Galera Cluster se svou (prakticky) synchronní replikací se běžně používá v mnoha různých typech prostředí. Škálování přidáním nových uzlů není těžké (nebo stačí jen pár kliknutí, když používáte ClusterControl).
Hlavním problémem synchronní replikace je synchronní část, která často vede k tomu, že celý cluster je tak rychlý, jako jeho nejpomalejší uzel. Jakýkoli zápis provedený na clusteru musí být replikován do všech uzlů a certifikován na nich. Pokud se z jakéhokoli důvodu tento proces zpomalí, může to vážně ovlivnit schopnost clusteru přizpůsobit se zápisům. Poté se spustí řízení toku, aby se zajistilo, že nejpomalejší uzel může stále držet krok se zatížením. Díky tomu je u některých běžných scénářů, které se dějí v prostředí reálného světa, docela složité.
Nejprve si proberme geograficky distribuované zotavení po havárii. Jasně, můžete provozovat clustery přes Wide Area Network, ale zvýšená latence bude mít významný dopad na výkon clusteru. To vážně omezuje možnost použití takového nastavení, zejména na delší vzdálenosti, kdy je latence vyšší.
Další docela běžný případ použití - testovací prostředí pro upgrade hlavní verze. Není dobrý nápad míchat různé verze uzlů MariaDB Galera Cluster ve stejném clusteru, i když je to možné. Na druhou stranu migrace na novější verzi vyžaduje podrobné testy. V ideálním případě by bylo testováno čtení i zápis. Jedním ze způsobů, jak toho dosáhnout, je vytvořit samostatný cluster Galera a spustit testy, ale rádi byste testy spouštěli v prostředí co nejblíže produkci. Po zřízení lze cluster použít pro testy s dotazy z reálného světa, ale bylo by těžké vygenerovat pracovní zatížení, které by se blížilo produkčnímu zatížení. Do takového testovacího systému nemůžete přesunout část produkčního provozu, protože data nejsou aktuální.
Nakonec samotná migrace. Znovu, co jsme si řekli dříve, i když je možné smíchat staré a nové verze uzlů Galera ve stejném clusteru, není to nejbezpečnější způsob.
Naštěstí nejjednodušším řešením všech těchto tří problémů by bylo propojit samostatné clustery Galera asynchronní replikací. Co z toho dělá tak dobré řešení? No, je to asynchronní, takže to neovlivňuje replikaci Galery. Neexistuje žádné řízení toku, takže výkon „master“ clusteru nebude ovlivněn výkonem „slave“ clusteru. Jako u každé asynchronní replikace se může objevit zpoždění, ale pokud zůstane v přijatelných mezích, může fungovat naprosto bez problémů. Musíte také mít na paměti, že v dnešní době lze asynchronní replikaci paralelizovat (více vláken může spolupracovat na zvýšení šířky pásma) a ještě více snížit zpoždění replikace.
V tomto příspěvku na blogu probereme, jaké jsou kroky k nasazení asynchronní replikace mezi clustery MariaDB Galera.
Jak nakonfigurovat asynchronní replikaci mezi clustery MariaDB Galera?
Nejprve musíme nasadit cluster. Pro naše účely nastavíme tříuzlový cluster. Nastavení omezíme na minimum, nebudeme tedy diskutovat o složitosti aplikační a proxy vrstvy. Proxy vrstva může být velmi užitečná pro zpracování úloh, pro které chcete nasadit asynchronní replikaci – přesměrování podmnožiny provozu pouze pro čtení do testovacího clusteru, což pomáhá v situaci zotavení po havárii, když „hlavní“ cluster není dostupný přesměrováním provoz do clusteru DR. Existuje mnoho proxy, které můžete vyzkoušet, v závislosti na vašich preferencích - HAProxy, MaxScale nebo ProxySQL - všechny lze v takových nastaveních použít a v závislosti na případu vám některé z nich mohou pomoci řídit provoz.
Konfigurace zdrojového clusteru
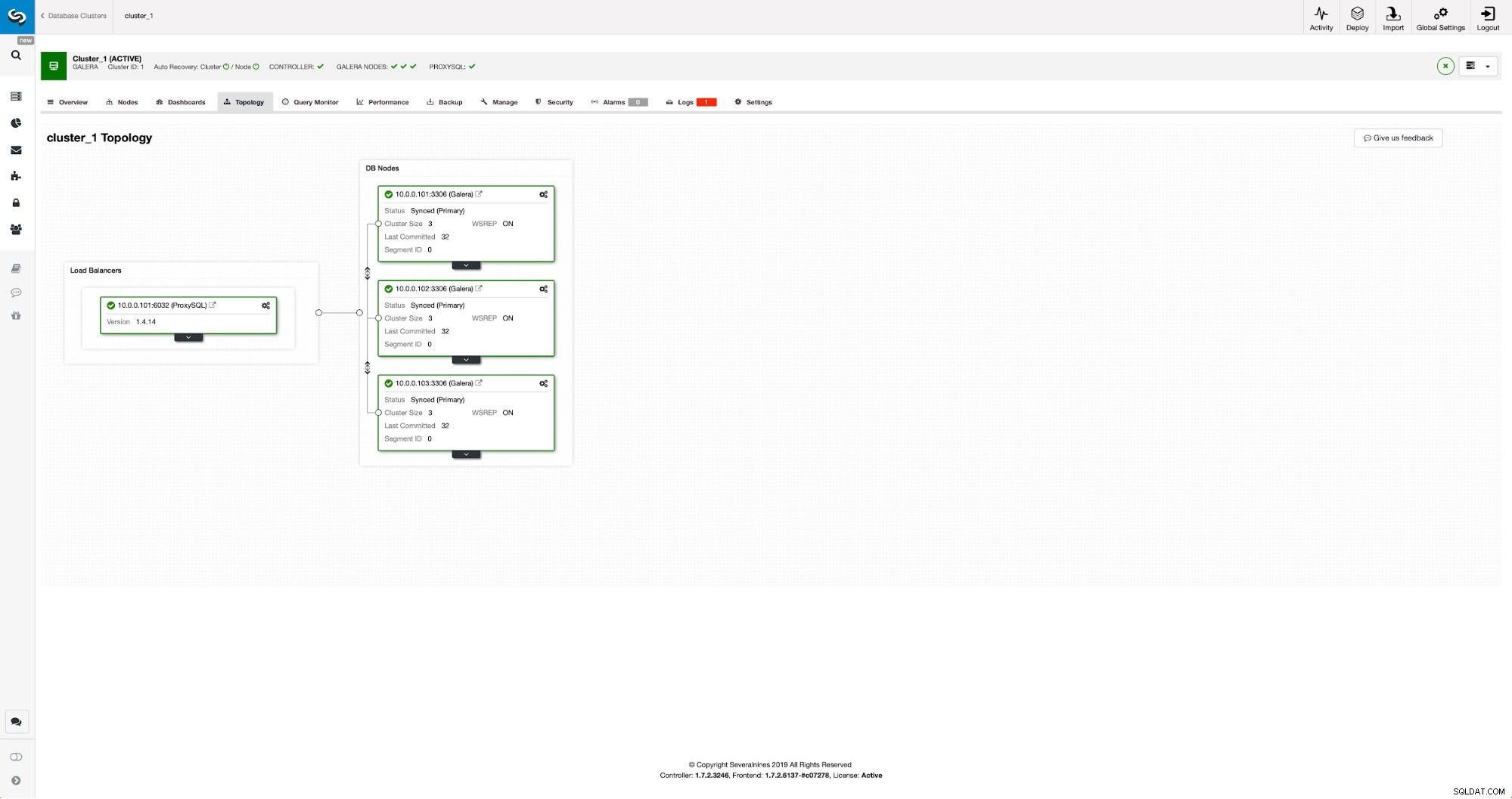
Náš cluster se skládá ze tří uzlů MariaDB 10.3, také jsme nasadili ProxySQL, abychom provedli rozdělení čtení a zápisu a distribuovali provoz mezi všechny uzly v clusteru. Toto není nasazení na produkční úrovni, k tomu bychom museli nasadit více uzlů ProxySQL a nad nimi Keepalived. Pro naše účely to stále stačí. Abychom mohli nastavit asynchronní replikaci, budeme muset mít v našem clusteru povolený binární protokol. Alespoň jeden uzel, ale je lepší ponechat jej povolený na všech pro případ, že by selhal jediný uzel s povoleným binlogem – pak chcete mít v clusteru v provozu další uzel, který můžete vypnout.
