V lednu 2015 můj dobrý přítel a kolega MVP pro SQL Server Rob Farley napsal o novém řešení problému hledání mediánu ve verzích SQL Server před rokem 2012. Kromě toho, že je to zajímavé čtení samo o sobě, ukázalo se, že skvělý příklad, který lze použít k demonstraci pokročilé analýzy plánu provádění a ke zvýraznění některých jemných chování optimalizátoru dotazů a prováděcího motoru.
Jeden medián
Ačkoli se Robův článek konkrétně zaměřuje na seskupený výpočet mediánu, začnu tím, že jeho metodu aplikuji na velký problém výpočtu jednoho mediánu, protože nejjasněji zdůrazňuje důležité problémy. Vzorová data budou opět pocházet z původního článku Aarona Bertranda:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); Použití techniky Roba Farleyho na tento problém poskytne následující kód:
-- 5800ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f;
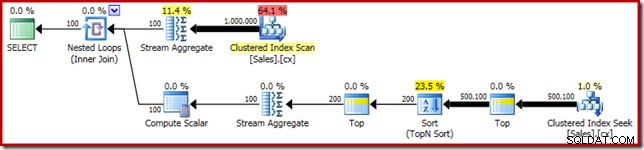
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Jako obvykle jsem zakomentoval počítání počtu řádků v tabulce a nahradil jej konstantou, abych se vyhnul zdroji odchylek ve výkonu. Plán provádění důležitého dotazu je následující:

Tento dotaz běží 5800 ms na mém testovacím zařízení.
Rozlití řazení
Hlavní příčina tohoto slabého výkonu by měla být zřejmá z výše uvedeného plánu provádění:Varování na operátoru Sort ukazuje, že nedostatečné přidělení paměti pracovního prostoru způsobilo přelití úrovně 2 (víceprůchodové) do fyzické tempdb disk:
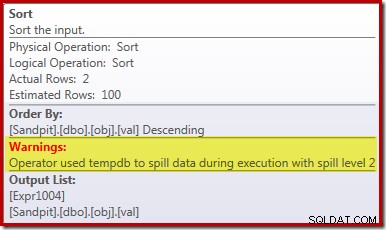
Ve verzích SQL Server před rokem 2012 byste museli samostatně monitorovat události seřazení, abyste to viděli. Nedostatečná rezervace paměti pro řazení je každopádně způsobena chybou odhadu mohutnosti, jak ukazuje plán před provedením (odhad):

Odhad mohutnosti 100 řádků na vstupu pro řazení je (zcela nepřesný) odhad optimalizátoru kvůli výrazu lokální proměnné v předchozím operátoru Top:

Všimněte si, že tato chyba odhadu mohutnosti nepředstavuje problém cíle řádku. Použití příznaku trasování 4138 odstraní efekt cíle řádku pod prvním horním, ale odhad po horním bude stále odhadem 100 řádků (takže rezervace paměti pro řazení bude stále příliš malá):

Nápověda hodnoty lokální proměnné
Existuje několik způsobů, jak bychom mohli vyřešit tento problém odhadu mohutnosti. Jednou z možností je použít nápovědu, která poskytne optimalizátoru informace o hodnotě obsažené v proměnné:
-- 3250ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, OPTIMIZE FOR (@Count = 11000000)); -- NEW!
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Použití nápovědy zvyšuje výkon na 3250 ms od 5800 ms. Plán po provedení ukazuje, že řazení se již nerozlévá:

