Od vydání ClusterControl 1.2.11 v roce 2015 je MariaDB MaxScale podporována jako nástroj pro vyrovnávání zatížení databáze. V průběhu let MaxScale rostl a dospěl a přidal několik bohatých funkcí. Nedávno byla vydána MariaDB MaxScale 2.2 a zavádí několik nových funkcí včetně správy převzetí služeb při selhání replikačního clusteru.
MariaDB MaxScale umožňuje nasazení master/slave s vysokou dostupností, automatickým převzetím služeb při selhání, ručním přepínáním a automatickým opětovným připojením. Pokud master selže, MariaDB MaxScale může automaticky povýšit nejaktuálnější slave na master. Pokud je poškozený master obnoven, MariaDB MaxScale jej může automaticky překonfigurovat jako slave k novému masteru. Kromě toho mohou administrátoři provést ruční přepnutí a změnit master na vyžádání.
V našich předchozích blozích jsme diskutovali o tom, jak nasadit MaxScale pomocí ClusterControl a také o nasazení MariaDB MaxScale na Docker. Pro ty, kteří ještě nejsou obeznámeni s MariaDB MaxScale, je to pokročilý, plug-in, databázový proxy pro databázové servery MariaDB. Maxscale sedí mezi klientskými aplikacemi a databázovými servery, směruje klientské dotazy a odpovědi serveru. Také monitoruje servery a rychle zaznamenává jakékoli změny stavu serveru nebo topologie replikace.
Ačkoli Maxscale sdílí některé vlastnosti jiných technologií pro vyvažování zátěže, jako je ProxySQL, tato nová funkce převzetí služeb při selhání (která je součástí mechanismu monitorování a autodetekce) vyniká. V tomto blogu budeme diskutovat o této vzrušující nové funkci Maxscale.
Přehled mechanismu MariaDB MaxScale Failover Mechanismu
Hlavní detekce
Monitor nyní s menší pravděpodobností náhle změní hlavní server, i když jiný server má více podřízených serverů než aktuální hlavní server. DBA může vynutit opětovný výběr hlavního serveru nastavením aktuálního hlavního serveru pouze pro čtení nebo odstraněním všech jeho podřízených zařízení, pokud je hlavní zařízení mimo provoz.
Pouze jeden server může mít příznak stavu hlavního serveru současně, a to i v nastavení s více servery. Ostatním serverům ve skupině multimaster jsou přiřazeny příznaky stavu Relay Master a Slave.
Přepnutí nového hlavního automatického výběru
Příkaz přepnutí lze nyní volat pouze s názvem instance monitoru jako parametrem. V tomto případě monitor automaticky vybere server pro propagaci.
Detekce zpoždění replikace
Měření zpoždění replikace nyní jednoduše čte Seconds_Behind_Master -pole výstupu stavu slave zařízení. Slave vypočítá tuto hodnotu porovnáním časové značky v události binlog, kterou slave aktuálně zpracovává, s vlastními hodinami slave. Pokud má slave více připojení slave, použije se nejmenší zpoždění.
Automatické přepnutí po zjištění nedostatku místa na disku
S nejnovějšími verzemi serveru MariaDB může nyní monitor zkontrolovat místo na disku na backendu a zjistit, zda na serveru dochází. Když k tomu dojde, monitor lze nastavit tak, aby se automaticky přepínal z hlavního zařízení s nedostatkem místa na disku. Slave lze také nastavit do režimu údržby. Prostor na disku je také faktorem, který se bere v úvahu při výběru nového hlavního serveru, který bude podporován.
Další informace naleznete v části switchover_on_low_disk_space a maintenance_on_low_disk_space.
Funkce resetování replikace
reset-replication příkaz monitor odstraní všechna připojení slave a binární protokoly a poté nastaví replikaci. Užitečné, když jsou data synchronizována, ale gtid nikoli.
Zpracování naplánovaných událostí v režimu Failover/Switchover/Rejoin
Události serveru spouštěné vláknem plánovače událostí jsou nyní zpracovávány během operací modifikace clusteru. Další informace viz handle_server_events.
Externí hlavní podpora
Monitor dokáže zjistit, zda se server v klastru replikuje z externího hlavního serveru (server, který není monitorován monitorem MaxScale). Pokud je replikující se server hlavním serverem clusteru, pak se samotný cluster považuje za externího hlavního serveru.