Když povolujete binární protokol, ujistěte se, že jste nakonfigurovali rotaci binárního protokolu tak, aby byly staré protokoly v určitém okamžiku odstraněny. Budete používat binární formát protokolu ROW. Měli byste se také ujistit, že máte nakonfigurováno a používáno GTID – bude to velmi užitečné, když budete muset znovu podřídit svůj „slave“ cluster nebo pokud potřebujete povolit replikaci s více vlákny. Protože se jedná o cluster Galera, chcete mít nakonfigurováno „wsrep_gtid_domain_id“ a povoleno „wsrep_gtid_mode“. Tato nastavení zajistí, že pro provoz přicházející z clusteru Galera budou generována GTID. Více informací naleznete v dokumentaci. Jakmile je toto vše hotovo, můžete pokračovat v nastavení druhého clusteru.
Nastavení cílového klastru
Vzhledem k tomu, že v současné době neexistuje žádný cílový cluster, musíme začít s jeho nasazením. Těmito kroky se nebudeme podrobně zabývat, pokyny najdete v dokumentaci. Obecně řečeno, proces se skládá z několika kroků:
- Nakonfigurujte úložiště MariaDB
- Nainstalujte balíčky MariaDB 10.3
- Nakonfigurujte uzly tak, aby vytvořily klastr
Na začátku začneme pouze s jedním uzlem. Všechny je můžete nastavit tak, aby vytvořily shluk, ale pak byste je měli zastavit a pro další krok použít pouze jeden. Tento jeden uzel se stane otrokem původního clusteru. K jeho poskytnutí použijeme mariabackup. Poté nakonfigurujeme replikaci.
Nejprve si musíme vytvořit adresář, kam budeme zálohu ukládat:
mkdir /mnt/mariabackupPoté provedeme zálohu a vytvoříme ji v adresáři připraveném v kroku výše. Ujistěte se prosím, že pro připojení k databázi používáte správného uživatele a heslo:
mariabackup --backup --user=root --password=pass --target-dir=/mnt/mariabackup/Dále musíme zkopírovat záložní soubory do prvního uzlu ve druhém clusteru. Použili jsme k tomu scp, můžete použít, co chcete - rsync, netcat, cokoli, co bude fungovat.
scp -r /mnt/mariabackup/* 10.0.0.104:/root/mariabackup/Po zkopírování zálohy ji musíme připravit použitím souborů protokolu:
mariabackup --prepare --target-dir=/root/mariabackup/
mariabackup based on MariaDB server 10.3.16-MariaDB debian-linux-gnu (x86_64)
[00] 2019-06-24 08:35:39 cd to /root/mariabackup/
[00] 2019-06-24 08:35:39 This target seems to be not prepared yet.
[00] 2019-06-24 08:35:39 mariabackup: using the following InnoDB configuration for recovery:
[00] 2019-06-24 08:35:39 innodb_data_home_dir = .
[00] 2019-06-24 08:35:39 innodb_data_file_path = ibdata1:100M:autoextend
[00] 2019-06-24 08:35:39 innodb_log_group_home_dir = .
[00] 2019-06-24 08:35:39 InnoDB: Using Linux native AIO
[00] 2019-06-24 08:35:39 Starting InnoDB instance for recovery.
[00] 2019-06-24 08:35:39 mariabackup: Using 104857600 bytes for buffer pool (set by --use-memory parameter)
2019-06-24 8:35:39 0 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
2019-06-24 8:35:39 0 [Note] InnoDB: Uses event mutexes
2019-06-24 8:35:39 0 [Note] InnoDB: Compressed tables use zlib 1.2.8
2019-06-24 8:35:39 0 [Note] InnoDB: Number of pools: 1
2019-06-24 8:35:39 0 [Note] InnoDB: Using SSE2 crc32 instructions
2019-06-24 8:35:39 0 [Note] InnoDB: Initializing buffer pool, total size = 100M, instances = 1, chunk size = 100M
2019-06-24 8:35:39 0 [Note] InnoDB: Completed initialization of buffer pool
2019-06-24 8:35:39 0 [Note] InnoDB: page_cleaner coordinator priority: -20
2019-06-24 8:35:39 0 [Note] InnoDB: Starting crash recovery from checkpoint LSN=3448619491
2019-06-24 8:35:40 0 [Note] InnoDB: Starting final batch to recover 759 pages from redo log.
2019-06-24 8:35:40 0 [Note] InnoDB: Last binlog file '/var/lib/mysql-binlog/binlog.000003', position 865364970
[00] 2019-06-24 08:35:40 Last binlog file /var/lib/mysql-binlog/binlog.000003, position 865364970
[00] 2019-06-24 08:35:40 mariabackup: Recovered WSREP position: e79a3494-964f-11e9-8a5c-53809a3c5017:25740
[00] 2019-06-24 08:35:41 completed OK!V případě jakékoli chyby možná budete muset zálohu znovu spustit. Pokud vše proběhlo v pořádku, můžeme odstranit stará data a nahradit je záložními informacemi
rm -rf /var/lib/mysql/*
mariabackup --copy-back --target-dir=/root/mariabackup/
…
[01] 2019-06-24 08:37:06 Copying ./sbtest/sbtest10.frm to /var/lib/mysql/sbtest/sbtest10.frm
[01] 2019-06-24 08:37:06 ...done
[00] 2019-06-24 08:37:06 completed OK!Chceme také nastavit správného vlastníka souborů:
chown -R mysql.mysql /var/lib/mysql/Budeme se spoléhat na GTID, abychom udrželi replikaci konzistentní, takže musíme vidět, jaké bylo naposledy použité GTID v této záloze. Tyto informace lze nalézt v souboru xtrabackup_info, který je součástí zálohy:
example@sqldat.com:~/mariabackup# cat /var/lib/mysql/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000003', position '865364970', GTID of the last change '9999-1002-23012'Budeme také muset zajistit, aby podřízený uzel měl povoleny binární protokoly spolu s „log_slave_updates“. V ideálním případě to bude povoleno na všech uzlech v druhém klastru – pro případ, že by „slave“ uzel selhal a vy byste museli nastavit replikaci pomocí jiného uzlu v podřízeném klastru.
Posledním krokem, který musíme udělat, než budeme moci nastavit replikaci, je vytvořit uživatele, kterého použijeme ke spuštění replikace:
MariaDB [(none)]> CREATE USER 'repuser'@'10.0.0.104' IDENTIFIED BY 'reppass';
Query OK, 0 rows affected (0.077 sec)MariaDB [(none)]> GRANT REPLICATION SLAVE ON *.* TO 'repuser'@'10.0.0.104';
Query OK, 0 rows affected (0.012 sec)To je vše, co potřebujeme. Nyní můžeme spustit první uzel ve druhém shluku, náš to-být-slave:
galera_new_clusterJakmile bude spuštěn, můžeme vstoupit do MySQL CLI a nakonfigurovat jej tak, aby se stal otrokem, pomocí pozice GITD, kterou jsme našli o pár kroků dříve:
mysql -ppassMariaDB [(none)]> SET GLOBAL gtid_slave_pos = '9999-1002-23012';
Query OK, 0 rows affected (0.026 sec)Jakmile to bude hotové, můžeme konečně nastavit replikaci a spustit ji:
MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.016 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)V tomto okamžiku máme Galera Cluster skládající se z jednoho uzlu. Tento uzel je také slave původního clusteru (konkrétně jeho hlavním uzlem je uzel 10.0.0.101). Pro připojení k dalším uzlům použijeme SST, ale aby to fungovalo, musíme se nejprve ujistit, že konfigurace SST je správná – mějte prosím na paměti, že jsme právě nahradili všechny uživatele v našem druhém clusteru obsahem zdrojového clusteru. Nyní musíte zajistit, aby konfigurace „wsrep_sst_auth“ druhého clusteru odpovídala konfiguraci prvního clusteru. Jakmile to uděláte, můžete začít zbývající uzly jeden po druhém a měly by se připojit ke stávajícímu uzlu (10.0.0.104), získat data přes SST a vytvořit cluster Galera. Nakonec byste měli skončit se dvěma clustery, každý se třemi uzly, s asynchronním replikačním propojením napříč nimi (od 10.0.0.101 do 10.0.0.104 v našem příkladu). Správnost replikace můžete potvrdit kontrolou hodnoty:
MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 106 |
+----------------------+-------+
1 row in set (0.001 sec)MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 114 |
+----------------------+-------+
1 row in set (0.001 sec)Jak nakonfigurovat asynchronní replikaci mezi clustery MariaDB Galera pomocí ClusterControl?