Má to však několik nevýhod. Za prvé, tento nový plán provádění vyžaduje 388 MB přidělení paměti – paměť, kterou by server jinak mohl použít k ukládání plánů, indexů a dat do mezipaměti:
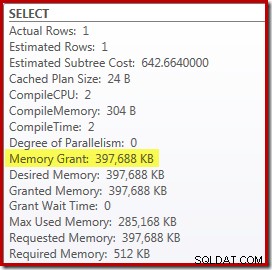
Za druhé, může být obtížné vybrat dobré číslo pro nápovědu, které bude dobře fungovat pro všechna budoucí provedení, aniž by se zbytečně vyhradilo paměť.
Všimněte si také, že jsme museli naznačit hodnotu proměnné, která je o 10 % vyšší než skutečná hodnota proměnné, abychom zcela eliminovali únik. To není neobvyklé, protože obecný algoritmus třídění je poněkud složitější než jednoduché třídění na místě. Rezervování paměti rovnající se velikosti množiny, která má být tříděna, nebude vždy (nebo dokonce obecně) stačit k tomu, aby se předešlo úniku za běhu.
Vkládání a překompilování
Další možností je využít optimalizaci vkládání parametrů povolenou přidáním nápovědy pro rekompilaci na úrovni dotazu na SQL Server 2008 SP1 CU5 nebo novější. Tato akce umožní optimalizátoru vidět runtime hodnotu proměnné a podle toho optimalizovat:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, RECOMPILE);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Tím se zkrátí doba provádění na 3150 ms – O 100 ms lepší než při použití OPTIMIZE FOR náznak. Důvod tohoto dalšího malého zlepšení lze zjistit z nového plánu po provedení:

Výraz (2 – @Count % 2) – jak bylo vidět dříve u druhého horního operátoru – lze nyní složit na jedinou známou hodnotu. Přepsání po optimalizaci pak může zkombinovat začátek s řazením, což vede k jedinému řazení Top N. Tento přepis nebyl dříve možný, protože sbalení Top + Sort do Top N Sort funguje pouze s konstantní doslovnou hodnotou Top (nikoli proměnnými nebo parametry).
Nahrazení Top a Sort za Top N Sort má malý příznivý vliv na výkon (zde 100 ms), ale také téměř úplně eliminuje potřebu paměti, protože Top N Sort musí sledovat pouze N nejvyšší (nebo nejnižší) řádky, spíše než celou sadu. V důsledku této změny v algoritmu plán po provedení tohoto dotazu ukazuje, že minimálně 1 MB paměť byla v tomto plánu vyhrazena pro Top N řazení a pouze 16 kB byl použit za běhu (nezapomeňte, že plán úplného třídění vyžadoval 388 MB):
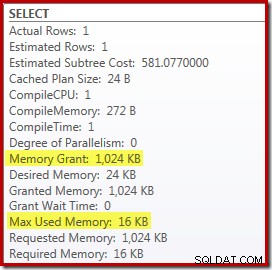
Vyhýbání se rekompilaci
(Zřejmou) nevýhodou použití nápovědy pro rekompilaci dotazu je, že vyžaduje úplnou kompilaci při každém spuštění. V tomto případě je režie poměrně malá – přibližně 1 ms času CPU a 272 kB paměti. I tak existuje způsob, jak dotaz vyladit tak, abychom získali výhody řazení Top N bez použití jakýchkoli nápověd a bez překompilování.
Myšlenka pochází z uznání, že maximum pro konečný výpočet mediánu bude zapotřebí dvou řádků. Může to být jeden řádek nebo dva za běhu, ale nikdy jich nemůže být více. Tento přehled znamená, že můžeme k dotazu přidat logicky redundantní horní (2) mezikrok takto:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2) -- NEW!
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Nový Top (s velmi důležitým konstantním literálem) znamená, že konečný plán provádění obsahuje požadovaný operátor řazení Top N bez překompilování:

