Minulý týden jsem během konference GroupBy prezentoval svou relaci T-SQL:Bad Habits and Best Practices. Záznam videa a další materiály jsou k dispozici zde:
- T-SQL:Špatné návyky a doporučené postupy
Jednou z věcí, které v této relaci vždy zmiňuji, je, že při odstraňování duplikátů obecně preferuji GROUP BY před DISTINCT. Zatímco DISTINCT lépe vysvětluje záměr a GROUP BY je vyžadováno pouze v případě, že jsou přítomny agregace, jsou v mnoha případech zaměnitelné.
Začněme něčím jednoduchým pomocí Wide World Importers. Tyto dva dotazy poskytují stejný výsledek:
SELECT DISTINCT Description FROM Sales.OrderLines; SELECT Description FROM Sales.OrderLines GROUP BY Description;
A ve skutečnosti odvodit jejich výsledky pomocí přesně stejného plánu provádění:

Stejné operátory, stejný počet čtení, zanedbatelné rozdíly v CPU a celkovém trvání (střídají se ve „vítězích“).
Proč bych tedy doporučoval používat srozumitelnější a méně intuitivní syntaxi GROUP BY oproti DISTINCT? No, v tomto jednoduchém případě jde o hod mincí. Ve složitějších případech však může DISTINCT nakonec udělat více práce. DISTINCT v podstatě shromažďuje všechny řádky, včetně výrazů, které je třeba vyhodnotit, a poté vyhazuje duplikáty. GROUP BY může (opět v některých případech) odfiltrovat duplicitní řádky před provádění jakékoli z těchto prací.
