Jedním z nejčastějších pojmů, které se v diskusích o ladění výkonu SQL Server objevují, jsou statistiky čekání . To sahá daleko do minulosti, ještě před tímto dokumentem společnosti Microsoft z roku 2006, „SQL Server 2005 čeká a fronty.“
Čekání není absolutně všechno a tato metodika není jediným způsobem, jak vyladit instanci, bez ohledu na individuální dotaz. Ve skutečnosti je čekání často zbytečné, když vše, co máte, je dotaz, který je utrpěl, a žádný okolní kontext, zvláště dlouho po tom. Dost často totiž to, na co dotaz čeká, není chyba tohoto dotazu . Jako cokoli jiného existují výjimky, ale pokud si vybíráte nástroj nebo skript pouze proto, že nabízí tuto velmi specifickou funkci, myslím, že si tím děláte medvědí službu. Mám sklon řídit se radou, kterou mi před časem dal Paul Randal:
…obecně doporučuji začít s čekáním na celou instanci. Nikdy bych nezačal řešení problémů pohledem na jednotlivé čekání na dotaz.
Občas ano, možná budete chtít proniknout hlouběji do jednotlivého dotazu a zjistit, na co čeká; Microsoft ve skutečnosti nedávno přidal statistiky čekání na úrovni dotazu do showplanu, aby pomohl s touto analýzou. Ale tato čísla vám obvykle nepomohou vyladit výkon vaší instance jako celku, pokud nepomohou poukázat na něco, co náhodou také ovlivňuje celou vaši pracovní zátěž. Pokud vidíte jeden dotaz ze včerejška, který běžel 5 minut, a všimnete si, že jeho typ čekání byl LCK_M_S , co s tím teď budeš dělat? Jak chcete zjistit, co ve skutečnosti blokovalo dotaz a způsobovalo tento typ čekání? Mohlo to být způsobeno transakcí, která se neprováděla z nějakého jiného důvodu, ale to nevidíte, pokud nevidíte stav celého systému a soustředíte se pouze na jednotlivé dotazy a čekání, které zažili.
Jason Hall (@SQLSaurus) mimochodem zmínil něco, co bylo zajímavé i pro mě. Řekl, že pokud by statistiky čekání na úrovni dotazu byly tak důležitou součástí úsilí o ladění, že by tato metodika byla zapečena do Query Store od začátku. Byl přidán nedávno (v SQL Server 2017). Stále však nezískáváte statistiky čekání na provedení; získáte průměry v průběhu času, jako jsou statistiky dotazů a statistiky procedur, které vidíte v DMV. Náhlé anomálie tedy mohou být zjevné na základě jiných metrik, které jsou zachyceny při provádění dotazu, ale ne na základě průměrů čekacích dob, které jsou vykresleny přes všechny exekuce. Můžete si upravit rozsah agregovaných čekání, ale na vytížených systémech to stále nemusí být dostatečně podrobné, aby udělalo to, co si myslíte, že to udělá za vás.
Cílem tohoto příspěvku je diskutovat o některých běžnějších typech čekání, které vidíme v naší zákaznické základně, a o tom, jaké akce můžete (a neměli byste) podniknout, když k nim dojde. Máme databázi anonymních statistik čekání, které shromažďujeme od našich zákazníků Cloud Sync již nějakou dobu, a od května 2017 všem ukazujeme, jak to vypadá v knihovně SQLskills Waits Library.
Paul mluví o důvodu knihovny a také o naší integraci s touto bezplatnou službou. V podstatě si vyhledáte typ čekání, který zažíváte nebo jste na něj zvědaví, a on vám vysvětlí, co to znamená a co s tím můžete dělat. Tyto kvalitativní informace doplňujeme grafem, který ukazuje, jak převládá aktuální čekání mezi naší uživatelskou základnou, ve srovnání se všemi ostatními typy čekání, které vidíme, takže můžete rychle zjistit, zda máte co do činění s běžným typem čekání nebo něčím trochu víc. exotický. (Mějte na paměti, že SQL Sentry nezahrnuje benigní, pozadí a čekání ve frontě, které představují šum a které většina skriptů odfiltruje, jako je WAITFOR nebo LAZYWRITER_SLEEP – to prostě nejsou zdroje problémů s výkonem.)
