Úlohy Gaps and Islands jsou klasické dotazovací výzvy, kde potřebujete identifikovat rozsahy chybějících hodnot a rozsahy existujících hodnot v sekvenci. Sekvence je často založena na nějakém datu nebo hodnotách data a času, které by se normálně měly objevovat v pravidelných intervalech, ale některé položky chybí. Úloha mezery hledá chybějící období a úloha ostrovy hledá existující období. V minulosti jsem se ve svých knihách a článcích zabýval mnoha řešeními problémů s mezerami a ostrovy. Nedávno mi můj přítel Adam Machanic předložil novou speciální výzvu pro ostrovy a její vyřešení vyžadovalo trochu kreativity. V tomto článku představuji výzvu a řešení, na které jsem přišel.
Výzva
Ve své databázi máte přehled o službách, které vaše společnost podporuje, v tabulce nazvané CompanyServices a každá služba obvykle přibližně jednou za minutu hlásí, že je online v tabulce nazvané EventLog. Následující kód vytvoří tyto tabulky a naplní je malými sadami ukázkových dat:
SET NOCOUNT ON; USE tempdb; IF OBJECT_ID(N'dbo.EventLog') IS NOT NULL DROP TABLE dbo.EventLog; IF OBJECT_ID(N'dbo.CompanyServices') IS NOT NULL DROP TABLE dbo.CompanyServices; CREATE TABLE dbo.CompanyServices ( serviceid INT NOT NULL, CONSTRAINT PK_CompanyServices PRIMARY KEY(serviceid) ); GO INSERT INTO dbo.CompanyServices(serviceid) VALUES(1), (2), (3); CREATE TABLE dbo.EventLog ( logid INT NOT NULL IDENTITY, serviceid INT NOT NULL, logtime DATETIME2(0) NOT NULL, CONSTRAINT PK_EventLog PRIMARY KEY(logid) ); GO INSERT INTO dbo.EventLog(serviceid, logtime) VALUES (1, '20180912 08:00:00'), (1, '20180912 08:01:01'), (1, '20180912 08:01:59'), (1, '20180912 08:03:00'), (1, '20180912 08:05:00'), (1, '20180912 08:06:02'), (2, '20180912 08:00:02'), (2, '20180912 08:01:03'), (2, '20180912 08:02:01'), (2, '20180912 08:03:00'), (2, '20180912 08:03:59'), (2, '20180912 08:05:01'), (2, '20180912 08:06:01'), (3, '20180912 08:00:01'), (3, '20180912 08:03:01'), (3, '20180912 08:04:02'), (3, '20180912 08:06:00'); SELECT * FROM dbo.EventLog;
Tabulka EventLog je aktuálně naplněna následujícími údaji:
logid serviceid logtime ----------- ----------- --------------------------- 1 1 2018-09-12 08:00:00 2 1 2018-09-12 08:01:01 3 1 2018-09-12 08:01:59 4 1 2018-09-12 08:03:00 5 1 2018-09-12 08:05:00 6 1 2018-09-12 08:06:02 7 2 2018-09-12 08:00:02 8 2 2018-09-12 08:01:03 9 2 2018-09-12 08:02:01 10 2 2018-09-12 08:03:00 11 2 2018-09-12 08:03:59 12 2 2018-09-12 08:05:01 13 2 2018-09-12 08:06:01 14 3 2018-09-12 08:00:01 15 3 2018-09-12 08:03:01 16 3 2018-09-12 08:04:02 17 3 2018-09-12 08:06:00