Pojďme se bavit například o agregaci řetězců. Zatímco v SQL Server v.Next budete moci používat STRING_AGG (viz příspěvky zde a zde), my ostatní musíme pokračovat s FOR XML PATH (a než mi řeknete, jak úžasné jsou k tomu rekurzivní CTE, prosím přečtěte si také tento příspěvek). Můžeme mít dotaz jako je tento, který se pokouší vrátit všechny objednávky z tabulky Sales.OrderLines spolu s popisy položek jako seznam oddělený svislou čarou:
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Toto je typický dotaz pro řešení tohoto druhu problému s následujícím plánem provádění (upozornění ve všech plánech se týká pouze implicitní konverze vycházející z filtru XPath):
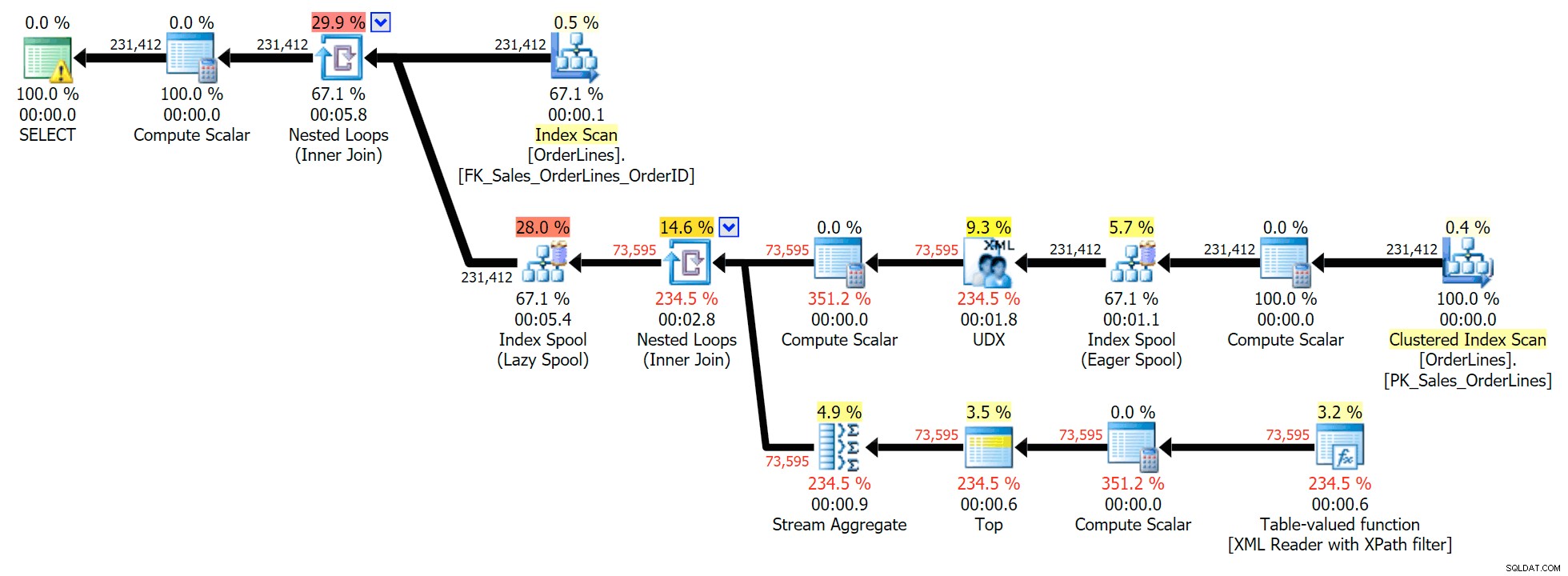
Má však problém, kterého si můžete všimnout ve výstupním počtu řádků. Určitě to můžete zaznamenat při náhodném skenování výstupu:

U každé objednávky vidíme seznam oddělený svislou čarou, ale pro každou položku vidíme řádek v každé objednávce. Prudká reakce je hodit DISTINCT na seznam sloupců:
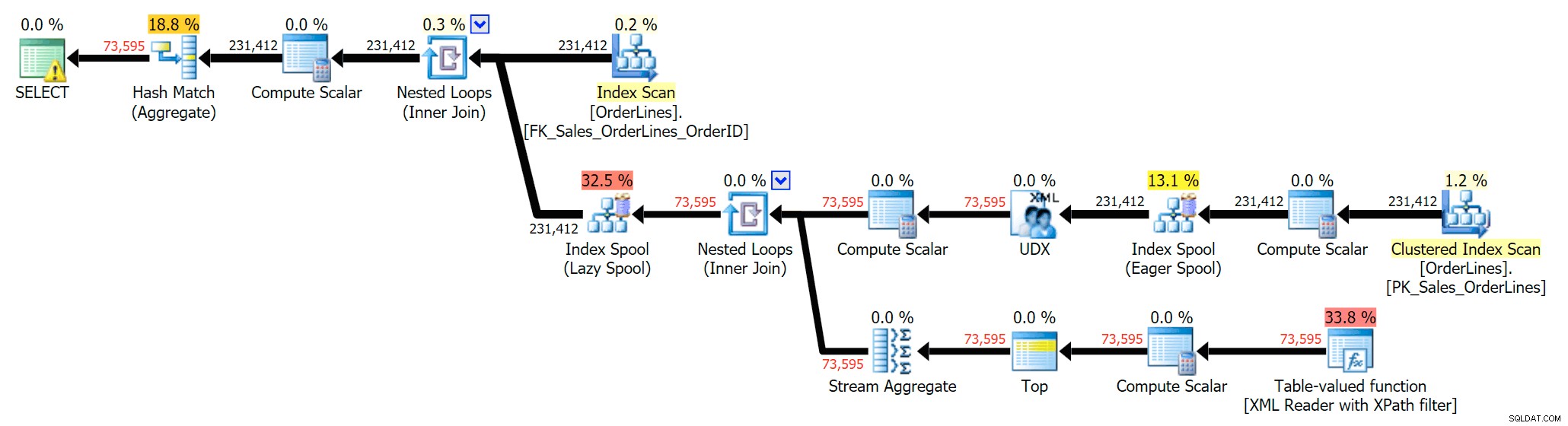
SELECT DISTINCT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Tím se odstraní duplikáty (a změní se vlastnosti řazení na skenech, takže výsledky se nemusí nutně objevit v předvídatelném pořadí) a vytvoří se následující plán provádění:
Dalším způsobem, jak toho dosáhnout, je přidat GROUP BY pro OrderID (protože poddotaz výslovně nepotřebuje být znovu odkazován v GROUP BY):
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o GROUP BY o.OrderID;