Výkon tohoto spouštěcího plánu se oproti verzi naznačené rekompilací nezměnil na 3150 ms a požadavky na paměť jsou stejné. Všimněte si však, že nedostatek vkládání parametrů znamená, že odhady mohutnosti pod řazením jsou odhady na 100 řádků (ačkoli to zde neovlivňuje výkon).
Hlavním přínosem v této fázi je, že pokud chcete řazení Top N s nízkou pamětí, musíte použít konstantní literál nebo povolit optimalizátoru, aby viděl literál prostřednictvím optimalizace vkládání parametrů.
Výpočetní skalár
Odstranění 388 MB přidělení paměti (a zároveň zvýšení výkonu o 100 ms) se určitě vyplatí, ale je k dispozici mnohem větší výkon. Nepravděpodobným cílem tohoto konečného vylepšení je výpočetní skalár těsně nad Clustered Index Scan.
Tento výpočetní skalár se vztahuje k výrazu (0E + f.val) obsažené v AVG agregovat v dotazu. V případě, že se vám to zdá divné, je to docela běžný trik při psaní dotazů (jako je násobení 1,0), abyste se vyhnuli celočíselné aritmetice při výpočtu průměru, ale má to některé velmi důležité vedlejší účinky.
Je zde určitá sekvence událostí, které musíme krok za krokem sledovat.
Nejprve si všimněte, že 0E je konstantní doslovná nula s float datový typ. Aby bylo možné toto přidat do hodnoty celočíselného sloupce, musí procesor dotazu převést sloupec z celého čísla na plovoucí (v souladu s pravidly priority datových typů). Podobný druh převodu by byl nutný, kdybychom se rozhodli vynásobit sloupec 1,0 (literál s implicitním číselným datovým typem). Důležité je, že tento rutinní trik zavádí výraz .
Nyní se SQL Server obecně snaží posunout výrazy dolů strom plánu během kompilace a optimalizace. Děje se tak z několika důvodů, včetně usnadnění shody výrazů s vypočítanými sloupci a usnadnění zjednodušení pomocí informací o omezeních. Tato zásada posunutí dolů vysvětluje, proč se výpočetní skalár jeví mnohem blíže úrovni listu plánu, než by naznačovala původní textová pozice výrazu v dotazu.
Při provádění tohoto posunutí dolů existuje riziko, že výraz může být vypočítán vícekrát, než je nutné. Většina plánů se vyznačuje snížením počtu řádků, jak se pohybujeme ve stromu plánu nahoru, kvůli efektu spojení, agregace a filtrů. Posunutí výrazů do stromu proto riskuje, že se tyto výrazy vyhodnotí vícekrát (tj. na více řádcích), než je nutné.
Aby se to zmírnilo, zavedl SQL Server 2005 optimalizaci, pomocí které lze výpočetní skalary jednoduše definovat výraz, jehož práce je vlastně hodnocení výraz odložen dokud pozdější operátor v plánu nebude vyžadovat výsledek. Když tato optimalizace funguje tak, jak bylo zamýšleno, výsledkem je získání všech výhod posunutí výrazů do stromu, přičemž se výraz ve skutečnosti vyhodnotí pouze tolikrát, kolikrát je skutečně potřeba.
Co všechno to Compute Scalar znamená
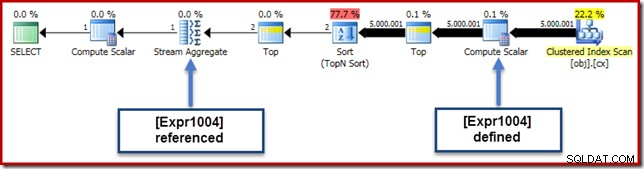
V našem běžícím příkladu 0E + val výraz byl původně spojen s AVG agregovat, takže bychom mohli očekávat, že jej uvidíme na (nebo mírně po) Stream Aggregate. Tento výraz byl však zatlačen strom se stane novým výpočetním skalárem hned po skenování s výrazem označeným jako [Expr1004].
Když se podíváme na plán provádění, můžeme vidět, že na [Expr1004] odkazuje Stream Aggregate (extrakt z karty Plan Explorer Expressions Tab zobrazený níže):

Pokud jsou všechny věci stejné, hodnocení výrazu [Expr1004] by bylo odloženo dokud agregát nebude potřebovat tyto hodnoty pro součtovou část výpočtu průměru. Vzhledem k tomu, že agregace může narazit pouze na jeden nebo dva řádky, mělo by to vést k tomu, že [Expr1004] bude vyhodnocen pouze jednou nebo dvakrát:
Tady to bohužel úplně takhle nefunguje. Problémem je blokující operátor řazení:
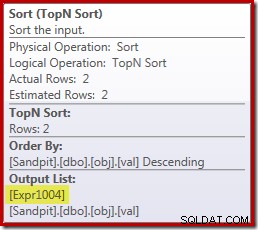
Toto vynutí vyhodnocení [Expr1004], takže místo toho, aby bylo vyhodnoceno jen jednou nebo dvakrát na Stream Aggregate, řazení znamená, že skončíme převodem val sloupec na plovoucí hodnotu a přidáním nuly k němu 5 000 001 krát!
Řešení
V ideálním případě by byl SQL Server v tom všem o něco chytřejší, ale takhle to dnes nefunguje. Neexistuje žádná nápověda k dotazu, která by zabránila posunutí výrazů do stromu plánu, a ani pomocí průvodce plánem nemůžeme vynutit výpočetní skalary. Nevyhnutelně existuje nezdokumentovaný příznak sledování, ale není to ten, o kterém bych v současném kontextu mohl zodpovědně mluvit.
Takže, ať už je to dobré nebo špatné, musíme se snažit najít přepsání dotazu, které zabrání SQL Serveru oddělit výraz od agregace a posouvat jej dolů za řazení, aniž by se změnil výsledek dotazu. Není to tak snadné, jak si možná myslíte, ale (sice trochu zvláštně vypadající) modifikace níže toho dosahuje pomocí CASE výraz na nedeterministické vnitřní funkci:
-- 2150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
-- NEW!
Median = AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + f.val END)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2)
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Plán provádění této konečné podoby dotazu je uveden níže:

Všimněte si, že výpočetní skalár se již nezobrazuje mezi Clustered Index Scan a Top. 0E + val výraz je nyní počítán v Stream Aggregate na maximálně dvou řádcích (namísto pěti milionů!) a výkon se zvyšuje o dalších 32 % od 3150 ms do 2150 ms v důsledku toho.
To stále není v porovnání s výkonem OFFSET pod sekundou a řešení pro výpočet mediánu dynamického kurzoru, ale stále představuje velmi významné zlepšení oproti původním 5800 ms pro tuto metodu na velké sadě problémů s jedním mediánem.
Samozřejmě není zaručeno, že trik CASE bude v budoucnu fungovat. Toto shrnutí není ani tak o používání podivných triků s výrazem případu, jako spíše o potenciálních důsledcích výkonu Compute Scalars. Až budete o něčem takovém vědět, možná si dvakrát rozmyslíte, než vynásobíte 1,0 nebo přidáte do průměrného výpočtu plovoucí nulu.
Aktualizace: podívejte se prosím na první komentář, kde najdete pěkné řešení od Roberta Heiniga, které nevyžaduje žádné nezdokumentované triky. Něco, co byste měli mít na paměti, až budete příště v pokušení násobit celé číslo desetinným (nebo plovoucím) číslem v průměrném souhrnu.
Skupinový medián
Pro úplnost a abychom tuto analýzu blíže spojili s původním Robovým článkem, dokončíme to použitím stejných vylepšení na seskupený výpočet mediánu. Menší velikosti sady (na skupinu) znamenají, že efekty budou samozřejmě menší.
Seskupená střední vzorová data (opět tak, jak byla původně vytvořena Aaronem Bertrandem) obsahuje deset tisíc řádků pro každého ze sta imaginárních prodejců:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount); Přímá aplikace řešení Roba Farleyho poskytne následující kód, který se spustí za 560 ms na mém počítači.
-- 560ms Original
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Prováděcí plán má zjevnou podobnost s jediným mediánem:
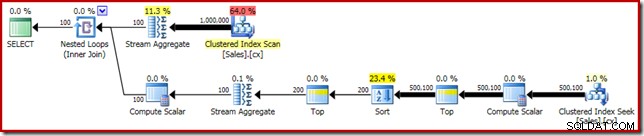
Naším prvním vylepšením je nahrazení Sort seřazením Top N přidáním explicitního Top (2). Tím se mírně prodlouží doba provádění z 560 ms na 550 ms .
-- 550ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
-- NEW!
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Plán provádění zobrazuje podle očekávání Top N řazení:
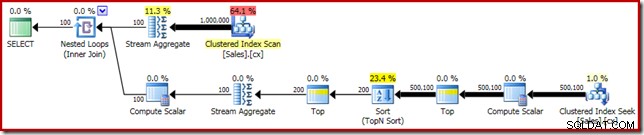
Nakonec nasadíme zvláštně vypadající výraz CASE, abychom odstranili posunutý výraz Compute Scalar. To dále zvyšuje výkon na 450 ms (20% zlepšení oproti originálu):
-- 450ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
-- NEW!
SELECT AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + Amount END)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Dokončený plán provádění je následující: