Problém s výkonem, který často vidím, je, když uživatelé potřebují porovnat část řetězce s dotazem, jako je tento:
... WHERE SomeColumn LIKE N'%SomePortion%';
S úvodním zástupným znakem je tento predikát „non-SARGable“ – je to jen skvělý způsob, jak říci, že nemůžeme najít relevantní řádky pomocí hledání proti indexu na SomeColumn .
Jedním z řešení, nad kterým se nám to trochu vrtá hlavou, je fulltextové vyhledávání; toto je však složité řešení a vyžaduje, aby se vyhledávací vzor skládal z celých slov, nepoužíval zastavovací slova atd. To může pomoci, pokud hledáme řádky, kde popis obsahuje slovo „měkký“ (nebo jiné odvozeniny jako „měkčí“ nebo „měkčí“), ale nepomůže, když hledáme řetězce, které by mohly být obsaženy ve slovech (nebo která vůbec nejsou slovy, jako všechny SKU produktů, které obsahují „X45-B“ nebo všechny poznávací značky, které obsahují sekvenci „7RA“).
Co když SQL Server nějak věděl o všech možných částech řetězce? Můj myšlenkový proces je v souladu s trigram / trigraph v PostgreSQL. Základní koncept je, že engine má schopnost provádět bodové vyhledávání podřetězců, což znamená, že nemusíte skenovat celou tabulku a analyzovat každou plnou hodnotu.
Konkrétním příkladem, který tam používají, je slovo cat . Kromě celého slova jej lze rozdělit na části:c , ca a at (vynechávají a a t podle definice – žádný koncový podřetězec nesmí být kratší než dva znaky). V SQL Server nepotřebujeme, aby to bylo tak složité; opravdu potřebujeme jen polovinu trigramu – pokud uvažujeme o vytvoření datové struktury, která obsahuje všechny podřetězce cat , potřebujeme pouze tyto hodnoty:
- kočka
- v
- t
Nepotřebujeme c nebo ca , protože kdokoli hledá LIKE '%ca%' mohl snadno najít hodnotu 1 pomocí LIKE 'ca%' namísto. Podobně každý, kdo hledá LIKE '%at%' nebo LIKE '%a%' mohl použít koncový zástupný znak pouze proti těmto třem hodnotám a najít tu, která se shoduje (např. LIKE 'at%' najde hodnotu 2 a LIKE 'a%' najde také hodnotu 2, aniž by musel hledat tyto podřetězce uvnitř hodnoty 1, odkud by pocházela skutečná bolest).
Takže vzhledem k tomu, že SQL Server nemá nic takového zabudováno, jak takový trigram vygenerujeme?
Samostatná tabulka fragmentů
Přestanu zde odkazovat na "trigram", protože to není ve skutečnosti analogie této funkci v PostgreSQL. V podstatě to, co uděláme, je vytvořit samostatnou tabulku se všemi „fragmenty“ původního řetězce. (Takže v cat například by zde byla nová tabulka s těmito třemi řádky a LIKE '%pattern%' vyhledávání by bylo nasměrováno proti této nové tabulce jako LIKE 'pattern%' predikáty.)
Než začnu ukazovat, jak by mé navrhované řešení fungovalo, dovolte mi být naprosto jasné, že toto řešení by nemělo být použito v každém jednotlivém případě, kdy LIKE '%wildcard%' vyhledávání je pomalé. Vzhledem k tomu, jak se chystáme „rozložit“ zdrojová data na fragmenty, je pravděpodobně praktické omezeno na menší řetězce, jako jsou adresy nebo jména, na rozdíl od větších řetězců, jako jsou popisy produktů nebo abstrakty relací.
Praktičtější příklad než cat je podívat se na Sales.Customer tabulky ve vzorové databázi WideWorldImporters. Má adresní řádky (oba nvarchar(60) ), s cennými informacemi o adrese ve sloupci DeliveryAddressLine2 (z neznámých důvodů). Někdo možná hledá někoho, kdo bydlí v ulici Hudecova , takže budou spouštět vyhledávání takto:
SELECT CustomerID, DeliveryAddressLine2
FROM Sales.Customers
WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
/* This returns two rows:
CustomerID DeliveryAddressLine2
---------- ----------------------
61 1695 Hudecova Avenue
181 1846 Hudecova Crescent
*/ Jak byste očekávali, SQL Server potřebuje provést skenování, aby našel tyto dva řádky. Což by mělo být jednoduché; kvůli složitosti tabulky však tento triviální dotaz poskytuje velmi chaotický plán provádění (skenování je zvýrazněno a má varování na zbytkové I/O):
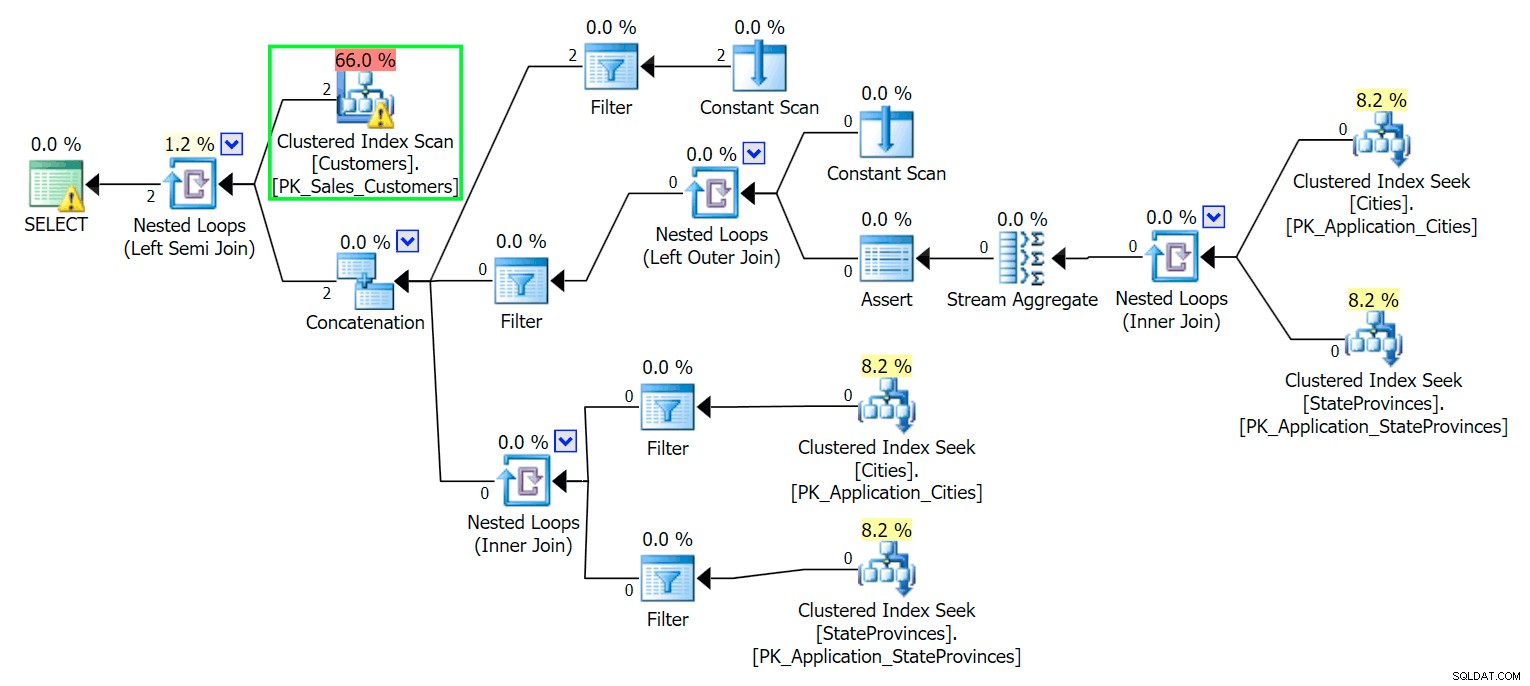
Blecch. Aby byl náš život jednoduchý a abychom se ujistili, že nehoníme hromadu červených sleďů, vytvoříme novou tabulku s podmnožinou sloupců a pro začátek vložíme tytéž dva řádky shora:
CREATE TABLE Sales.CustomersCopy ( CustomerID int IDENTITY(1,1) CONSTRAINT PK_CustomersCopy PRIMARY KEY, CustomerName nvarchar(100) NOT NULL, DeliveryAddressLine1 nvarchar(60) NOT NULL, DeliveryAddressLine2 nvarchar(60) ); GO INSERT Sales.CustomersCopy ( CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 ) SELECT CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 FROM Sales.Customers WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
Nyní, když spustíme stejný dotaz, jaký jsme spustili proti hlavní tabulce, dostaneme něco mnohem rozumnějšího, na co se dívat jako na výchozí bod. Toto bude stále skenování bez ohledu na to, co děláme – pokud přidáme index pomocí DeliveryAddressLine2 jako hlavní sloupec klíče s největší pravděpodobností získáme sken indexu s vyhledáváním klíče podle toho, zda index pokrývá sloupce v dotazu. Takto získáme skenování clusteru indexu:
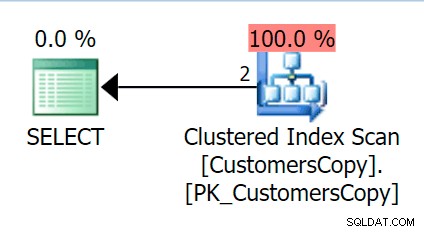
Dále vytvoříme funkci, která tyto hodnoty adres „rozloží“ na fragmenty. Očekávali bychom 1846 Hudecova Crescent , například mít následující sadu fragmentů:
- 1846 Hudecova půlměsíc
- 846 Hudecova půlměsíc
- 46 Hudecova půlměsíce
- 6 Hudecova půlměsíce
- Hudecova půlměsíc
- Hudecova půlměsíc
- udecova Crescent
- decova Crescent
- ecova Crescent
- cova Crescent
- ova Crescent
- va Crescent
- Půlměsíc
- Srpek
- Srpek
- vysvítit
- vystupovat
- vůně
- cent
- ent
- nt
- t
Je poměrně triviální napsat funkci, která vytvoří tento výstup – potřebujeme pouze rekurzivní CTE, které lze použít k procházení každého znaku po celé délce vstupu:
CREATE FUNCTION dbo.CreateStringFragments( @input nvarchar(60) )
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
WITH x(x) AS
(
SELECT 1 UNION ALL SELECT x+1 FROM x WHERE x < (LEN(@input))
)
SELECT Fragment = SUBSTRING(@input, x, LEN(@input)) FROM x
);
GO
SELECT Fragment FROM dbo.CreateStringFragments(N'1846 Hudecova Crescent');
-- same output as above bulleted list Nyní vytvoříme tabulku, která bude ukládat všechny fragmenty adres a ke kterému zákazníkovi patří:
CREATE TABLE Sales.CustomerAddressFragments ( CustomerID int NOT NULL, Fragment nvarchar(60) NOT NULL, CONSTRAINT FK_Customers FOREIGN KEY(CustomerID) REFERENCES Sales.CustomersCopy(CustomerID) ); CREATE CLUSTERED INDEX s_cat ON Sales.CustomerAddressFragments(Fragment, CustomerID);
Pak jej můžeme naplnit takto:
INSERT Sales.CustomerAddressFragments(CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f;
Pro naše dvě hodnoty to vloží 42 řádků (jedna adresa má 20 znaků a druhá 22). Nyní náš dotaz zní:
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
INNER JOIN Sales.CustomerAddressFragments AS f
ON f.CustomerID = c.CustomerID
AND f.Fragment LIKE N'Hudecova%'; Zde je mnohem hezčí plán – spojení dvou seskupených indexů *hledání* a vnořených smyček:
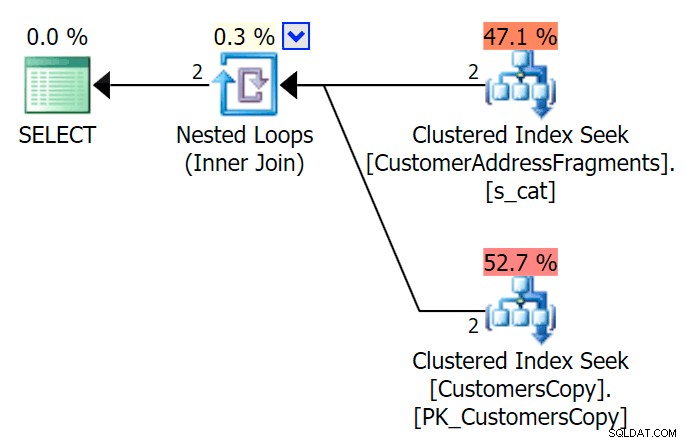
Můžeme to udělat také jiným způsobem, pomocí EXISTS :
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
WHERE EXISTS
(
SELECT 1 FROM Sales.CustomerAddressFragments
WHERE CustomerID = c.CustomerID
AND Fragment LIKE N'Hudecova%'
); Zde je plán, který se na první pohled zdá být dražší – volí skenování tabulky CustomersCopy. Brzy uvidíme, proč je toto lepší přístup k dotazu:
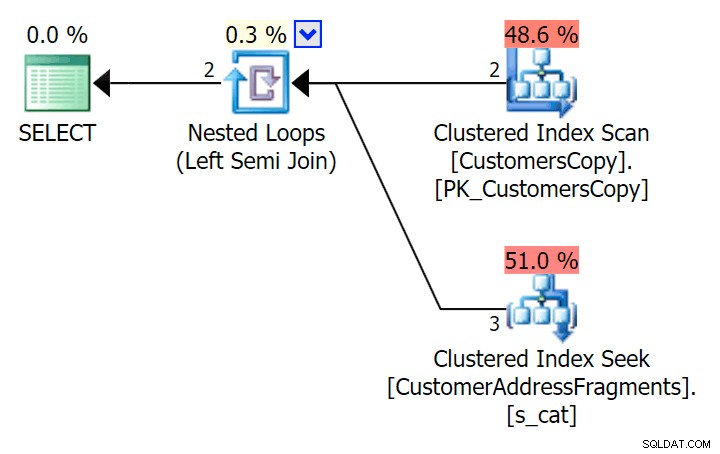
Nyní, na tomto masivním souboru dat o 42 řádcích, jsou rozdíly pozorované v trvání a I/O tak nepatrné, že jsou irelevantní (a ve skutečnosti při této malé velikosti vypadá skenování proti základní tabulce levněji, pokud jde o I/ O než ostatní dva plány, které používají tabulku fragmentů):

Co kdybychom tyto tabulky naplnili mnohem více daty? Moje kopie Sales.Customers má 663 řádků, takže pokud to zkřížíme proti sobě, dostali bychom se někde blízko 440 000 řádků. Pojďme tedy jednoduše rozmixovat 400 kB a vygenerovat mnohem větší tabulku:
TRUNCATE TABLE Sales.CustomerAddressFragments; DELETE Sales.CustomersCopy; DBCC FREEPROCCACHE WITH NO_INFOMSGS; INSERT Sales.CustomersCopy WITH (TABLOCKX) (CustomerName, DeliveryAddressLine1, DeliveryAddressLine2) SELECT TOP (400000) c1.CustomerName, c1.DeliveryAddressLine1, c2.DeliveryAddressLine2 FROM Sales.Customers c1 CROSS JOIN Sales.Customers c2 ORDER BY NEWID(); -- fun for distribution -- this will take a bit longer - on my system, ~4 minutes -- probably because I didn't bother to pre-expand files INSERT Sales.CustomerAddressFragments WITH (TABLOCKX) (CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f; -- repeated for compressed version of the table -- 7.25 million rows, 278MB (79MB compressed; saving those tests for another day)
Nyní, abych porovnal plány výkonu a provádění s ohledem na různé možné parametry vyhledávání, otestoval jsem výše uvedené tři dotazy s těmito predikáty:
| Dotaz | Predikáty | ||||
|---|---|---|---|---|---|
| KDE DeliveryLineAddress2 LIKE … | N'%Hudecova%' | N'%cova%' | N'%ova%' | N'%va%' | |
| PŘIPOJTE SE … KDE Fragmentujte JAKO … | N'Hudecova%' | N'cova%' | N'ova%' | N'va%' | |
| KDE EXISTUJE (… WHERE Fragment LIKE …) | |||||
Když odstraňujeme písmena z vyhledávacího vzoru, očekával bych, že uvidím více výstupů řádků a možná i jiné strategie zvolené optimalizátorem. Podívejme se, jak to probíhalo u každého vzoru:
Hudecova%
U tohoto vzoru bylo skenování stále stejné pro podmínku LIKE; s více daty jsou však náklady mnohem vyšší. Hledání do tabulky fragmentů se při tomto počtu řádků (1 206) opravdu vyplatí, a to i při opravdu nízkých odhadech. Plán EXISTS přidává odlišné řazení, od kterého byste očekávali, že zvýší náklady, i když v tomto případě to skončí tím, že provede méně čtení:

 Plánujte JOIN k tabulce fragmentů
