se stovkami geograficky umístěných serverů a petabajty dat začal Facebook hledat alternativní platformu pro své clustery Hadoop. Jejich infrastrukturní tým chtěl zkrátit čas potřebný ke spouštění analytických dávkových úloh a zjednodušit vývoj kanálu pomocí programovacího jazyka široce známého v organizaci – SQL.
Podle nadace Presto „Facebook používá Presto pro interaktivní dotazy na několik interních datových úložišť, včetně jejich 300PB datového skladu. Více než 1 000 zaměstnanců Facebooku používá Presto denně ke spouštění více než 30 000 dotazů, které celkem proskenují každý den přes petabajt.“
Zatímco Facebook má výjimečné prostředí datového skladu, stejné výzvy jsou přítomny v mnoha organizacích, které se zabývají velkými daty.
V tomto blogu se podíváme na to, jak nastavit základní prostředí presto pomocí serveru Docker ze souboru tar. Jako zdroj dat se zaměříme na zdroj dat MySQL, ale může to být jakýkoli jiný populární RDBMS.
Spuštění Presto v prostředí Big Data
Než začneme, pojďme se rychle podívat na jeho hlavní principy architektury. Presto je alternativou k nástrojům, které dotazují HDFS pomocí kanálů úloh MapReduce – jako je Hive. Na rozdíl od Hive Presto nepoužívá MapReduce. Presto běží se speciálním modulem pro provádění dotazů s operátory na vysoké úrovni a zpracováním v paměti.
Na rozdíl od Hive Presto může streamovat data přes všechny fáze najednou a současně spouštět datové bloky. Je navržen tak, aby spouštěl ad-hoc analytické dotazy na jednotlivé nebo distribuované heterogenní zdroje dat. Může oslovit platformu Hadoop a dotazovat se na relační databáze nebo jiná úložiště dat, jako jsou ploché soubory.
Presto používá standardní ANSI SQL včetně agregací, spojení nebo funkcí analytického okna. SQL je dobře známý a mnohem jednodušší na použití ve srovnání s MapReduce napsaným v Javě.
Nasazení aplikace Presto do Dockeru
Základní konfiguraci Presto lze nasadit s předem nakonfigurovaným obrazem Docker nebo tarballem serveru Presto.
Docker server a kontejnery Presto CLI lze snadno nasadit pomocí:
docker run -d -p 127.0.0.1:8080:8080 --name presto starburstdata/presto
docker exec -it presto presto-cliMůžete si vybrat mezi dvěma verzemi serveru Presto. Komunitní verze a Enterprise verze od Starburst. Protože jej budeme provozovat v neprodukčním prostředí sandbox, použijeme v tomto článku verzi Apache.
Předběžné požadavky
Presto je implementováno výhradně v Javě a vyžaduje instalaci JVM do vašeho systému. Běží na OpenJDK i Oracle Java. Minimální verze je Java 8u151 nebo Java 11.
Pro stažení JAVA JDK navštivte https://openjdk.java.net/ nebo https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Verzi Javy můžete zkontrolovat pomocí
$ java -version
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.222-b10, mixed mode)Instalace Presto
Pro instalaci Presto si stáhneme server tar a spustitelný soubor Presto CLI jar.
Tarball bude obsahovat jeden adresář nejvyšší úrovně, presto-server-0.223, který budeme nazývat instalační adresář.
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.223/presto-server-0.223.tar.gz
$ tar -xzvf presto-server-0.223.tar.gz
$ cd presto-server-0.223/
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.223/presto-cli-0.223-executable.jar
$ mv presto-cli-0.223-executable.jar presto
$ chmod +x prestoPresto navíc potřebuje datový adresář pro ukládání protokolů atd.
Je doporučeno vytvořit datový adresář mimo instalační adresář.
$ mkdir -p ~/data/presto/Toto místo je místem, kde začínáme odstraňování problémů.
Konfigurace Presto
Než spustíme naši první instanci, musíme vytvořit spoustu konfiguračních souborů. Začněte vytvořením adresáře etc/ v instalačním adresáři. Toto umístění bude obsahovat následující konfigurační soubory:
atd/
- Vlastnosti uzlu – konfigurace prostředí uzlu
- JVM Config (jvm.config) – konfigurace Java Virtual Machine
- Vlastnosti konfigurace (config.properties) – konfigurace serveru Presto
- Vlastnosti katalogu – konfigurace pro konektory (zdroje dat)
- Vlastnosti protokolu – Konfigurace protokolů
Níže naleznete základní konfiguraci pro spuštění sandboxu Presto. Další podrobnosti naleznete v dokumentaci.
vi etc/config.properties
Config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = https://localhost:8080
vi etc/jvm.config
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
vi etc/log.properties
com.facebook.presto = INFOvi etc/node.properties
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/bartez/data/prestoZákladní struktura etc/ může vypadat následovně:

Dalším krokem je nastavení konektoru MySQL.
