Minulý měsíc jsem řešil výzvu Special Islands. Úkolem bylo identifikovat období aktivity pro každé ID služby, tolerovat mezeru až do vstupního počtu sekund (@allowedgap ). Upozornění bylo, že řešení muselo být kompatibilní před rokem 2012, takže jste nemohli používat funkce jako LAG a LEAD nebo agregovat funkce okna s rámem. V komentářích od Tobyho Ovoda-Everetta, Petera Larssona a Kamila Kosna jsem dostal řadu velmi zajímavých řešení. Nezapomeňte si projít jejich řešení, protože všechna jsou docela kreativní.
Je zajímavé, že řada řešení běžela s doporučeným indexem pomaleji než bez něj. V tomto článku pro to navrhuji vysvětlení.
I když byla všechna řešení zajímavá, zde jsem se chtěl zaměřit na řešení Kamila Kosna, který je ETL vývojářem se Zopa. Kamil ve svém řešení použil velmi kreativní techniku k napodobení LAG a LEAD bez LAG a LEAD. Pravděpodobně se vám tato technika bude hodit, pokud potřebujete provádět výpočty podobné LAG/LEAD pomocí kódu, který je kompatibilní před rokem 2012.
Proč jsou některá řešení rychlejší bez doporučeného indexu?
Jako připomenutí jsem navrhl použít následující index na podporu řešení problému:
VYTVOŘTE INDEX idx_sid_ltm_lid NA dbo.EventLog(serviceid, logtime, logid);
Moje řešení kompatibilní z doby před rokem 2012 bylo následující:
DECLARE @allowedgap AS INT =66; -- v sekundách WITH C1 AS( SELECT logid, serviceid, logtime AS s, -- důležité, 's'> 'e', pro pozdější objednání DATEADD(sekunda, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach FROM dbo.EventLog),C2 AS( SELECT logid, serviceid, logtime, eventtype, counteach, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth FROM C1 UNPIVOT(logtime FOR eventtype IN (s, e)) AS U),C3 AS( SELECT serviceid, eventtype, logtime, (ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 JAKO grp OD C2 CROSS APPLY ( VALUES( CASE WHEN eventtype ='s' THEN counteach - (countboth - counteach) WHEN eventtype ='e' THEN (countboth - counteach) - counteach END ) ) AS A(countactive) WHERE ( eventtype ='s' AND countactive =1) NEBO (typ události ='e' AND countactive =0))SELECT serviceid, s AS počáteční čas, DATEADD(sekunda, -@povolená mezera, e) AS koncový časFROM C3 PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P;
Obrázek 1 obsahuje plán mého řešení s doporučeným indexem na místě.
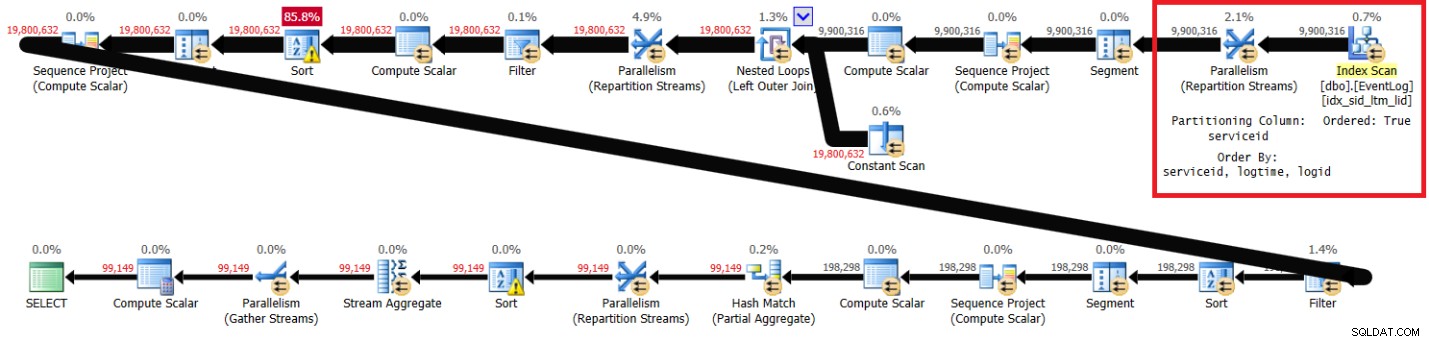 Obrázek 1:Plán Itzikova řešení s doporučeným indexem
Obrázek 1:Plán Itzikova řešení s doporučeným indexem
Všimněte si, že plán prohledá doporučený index v pořadí klíčů (vlastnost Ordered je True), rozdělí proudy podle serviceid pomocí výměny se zachováním pořadí a poté použije počáteční výpočet čísel řádků podle pořadí indexu bez nutnosti řazení. Níže jsou uvedeny statistiky výkonu, které jsem získal pro toto provedení dotazu na mém notebooku (uplynulý čas, čas CPU a nejvyšší čekání vyjádřené v sekundách):
uplynulo:43, CPU:60, logická čtení:144 120 , nejvyšší čekání:CXPACKET:166
Poté jsem zrušil doporučený index a znovu spustil řešení:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;
Mám plán zobrazený na obrázku 2.