Plánujte JOIN k tabulce fragmentů 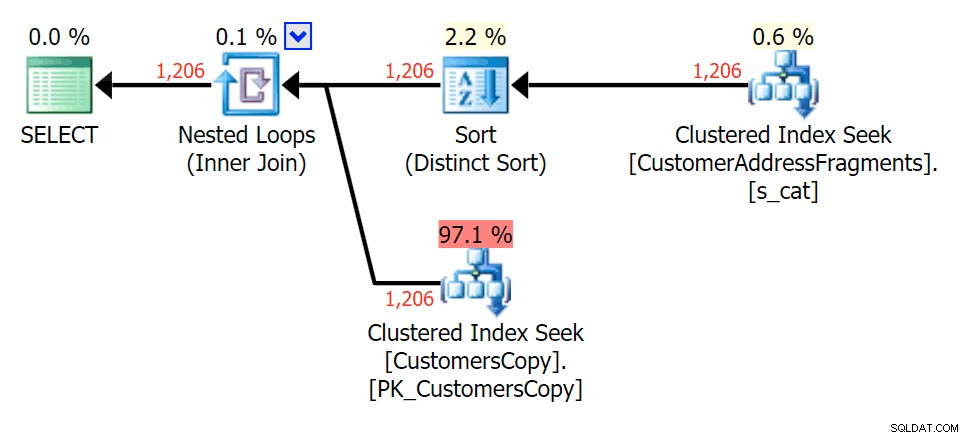 Plánujte EXISTUJE proti tabulce fragmentů
Plánujte EXISTUJE proti tabulce fragmentů cova%
Když z našeho predikátu odstraníme některá písmena, vidíme hodnoty ve skutečnosti o něco vyšší než u původního skenování shlukovaného indexu a nyní přejdeme - odhadnout řádky. I přesto zůstává naše trvání výrazně nižší u obou fragmentových dotazů; rozdíl je tentokrát jemnější – oba mají své druhy (rozlišuje se pouze EXISTS):

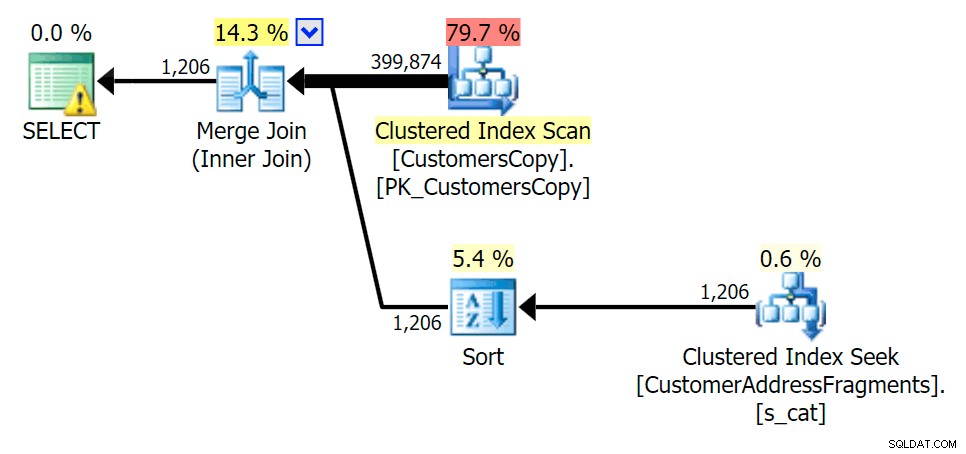 Plánujte JOIN k tabulce fragmentů
Plánujte JOIN k tabulce fragmentů 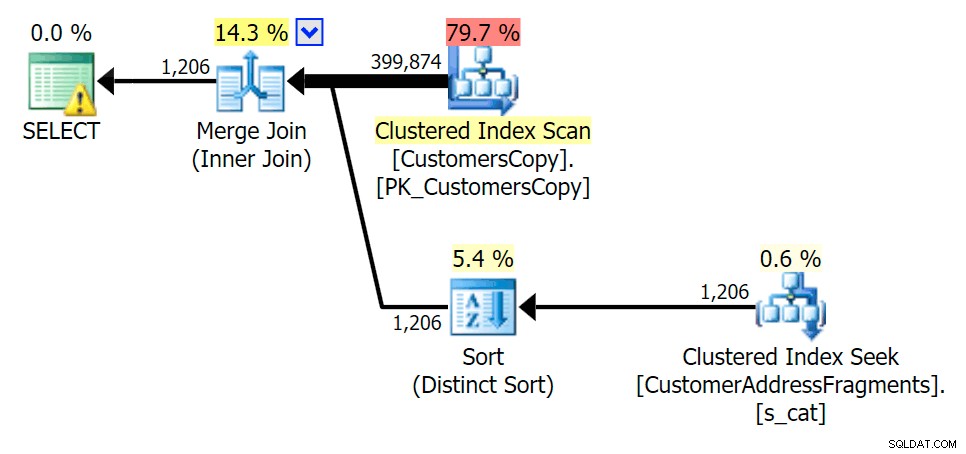 Plánujte EXISTUJE proti tabulce fragmentů
Plánujte EXISTUJE proti tabulce fragmentů ova%
Odstranění dalšího písmene se příliš nezměnilo; i když stojí za zmínku, jak moc zde přeskakují odhadované a skutečné řádky – což znamená, že se může jednat o běžný vzor podřetězců. Původní dotaz LIKE je stále o něco pomalejší než fragmentové dotazy.

 Plánujte JOIN k tabulce fragmentů
Plánujte JOIN k tabulce fragmentů 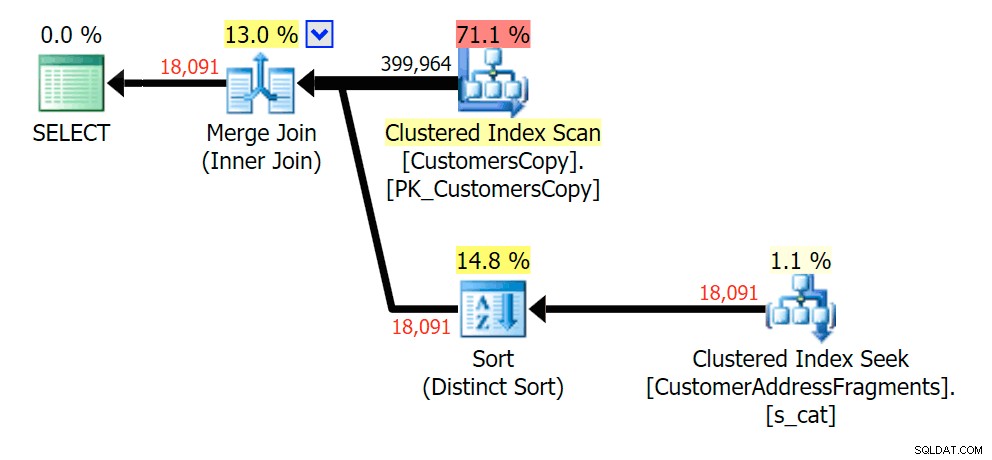 Plánujte EXISTUJE proti tabulce fragmentů
Plánujte EXISTUJE proti tabulce fragmentů va%
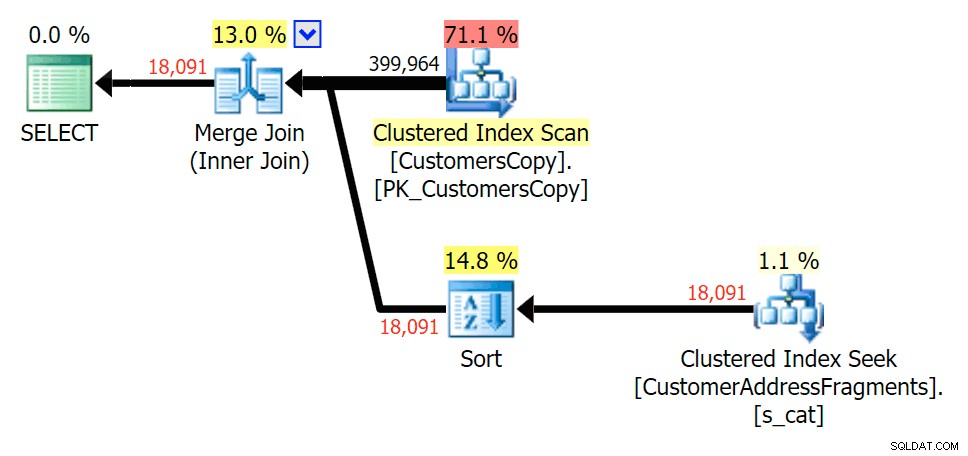
Až na dvě písmena to představuje naši první nesrovnalost. Všimněte si, že JOIN přináší více řádků než původní dotaz nebo EXISTS. Proč by to bylo?

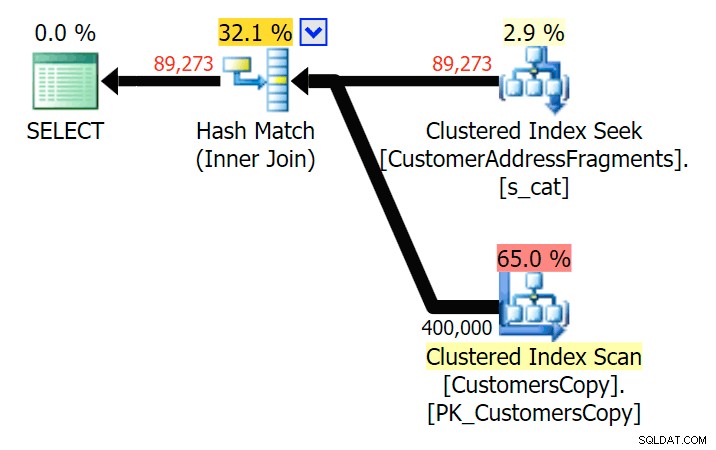 Plánujte JOIN k tabulce fragmentů
Plánujte JOIN k tabulce fragmentů 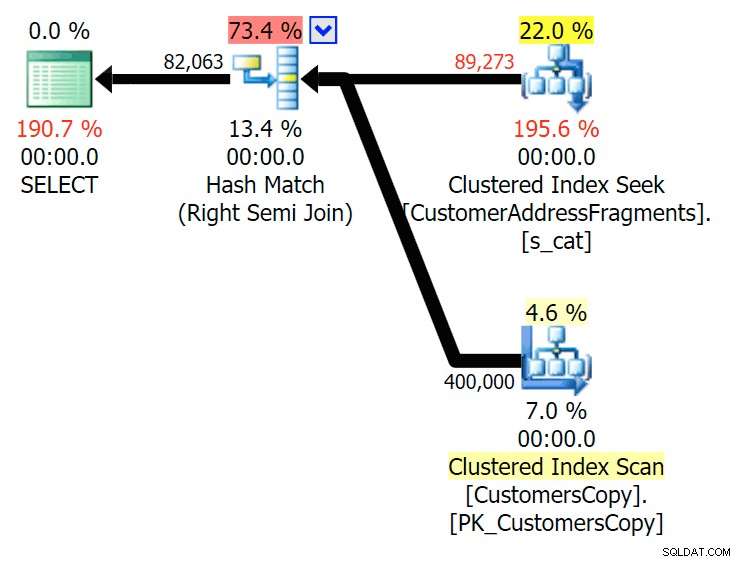 Plánujte EXISTUJE proti tabulce fragmentů Nemusíme hledat daleko. Pamatujte, že od každého následujícího znaku v původní adrese začíná fragment, což znamená něco jako