Zde je příklad grafu pro CXPACKET , nejběžnější typ čekání:
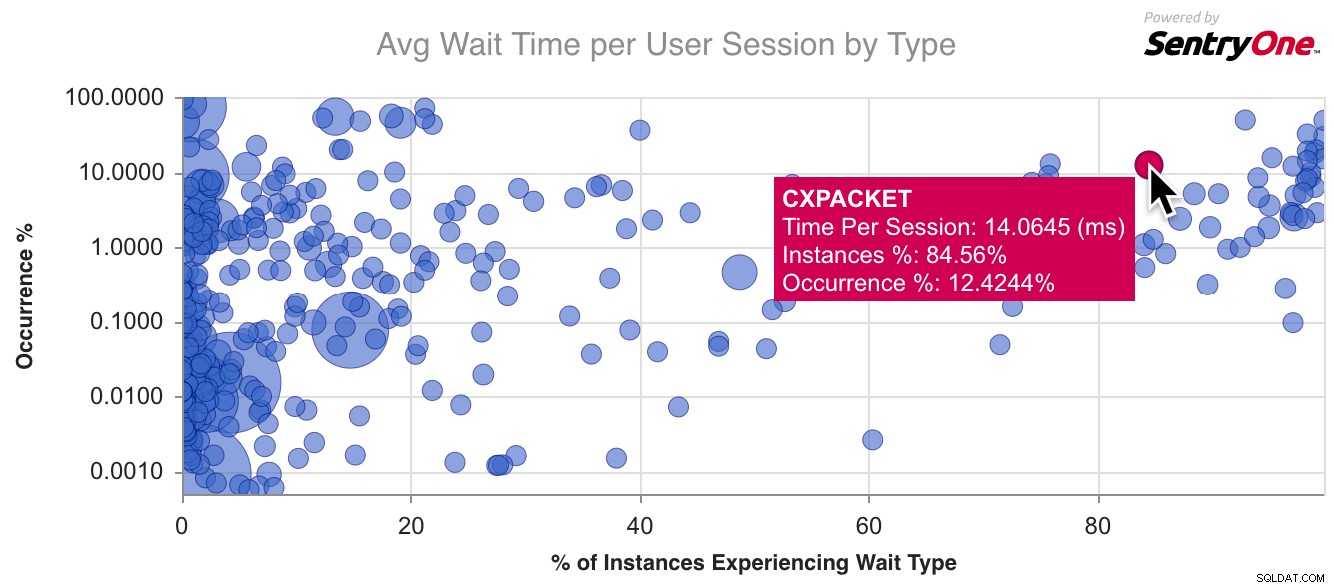
Začal jsem jít trochu dále, mapovat některé z běžnějších typů čekání a všímat si některých vlastností, které sdíleli. Přeloženo do otázek, které by tuner mohl mít ohledně typu čekání, se kterým se setkává:
- Lze typ čekání vyřešit na úrovni dotazu?
- Je pravděpodobné, že hlavní příznak čekání ovlivní další dotazy?
- Je pravděpodobné, že budete k „řešení“ problému potřebovat více informací mimo kontext jednoho dotazu a typů čekání?
Když jsem se rozhodl napsat tento příspěvek, mým cílem bylo pouze seskupit nejběžnější typy čekání a pak si o nich začít zapisovat poznámky týkající se výše uvedených otázek. Jason vytáhl z knihovny ty nejběžnější a pak jsem na tabuli nakreslil nějaký slepičí škrábanec, který jsem později trochu uklidil. Tento počáteční výzkum vedl k přednášce, kterou Jason přednesl o nejnovější TechOutbound SQL Cruise na Aljašce. Je mi trochu trapně, že dal dohromady řeč měsíce předtím, než jsem mohl dokončit tento příspěvek, takže pojďme na to. Zde jsou nejčastější čekání, která vidíme (která do značné míry odpovídají Paulovu průzkumu z roku 2014), mé odpovědi na výše uvedené otázky a několik komentářů ke každé z nich:
Chcete-li pracovat s odkazy v tabulce níže, navštivte tuto stránku na širší obrazovce.
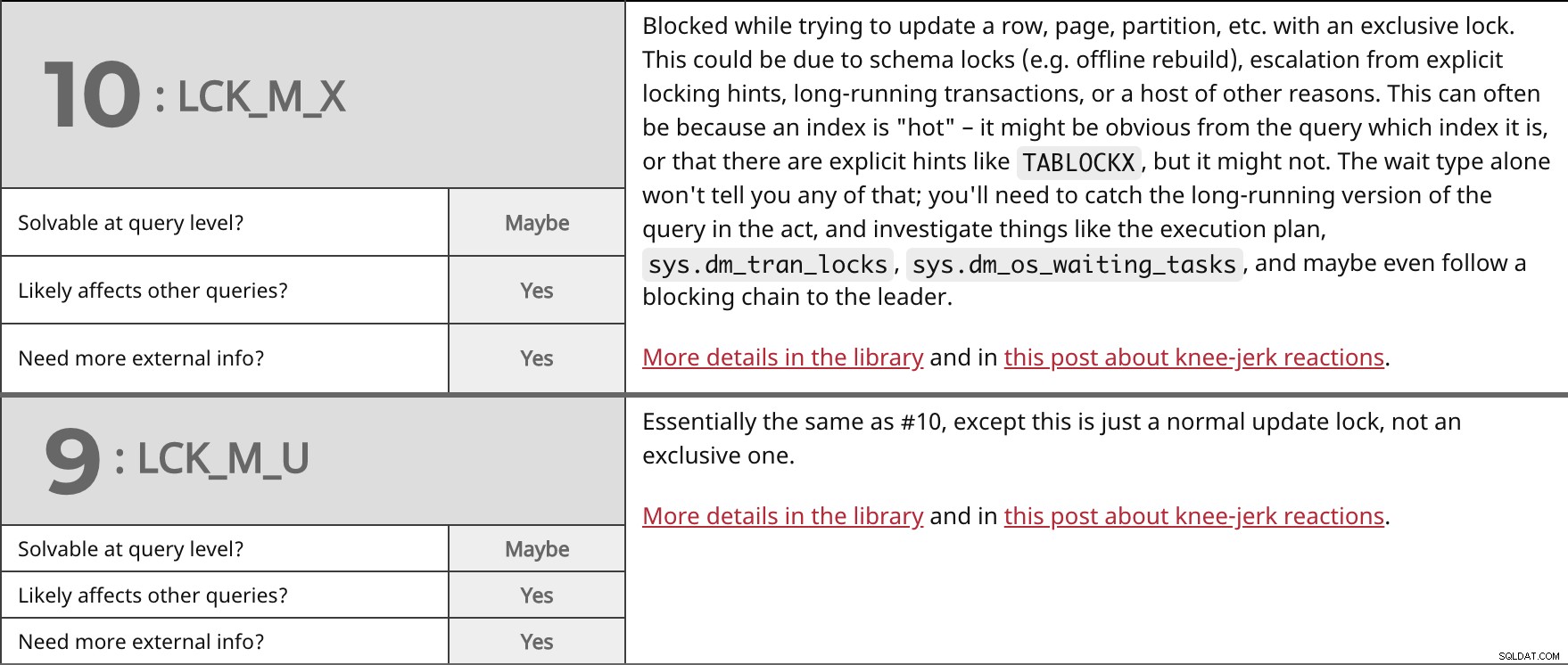