Pokud dojde k převzetí služeb při selhání/přepnutí, je nový hlavní server nastaven na replikaci z externího hlavního serveru clusteru. Uživatelské jméno a heslo pro replikaci jsou definovány v Replication_user a Replication_password. Použitá adresa a port jsou ty, které jsou zobrazeny příkazem SHOW ALL SLAVES STATUS na starém hlavním serveru clusteru. V případě přepnutí se starý hlavní server také přestane replikovat z externího serveru, aby byla zachována topologie.
Po převzetí služeb při selhání se nový hlavní server replikuje z externího hlavního serveru. Pokud se starý hlavní server, který selhal, vrátí do režimu online, replikuje se také z externího serveru. Chcete-li situaci normalizovat, buď zapněte auto_rejoin, nebo ručně proveďte opětovné připojení. Toto přesměruje starý master na aktuální master clusteru.
Jak je převzetí služeb při selhání užitečné a použitelné?
Failover vám pomůže minimalizovat prostoje, provádět každodenní údržbu nebo zvládnout katastrofální a nechtěnou údržbu, ke které někdy může dojít v nešťastných dobách. Se schopností MaxScale izolovat klientské aplikace od backendových databázových serverů přidává cenné funkce, které pomáhají minimalizovat prostoje.
Monitorovací plugin MaxScale nepřetržitě monitoruje stav backendových databázových serverů. Směrovací zásuvný modul MaxScale pak používá tyto stavové informace k tomu, aby vždy směroval dotazy na backendové databázové servery, které jsou v provozu. Je pak schopen posílat dotazy do backendových databázových clusterů, i když některé servery clusteru procházejí údržbou nebo dojde k selhání.
Vysoká konfigurovatelnost MaxScale umožňuje, aby změny v konfiguraci clusteru zůstaly transparentní pro klientské aplikace. Pokud je například potřeba administrativně přidat nový server do clusteru master-slave nebo z něj odebrat, můžete jednoduše přidat konfiguraci MaxScale do seznamu serverů zásuvných modulů monitoru a routeru prostřednictvím konzoly CLI maxadmin. Klientská aplikace nebude o této změně vůbec vědět a bude nadále odesílat databázové dotazy na naslouchací port MaxScale.
Nastavení databázového serveru v údržbě je jednoduché a snadné. Jednoduše proveďte následující příkaz pomocí maxctrl a MaxScale zastaví odesílání jakýchkoli dotazů na tento server. Například,
maxctrl: set server DB_785 maintenance
OKPoté zkontrolujte stav serverů následovně,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬──────────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Maintenance, Running │ 0-43001-70 │
└────────┴───────────────┴──────┴─────────────┴──────────────────────┴────────────┘Jakmile je v režimu údržby, MaxScale přestane směrovat všechny nové požadavky na server. U aktuálních požadavků MaxScale neukončí tyto relace, ale spíše mu umožní dokončit jejich provádění a nepřeruší žádné běžící dotazy v režimu údržby. Pamatujte také, že režim údržby není trvalý. Pokud se MaxScale restartuje, když je uzel v režimu údržby, nová instance MariaDB MaxScale nebude tento režim respektovat. Pokud je více instancí MariaDB MaxScale nakonfigurováno pro použití uzlu, musí být nastaven režim údržby v každé instanci MariaDB MaxScale. Pokud však server používá více služeb v rámci jedné instance MariaDB MaxScale, stačí na serveru nastavit režim údržby pouze jednou, aby všechny služby zaznamenaly změnu režimu.
Až budete s údržbou hotovi, stačí vymazat server pomocí následujícího příkazu. Například,
maxctrl: clear server DB_785 maintenance
OKChcete-li zkontrolovat, zda je nastaveno zpět do normálu, stačí spustit příkaz list servers .
