Ačkoli v budoucnu bude většina databázových serverů (zejména těch, které zpracovávají pracovní zátěže podobné OLTP) používat úložiště založené na flash, my tam ještě nejsme – flash úložiště je stále podstatně dražší než tradiční pevné disky, a tak mnoho systémů používá kombinaci disků SSD a HDD. To však znamená, že se musíme rozhodnout, jak rozdělit databázi – co by mělo jít do rotující rzi (HDD) a co je dobrým kandidátem na flash úložiště, které je dražší, ale mnohem lépe zvládá náhodné I/O.
Existují řešení, která se to snaží zvládnout automaticky na úrovni úložiště tím, že automaticky používají SSD jako mezipaměť a automaticky udržují aktivní část dat na SSD. Úložná zařízení / SAN to často dělají interně, existují hybridní SATA/SAS disky s velkým HDD a malým SSD v jednom balíčku a samozřejmě existují řešení, jak to udělat přímo na hostiteli – například v Linuxu existuje dm-cache, LVM v roce 2014 také získal takovou schopnost (postavenou na dm-cache) a samozřejmě ZFS má L2ARC.
Ale ignorujme všechny tyto automatické možnosti a řekněme, že máme dvě zařízení připojená přímo k systému – jedno založené na HDD a druhé na flash. Jak byste měli rozdělit databázi, abyste co nejvíce využili drahý flash? Jedním z běžně používaných vzorů je provést to podle typu objektu, zejména tabulky vs. indexy. Což obecně dává smysl, ale často vidíme lidi umisťovat indexy na úložiště SSD, protože indexy jsou spojeny s náhodnými I/O. I když se to může zdát rozumné, ukázalo se, že je to přesně opak toho, co byste měli dělat.
Dovolte mi, abych vám ukázal benchmark…
Dovolte mi demonstrovat to na systému s HDD úložištěm (RAID10 sestaveným ze 4x 10k SAS disků) a jedním SSD zařízením (Intel S3700). Systém má 16GB RAM, takže použijme pgbench s měřítky 300 (=4,5GB) a 3000 (=45GB), tedy takový, který se snadno vejde do RAM a násobku RAM. Potom umístěte tabulky a indexy na různé úložné systémy (pomocí tabulkových prostorů) a změřte výkon. Databázový cluster byl přiměřeně nakonfigurován (sdílené vyrovnávací paměti, limity WAL atd.) s ohledem na hardwarové prostředky. WAL byla umístěna na samostatném zařízení SSD připojeném k řadiči RAID sdílenému s disky SAS.
Na malém (4,5 GB) datovém souboru vypadají výsledky takto (všimněte si, že osa y začíná na 3000 tps):
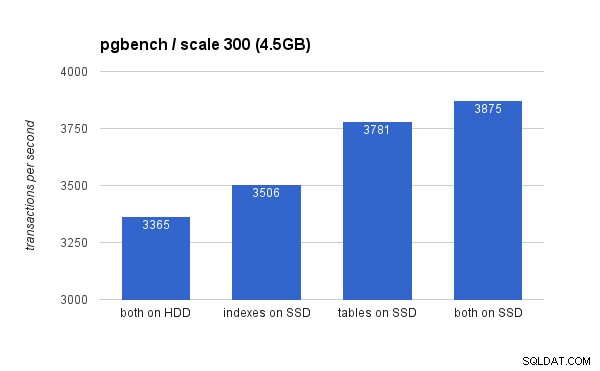
Je zřejmé, že umístění indexů na SSD poskytuje nižší přínos ve srovnání s použitím SSD pro tabulky. Zatímco datová sada se snadno vejde do paměti RAM, změny je třeba nakonec zapsat na disk, a zatímco řadič RAID má mezipaměť pro zápis, nemůže ve skutečnosti konkurovat flash úložišti. Nové řadiče RAID by pravděpodobně fungovaly o něco lépe, ale také nové disky SSD.
Na velkém souboru dat jsou rozdíly mnohem významnější (tentokrát osa y začíná na 0):
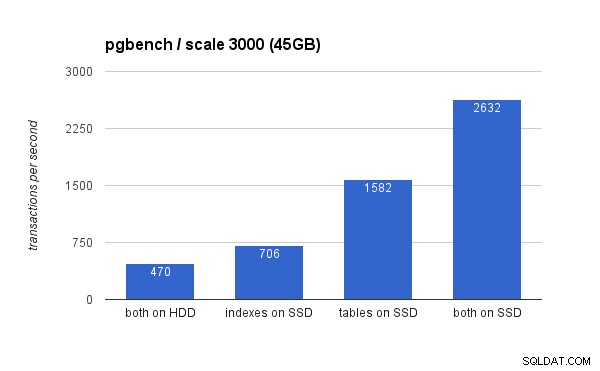
Umístění indexů na SSD vede ke značnému nárůstu výkonu (téměř 50 %, vezmeme-li úložiště HDD jako základ), ale přesun tabulek na SSD to snadno překoná ziskem více než 200 %. Samozřejmě, pokud na SSD umístíte jak tabulky, tak index, výkon dále zlepšíte – ale pokud to dokážete, nemusíte si dělat starosti s ostatními případy.
Ale proč?
Dosažení lepšího výkonu umístěním tabulek na SSD se může zdát trochu neintuitivní, tak proč se to chová takto? Pravděpodobně jde o kombinaci několika faktorů:
- indexy jsou obvykle mnohem menší než tabulky, a proto se snáze vejdou do paměti
- stránky v úrovních indexů (ve stromu) jsou obvykle poměrně horké, a proto zůstávají v paměti
- při skenování a indexování je velká část skutečných I/O sekvenční povahy (zejména u listových stránek)
Důsledkem toho je, že překvapivé množství I/O proti indexům se buď vůbec neděje (díky ukládání do mezipaměti), nebo je sekvenční. Na druhou stranu jsou indexy skvělým zdrojem náhodných I/O proti tabulkám.
Je to však složitější…
Samozřejmě, toto byl jen jednoduchý příklad a závěry se mohou lišit například pro podstatně odlišné pracovní zatížení. Podobně, protože SSD jsou dražší, systémy mívají více místa na disku na jednotkách HDD než na jednotkách SSD, takže tabulky se na SSD nemusí vejít, zatímco indexy ano. V těchto případech je nutné propracovanější umístění – například s ohledem nejen na typ objektu, ale také na to, jak často se používá (a pouze přesunout silně používané tabulky na SSD), nebo dokonce podmnožiny tabulek (např. data z SSD na HDD).