Blokováno při pokusu o aktualizaci řádku, stránky, oddílu atd. pomocí exkluzivního zámku. To může být způsobeno uzamčením schématu (např. offline přestavba), eskalací z explicitních zamykacích tipů, dlouhotrvajícími transakcemi nebo řadou dalších důvodů. Často to může být způsobeno tím, že index je "horký" – z dotazu může být zřejmé, o jaký index se jedná, nebo že existují explicitní nápovědy jako TABLOCKX , ale nemusí. Samotný typ čekání vám nic z toho neřekne; budete muset zachytit dlouhotrvající verzi dotazu v akci a prozkoumat věci, jako je plán provádění, sys.dm_tran_locks , sys.dm_os_waiting_tasks a možná dokonce následovat blokovací řetězec k vedoucímu. Více podrobností v knihovně a v tomto příspěvku o reakcích na kolena. | ||
| Řešitelné na úrovni dotazu? | Možná | |
| Ano | ||
| Potřebujete více externích informací? | Ano | |
|
V podstatě stejné jako #10, až na to, že se jedná pouze o běžný aktualizační zámek, nikoli o exkluzivní. Více podrobností v knihovně a v tomto příspěvku o reakcích na kolena. | ||
| Řešitelné na úrovni dotazu? | Možná | |
| Ano | ||
| Potřebujete více externích informací? | Ano | |
|
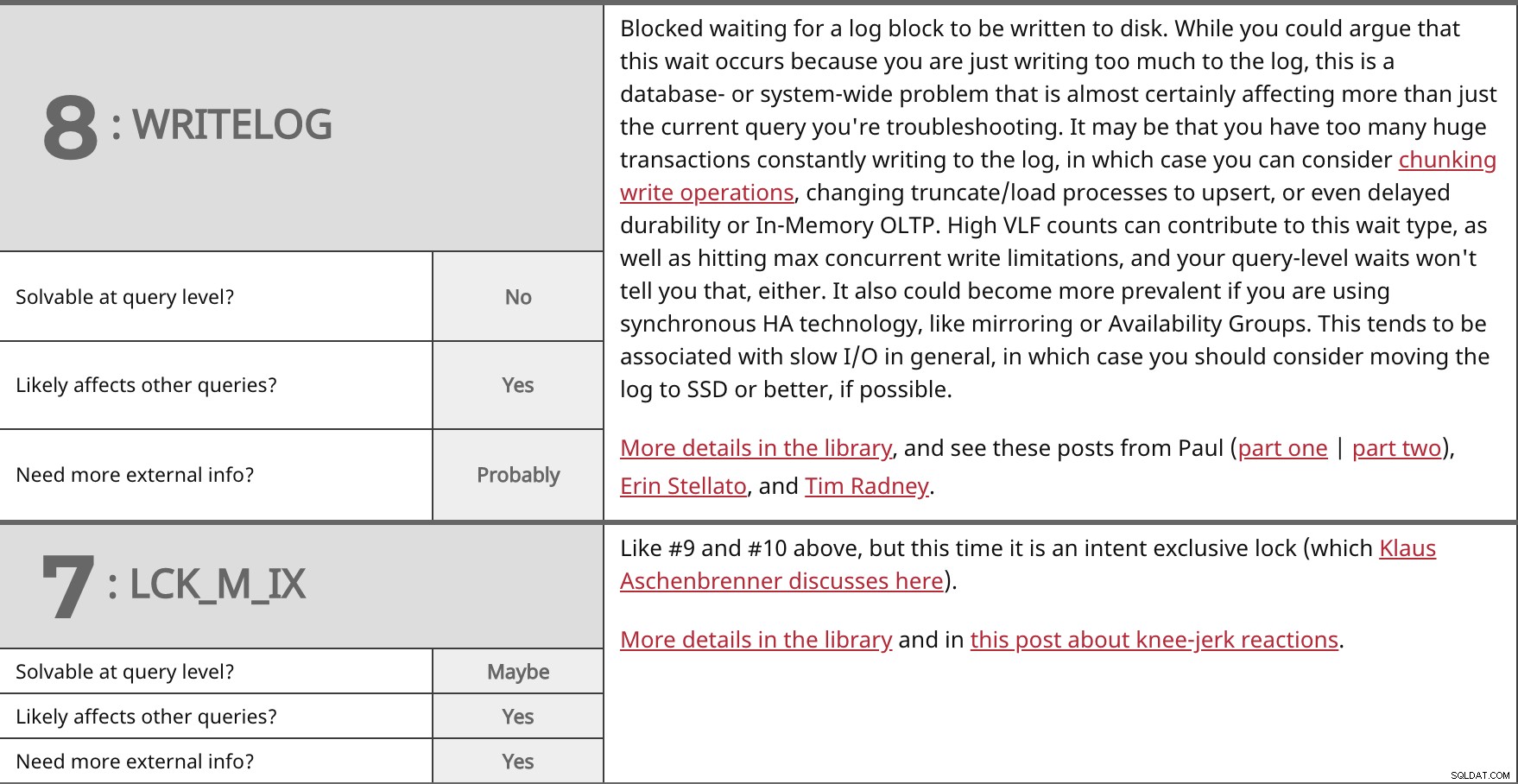
Blokováno čekání na zapsání bloku protokolu na disk. I když byste mohli namítnout, že k tomuto čekání dochází proto, že zapisujete příliš mnoho do protokolu, jedná se o problém databáze nebo systému, který téměř jistě ovlivňuje více než jen aktuální dotaz, který řešíte. Může se stát, že do protokolu neustále zapisujete příliš mnoho velkých transakcí, v takovém případě můžete zvážit