Výsledkem jsou stejné výsledky (ačkoli objednávka se vrátila) a mírně odlišný plán:
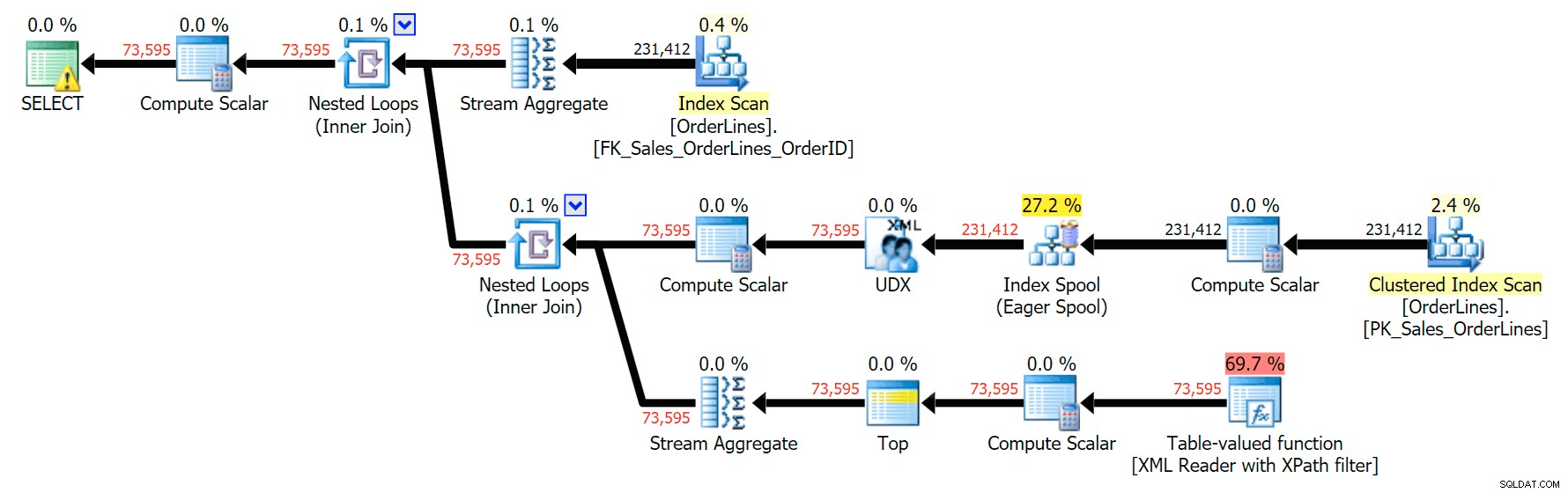
Metriky výkonu jsou však zajímavé pro srovnání.

Varianta DISTINCT trvala 4X tak dlouho, využívala 4X CPU a téměř 6X čtení ve srovnání s variantou GROUP BY. (Pamatujte si, že tyto dotazy vracejí přesně stejné výsledky.)
Můžeme také porovnat prováděcí plány, když změníme náklady z kombinace CPU + I/O na pouze I/O, což je funkce exkluzivní pro Plan Explorer. Zobrazujeme také přeúčtované hodnoty (které jsou založeny na skutečných náklady pozorované během provádění dotazu, což je funkce, kterou lze nalézt také pouze v Průzkumníku plánu). Zde je DISTINCT plán:
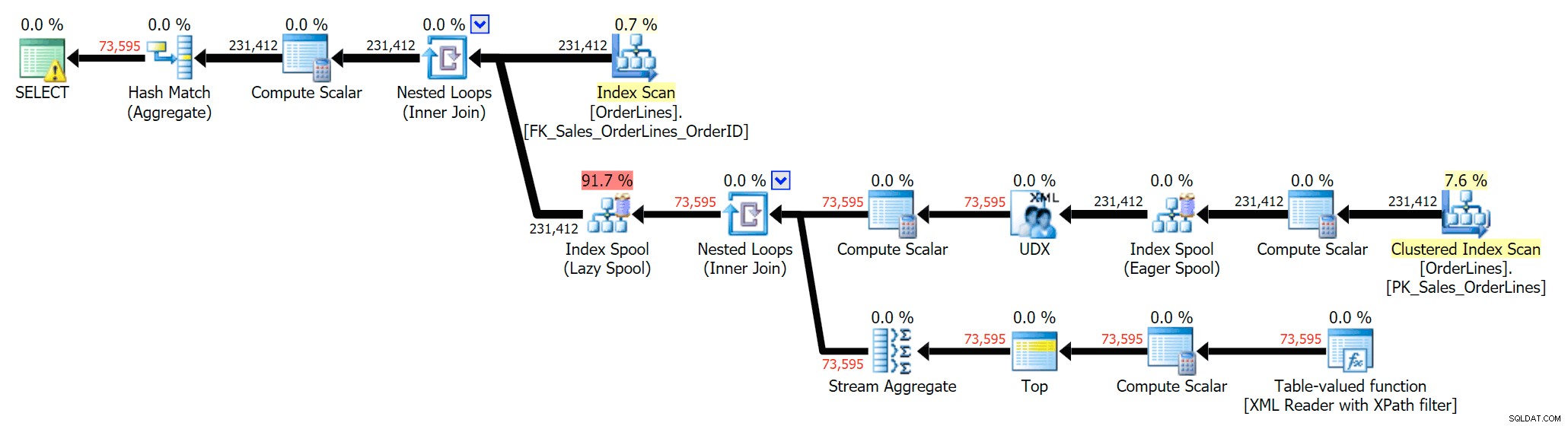
A zde je plán GROUP BY:
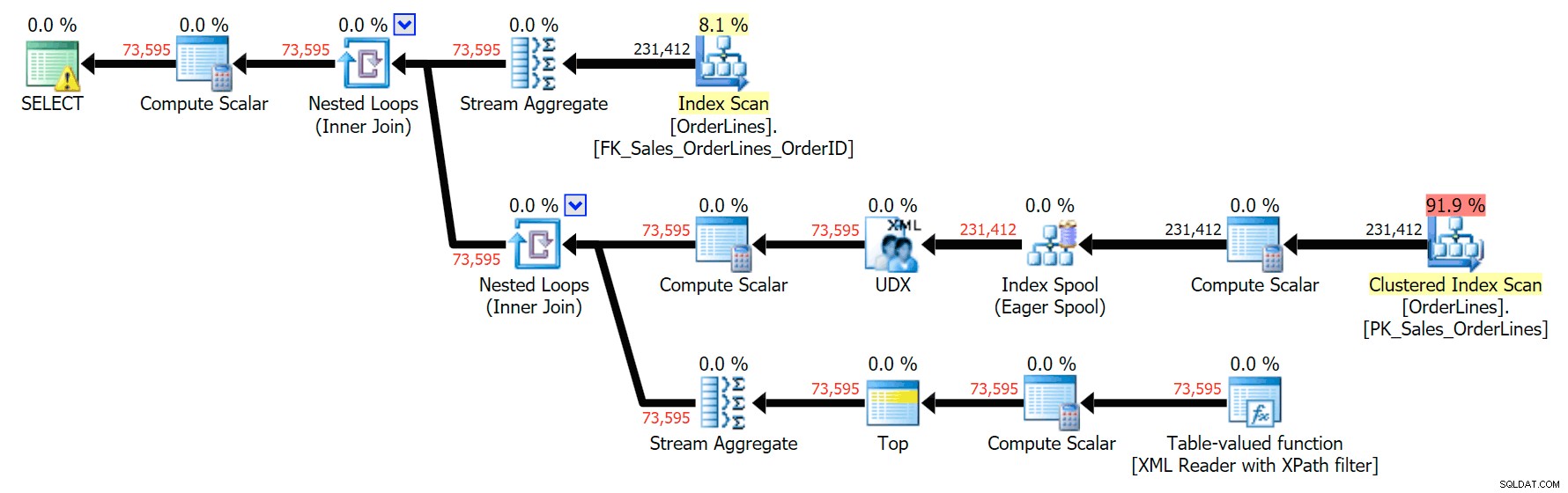
Můžete vidět, že v plánu GROUP BY jsou téměř všechny I/O náklady na skenování (zde je popis pro skenování CI, který ukazuje cenu I/O ~3,4 "dotazů"). Přesto v plánu DISTINCT je většina I/O nákladů v indexovém zařazování (a zde je tento popis; cena I/O je zde ~41,4 "dotazů"). Všimněte si, že CPU je také mnohem vyšší s indexovou cívkou. O „dotazech“ si povíme jindy, ale jde o to, že zařazování indexů je více než 10x dražší než skenování – přesto je skenování v obou plánech stále stejné 3,4. To je jeden z důvodů, proč mě vždy štve, když lidé říkají, že potřebují „opravit“ operátora v plánu s nejvyššími náklady. Některý operátor v plánu bude vždy být nejdražší; to neznamená, že to musí být opraveno.