Plánujte EXISTUJE proti tabulce fragmentů Nemusíme hledat daleko. Pamatujte, že od každého následujícího znaku v původní adrese začíná fragment, což znamená něco jako 899 Valentova Road bude mít v tabulce fragmentů dva řádky, které začínají va (rozlišování velkých a malých písmen stranou). Shodujete se tedy na obou Fragment = N'Valentova Road' a Fragment = N'va Road' . Ušetřím vám hledání a uvedu jeden příklad z mnoha: SELECT TOP (2) c.CustomerID, c.DeliveryAddressLine2, f.Fragment FROM Sales.CustomersCopy AS c INNER JOIN Sales.CustomerAddressFragments AS f ON c.CustomerID = f.CustomerID WHERE f.Fragment LIKE N'va%' AND c.DeliveryAddressLine2 = N'899 Valentova Road' AND f.CustomerID = 351; /* CustomerID DeliveryAddressLine2 Fragment ---------- -------------------- -------------- 351 899 Valentova Road va Road 351 899 Valentova Road Valentova Road */
To snadno vysvětluje, proč JOIN vytváří více řádků; pokud chcete odpovídat výstupu původního dotazu LIKE, měli byste použít EXISTS. Skutečnost, že správné výsledky lze obvykle získat také méně náročným způsobem, je jen bonus. (Byl bych nervózní, kdyby si lidé zvolili JOIN, pokud by to byla opakovaně efektivnější možnost – vždy byste měli upřednostňovat správné výsledky před obavami o výkon.)
Shrnutí
Je jasné, že v tomto konkrétním případě – se sloupcem adresy nvarchar(60) a maximální délka 26 znaků – rozdělení každé adresy na fragmenty může přinést určitou úlevu při jinak nákladném vyhledávání „hlavních zástupných znaků“. Zdá se, že k lepšímu zisku dochází, když je vyhledávací vzorec větší a v důsledku toho jedinečnější. Také jsem ukázal, proč je EXISTS lepší ve scénářích, kde je možné více shod – s JOIN získáte redundantní výstup, pokud nepřidáte nějakou logiku „největší n na skupinu“.