rozdělení operací zápisu, změnu procesů oříznutí/načtení na upsert nebo dokonce zpožděnou trvanlivost nebo OLTP v paměti. Vysoké počty VLF mohou přispět k tomuto typu čekání a také k dosažení maximálních omezení souběžného zápisu a vaše čekání na úrovni dotazu vám to také neřekne. Také by se to mohlo stát rozšířenější, pokud používáte synchronní technologii HA, jako je zrcadlení nebo skupiny dostupnosti. To bývá spojováno s pomalými I/O obecně, v takovém případě byste měli zvážit přesunutí protokolu na SSD nebo lepší, pokud je to možné. Více podrobností v knihovně a podívejte se na tyto příspěvky od Paula (první část | část druhá), Erin Stellato a Tima Radneyho. | ||
| Řešitelné na úrovni dotazu? | Ne | |
| Ano | ||
| Potřebujete více externích informací? | Pravděpodobně | |
|
Jako č. 9 a č. 10 výše, ale tentokrát se jedná o výhradní zámek (o kterém zde pojednává Klaus Aschenbrenner). Více podrobností v knihovně a v tomto příspěvku o reakcích na kolena. | ||
| Řešitelné na úrovni dotazu? | Možná | |
| Ano | ||
| Potřebujete více externích informací? | Ano | |
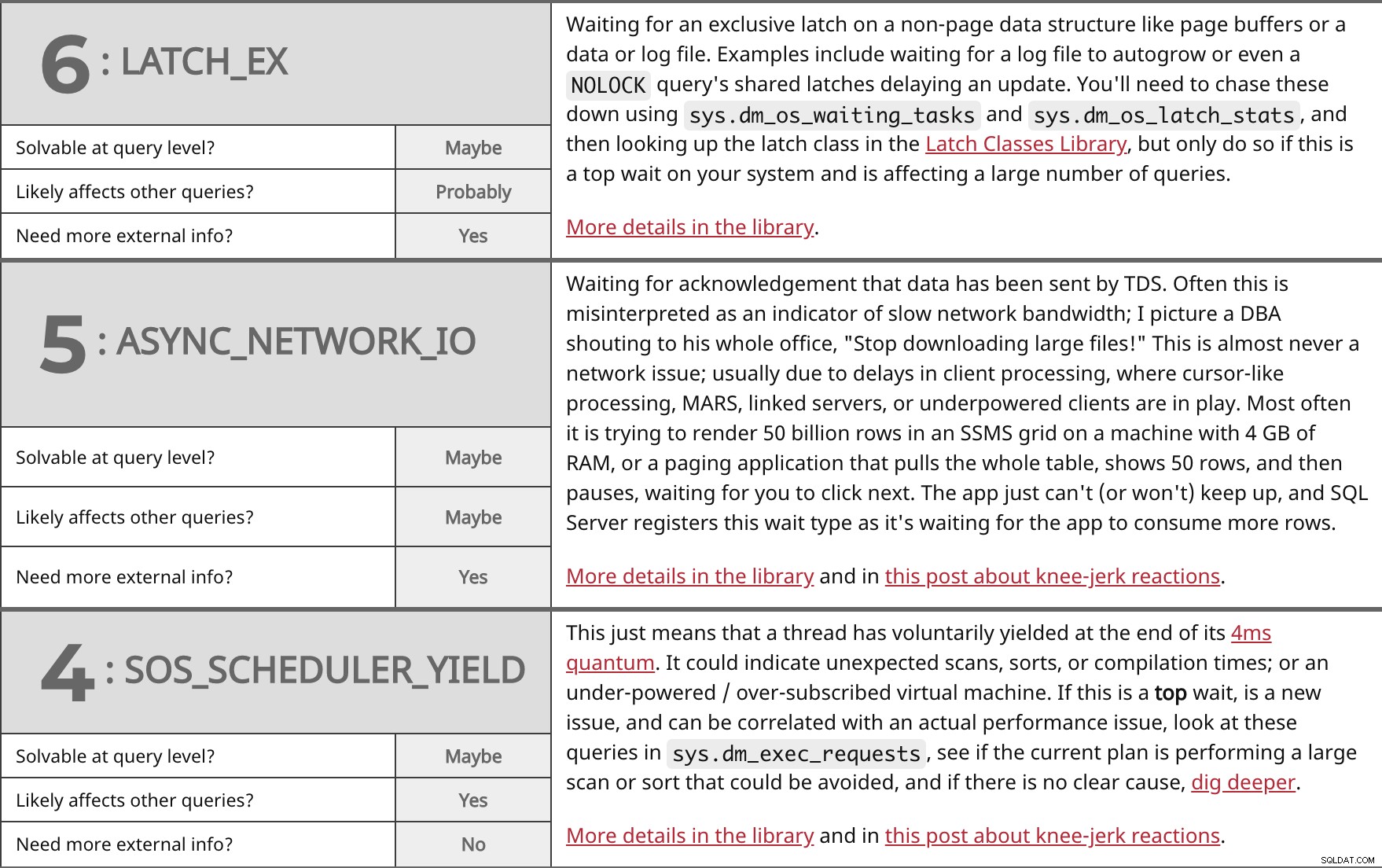
Čekání na exkluzivní blokování nestránkové datové struktury, jako jsou vyrovnávací paměti stránek nebo datový nebo protokolový soubor. Mezi příklady patří čekání na automatický růst souboru protokolu nebo dokonce NOLOCK sdílené zámky dotazu zdržující aktualizaci. Budete je muset dohnat pomocí sys.dm_os_waiting_tasks a sys.dm_os_latch_stats a poté vyhledejte třídu latch v knihovně tříd Latch, ale udělejte to pouze v případě, že se jedná o nejvyšší čekání ve vašem systému a ovlivňuje velký počet dotazů. Více podrobností v knihovně. | ||
