Jakmile spustíte databázový server a vaše využití poroste, budete vystaveni mnoha typům technických problémů, snížení výkonu a selhání databáze. Každý z nich by mohl vést k mnohem větším problémům, jako je katastrofální selhání nebo ztráta dat. Je to jako řetězová reakce, kdy jedna věc může vést k druhé a způsobit další a další problémy. Je nutné provést proaktivní protiopatření, abyste měli stabilní prostředí co nejdéle.
V tomto příspěvku na blogu se podíváme na spoustu skvělých funkcí nabízených ClusterControl, které nám mohou velmi pomoci při odstraňování a opravě problémů s naší databází MySQL, když nastanou.
Databázové alarmy a oznámení
Pro všechny nežádoucí události zaznamená ClusterControl vše pod Alarmy, které jsou dostupné na stránce Aktivita (horní nabídka) na stránce ClusterControl. Toto je obvykle první krok k zahájení odstraňování problémů, když se něco pokazí. Z této stránky můžeme získat představu o tom, co se vlastně děje s naším databázovým clusterem:
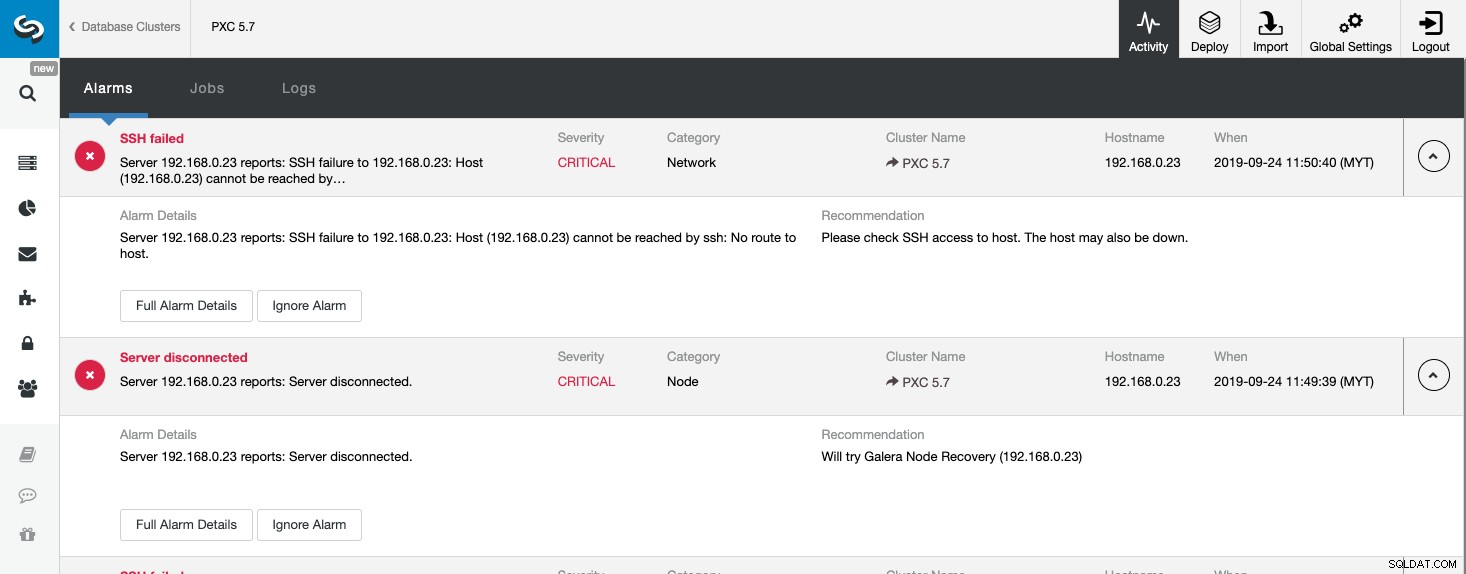
Výše uvedený snímek obrazovky ukazuje příklad události nedostupnosti serveru se závažností KRITICKÉ , detekovaný dvěma komponentami, Network a Node. Pokud jste nakonfigurovali nastavení e-mailových upozornění, měli byste dostat kopii těchto alarmů do vaší poštovní schránky.