V době vydání tohoto blogu nemá ClusterControl funkci pro konfiguraci asynchronní replikace napříč více clustery, pracujeme na tom, když toto píšu. ClusterControl však může být v tomto procesu velkou pomocí – ukážeme vám, jak můžete urychlit pracné ruční kroky pomocí automatizace poskytované ClusterControl.
Z toho, co jsme si ukázali dříve, můžeme usoudit, že toto jsou obecné kroky, které je třeba podniknout při nastavování replikace mezi dvěma clustery Galera:
- Nasaďte nový cluster Galera
- Zajištění nového clusteru pomocí dat ze starého
- Nakonfigurujte nový cluster (konfigurace SST, binární protokoly)
- Nastavte replikaci mezi starým a novým clusterem
První tři body jsou něco, co můžete snadno udělat pomocí ClusterControl i nyní. Ukážeme vám, jak na to.
Nasazení a poskytování nového clusteru MariaDB Galera pomocí ClusterControl
Výchozí situace je podobná – máme jeden cluster v provozu. Musíme nastavit druhý. Jednou z novějších funkcí ClusterControl je možnost nasadit nový cluster a zřídit jej pomocí dat ze zálohy. To je velmi užitečné pro vytváření testovacích prostředí, je to také možnost, kterou použijeme k zajištění našeho nového clusteru pro nastavení replikace. Proto prvním krokem, který uděláme, je vytvoření zálohy pomocí mariabackup:
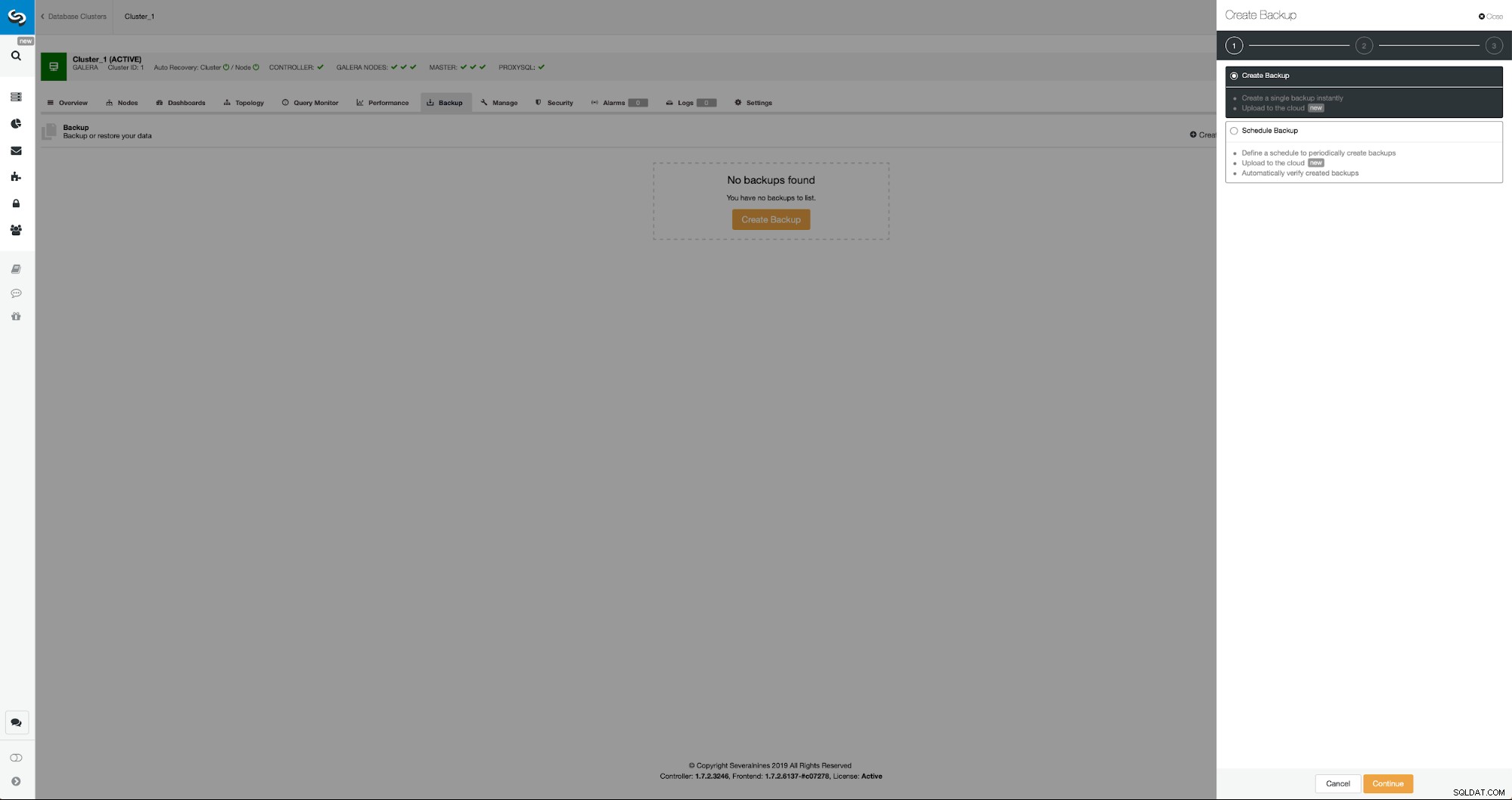
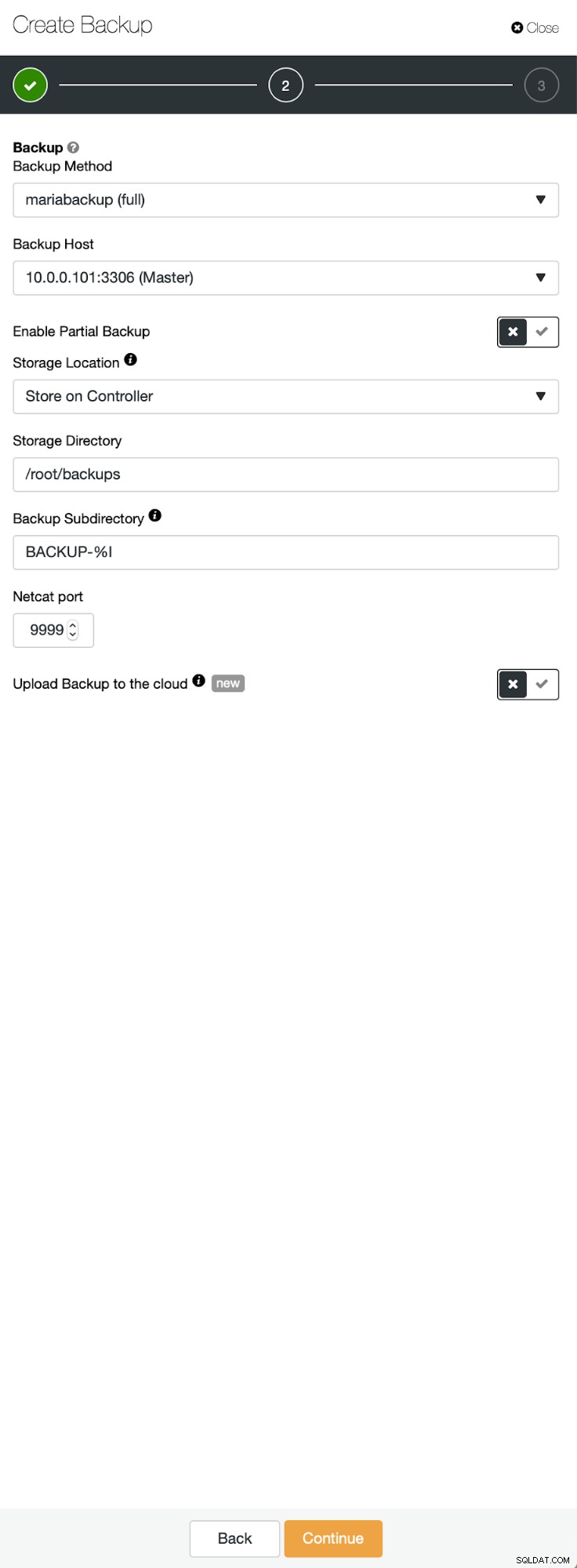
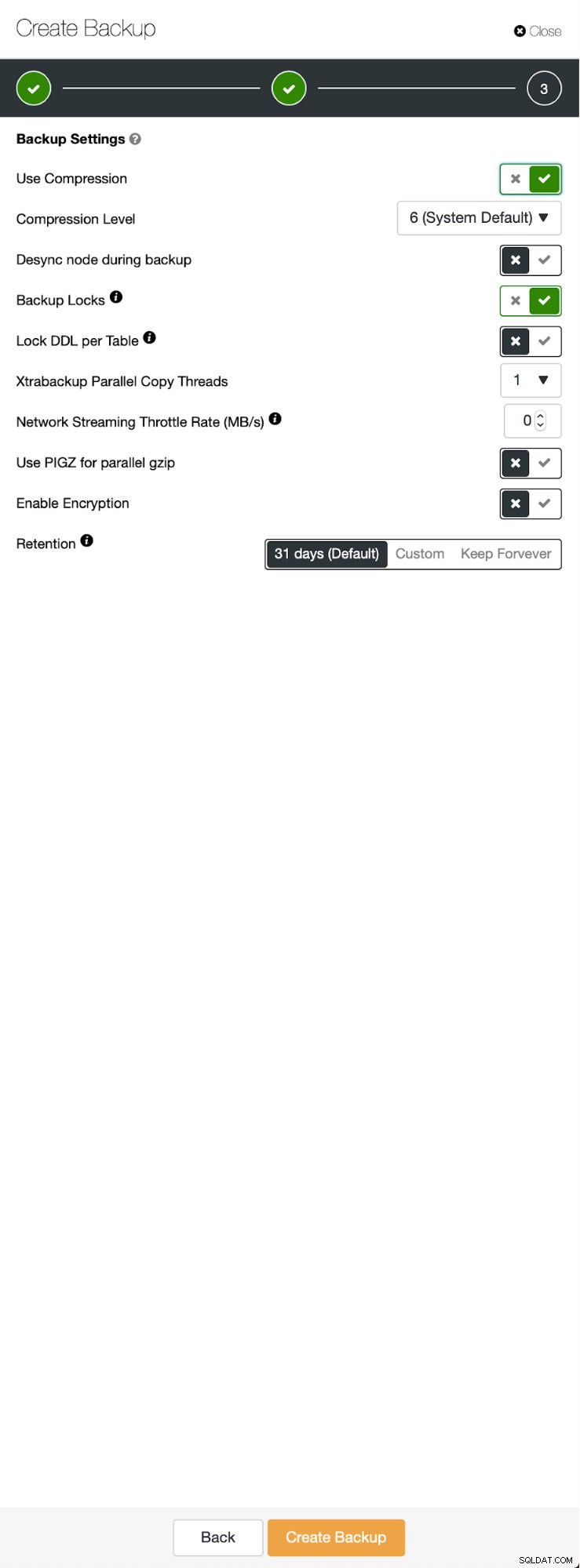
Tři kroky, ve kterých jsme vybrali uzel, abychom z něj sundali zálohu. Tento uzel (10.0.0.101) se stane hlavním. Musí mít povoleny binární protokoly. V našem případě mají všechny uzly povolený binlog, ale pokud ne, je velmi snadné jej povolit z ClusterControl – kroky si ukážeme později, až to uděláme pro druhý cluster.
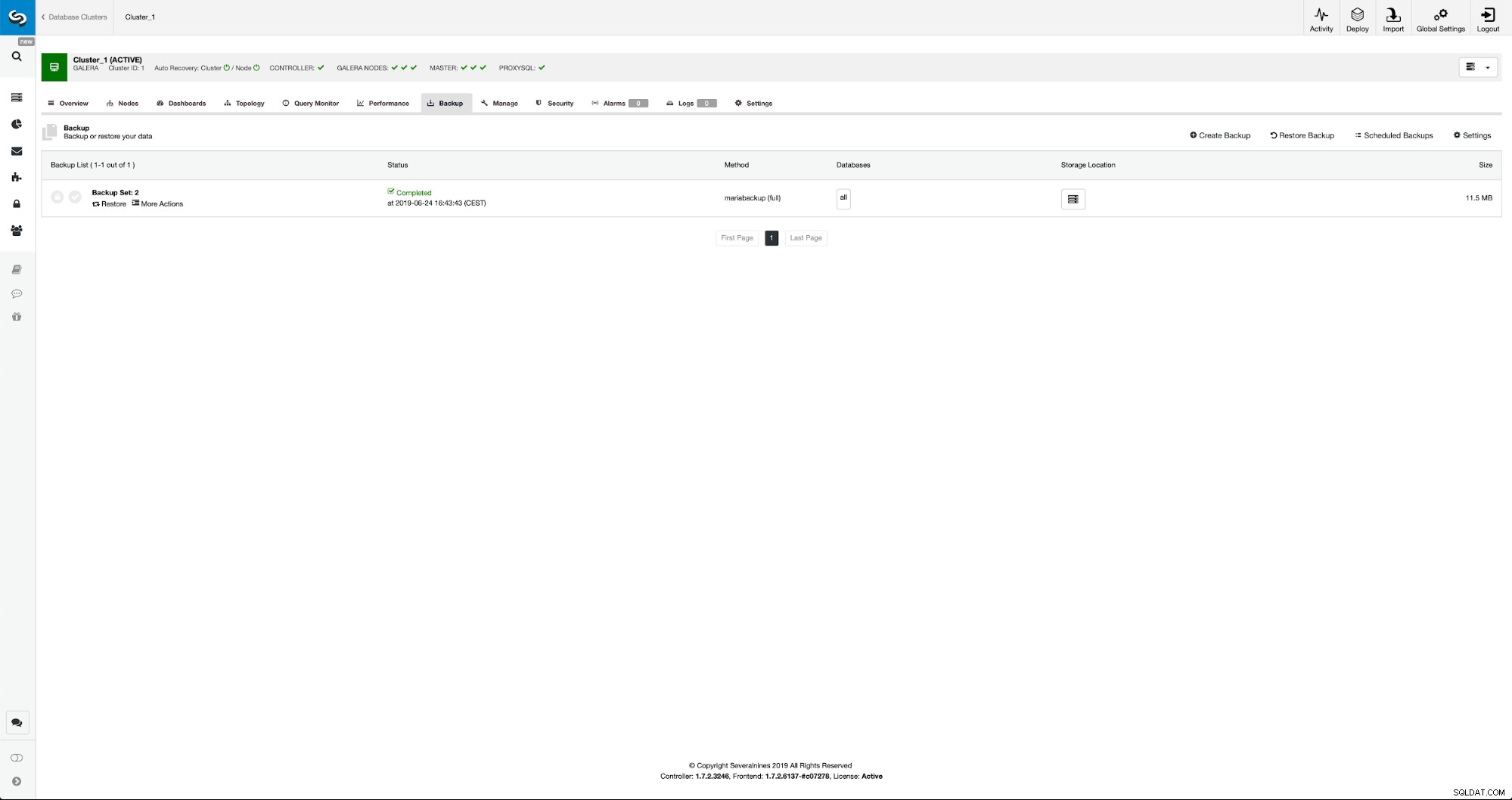
Jakmile je záloha dokončena, bude viditelná v seznamu. Poté můžeme pokračovat a obnovit jej:

Pokud bychom to chtěli, mohli bychom dokonce provést Point-In-Time Recovery, ale v našem případě na tom opravdu nezáleží:jakmile bude replikace nakonfigurována, všechny požadované transakce z binlogů budou aplikovány na nový cluster.