| Řešitelné na úrovni dotazu? | Možná | |
| Pravděpodobně | ||
| Potřebujete více externích informací? | Ano | |
|
Čekání na potvrzení, že data byla odeslána TDS. Často je to chybně interpretováno jako indikátor pomalé šířky pásma sítě; Představuji si DBA, jak křičí na celou svou kancelář:"Přestaňte stahovat velké soubory!" Téměř nikdy se nejedná o síťový problém; obvykle kvůli zpožděním ve zpracování klienta, kde je ve hře zpracování podobné kurzoru, MARS, propojené servery nebo klienti s nedostatečným výkonem. Nejčastěji se snaží vykreslit 50 miliard řádků v SSMS mřížce na stroji se 4 GB RAM nebo stránkovací aplikací, která stáhne celou tabulku, ukáže 50 řádků a pak se pozastaví a čeká, až klikneš dál. Aplikace prostě nemůže (nebo nebude) držet krok a SQL Server zaregistruje tento typ čekání, protože čeká, až aplikace spotřebuje více řádků. Více podrobností v knihovně a v tomto příspěvku o reakcích na kolena. | ||
| Řešitelné na úrovni dotazu? | Možná | |
| Možná | ||
| Potřebujete více externích informací? | Ano | |
To jen znamená, že vlákno dobrovolně ustoupilo na konci svého 4ms kvanta. Mohlo by to znamenat neočekávané skenování, řazení nebo časy kompilace; nebo virtuální stroj s nedostatečným napájením / s příliš vysokým odběrem. Pokud je toto top počkat, je nový problém a lze jej korelovat se skutečným problémem s výkonem, podívejte se na tyto dotazy v sys.dm_exec_requests , zjistěte, zda aktuální plán provádí velké skenování nebo řazení, kterému by se dalo předejít, a pokud neexistuje jasná příčina, zapátrejte hlouběji. Více podrobností v knihovně a v tomto příspěvku o reakcích na kolena. | ||
| Řešitelné na úrovni dotazu? | Možná | |
| Ano | ||
| Potřebujete více externích informací? | Ne | |
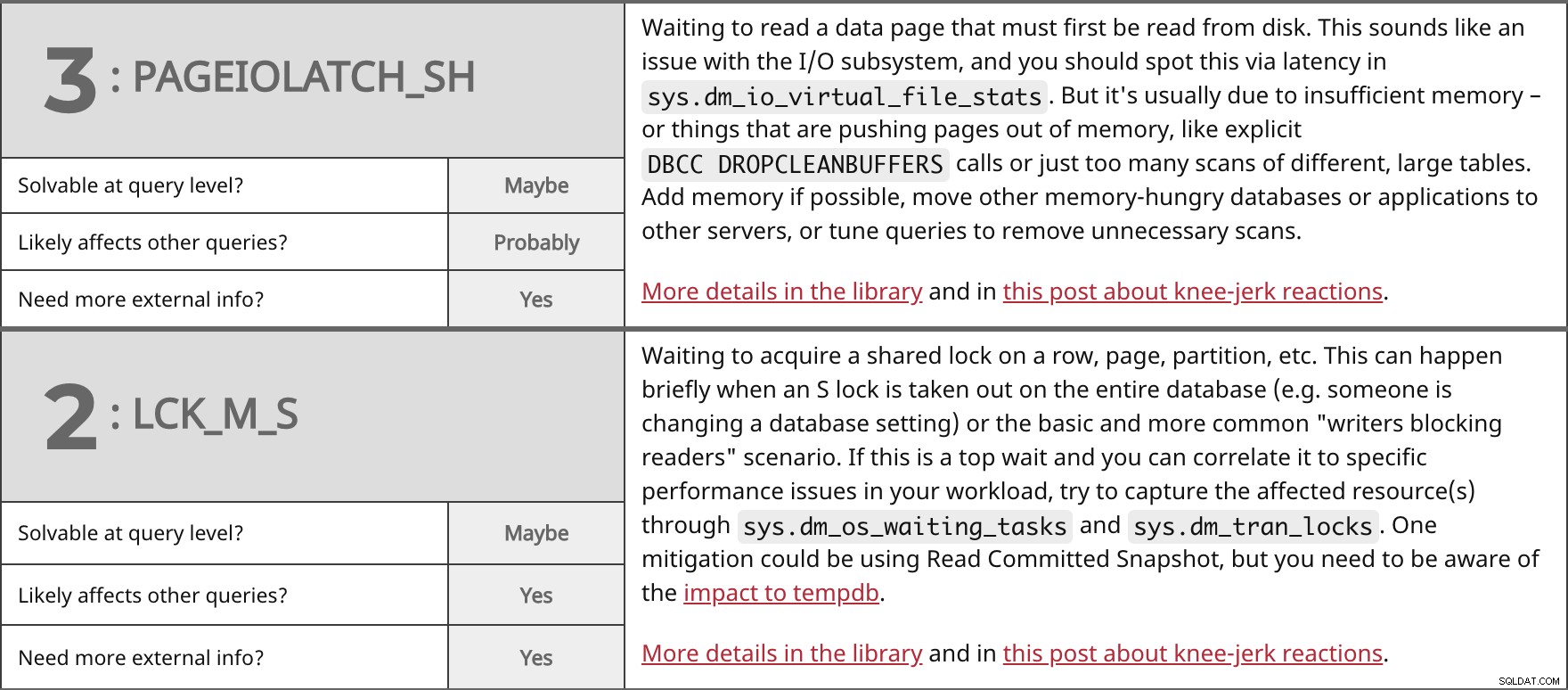
Čekání na načtení datové stránky, která musí být nejprve načtena z disku. To zní jako problém s I/O subsystémem a měli byste to zjistit pomocí latence v sys.dm_io_virtual_file_stats . Ale obvykle je to kvůli nedostatečné paměti – nebo věcem, které vytlačují stránky z paměti, jako je explicitní DBCC DROPCLEANBUFFERS volání nebo prostě příliš mnoho skenů různých velkých tabulek. Pokud je to možné, přidejte paměť, přesuňte jiné databáze nebo aplikace náročné na paměť na jiné servery nebo vylaďte dotazy, abyste odstranili nepotřebná skenování. Více podrobností v knihovně a v tomto příspěvku o reakcích na kolena. | ||
| Řešitelné na úrovni dotazu? | Možná | |
| Pravděpodobně | ||
| Potřebujete více externích informací? | Ano | |
Čekání na získání sdíleného zámku na řádku, stránce, oddílu atd. K tomu může dojít krátce, když je z celé databáze odstraněn zámek S (např. někdo mění nastavení databáze) nebo základní a běžnější scénář „autoři blokující čtenáře“. Pokud se