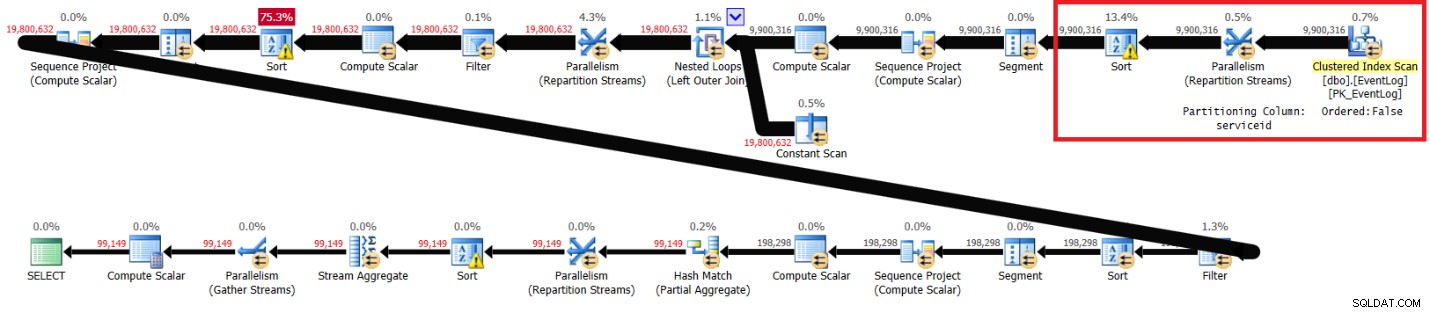 Obrázek 2:Plán Itzikova řešení bez doporučeného indexu
Obrázek 2:Plán Itzikova řešení bez doporučeného indexu
Zvýrazněné části ve dvou plánech ukazují rozdíl. Plán bez doporučeného indexu provede neuspořádané prohledávání seskupeného indexu, rozdělí proudy podle serviceid pomocí výměny nezachovávající pořadí a pak seřadí řádky, jak potřebuje funkce okna (podle serviceid, logtime, logid). Zbytek práce se zdá být v obou plánech stejný. Mysleli byste si, že plán bez doporučeného indexu by měl být pomalejší, protože má další řazení, které druhý plán nemá. Ale zde jsou statistiky výkonu, které jsem získal pro tento plán na svém notebooku:
uplynulo:31, CPU:89, logická čtení:172 598 , CXPACKET čeká:84
Je s tím spojeno více času CPU, což je částečně způsobeno zvláštním řazením; je zapojeno více I/O, pravděpodobně kvůli dalšímu rozlití; uplynulý čas je však asi o 30 procent rychlejší. Co by to mohlo vysvětlit? Jedním ze způsobů, jak to zkusit a přijít na to, je spustit dotaz v SSMS s povolenou možností Live Query Statistics. Když jsem to udělal, operátor Parallelism (Repartition Streams) úplně vpravo skončil za 6 sekund bez doporučeného indexu a za 35 sekund s doporučeným indexem. Klíčový rozdíl je v tom, že první získává data předobjednaná z indexu a jedná se o výměnu uchovávající objednávky. Ten získá data neuspořádaná a nejedná se o výměnu zachovávající objednávku. Burzy zachovávající objednávky bývají dražší než burzy nezachovávající objednávky. Také alespoň v pravé části plánu až do prvního řazení první řazení dodává řádky ve stejném pořadí jako sloupec rozdělení na výměnu, takže nemusíte všechna vlákna skutečně zpracovávat paralelně. Pozdější dodává řádky neuspořádané, takže všechna vlákna zpracovávají řádky skutečně paralelně. Můžete vidět, že nejvyšší čekání v obou plánech je CXPACKET, ale v prvním případě je čekací doba dvojnásobná oproti druhému, což vám říká, že zpracování paralelismu v druhém případě je optimálnější. Ve hře mohou být další faktory, o kterých nepřemýšlím. Pokud máte další nápady, které by mohly vysvětlit překvapivý rozdíl ve výkonu, podělte se o ně.