Úkolem speciálních ostrovů je identifikovat období dostupnosti (servis, čas zahájení, čas ukončení). Jeden háček je v tom, že neexistuje žádná záruka, že služba bude hlásit, že je online přesně každou minutu; měli byste tolerovat interval až řekněme 66 sekund od předchozího záznamu v protokolu a stále to považovat za součást stejného období dostupnosti (ostrov). Po 66 sekundách začíná nová položka protokolu nové období dostupnosti. Takže pro vstupní vzorová data výše by vaše řešení mělo vracet následující sadu výsledků (ne nutně v tomto pořadí):
serviceid starttime endtime ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 2 2018-09-12 08:00:02 2018-09-12 08:06:01 3 2018-09-12 08:00:01 2018-09-12 08:00:01 3 2018-09-12 08:03:01 2018-09-12 08:04:02 3 2018-09-12 08:06:00 2018-09-12 08:06:00
Všimněte si například, jak záznam protokolu 5 spustí nový ostrov, protože interval od předchozího záznamu protokolu je 120 sekund (> 66), zatímco záznam protokolu 6 nezahájí nový ostrov, protože interval od předchozího záznamu je 62 sekund ( <=66. jako MAS a LEAD. Jako obvykle doporučuji zkusit problém vyřešit sami, než se podíváte na moje řešení. Použijte malé sady vzorových dat ke kontrole platnosti vašich řešení. Následující kód použijte k naplnění tabulek velkými sadami ukázkových dat (500 služeb, ~10 milionů záznamů protokolu pro testování výkonu vašich řešení):
-- Helper function dbo.GetNums
IF OBJECT_ID(N'dbo.GetNums') IS NOT NULL DROP FUNCTION dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
-- ~10,000,000 intervals
DECLARE
@numservices AS INT = 500,
@logsperservice AS INT = 20000,
@enddate AS DATETIME2(0) = '20180912',
@validinterval AS INT = 60, -- seconds
@normdifferential AS INT = 3, -- seconds
@percentmissing AS FLOAT = 0.01;
TRUNCATE TABLE dbo.EventLog;
TRUNCATE TABLE dbo.CompanyServices;
INSERT INTO dbo.CompanyServices(serviceid)
SELECT A.n AS serviceid
FROM dbo.GetNums(1, @numservices) AS A;
WITH C AS
(
SELECT S.n AS serviceid,
DATEADD(second, -L.n * @validinterval + CHECKSUM(NEWID()) % (@normdifferential + 1), @enddate) AS logtime,
RAND(CHECKSUM(NEWID())) AS rnd
FROM dbo.GetNums(1, @numservices) AS S
CROSS JOIN dbo.GetNums(1, @logsperservice) AS L
)
INSERT INTO dbo.EventLog WITH (TABLOCK) (serviceid, logtime)
SELECT serviceid, logtime
FROM C
WHERE rnd > @percentmissing; Výstupy, které poskytnu pro kroky svých řešení, budou předpokládat malé sady vzorových dat a čísla výkonu, která poskytnu, budou předpokládat velké sady.
Všechna řešení, která představím, těží z následujícího indexu:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Hodně štěstí!
Řešení 1 pro SQL Server 2012+
Než se budu zabývat řešením, které je kompatibilní s prostředími staršími než SQL Server 2012, budu se zabývat řešením, které vyžaduje minimálně SQL Server 2012. Budu mu říkat Řešení 1.
Prvním krokem v řešení je vypočítat příznak nazvaný isstart, který je 0, pokud událost nezahájí nový ostrov, a 1 v opačném případě. Toho lze dosáhnout pomocí funkce LAG k získání času záznamu předchozí události a kontroly, zda časový rozdíl v sekundách mezi předchozí a aktuální událostí je menší nebo roven povolené mezeře. Zde je kód implementující tento krok:
DECLARE @allowedgap AS INT = 66; -- in seconds
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog; Tento kód generuje následující výstup:
logid serviceid logtime isstart ----------- ----------- --------------------------- ----------- 1 1 2018-09-12 08:00:00 1 2 1 2018-09-12 08:01:01 0 3 1 2018-09-12 08:01:59 0 4 1 2018-09-12 08:03:00 0 5 1 2018-09-12 08:05:00 1 6 1 2018-09-12 08:06:02 0 7 2 2018-09-12 08:00:02 1 8 2 2018-09-12 08:01:03 0 9 2 2018-09-12 08:02:01 0 10 2 2018-09-12 08:03:00 0 11 2 2018-09-12 08:03:59 0 12 2 2018-09-12 08:05:01 0 13 2 2018-09-12 08:06:01 0 14 3 2018-09-12 08:00:01 1 15 3 2018-09-12 08:03:01 1 16 3 2018-09-12 08:04:02 0 17 3 2018-09-12 08:06:00 1
Dále jednoduchý průběžný součet příznaku isstart vytvoří identifikátor ostrova (budu to nazývat grp). Zde je kód implementující tento krok:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
)
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1; Tento kód generuje následující výstup:
logid serviceid logtime isstart grp ----------- ----------- --------------------------- ----------- ----------- 1 1 2018-09-12 08:00:00 1 1 2 1 2018-09-12 08:01:01 0 1 3 1 2018-09-12 08:01:59 0 1 4 1 2018-09-12 08:03:00 0 1 5 1 2018-09-12 08:05:00 1 2 6 1 2018-09-12 08:06:02 0 2 7 2 2018-09-12 08:00:02 1 1 8 2 2018-09-12 08:01:03 0 1 9 2 2018-09-12 08:02:01 0 1 10 2 2018-09-12 08:03:00 0 1 11 2 2018-09-12 08:03:59 0 1 12 2 2018-09-12 08:05:01 0 1 13 2 2018-09-12 08:06:01 0 1 14 3 2018-09-12 08:00:01 1 1 15 3 2018-09-12 08:03:01 1 2 16 3 2018-09-12 08:04:02 0 2 17 3 2018-09-12 08:06:00 1 3
Nakonec seskupíte řádky podle ID služby a identifikátoru ostrova a vrátíte minimální a maximální časy protokolu jako počáteční a koncový čas každého ostrova. Zde je kompletní řešení:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1
)
SELECT serviceid, MIN(logtime) AS starttime, MAX(logtime) AS endtime
FROM C2
GROUP BY serviceid, grp; Toto řešení trvalo na mém systému 41 sekund a vytvořilo plán zobrazený na obrázku 1.
 Obrázek 1:Plán řešení 1
Obrázek 1:Plán řešení 1
Jak můžete vidět, obě funkce okna jsou počítány na základě pořadí indexů, bez nutnosti explicitního řazení.
Pokud používáte SQL Server 2016 nebo novější, můžete použít trik, který zde uvádím, k povolení dávkového režimu Window Aggregate operátor vytvořením prázdného filtrovaného indexu columnstore, například takto:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
Dokončení stejného řešení na mém systému nyní trvá pouze 5 sekund a vytvoří se plán zobrazený na obrázku 2.
 Obrázek 2:Plán řešení 1 pomocí dávkového režimu Window Aggregate operátor
Obrázek 2:Plán řešení 1 pomocí dávkového režimu Window Aggregate operátor
To vše je skvělé, ale jak již bylo zmíněno, Adam hledal řešení, které lze spustit v prostředích před rokem 2012.
Než budete pokračovat, ujistěte se, že jste zrušili index columnstore pro vyčištění:
DROP INDEX idx_cs ON dbo.EventLog;
Řešení 2 pro prostředí starší verze než SQL Server 2012
Bohužel před SQL Serverem 2012 jsme neměli podporu pro funkce offsetového okna, jako je LAG, ani jsme neměli podporu pro výpočet průběžných součtů s funkcemi agregace oken s rámcem. To znamená, že budete muset pracovat mnohem tvrději, abyste přišli s rozumným řešením.
Trik, který jsem použil, je převést každý záznam do umělého intervalu, jehož počáteční čas je záznamový čas záznamu a jehož koncový čas je záznamový čas záznamu plus povolená mezera. S úlohou pak můžete zacházet jako s klasickou úlohou intervalového balení.
První krok řešení vypočítá umělé intervalové oddělovače a čísla řádků označující pozice každého z druhů událostí (counteach). Zde je kód implementující tento krok:
DECLARE @allowedgap AS INT = 66; SELECT logid, serviceid, logtime AS s, -- important, 's' > 'e', for later ordering DATEADD(second, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach FROM dbo.EventLog;
Tento kód generuje následující výstup:
logid serviceid s e counteach ------ ---------- -------------------- -------------------- ---------- 1 1 2018-09-12 08:00:00 2018-09-12 08:01:06 1 2 1 2018-09-12 08:01:01 2018-09-12 08:02:07 2 3 1 2018-09-12 08:01:59 2018-09-12 08:03:05 3 4 1 2018-09-12 08:03:00 2018-09-12 08:04:06 4 5 1 2018-09-12 08:05:00 2018-09-12 08:06:06 5 6 1 2018-09-12 08:06:02 2018-09-12 08:07:08 6 7 2 2018-09-12 08:00:02 2018-09-12 08:01:08 1 8 2 2018-09-12 08:01:03 2018-09-12 08:02:09 2 9 2 2018-09-12 08:02:01 2018-09-12 08:03:07 3 10 2 2018-09-12 08:03:00 2018-09-12 08:04:06 4 11 2 2018-09-12 08:03:59 2018-09-12 08:05:05 5 12 2 2018-09-12 08:05:01 2018-09-12 08:06:07 6 13 2 2018-09-12 08:06:01 2018-09-12 08:07:07 7 14 3 2018-09-12 08:00:01 2018-09-12 08:01:07 1 15 3 2018-09-12 08:03:01 2018-09-12 08:04:07 2 16 3 2018-09-12 08:04:02 2018-09-12 08:05:08 3 17 3 2018-09-12 08:06:00 2018-09-12 08:07:06 4
Dalším krokem je sejmutí intervalů do chronologické sekvence počátečních a koncových událostí, označených jako typy událostí „s“ a „e“. Všimněte si, že výběr písmen s a e je důležitý ('s' > 'e' ). Tento krok vypočítává čísla řádků označující správné chronologické pořadí obou druhů událostí, které jsou nyní prokládány (countboth). V případě, že jeden interval končí přesně tam, kde začíná jiný, umístíte počáteční událost před událost end, sbalíte je dohromady. Zde je kód implementující tento krok:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
)
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U; Tento kód generuje následující výstup:
logid serviceid logtime eventtype counteach countboth ------ ---------- -------------------- ---------- ---------- ---------- 1 1 2018-09-12 08:00:00 s 1 1 2 1 2018-09-12 08:01:01 s 2 2 1 1 2018-09-12 08:01:06 e 1 3 3 1 2018-09-12 08:01:59 s 3 4 2 1 2018-09-12 08:02:07 e 2 5 4 1 2018-09-12 08:03:00 s 4 6 3 1 2018-09-12 08:03:05 e 3 7 4 1 2018-09-12 08:04:06 e 4 8 5 1 2018-09-12 08:05:00 s 5 9 6 1 2018-09-12 08:06:02 s 6 10 5 1 2018-09-12 08:06:06 e 5 11 6 1 2018-09-12 08:07:08 e 6 12 7 2 2018-09-12 08:00:02 s 1 1 8 2 2018-09-12 08:01:03 s 2 2 7 2 2018-09-12 08:01:08 e 1 3 9 2 2018-09-12 08:02:01 s 3 4 8 2 2018-09-12 08:02:09 e 2 5 10 2 2018-09-12 08:03:00 s 4 6 9 2 2018-09-12 08:03:07 e 3 7 11 2 2018-09-12 08:03:59 s 5 8 10 2 2018-09-12 08:04:06 e 4 9 12 2 2018-09-12 08:05:01 s 6 10 11 2 2018-09-12 08:05:05 e 5 11 13 2 2018-09-12 08:06:01 s 7 12 12 2 2018-09-12 08:06:07 e 6 13 13 2 2018-09-12 08:07:07 e 7 14 14 3 2018-09-12 08:00:01 s 1 1 14 3 2018-09-12 08:01:07 e 1 2 15 3 2018-09-12 08:03:01 s 2 3 16 3 2018-09-12 08:04:02 s 3 4 15 3 2018-09-12 08:04:07 e 2 5 16 3 2018-09-12 08:05:08 e 3 6 17 3 2018-09-12 08:06:00 s 4 7 17 3 2018-09-12 08:07:06 e 4 8
Jak již bylo zmíněno, counteach označuje pozici události pouze mezi událostmi stejného druhu a countboth označuje pozici události mezi kombinovanými, prokládanými událostmi obou druhů.
Kouzlo je pak řešeno dalším krokem – vypočítáním počtu aktivních intervalů po každé události na základě počtu a počtu obou. Počet aktivních intervalů je počet počátečních událostí, které se dosud staly, mínus počet konečných událostí, které se dosud staly. U počátečních událostí vám counteach říká, kolik počátečních událostí se dosud stalo, a kolik jich dosud skončilo, můžete zjistit odečtením counteach od countboth. Takže úplný výraz, který vám řekne, kolik intervalů je aktivních, je:
counteach - (countboth - counteach)
U koncových událostí vám counteach řekne, kolik koncových událostí se dosud stalo, a kolik jich dosud začalo, můžete zjistit odečtením counteach od countboth. Takže úplný výraz, který vám řekne, kolik intervalů je aktivních, je:
(countboth - counteach) - counteach
Pomocí následujícího výrazu CASE vypočítáte početní sloupec na základě typu události:
CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END Ve stejném kroku filtrujete pouze události představující začátek a konec sbalených intervalů. Začátky sbalených intervalů mají typ 's' a početní 1. Konce sbalených intervalů mají typ 'e' a početní 0.
Po filtrování vám zbydou páry událostí začátku a konce seskupených intervalů, ale každá dvojice je rozdělena do dvou řad – jedna pro událost zahájení a druhá pro událost end. Proto stejný krok vypočítá identifikátor páru pomocí čísel řádků se vzorcem (rownum – 1) / 2 + 1.
Zde je kód implementující tento krok:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
)
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0); Tento kód generuje následující výstup:
serviceid eventtype logtime grp ----------- ---------- -------------------- ---- 1 s 2018-09-12 08:00:00 1 1 e 2018-09-12 08:04:06 1 1 s 2018-09-12 08:05:00 2 1 e 2018-09-12 08:07:08 2 2 s 2018-09-12 08:00:02 1 2 e 2018-09-12 08:07:07 1 3 s 2018-09-12 08:00:01 1 3 e 2018-09-12 08:01:07 1 3 s 2018-09-12 08:03:01 2 3 e 2018-09-12 08:05:08 2 3 s 2018-09-12 08:06:00 3 3 e 2018-09-12 08:07:06 3
Poslední krok otočí dvojice událostí do řady na interval a odečte povolenou mezeru od času konce, aby se znovu vytvořil správný čas události. Zde je úplný kód řešení:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; Toto řešení trvalo v mém systému 43 sekund a vygenerovalo plán zobrazený na obrázku 3.