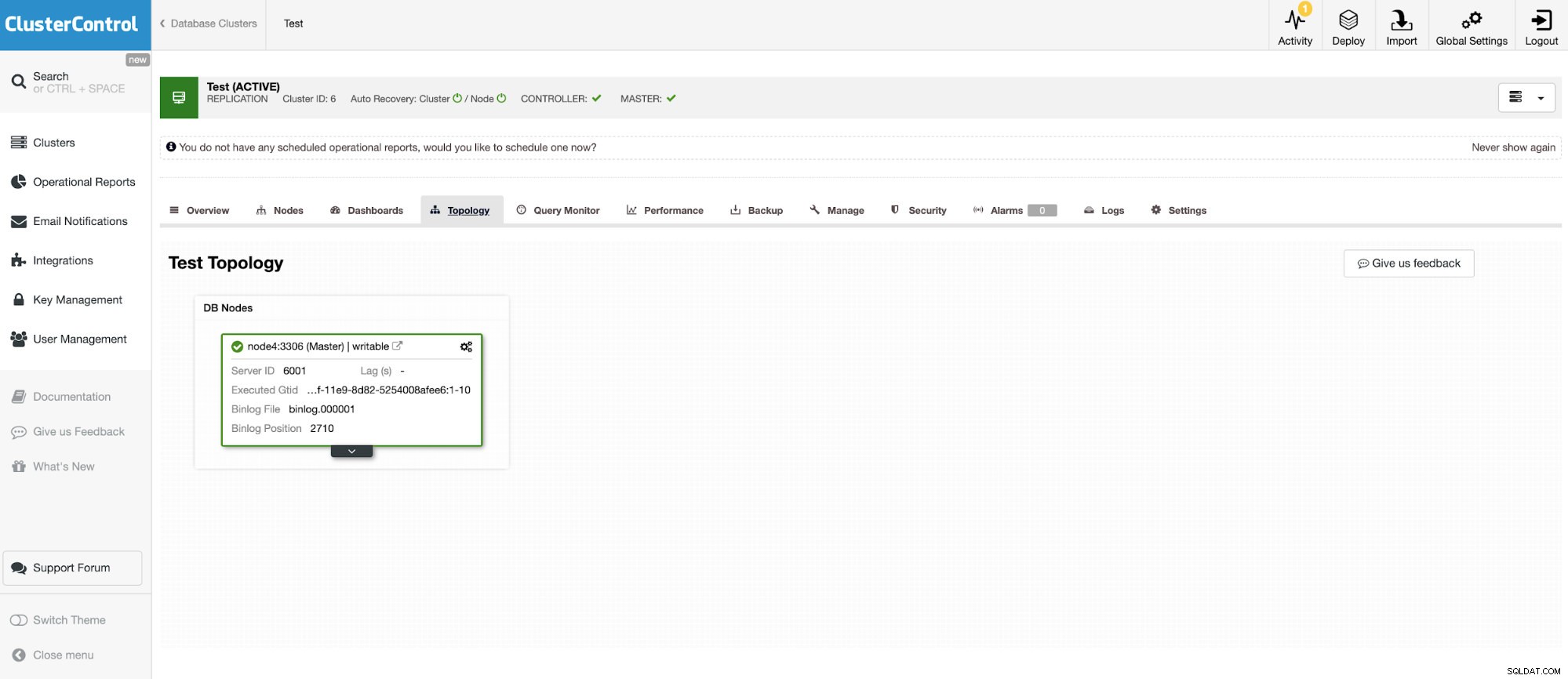
Připojíme se k jednomu ze 3 uzlů MariaDB Cluster.