Na mém notebooku to vedlo ke spuštění, aniž by byl doporučený index rychlejší než ten s doporučeným indexem. Přesto na jiném testovacím stroji to bylo naopak. Koneckonců, máte zvláštní druh s potenciálem rozlití.
Ze zvědavosti jsem otestoval sériové provedení (s možností MAXDOP 1) s doporučeným indexem a na svém notebooku jsem získal následující statistiky výkonu:
uplynulo:42, CPU:40, logická čtení:143 519
Jak můžete vidět, doba běhu je podobná době běhu paralelního provádění s doporučeným indexem na místě. V notebooku mám pouze 4 logické CPU. Váš počet najetých kilometrů se samozřejmě může lišit podle různého hardwaru. Jde o to, že stojí za to vyzkoušet různé alternativy, včetně indexování a bez něj, o kterém si myslíte, že by to mělo pomoci. Výsledky jsou někdy překvapivé a kontraintuitivní.
Kamilovo řešení
Kamilovo řešení mě opravdu zaujalo a obzvláště se mi líbilo, jak emuloval LAG a LEAD pomocí techniky kompatibilní z doby před rokem 2012.
Zde je kód implementující první krok řešení:
SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER (PARTITION BY serviceid ORDER BY logtime) - 1 AS start_timeFROM dbo.EventLog;
Tento kód generuje následující výstup (zobrazuje pouze data pro serviceid 1):
serviceid logtime end_time start_time---------- -------------------- --------- ---- -------1 2018-09-12 08:00:00 1 01 2018-09-12 08:01:01 2 11 2018-09-12 08:01:59 3 21 2018-09-12 08 :03:00 4 31 2018-09-12 08:05:00 5 41 2018-09-12 08:06:02 6 5...
Tento krok vypočítá dvě čísla řádků, která jsou pro každý řádek jedno, rozdělená podle serviceid a seřazená podle logtime. Číslo aktuálního řádku představuje čas ukončení (nazývejte ho end_time) a číslo aktuálního řádku mínus jedna představuje čas zahájení (říkejte mu čas_počátečního_času).
Následující kód implementuje druhý krok řešení:
WITH RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER (PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER (PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog)SELECT * FROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U;
Tento krok generuje následující výstup:
serviceid logtime rownum time_type---------- -------------------- ------- ------ -----1 2018-09-12 08:00:00 0 start_time1 2018-09-12 08:00:00 1 end_time1 2018-09-12 08:01:01 1 start_time1 2018-09-112 08 :01 2 end_time1 2018-09-12 08:01:59 2 start_time1 2018-09-12 08:01:59 3 end_time1 2018-09-12 08:03:00 3 start_time1 2018-08-09-09 4 end_time1 2018-09-12 08:05:00 4 start_time1 2018-09-12 08:05:00 5 end_time1 2018-09-12 08:06:02 5 start_time1 2018-08:06:02 62 ...
Tento krok rozloží každý řádek na dva řádky a zduplikuje každý záznam protokolu – jednou pro typ času start_time a další pro end_time. Jak vidíte, kromě minimálního a maximálního počtu řádků se každé číslo řádku zobrazuje dvakrát – jednou s časem protokolu aktuální události (start_time) a další s časem protokolu předchozí události (end_time).
Následující kód implementuje třetí krok v řešení:
WITH RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER (PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER (PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog)SELECT * FROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P;
Tento kód generuje následující výstup:
serviceid rownum start_time end_time----------- -------------------- ------------ --------------- ---------------------------1 0 2018-09-12 08 :00:00 NULL1 1 2018-09-12 08:01:01 2018-09-12 08:00:001 2 2018-09-12 08:01:59 2018-09-12 08:31:018 09-12 08:03:00 2018-09-12 08:01:591 4 2018-09-12 08:05:00 2018-09-12 08:03:001 5 2018-09-12:028:06 2018-09-12 08:05:001 6 NULL 2018-09-12 08:06:02...
Tento krok provádí pivotování dat, seskupuje páry řádků se stejným číslem řádku a vrací jeden sloupec pro aktuální čas protokolu událostí (start_time) a další pro předchozí čas protokolu událostí (end_time). Tato část efektivně emuluje funkci LAG.