Poté vybereme možnost vytvořit cluster ze zálohy. Otevře se další dialog:
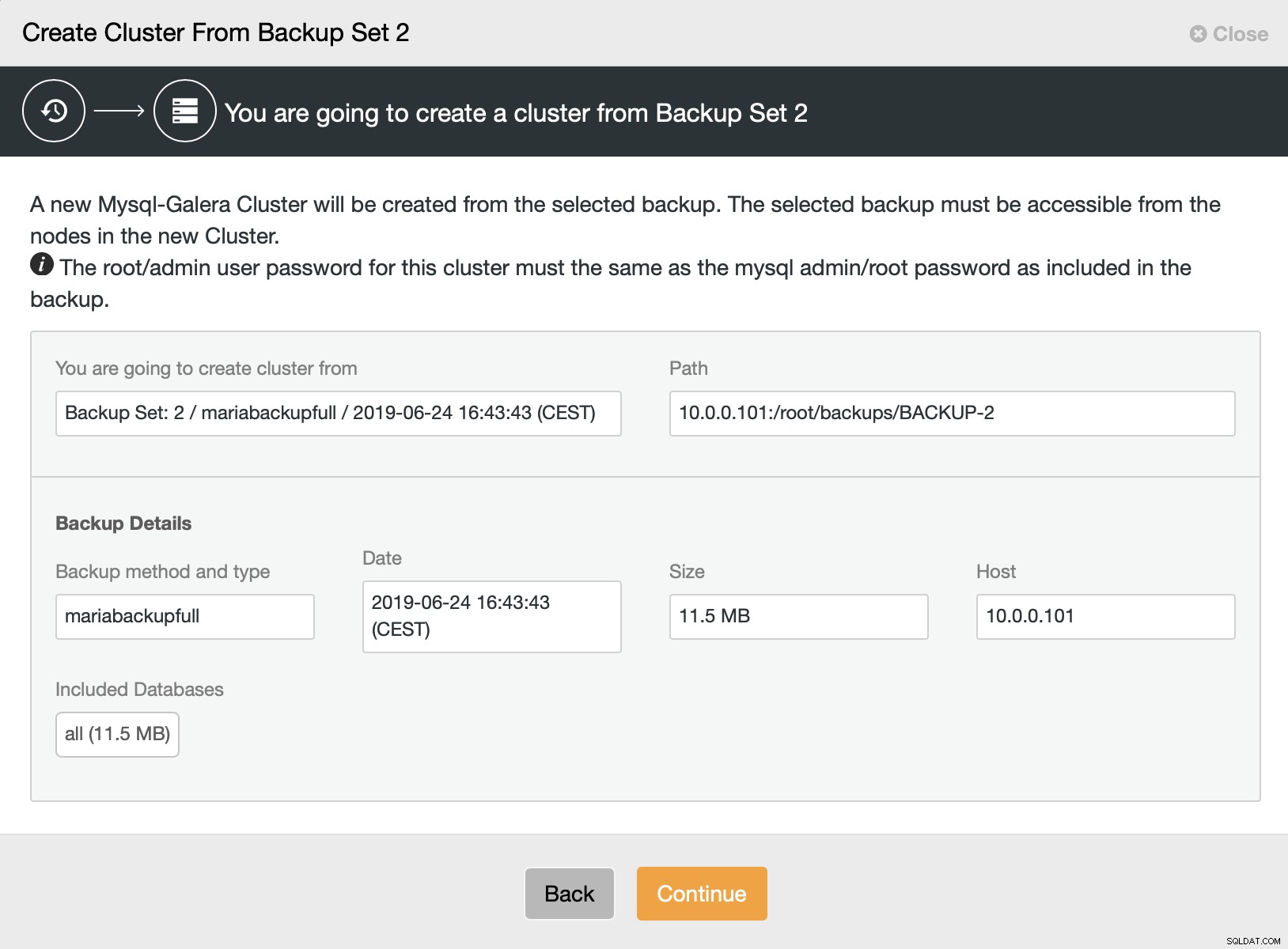
Jedná se o potvrzení, která záloha bude použita, z kterého hostitele byla záloha převzata, jaká metoda byla použita k jejímu vytvoření a některá metadata, která pomohou ověřit, zda záloha vypadá správně.
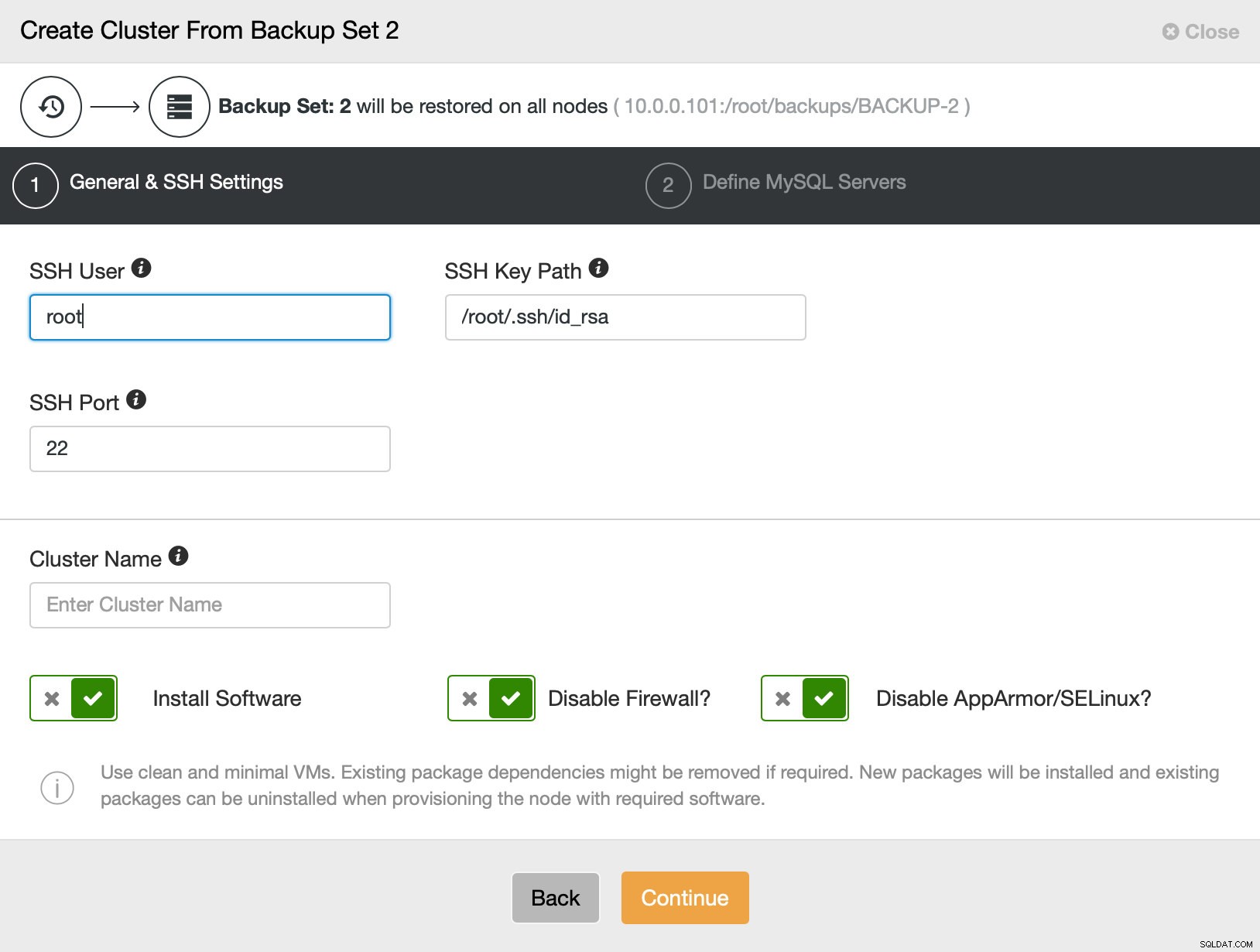
Poté v podstatě přejdeme k běžnému průvodci nasazením, ve kterém musíme definovat SSH konektivitu mezi hostitelem ClusterControl a uzly, na kterých se má cluster nasadit (požadavek na ClusterControl), a ve druhém kroku dodavatele, verzi, heslo a uzly k nasazení. dne:
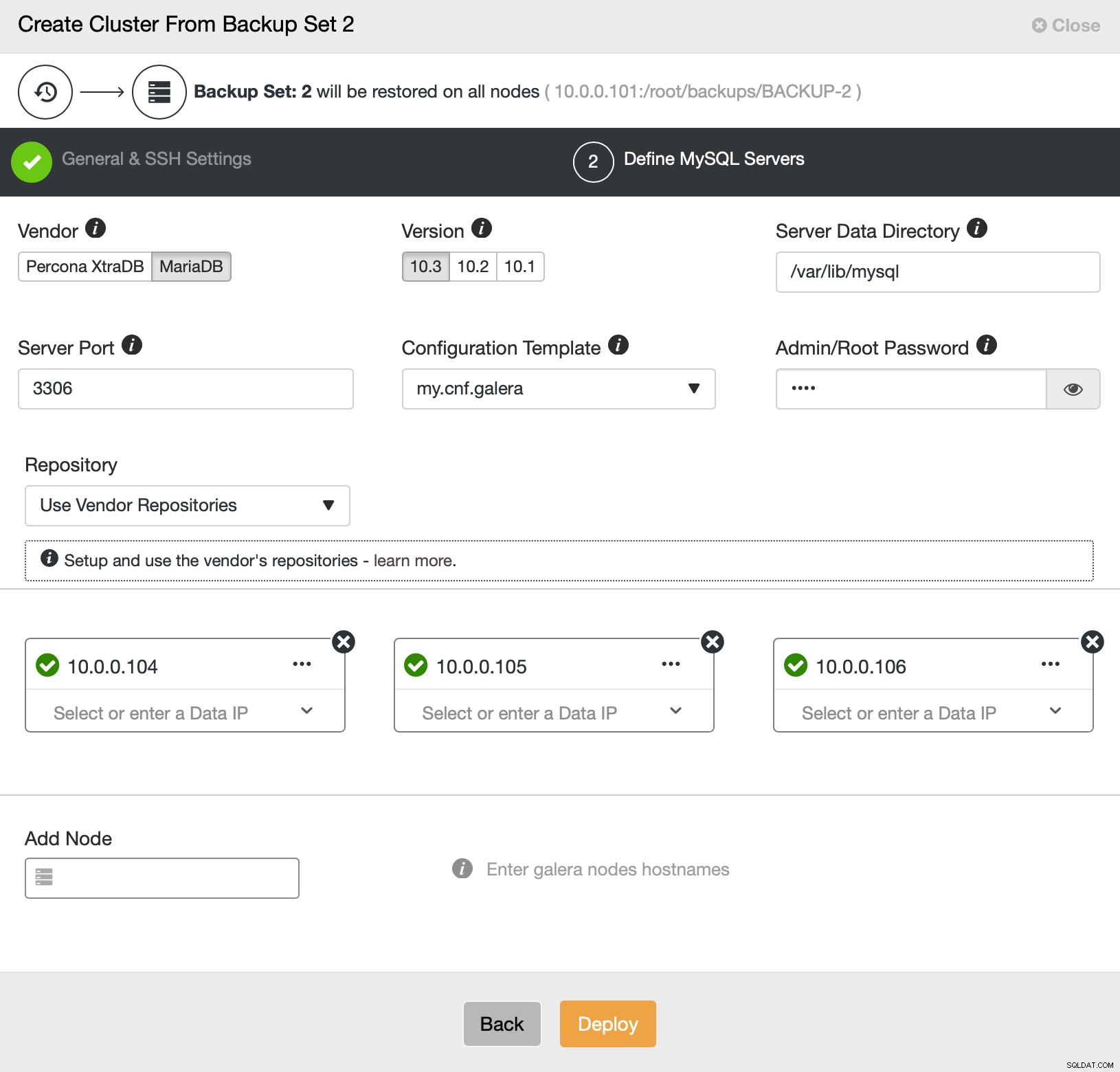
To je vše ohledně nasazení a poskytování. ClusterControl nastaví nový cluster a zřídí jej pomocí dat ze starého.
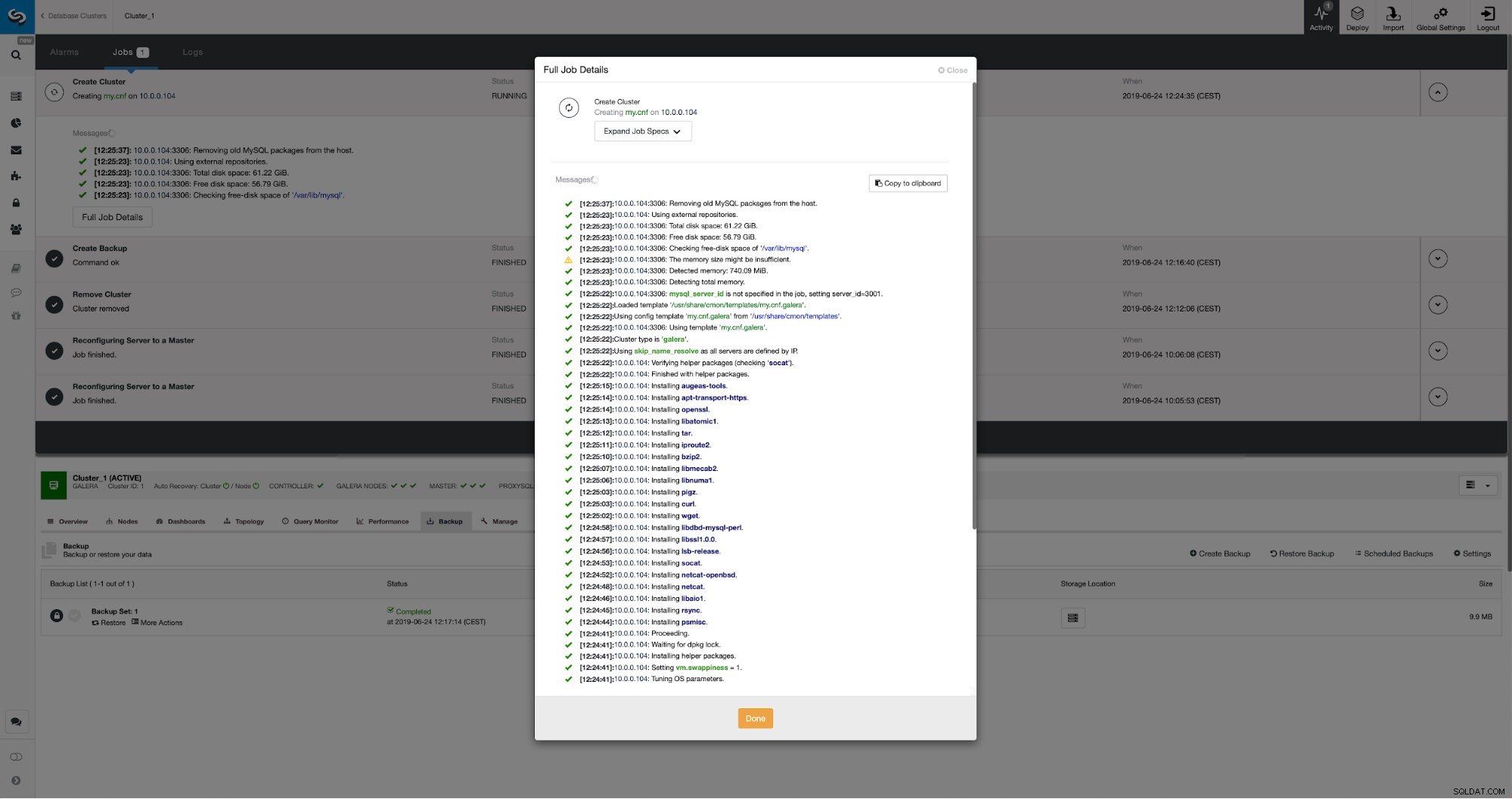
Průběh můžeme sledovat v záložce aktivity. Po dokončení se druhý cluster zobrazí v seznamu clusterů v ClusterControl.
Rekonfigurace nového clusteru pomocí ClusterControl
Nyní musíme znovu nakonfigurovat cluster - povolíme binární protokoly. V ručním procesu jsme museli provést změny v konfiguraci wsrep_sst_auth a také konfigurační položky v sekcích [mysqldump] a [xtrabackup] konfigurace. Tato nastavení lze nalézt v souboru secrets-backup.cnf. Tentokrát to není potřeba, protože ClusterControl vygeneroval nová hesla pro cluster a správně nakonfiguroval soubory. Co je však důležité mít na paměti, pokud změníte heslo uživatele 'backupuser'@'127.0.0.1' v původním clusteru, budete muset provést změny konfigurace i v druhém clusteru, aby se to projevilo jako změny v první cluster se replikuje do druhého clusteru.