jedná o nejvyšší čekání a můžete to korelovat s konkrétními problémy s výkonem ve vaší pracovní zátěži, zkuste zachytit ovlivněné zdroje prostřednictvím sys.dm_os_waiting_tasks a sys.dm_tran_locks . Jedním zmírněním může být použití Read Committed Snapshot, ale musíte si být vědomi dopadu na tempdb. Více podrobností v knihovně a v tomto příspěvku o reakcích na kolena. | ||
| Řešitelné na úrovni dotazu? | Možná | |
| Ano | ||
| Potřebujete více externích informací? | Ano | |
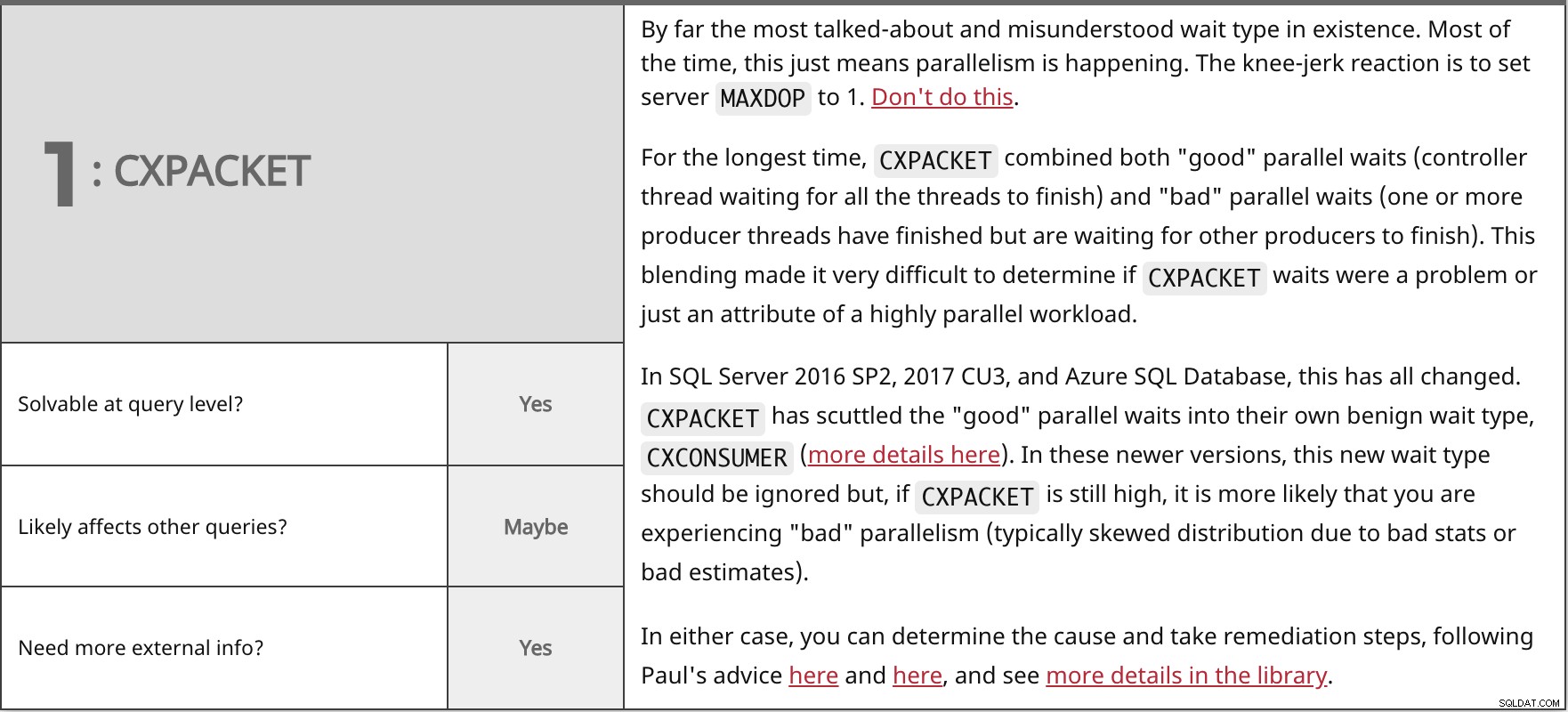
Zdaleka nejvíce diskutovaný a nepochopený typ čekání, jaký existuje. Většinou to znamená, že dochází k paralelismu. Prudká reakce je nastavit server MAXDOP na 1. Nedělejte to.
Nejdelší dobu
V SQL Server 2016 SP2, 2017 CU3 a Azure SQL Database se to všechno změnilo. V obou případech můžete určit příčinu a podniknout kroky k nápravě podle Pavlových rad zde a zde a další podrobnosti naleznete v knihovně. | ||
| Řešitelné na úrovni dotazu? | Ano | |
| Možná | ||
| Potřebujete více externích informací? | Ano | |
Shrnutí
Ve většině těchto případů je lepší podívat se na čekání na úrovni instance a zdokonalit čekání na úrovni dotazu pouze tehdy, když řešíte konkrétní dotazy, které vykazují problémy s výkonem bez ohledu na typ čekání. To jsou věci, které vyplouvají na povrch z jiných důvodů, jako je dlouhé trvání, vysoký CPU nebo vysoký I/O, a nedají se vysvětlit jednoduššími věcmi (jako je skenování clusteru indexu, když jste očekávali hledání).