Následující kód implementuje čtvrtý krok v řešení:
DECLARE @allowedgap AS INT =66; WITH RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER (PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER (PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog)SELECT serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grpFROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U PIVOT MAX(log time) FOR time_type IN(start_time, end_time)) AS PWHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1)> @allowedgap;
Tento kód generuje následující výstup:
serviceid rownum start_time end_time start_time_grp end_time_grp---------- ------- ------------------- ---- ---------------- --------------- -------------1 09. 2018- 12 08:00:00 NULL 1 01 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 11 6 NULL 2018-09-12 08:06:02 3 2... /před>Tento krok filtruje páry, kde je rozdíl mezi předchozím časem ukončení a aktuálním časem zahájení větší než povolená mezera, a řádky s pouze jednou událostí. Nyní musíte propojit počáteční čas každého aktuálního řádku s časem ukončení dalšího řádku. To vyžaduje výpočet podobný LEAD. Aby toho dosáhl, kód opět vytváří čísla řádků, která jsou od sebe jedna, pouze tentokrát číslo aktuálního řádku představuje počáteční čas (start_time_grp ) a aktuální číslo řádku mínus jedna představuje čas ukončení (end_time_grp).
Stejně jako předtím je dalším krokem (číslo 5) uvolnění řad. Zde je kód implementující tento krok:
DECLARE @allowedgap AS INT =66; WITH RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER (PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER (PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog),Rozsahy jako ( SELECT serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp FROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time) ) AS U PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1)> @allowedgap)SELECT *FROM Rozsahy UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U;Výstup:
serviceid rownum start_time end_time grp grp_type---------- ------- -------------------- ---- ---------------- ---- ---------------1 0 2018-09-12 08:00:00 NULL 0 end_time_grp1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 end_time_grp1 0 2018-09-12 08:00:00 NULL 1 start_time_grp1 6 NULL-2018-09 NULL-2018-09 end_time_grp1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 start_time_grp1 6 NULL 2018-09-12 08:06:02 3 start_time_grp...Jak můžete vidět, sloupec grp je jedinečný pro každý ostrov v rámci ID služby.
Krok 6 je posledním krokem v řešení. Zde je kód implementující tento krok, který je také úplným kódem řešení:
DECLARE @allowedgap AS INT =66; WITH RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER (PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER (PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog),Rozsahy jako ( SELECT serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp FROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time) ) AS U PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P WHERE ISNULL(DATEDIFF(sekunda, konec_time, start_time), @allowedgap + 1)> @allowedgap)SELECT serviceid, MIN(start_time) AS start_time , MAX(end_time) AS end_timeFROM Rozsahy UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS UGROUP BY serviceid, grpHAVING (MIN(start_time) NENÍ NULL A MAX(end_time) NENÍ NULL);Tento krok generuje následující výstup:
serviceid start_time end_time----------- -------------------------- ------ ---------------------1 2018-09-12 08:00:00 2018-09-12 08:03:001 2018-09-12 08:05 :00 2018-09-12 08:06:02...Tento krok seskupuje řádky podle serviceid a grp, filtruje pouze relevantní skupiny a vrací minimální čas začátku jako začátek ostrova a maximální čas ukončení jako konec ostrova.
Obrázek 3 ukazuje plán, který jsem získal pro toto řešení s doporučeným indexem:
VYTVOŘTE INDEX idx_sid_ltm_lid NA dbo.EventLog(serviceid, logtime, logid);Plán s doporučeným indexem na obrázku 3.
Obrázek 3:Plán Kamilova řešení s doporučeným indexem
Zde jsou statistiky výkonu, které jsem získal pro toto provedení na svém notebooku:
uplynulo:44, CPU:66, logická čtení:72979, horní čekání:CXPACKET:148Poté jsem zrušil doporučený index a znovu spustil řešení:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;Získal jsem plán znázorněný na obrázku 4 pro provedení bez doporučeného indexu.
Obrázek 4:Plán Kamilova řešení bez doporučeného indexu
Zde jsou statistiky výkonu, které jsem získal pro toto provedení:
uplynulo:30, CPU:85, logická čtení:94813, horní čekání:CXPACKET:70Doba běhu, doba CPU a doba čekání CXPACKET jsou velmi podobné mému řešení, i když logické čtení je nižší. Kamilovo řešení také běží rychleji na mém notebooku bez doporučeného indexu a zdá se, že je to z podobných důvodů.
Závěr
Anomálie jsou dobrá věc. Díky nim jste zvědaví a nutí vás, abyste šli zkoumat hlavní příčinu problému, a v důsledku toho se učili nové věci. Je zajímavé vidět, že některé dotazy na určitých počítačích běží rychleji bez doporučeného indexování.
Ještě jednou děkuji Tobymu, Petrovi a Kamilovi za vaše řešení. V tomto článku jsem popsal Kamilovo řešení s jeho kreativní technikou emulovat LAG a LEAD s čísly řádků, unpivoting a pivoting. Tato technika se vám bude hodit, když potřebujete výpočty podobné LAG a LEAD, které musí být podporovány v prostředích před rokem 2012.