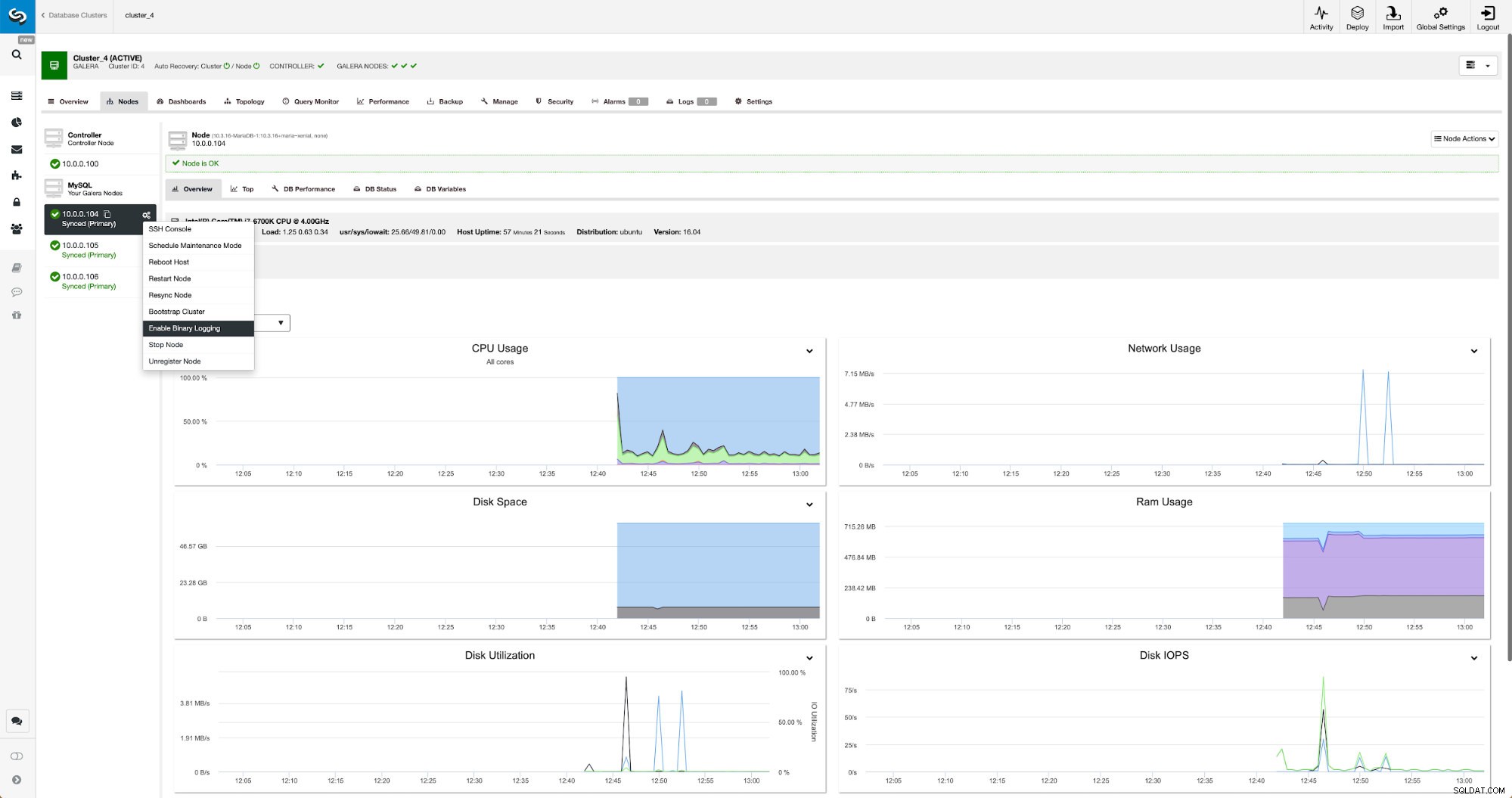
Binární protokoly lze povolit v sekci Nodes. Musíte vybrat uzel po uzlu a spustit úlohu „Povolit binární protokolování“. Zobrazí se vám dialog:
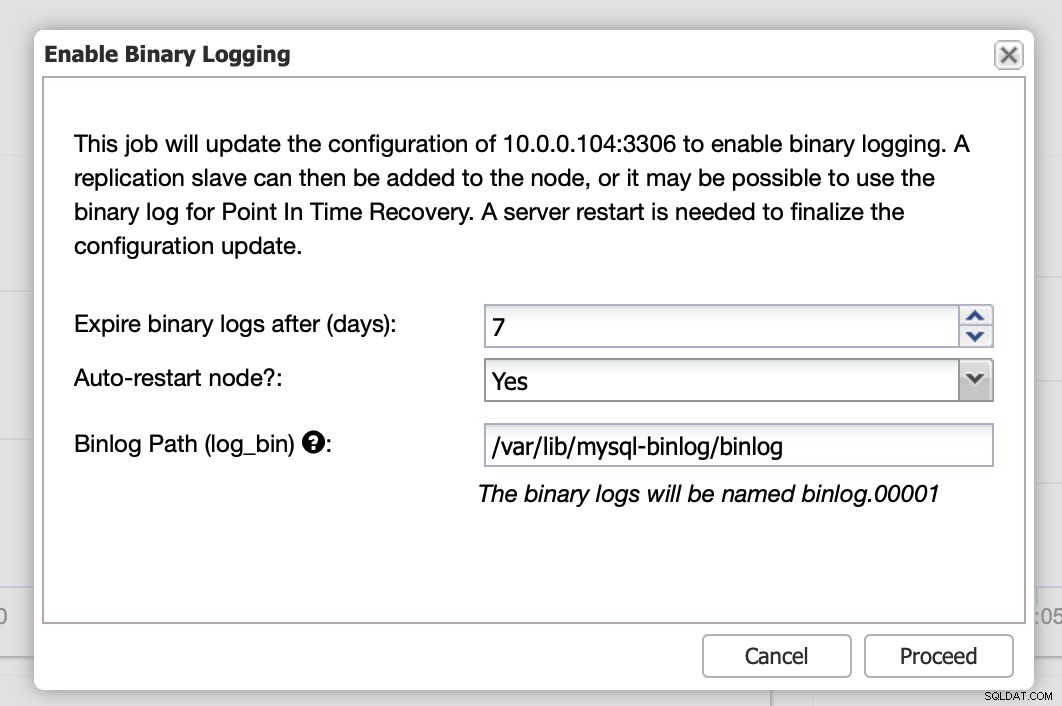
Zde můžete definovat, jak dlouho chcete uchovávat protokoly, kde by se měly ukládat a zda má ClusterControl restartovat uzel, abyste mohli použít změny – konfigurace binárního protokolu není dynamická a pro použití těchto změn je třeba restartovat MariaDB.
Po dokončení změn uvidíte všechny uzly označené jako „master“, což znamená, že tyto uzly mají povolený binární protokol a mohou fungovat jako hlavní.