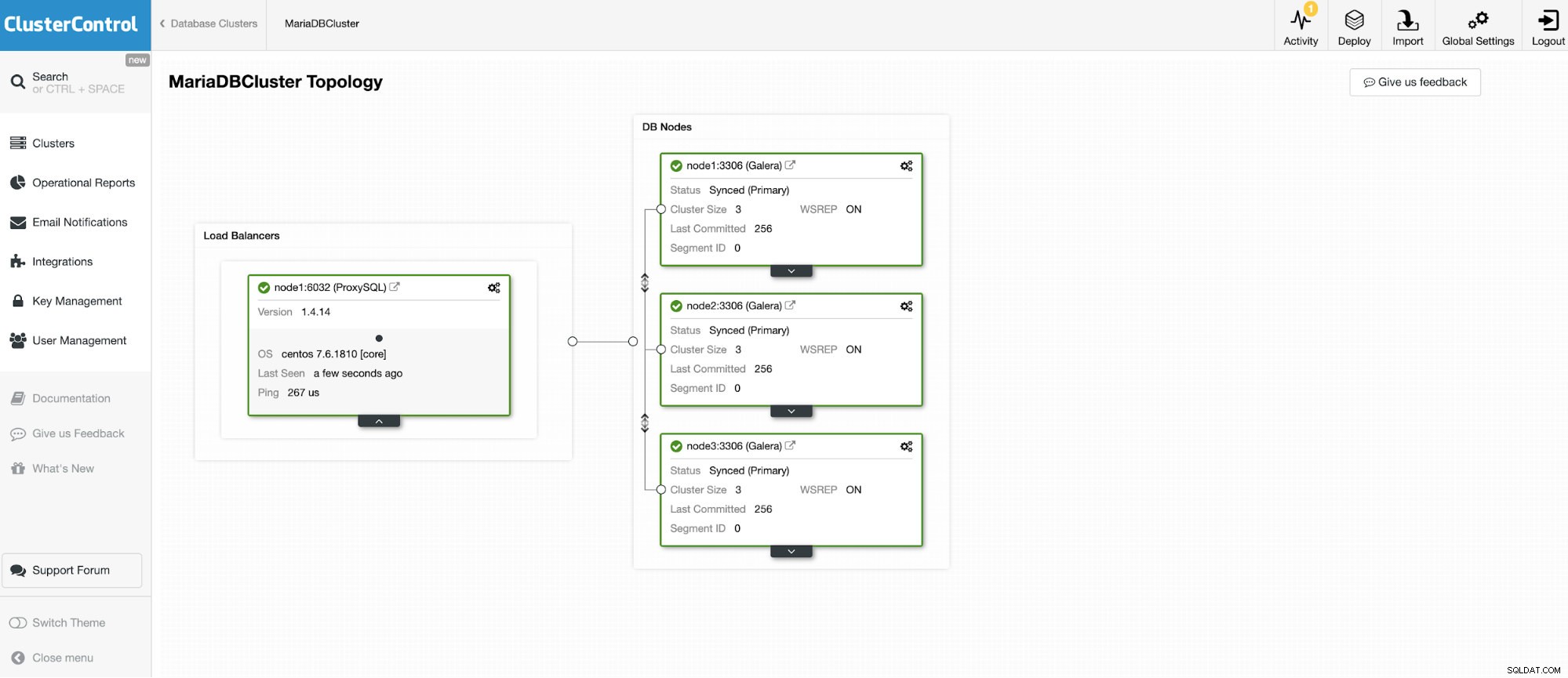
A další samostatná instance se systémem Oracle MySQL 5.7.
Konektor MySQL umožňuje dotazování a vytváření tabulek v externí databázi MySQL. To lze použít ke spojení dat mezi různými systémy, jako je MariaDB a MySQL od společnosti Oracle.
Presto používá zásuvné konektory a konfigurace je velmi snadná. Chcete-li nakonfigurovat konektor MySQL, vytvořte soubor vlastností katalogu v etc/catalog s názvem například mysql.properties, abyste konektor MySQL připojili jako katalog mysql. Každý ze souborů představuje připojení k jinému serveru. V tomto případě máme dva soubory:
vi etc/catalog/mysq.properties:
connector.name=mysql
connection-url=jdbc:mysql://node1.net:3306
connection-user=bart
connection-password=secretvi etc/catalog/mysq2.properties
connector.name=mysql
connection-url=jdbc:mysql://node4.net:3306
connection-user=bart2
connection-password=secretSpuštění Presto
Když je vše nastaveno, je čas spustit instanci Presto. Chcete-li spustit presto, přejděte do adresáře bin v rámci instalace preso a spusťte následující:
$ bin/launcher start
Started as 18363Pro zastavení Presto run
$ bin/launcher stopNyní, když je server v provozu, můžeme se připojit k Presto pomocí CLI a dotazovat se na databázi MySQL.
Chcete-li spustit konzolu Presto, spusťte:
./presto --server localhost:8080 --catalog mysql --schema employeesNyní můžeme naše databáze dotazovat pomocí CLI.
presto:mysql> select * from mysql.employees.departments;
dept_no | dept_name
---------+--------------------
d009 | Customer Service
d005 | Development
d002 | Finance
d003 | Human Resources
d001 | Marketing
d004 | Production
d006 | Quality Management
d008 | Research
d007 | Sales
(9 rows)
Query 20190730_232304_00019_uq3iu, FINISHED, 1 node
Splits: 17 total, 17 done (100,00%)
0:00 [9 rows, 0B] [81 rows/s, 0B/s]
Obě databáze MariaDB cluster a MySQL byly napájeny databází zaměstnanců.