Prostřednictvím uživatelského rozhraní ClusterControl můžete také použít určité administrativní akce. Podívejte se na ukázkový snímek obrazovky níže:
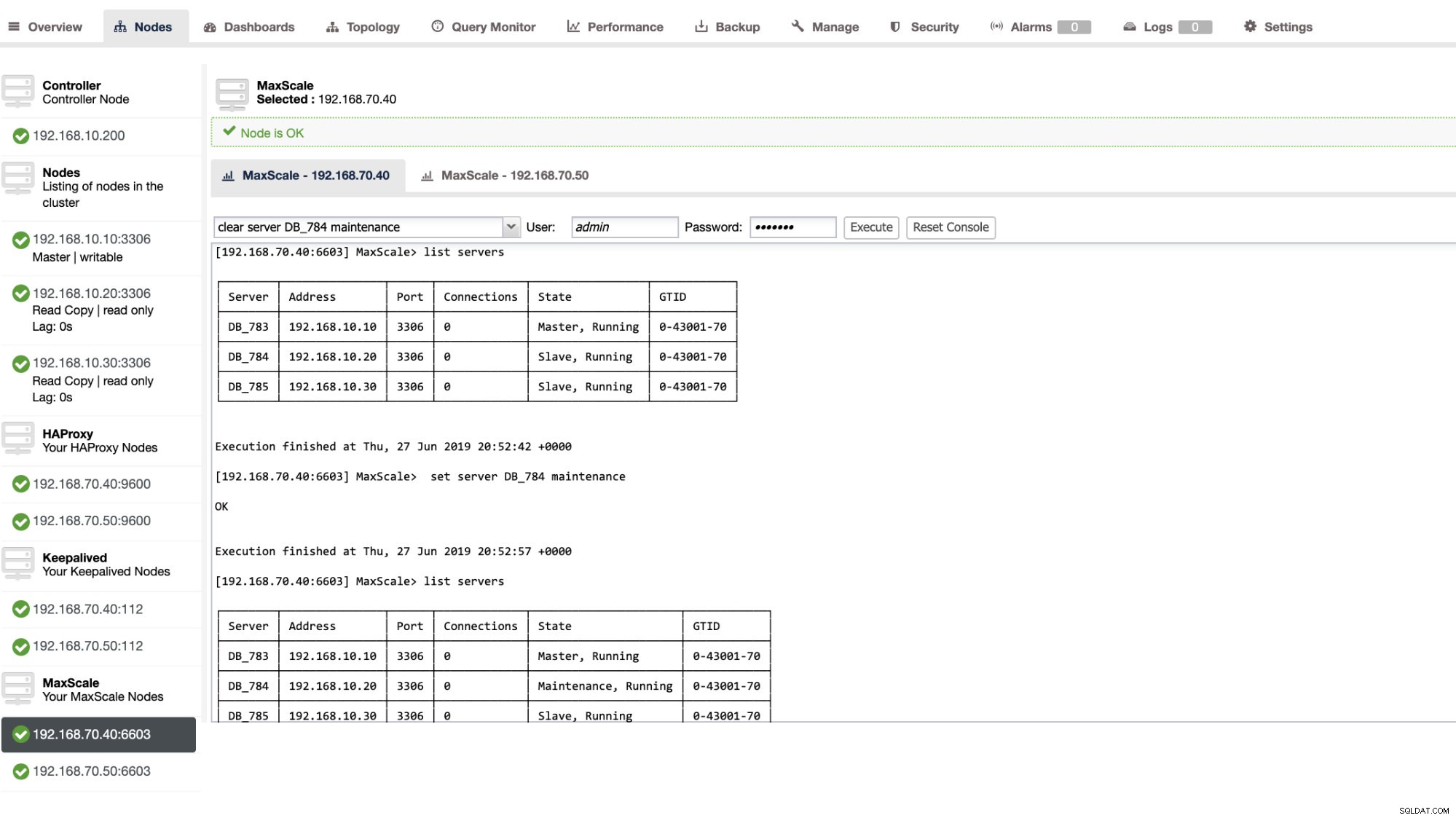
MaxScale Failover v akci
Automatické převzetí služeb při selhání
Přepnutí při selhání MaxScale od MariaDB funguje velmi efektivně a podle očekávání překonfiguruje slave zařízení. V tomto testu máme následující sadu konfiguračních souborů, která byla vytvořena a spravována ClusterControl. Viz níže:
[replication_monitor]
type=monitor
servers=DB_783,DB_784,DB_785
disk_space_check_interval=1000
disk_space_threshold=/:85
detect_replication_lag=true
enforce_read_only_slaves=true
failcount=3
auto_failover=1
auto_rejoin=true
monitor_interval=300
password=725DE70F196694B277117DC825994D44
user=maxscalecc
replication_password=5349E1268CC4AF42B919A42C8E52D185
replication_user=rpl_user
module=mariadbmonVezměte na vědomí, že pouze auto_failover a auto_rejoin jsou proměnné, které jsem přidal, protože ClusterControl to ve výchozím nastavení nepřidá, jakmile nastavíte nástroj pro vyrovnávání zatížení MaxScale (podívejte se na tento blog o tom, jak nastavit MaxScale pomocí ClusterControl). Nezapomeňte, že jakmile použijete změny v konfiguračním souboru, musíte restartovat MariaDB MaxScale. Stačí běžet,
systemctl restart maxscalea můžete jít.