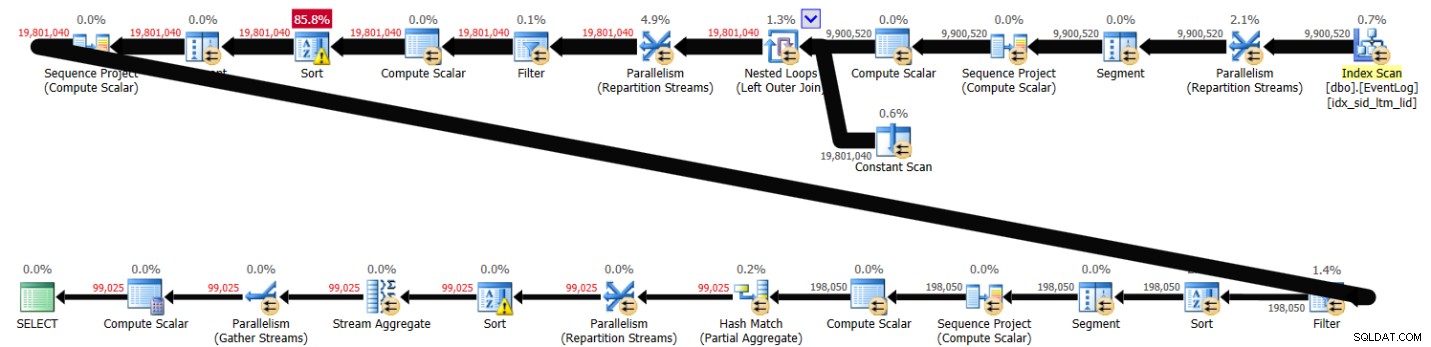 Obrázek 3:Plán řešení 2
Obrázek 3:Plán řešení 2
Jak vidíte, výpočet čísla prvního řádku se vypočítá na základě pořadí indexu, ale další dva zahrnují explicitní řazení. Přesto výkon není tak špatný, vezmeme-li v úvahu asi 10 000 000 řádků.
I když smyslem tohoto řešení je použít prostředí starší než SQL Server 2012, jen pro zábavu jsem po vytvoření filtrovaného indexu columnstore otestoval jeho výkon, abych zjistil, jak to funguje s povoleným dávkovým zpracováním:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
S povoleným dávkovým zpracováním trvalo toto řešení v mém systému 29 sekund, než se vytvořil plán znázorněný na obrázku 4.
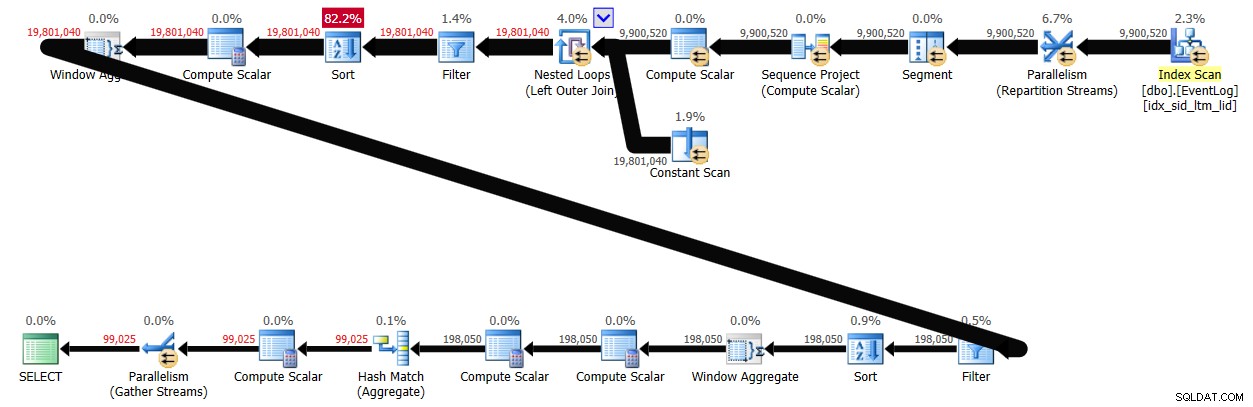
Závěr
Je přirozené, že čím omezenější je vaše prostředí, tím náročnější je řešení úloh dotazování. Speciální výzva Adam's Islands je mnohem snazší vyřešit na novějších verzích SQL Serveru než na starších. Pak se ale přinutíte používat kreativnější techniky. Takže jako cvičení, abyste zlepšili své dovednosti v dotazování, můžete se vypořádat s výzvami, které již znáte, ale záměrně zavést určitá omezení. Nikdy nevíte, na jaké druhy zajímavých nápadů můžete narazit!