@AaronBertrand tyto dotazy nejsou ve skutečnosti logicky ekvivalentní — DISTINCT je v obou sloupcích, zatímco vaše GROUP BY je pouze v jednom
— Adam Machanic (@AdamMachanic) 20. ledna 2017
I když má Adam Machanic pravdu, když říká, že tyto dotazy jsou sémanticky odlišné, výsledek je stejný – dostaneme stejný počet řádků, které obsahují úplně stejné výsledky, a udělali jsme to s mnohem menším počtem čtení a CPU.
Takže zatímco DISTINCT a GROUP BY jsou v mnoha scénářích totožné, zde je jeden případ, kdy přístup GROUP BY rozhodně vede k lepšímu výkonu (za cenu méně jasného deklarativního záměru v samotném dotazu). Zajímalo by mě, jestli si myslíte, že existují nějaké scénáře, kdy je DISTINCT lepší než GROUP BY, alespoň pokud jde o výkon, který je mnohem méně subjektivní než styl nebo zda prohlášení musí být samodokumentující.
Tento příspěvek zapadá do mé série „překvapení a domněnky“, protože mnoho věcí, které považujeme za pravdy založené na omezených pozorováních nebo konkrétních případech použití, lze otestovat při použití v jiných scénářích. Jen si musíme pamatovat, že tomu musíme věnovat čas v rámci optimalizace dotazů SQL…
Odkazy
- Skupinové zřetězení v SQL Server
- Skupinové zřetězení:řazení a odstraňování duplikátů
- Čtyři praktické případy použití pro seskupené zřetězení
- SQL Server v. Next:Výkon STRING_AGG()
- SQL Server v.Next:Výkon STRING_AGG, část 2