Než budete pokračovat v testu převzetí služeb při selhání, zkontrolujme nejprve stav clusteru:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Vypadá skvěle!
Zabil jsem mistra pouze čistým zabijáckým příkazem KILL -9 $(pidof mysqld) v mém hlavním uzlu a k žádnému překvapení jsem viděl, že monitor si toho rychle všiml a spustil přepnutí při selhání. Prohlédněte si protokoly takto:
2019-06-28 06:39:14.306 error : (mon_log_connect_error): Monitor was unable to connect to server DB_783[192.168.10.10:3306] : 'Can't connect to MySQL server on '192.168.10.10' (115)'
2019-06-28 06:39:14.329 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: master_down. [Master, Running] -> [Down]
2019-06-28 06:39:14.329 warning: (handle_auto_failover): Master has failed. If master status does not change in 2 monitor passes, failover begins.
2019-06-28 06:39:15.011 notice : (select_promotion_target): Selecting a server to promote and replace 'DB_783'. Candidates are: 'DB_784', 'DB_785'.
2019-06-28 06:39:15.011 warning: (warn_replication_settings): Slave 'DB_784' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 warning: (warn_replication_settings): Slave 'DB_785' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 notice : (select_promotion_target): Selected 'DB_784'.
2019-06-28 06:39:15.012 notice : (handle_auto_failover): Performing automatic failover to replace failed master 'DB_783'.
2019-06-28 06:39:15.017 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_784' instead of 'DB_783'.
2019-06-28 06:39:15.024 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 06:39:15.527 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_784'.
2019-06-28 06:39:15.527 notice : (handle_auto_failover): Failover 'DB_783' -> 'DB_784' performed.
2019-06-28 06:39:15.634 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 06:39:20.165 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: slave_up. [Down] -> [Slave, Running]Nyní se podívejme na zdraví jeho clusteru,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Down │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Uzel 192.168.10.10, který byl dříve hlavním, je mimo provoz. Pokusil jsem se restartovat a zjistit, zda se spustí automatické opětovné připojení, a jak jste si všimli v protokolu v čase 2019-06-28 06:39:20.165, bylo tak rychlé zachytit stav uzlu a poté automaticky nastavit konfiguraci bez problémů, aby jej DBA zapnul.
Nyní, když naposledy zkontrolujeme jeho stav, vypadá perfektně, že funguje podle očekávání. Viz níže:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Můj bývalý magistr byl opraven a obnoven a já chci přejít
Přechod na předchozího mistra také není žádný problém. Můžete to ovládat pomocí maxctrl (nebo maxadmin v předchozích verzích MaxScale) nebo prostřednictvím uživatelského rozhraní ClusterControl (jak bylo ukázáno dříve).
Podívejme se jen na předchozí stav stavu replikačního klastru dříve a chtěli jsme přepnout 192.168.10.10 (aktuálně slave) zpět do hlavního stavu. Než budeme pokračovat, možná budete muset nejprve identifikovat monitor, který budete používat. Můžete to ověřit pomocí následujícího příkazu:
maxctrl: list monitors
┌─────────────────────┬─────────┬────────────────────────┐
│ Monitor │ State │ Servers │
├─────────────────────┼─────────┼────────────────────────┤
│ replication_monitor │ Running │ DB_783, DB_784, DB_785 │
└─────────────────────┴─────────┴────────────────────────┘Jakmile jej budete mít, můžete přepnout pomocí následujícího příkazu:
maxctrl: call command mariadbmon switchover replication_monitor DB_783 DB_784
OKPoté znovu zkontrolujte stav clusteru
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Vypadá perfektně!