Kliknutím na „Úplné podrobnosti alarmu“ můžete získat důležité podrobnosti o alarmu, jako je název hostitele, časové razítko, název clusteru a podobně. Poskytuje také další doporučený krok. Tento alarm můžete také odeslat jako e-mail dalším příjemcům nakonfigurovaným v Nastavení upozornění e-mailem.
Můžete se také rozhodnout ztišit alarm kliknutím na tlačítko „Ignorovat alarm“ a alarm se znovu nezobrazí v seznamu. Ignorování alarmu může být užitečné, pokud máte alarm nízké závažnosti a víte, jak s ním zacházet nebo jak jej obejít. Například pokud ClusterControl detekuje duplicitní index ve vaší databázi, kde by to v některých případech vyžadovaly vaše starší aplikace.
Když se podíváme na tuto stránku, můžeme okamžitě porozumět tomu, co se děje s naším databázovým clusterem a jaký je další krok k vyřešení problému. Jako v tomto případě jeden z databázových uzlů selhal a stal se nedostupným přes SSH z hostitele ClusterControl. Dokonce i začátečník SysAdmin by nyní věděl, co dělat dál, pokud se objeví tento alarm.
Soubory protokolu centralizované databáze
Zde můžeme zjistit, co bylo na našem databázovém serveru špatně. V části ClusterControl -> Logs -> System Logs můžete vidět všechny soubory protokolu související s databázovým clusterem. Pokud jde o databázový cluster založený na MySQL, ClusterControl stáhne protokol ProxySQL, protokol chyb MySQL a protokoly zálohování:
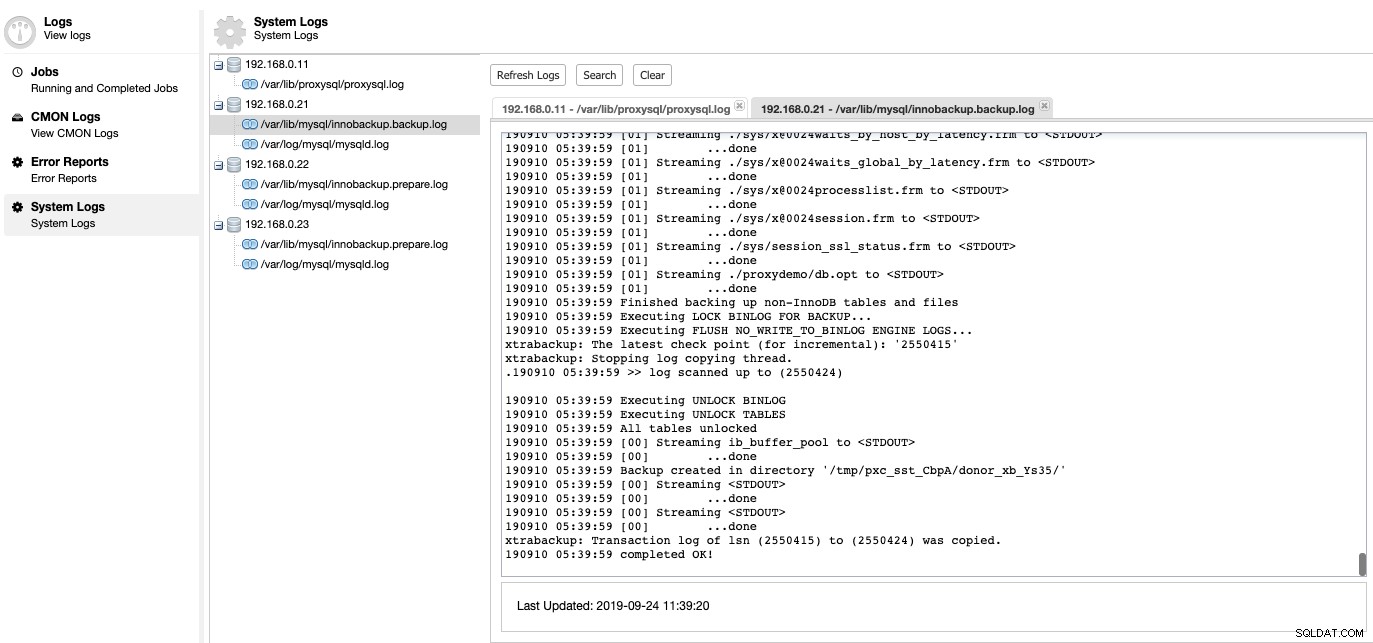
Kliknutím na „Obnovit protokol“ získáte nejnovější protokol ze všech hostitelů, kteří jsou v danou dobu přístupní. Pokud je uzel nedostupný, ClusterControl bude stále zobrazovat zastaralé přihlášení, protože tyto informace jsou uloženy v databázi CMON. Ve výchozím nastavení ClusterControl načítá systémové protokoly každých 10 minut, což lze konfigurovat v Nastavení -> Interval protokolování.