Upozornění
Budu první, kdo připustí, že toto řešení je nedokonalé, neúplné a nedomyšlené:
- Budete muset udržovat tabulku fragmentů synchronizovanou se základní tabulkou pomocí spouštěčů – nejjednodušší by bylo pro vkládání a aktualizace, smazat všechny řádky pro tyto zákazníky a znovu je vložit a pro smazání samozřejmě odstranit řádky z fragmentů stůl.
- Jak bylo uvedeno, toto řešení fungovalo lépe pro tuto konkrétní velikost dat a nemusí fungovat tak dobře pro jiné délky řetězců. Vyžadovalo by to další testování, aby bylo zajištěno, že je vhodný pro vaši velikost sloupce, průměrnou délku hodnoty a typickou délku vyhledávacího parametru.
- Vzhledem k tomu, že budeme mít spoustu kopií fragmentů, jako je „Půlměsíc“ a „Ulice“ (nehledě na všechny stejné nebo podobné názvy ulic a čísla domů), můžeme je dále normalizovat uložením každého jedinečného fragmentu do tabulky fragmentů, a pak ještě další tabulku, která funguje jako spojovací tabulka many-to-many. To by bylo mnohem obtížnější nastavovat a nejsem si jistý, že bych tím mohl hodně získat.
- Ještě jsem plně nezkoumal kompresi stránky, zdá se, že – alespoň teoreticky – by to mohlo přinést určité výhody. Také mám pocit, že implementace columnstore může být v některých případech také prospěšná.
Každopádně, všechno, co bylo řečeno, jsem to chtěl sdílet jako rozvíjející se nápad a vyžádat si jakoukoli zpětnou vazbu ohledně jeho praktičnosti pro konkrétní případy použití. Pokud mi dáte vědět, jaké aspekty tohoto řešení vás zajímají, mohu se ponořit do podrobností pro budoucí příspěvek.