wget https://github.com/datacharmer/test_db/archive/master.zip
mysql -uroot -psecret < employees.sqlStav dotazu je také viditelný ve webové konzoli Presto:https://localhost:8080/ui/#
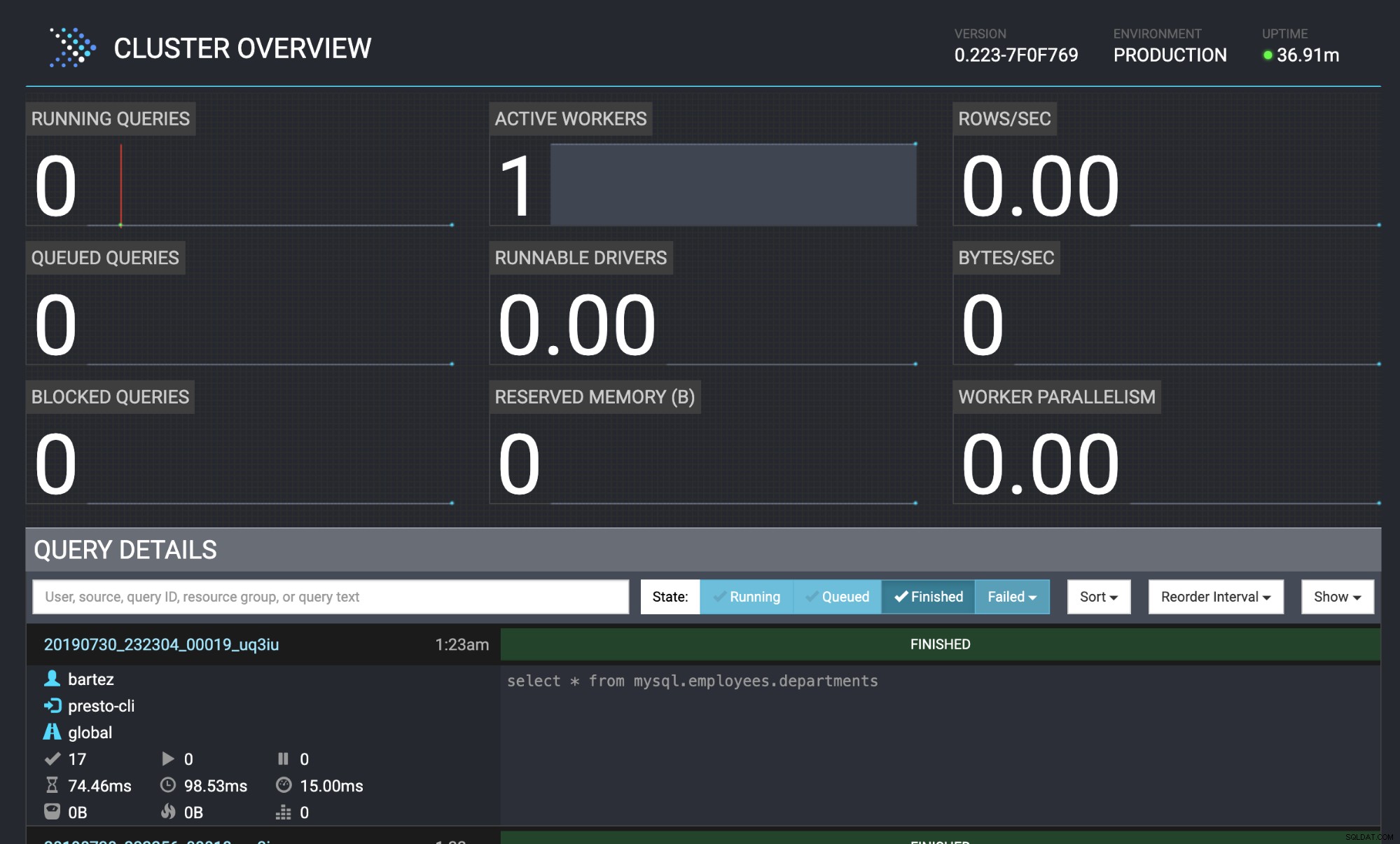 Přehled clusteru Presto
Přehled clusteru Presto Závěr
Mnoho známých společností (jako Airbnb, Netflix, Twitter) používá Presto pro výkon s nízkou latencí. Je to bezpochyby velmi zajímavý software, který může eliminovat potřebu spouštění těžkých procesů ETL datových skladů. V tomto blogu jsme se jen krátce podívali na konektor MySQL, ale můžete jej použít k analýze dat z HDFS, úložišť objektů, RDBMS (SQL Server, Oracle, PostgreSQL), Kafka, Cassandra, MongoDB a mnoha dalších.