ClusterControl spustí úlohu a načte nejnovější protokol z každého serveru, jak je znázorněno v následující úloze "Shromažďovat protokoly":
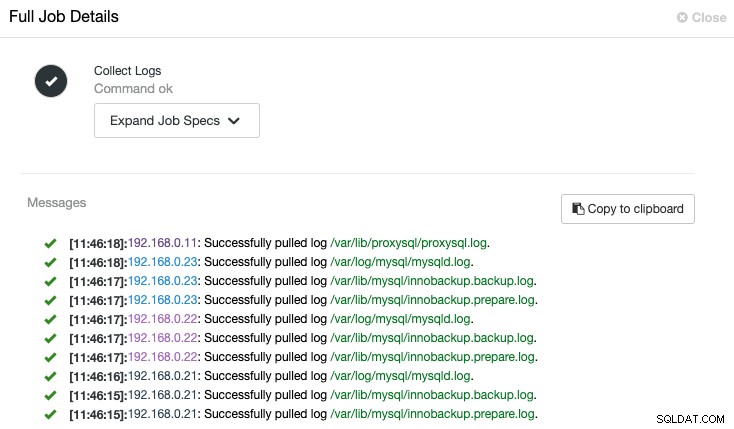
Centralizované zobrazení souboru protokolu nám umožňuje rychleji porozumět tomu, co se stalo špatně. U databázového clusteru, který běžně zahrnuje více uzlů a vrstev, tato funkce výrazně zlepší čtení protokolů, kde SysAdmin může porovnávat tyto protokoly vedle sebe a určit kritické události, čímž se zkrátí celková doba odstraňování problémů.
Webová konzola SSH
ClusterControl poskytuje webovou konzolu SSH, takže můžete přistupovat k serveru DB přímo prostřednictvím uživatelského rozhraní ClusterControl (protože uživatel SSH je nakonfigurován pro připojení k hostitelům databáze). Odtud můžeme shromáždit mnohem více informací, které nám umožní vyřešit problém ještě rychleji. Každý ví, že když problém s databází zasáhne produkční systém, každá sekunda výpadku se počítá.
Chcete-li přistupovat ke konzole SSH přes web, jednoduše vyberte uzly v části Nodes -> Node Actions -> SSH Console, nebo jednoduše klikněte na ikonu ozubeného kola pro zástupce:
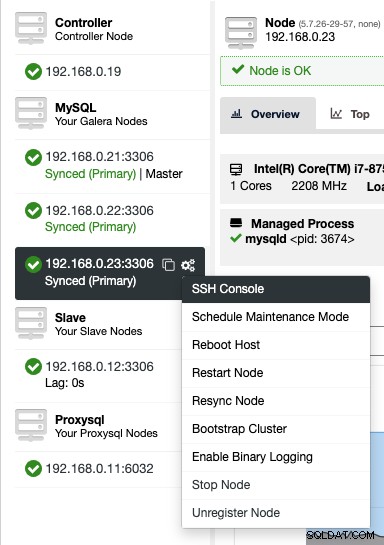
Vzhledem k bezpečnostním obavám, které mohou být způsobeny touto funkcí, zejména pro více -user nebo multi-tenant prostředí, lze jej zakázat tak, že přejdete na /var/www/html/clustercontrol/bootstrap.php na serveru ClusterControl a nastavíte následující konstantu na false:
define('SSH_ENABLED', false);Obnovte stránku uživatelského rozhraní ClusterControl a načtěte nové změny.