Protokoly vám podrobně ukážou, jak to probíhalo a jaká série jeho akcí probíhala během přepínání. Podrobnosti naleznete níže:
2019-06-28 07:03:48.064 error : (switchover_prepare): 'DB_784' is not a valid promotion target for switchover because it is already the master.
2019-06-28 07:03:48.064 error : (manual_switchover): Switchover cancelled.
2019-06-28 07:04:30.700 notice : (create_start_slave): Slave connection from DB_784 to [192.168.10.10]:3306 created and started.
2019-06-28 07:04:30.700 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_783' instead of 'DB_784'.
2019-06-28 07:04:30.708 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 07:04:31.209 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_783'.
2019-06-28 07:04:31.209 notice : (manual_switchover): Switchover 'DB_784' -> 'DB_783' performed.
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_slave. [Master, Running] -> [Slave, Running]V případě špatného přepnutí nebude pokračovat, a proto vygeneruje chybu, jak je uvedeno v protokolu výše. Takže budete v bezpečí a žádná děsivá překvapení.
Vylepšení dostupnosti MaxScale
I když je to trochu mimo téma, pokud jde o převzetí služeb při selhání, chtěl jsem sem přidat některé cenné body týkající se vysoké dostupnosti a toho, jak to souvisí s převzetím služeb při selhání MariaDB MaxScale.
Vysoká dostupnost vašeho MaxScale je důležitou součástí v případě, že váš systém spadne, dojde k poškození disku nebo poškození virtuálního počítače. Tyto situace jsou nevyhnutelné a mohou ovlivnit stav vašeho automatického nastavení převzetí služeb při selhání, když nastanou tyto neočekávané cykly údržby.
Pro prostředí typu replikačního clusteru je to velmi výhodné a vysoce doporučeno pro konkrétní nastavení MaxScale. Účelem toho je, že pouze jedné instanci MaxScale by mělo být povoleno upravovat cluster v daném okamžiku. Pokud máte nastavení s Keepalived, zde jsou instance se statusem MASTER. MaxScale sám o sobě nezná svůj stav, ale pomocí maxctrl (nebo maxadmin v předchozích verzích) lze nastavit instanci MaxScale do pasivního režimu. Od verze 2.2.2 se pasivní MaxScale chová podobně jako aktivní s tím rozdílem, že neprovede převzetí služeb při selhání, přepnutí ani opětovné připojení. I ruční verze těchto příkazů skončí chybou. Rozdíly mezi pasivním a aktivním režimem se mohou v budoucnu rozšířit, takže sledujte tyto změny v MaxScale. Chcete-li to provést, postupujte takto:
maxctrl: alter maxscale passive true
OKMůžete to ověřit později spuštěním příkazu níže:
[example@sqldat.com vagrant]# maxctrl -u admin -p mariadb -h 127.0.0.1:8989 show maxscale|grep 'passive'
│ │ "passive": true, │Pokud se chcete podívat, jak nastavit vysokou dostupnost s Keepalived, podívejte se na tento příspěvek od MariaDB.
VIP manipulace
Navíc, protože MaxScale nemá vestavěné ovládání VIP, můžete použít Keepalived, který to zvládne za vás. Stačí použít adresu virtual_ipaddress přiřazenou uzlu stavu MASTER. To pravděpodobně přijde se správou virtuálních IP, stejně jako MHA s proměnnou master_failover_script. Jak již bylo zmíněno, podívejte se na tento blogový příspěvek Keepalived with MaxScale od MariaDB.
Závěr
MariaDB MaxScale je bohatý na funkce a má spoustu funkcí, které se neomezují pouze na proxy a vyrovnávání zatížení, ale také nabízí mechanismus převzetí služeb při selhání, který velké organizace hledají. Je to téměř univerzální software, ale samozřejmě přichází s omezeními, která určitá aplikace může potřebovat na rozdíl od jiných vyrovnávačů zátěže, jako je ProxySQL.
ClusterControl také nabízí automatické přepnutí při selhání a hlavní automatický detekční mechanismus, plus obnovení clusteru a uzlů s možností nasazení Maxscale a dalších technologií pro vyrovnávání zátěže.
Každý z těchto nástrojů má své rozmanité funkce a funkce, ale MariaDB MaxScale je dobře podporována v rámci ClusterControl a lze ji nasadit proveditelně spolu s Keepalived, HAProxy, což vám pomůže urychlit váš každodenní rutinní úkol.