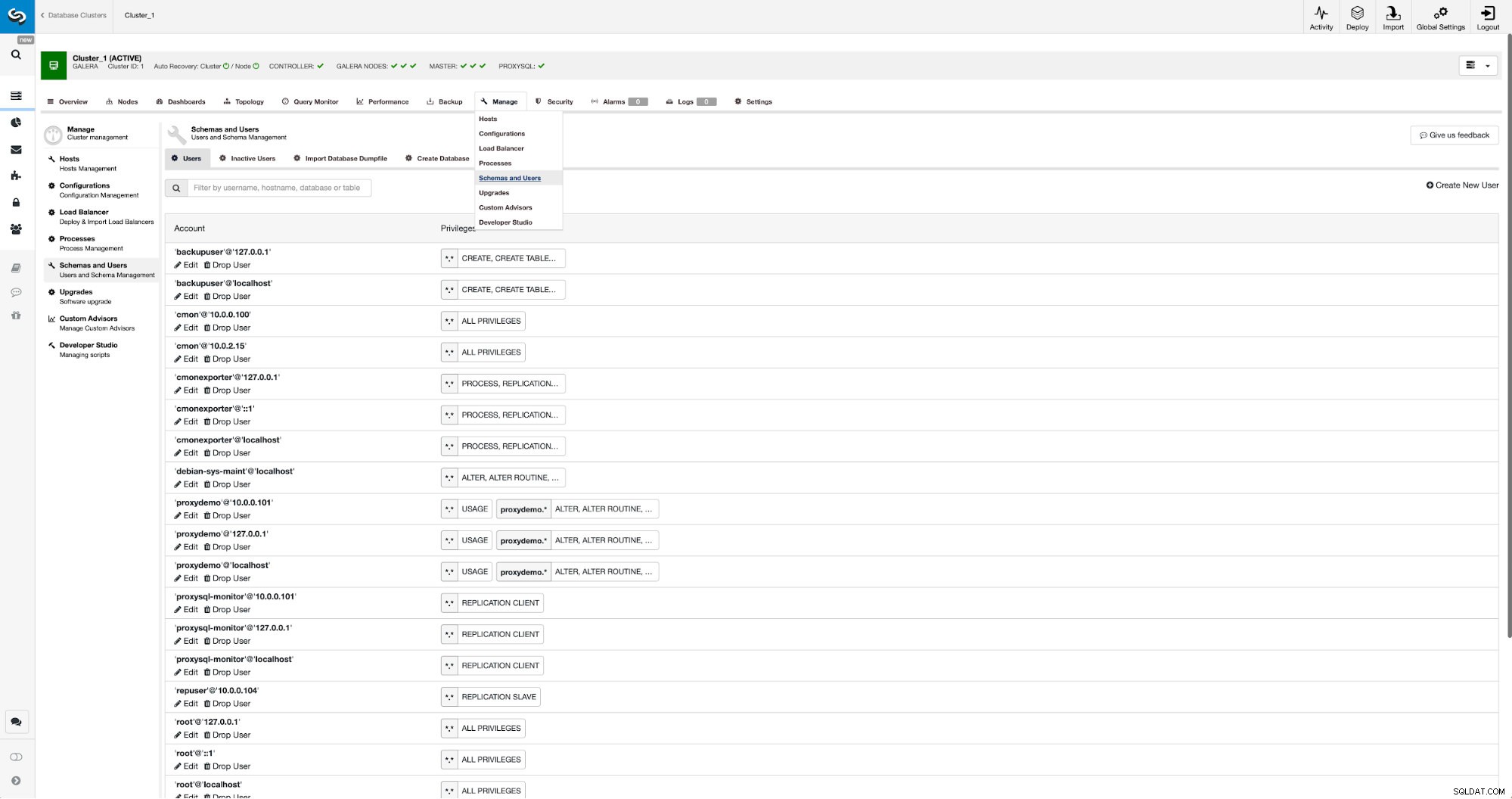
Pokud ještě nemáme vytvořeného uživatele replikace, musíme to udělat. V prvním clusteru musíme jít do Spravovat -> Schémata a uživatelé:
Na pravé straně máme možnost vytvořit nového uživatele:
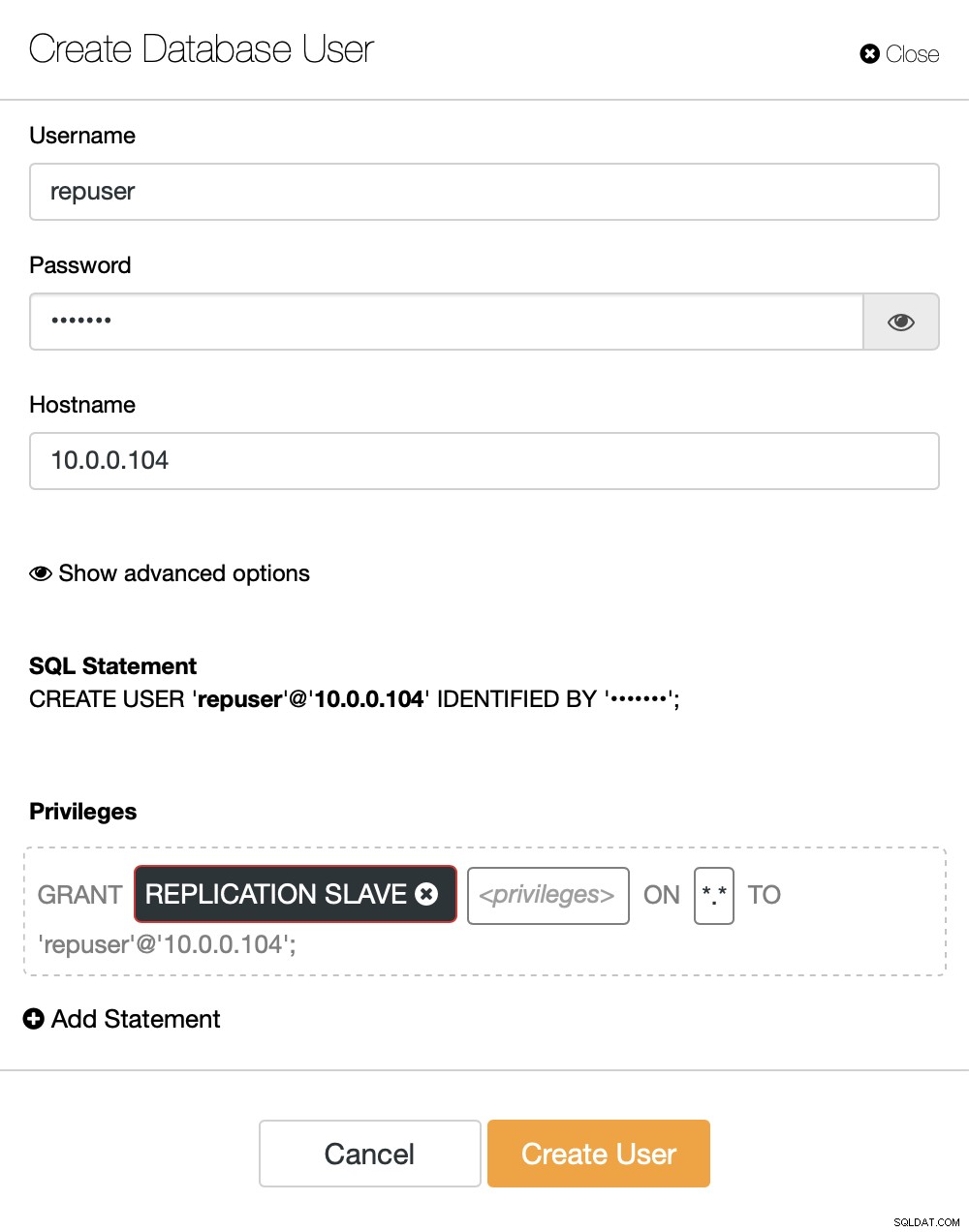
Tím je konfigurace potřebná k nastavení replikace ukončena.
Nastavení replikace mezi clustery pomocí ClusterControl
Jak jsme uvedli, pracujeme na automatizaci této části. V současnosti se to musí dělat ručně. Jak si možná pamatujete, potřebujeme pozici GITD naší zálohy a poté spustit několik příkazů pomocí MySQL CLI. Údaje GTID jsou k dispozici v záloze. ClusterControl vytvoří zálohu pomocí xbstream/mbstream a následně ji zkomprimuje. Naše záloha je uložena na hostiteli ClusterControl, kde nemáme přístup k binárnímu mbstream. Můžete jej zkusit nainstalovat nebo můžete zkopírovat záložní soubor do umístění, kde je takový binární soubor dostupný:
scp /root/backups/BACKUP-2/ backup-full-2019-06-24_144329.xbstream.gz 10.0.0.104:/root/mariabackup/Až to bude hotové, 10.0.0.104 chceme zkontrolovat obsah souboru xtrabackup_info:
cd /root/mariabackup
zcat backup-full-2019-06-24_144329.xbstream.gz | mbstream -x
example@sqldat.com:~/mariabackup# cat /root/mariabackup/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000007', position '379', GTID of the last change '9999-1002-846116'Nakonec nakonfigurujeme replikaci a spustíme ji:
MariaDB [(none)]> SET GLOBAL gtid_slave_pos ='9999-1002-846116';
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)To je ono – právě jsme nakonfigurovali asynchronní replikaci mezi dvěma clustery MariaDB Galera pomocí ClusterControl. Jak jste mohli vidět, ClusterControl dokázal zautomatizovat většinu kroků, které jsme museli udělat, abychom toto prostředí nastavili.