Problémy s výkonem databáze
Kromě funkcí monitorování a trendování vám ClusterControl proaktivně zasílá různé alarmy a poradce související s výkonem databáze, například:
- Nadměrné využití – Zdroj, který překračuje určité prahové hodnoty, jako je CPU, paměť, využití swapu a místo na disku.
- Degradace clusteru – rozdělení clusteru a sítě.
- Posun času systému – Časový rozdíl mezi všemi uzly v clusteru (včetně uzlu ClusterControl).
- Různí další poradci související s MySQL:
- Replikace – zpoždění replikace, vypršení platnosti binlogu, umístění a růst
- Galera – metoda SST, skenování souboru protokolu GRA, kontrola adresy clusteru
- Kontrola schématu – Existence netransakční tabulky v Galera Cluster.
- Spojení – poměr připojených vláken
- InnoDB – Poměr špinavých stránek, nárůst souboru protokolu InnoDB
- Pomalé dotazy – ClusterControl standardně spustí alarm, pokud zjistí, že dotaz běží déle než 30 sekund. To je samozřejmě konfigurovatelné v části Nastavení -> Konfigurace běhu -> Dlouhý dotaz.
- Zablokování – zablokování transakcí InnoDB a zablokování Galery.
- Indexy – Duplicitní klíče, tabulka bez primárních klíčů.
Podívejte se na stránku Poradci v části Výkon -> Poradci, kde najdete podrobnosti o věcech, které lze zlepšit, jak navrhuje ClusterControl. Pro každého poradce poskytuje odůvodnění a rady, jak je uvedeno v následujícím příkladu poradce „Kontrola využití místa na disku“:
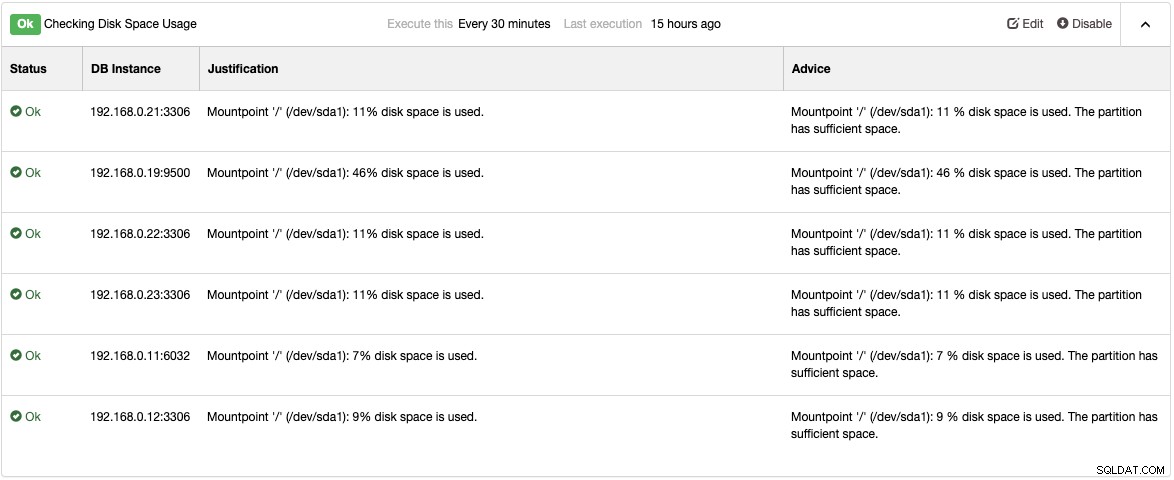
Když nastane problém s výkonem, zobrazí se „Varování“ (žlutá) nebo "Kritický" (červený) stav u těchto poradců. K překonání problému je obvykle nutné další ladění. Poradci vyvolávají poplachy, což znamená, že uživatelé dostanou kopii těchto poplachů do poštovní schránky, pokud jsou e-mailová upozornění odpovídajícím způsobem nakonfigurována. O každém alarmu vyvolaném ClusterControl nebo jeho poradci obdrží uživatelé také e-mail, pokud byl alarm vymazán. Ty jsou předem nakonfigurovány v rámci ClusterControl a nevyžadují žádnou počáteční konfiguraci. Další přizpůsobení je vždy možné pod Manage -> Developer Studio. Můžete se podívat na tento blogový příspěvek o tom, jak napsat svého vlastního poradce.