Ani na úrovni instance nepronásledujte každé čekání, které se stane nejvyšším čekáním ve vašem systému – budete VŽDY počkejte si a už nikdy nebudete moci přestat honit. Ujistěte se, že ignorujete benigní čekání (Paul vede seznam) a starejte se pouze o čekání, které si můžete přiřadit ke skutečnému problému s výkonem, který máte. Pokud CXPACKET čekání je vysoké, tak co? Existují nějaké další příznaky kromě toho, že toto číslo je „vysoké“ nebo že je na vrcholu seznamu?
Všechno jde o to, proč řešíte problémy na prvním místě. Stěžuje si jeden uživatel na jednu instanci nepoctivého dotazu? Je váš server na kolenou? Něco mezi? V prvním případě jistě může být užitečné vědět, proč je dotaz pomalý, ale je docela drahé sledovat (nevadí, ponechat to donekonečna) všechna čekání spojená s každým jedním dotazem, celý den, každý den, při zvláštní příležitosti chcete se vrátit a zkontrolovat je později. Pokud se jedná o všudypřítomný problém izolovaný od tohoto dotazu, měli byste být schopni určit, co tento dotaz zpomaluje, tím, že jej znovu spustíte a shromáždíte plán provádění, dobu kompilace a další metriky běhu. Pokud to byla jednorázová věc, která se stala minulé úterý, ať už čekáte na tuto jedinou instanci dotazu nebo ne, možná nebudete schopni problém vyřešit bez dalšího kontextu. Možná došlo k blokování, ale nebudete vědět čím, nebo možná došlo ke špičce I/O, ale tento problém budete muset vysledovat samostatně. Typ čekání sám o sobě obvykle neposkytuje dostatek informací kromě, v nejlepším případě, ukazatele na něco jiného.
Samozřejmě si musím vydělat i tady. Náš vlajkový produkt, SQL Sentry, zaujímá holistický přístup k monitorování. Shromažďujeme statistiky čekání za celou instanci, kategorizujeme je pro vás a zobrazujeme je v grafu na našem řídicím panelu:
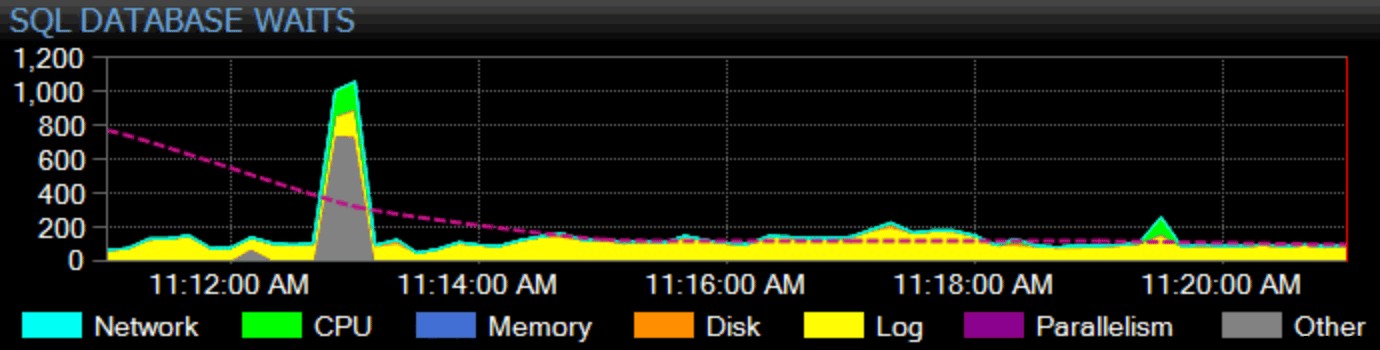
Můžete si přizpůsobit, jak je jednotlivá čekání kategorizována a zda se tato kategorie vůbec zobrazuje na řídicím panelu. Můžete porovnat aktuální statistiky čekání s vestavěnými nebo vlastními základními liniemi a dokonce nastavit výstrahy nebo akce, když překročí určitou definovanou odchylku od základní linie. A co je možná nejdůležitější, můžete se podívat na datový bod z minulosti a synchronizovat celý řídicí panel do tohoto bodu v čase, takže můžete zachytit veškerý okolní kontext a jakoukoli další situaci, která mohla problém ovlivnit. Když najdete podrobnější věci, na které se můžete zaměřit, jako je blokování, vysoká latence disku nebo dotazy s vysokým I/O nebo dlouhým trváním, můžete tyto metriky proniknout a dostat se ke kořenu problému poměrně rychle.
Pro více informací o obecných přístupech ke statistikám čekání a konkrétně o našem řešení se můžete podívat na bílou knihu Kevina Klinea Troubleshooting SQL Server Wait Stats a můžete si stáhnout dvoudílný webinář prezentovaný Paulem Randalem, Andy Yunem (@SQLBek), a Andy Mallon (@AMtwo):
- Část 1:Odstraňování problémů s výkonem pomocí statistiky čekání
- Část 2:Rychlá analýza statistik čekání pomocí SentryOne
A pokud chcete platformu SentryOne zatočit, můžete začít zde s časově omezenou nabídkou:
Stáhněte si 15denní bezplatnou zkušební verzi