ClusterControl také poskytuje vyhrazenou stránku týkající se výkonu databáze pod ClusterControl -> Výkon. Poskytuje všechny druhy přehledů databáze podle osvědčených postupů, jako je centralizovaný pohled na stav DB, proměnné, stav InnoDB, analyzátor schémat, protokoly transakcí. Ty jsou docela samozřejmé a snadno pochopitelné.
Pokud jde o výkon dotazů, můžete zkontrolovat Nejčastější dotazy a Odlehlé hodnoty dotazů, kde ClusterControl zvýrazňuje dotazy, jejichž výkon se výrazně liší od průměrného dotazu. Tomuto tématu jsme se podrobně věnovali v tomto blogovém příspěvku, MySQL Query Performance Tuning.
Hlášení o chybách databáze
ClusterControl přichází s nástrojem pro generování chybových hlášení, který shromažďuje informace o ladění vašeho databázového clusteru a pomáhá tak porozumět aktuální situaci a stavu. Chcete-li vygenerovat chybové hlášení, jednoduše přejděte na ClusterControl -> Protokoly -> Hlášení o chybách -> Vytvořit hlášení o chybě:
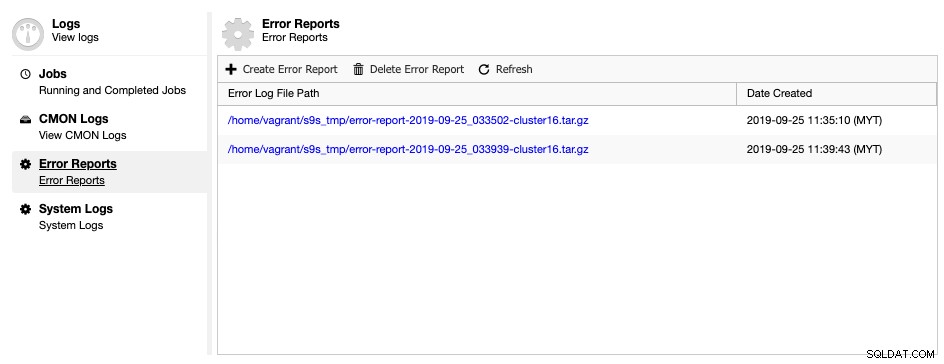
Vygenerovanou chybovou zprávu lze stáhnout z této stránky, jakmile bude připravena. Tato vygenerovaná zpráva bude ve formátu míče TAR (tar.gz) a můžete ji připojit k žádosti o podporu. Vzhledem k tomu, že lístek podpory má limit 10 MB velikosti souboru, pokud je velikost tarballu větší, můžete jej nahrát na cloudovou jednotku a sdílet s námi odkaz ke stažení pouze s příslušným oprávněním. Můžete jej odstranit později, jakmile již soubor obdržíme. Hlášení o chybě můžete také vygenerovat pomocí příkazového řádku, jak je vysvětleno na stránce dokumentace k hlášení o chybě.
V případě výpadku důrazně doporučujeme vygenerovat několik chybových hlášení během výpadku a bezprostředně po něm. Tyto zprávy budou velmi užitečné při pokusu pochopit, co se pokazilo, o důsledcích výpadku a ověřit, že cluster je po katastrofální události ve skutečnosti zpět do provozního stavu.
Závěr
Proaktivní monitorování ClusterControl spolu se sadou funkcí pro odstraňování problémů poskytují uživatelům účinnou platformu pro řešení jakýchkoli problémů s databází MySQL. Dávno pryč je zastaralý způsob řešení problémů, kdy je nutné otevřít více relací SSH pro přístup k více hostitelům a opakovaně spouštět více příkazů, aby bylo možné určit hlavní příčinu.
Pokud vám výše uvedené funkce nepomohou při řešení problému nebo řešení problému s databází, vždy se obraťte na tým podpory společnosti Somenines, aby vás podpořil. Naši 24/7/365 specializovaní techničtí odborníci jsou kdykoli k dispozici, aby se mohli zúčastnit vašeho požadavku. Naše průměrná doba první odpovědi je obvykle méně než 30 minut.