
Pro úterý T-SQL tohoto měsíce nás Steve Jones (@way0utwest) požádal, abychom si promluvili o našich nejlepších nebo nejhorších zkušenostech se spouštěčem. I když je pravda, že spouštěče jsou často odsuzovány nebo dokonce obávány, mají několik platných případů použití, včetně:
- Audit (před aktualizací SP1 2016, kdy byla tato funkce zdarma ve všech edicích)
- Prosazování obchodních pravidel a integrity dat, když je nelze snadno implementovat v omezeních a nechcete, aby byly závislé na kódu aplikace nebo samotných dotazech DML
- Udržování historických verzí dat (před zachycením dat změn, sledováním změn a dočasnými tabulkami)
- Řazení výstrah do fronty nebo asynchronní zpracování v reakci na konkrétní změnu
- Povolení úprav zobrazení (prostřednictvím spouštěčů MÍSTO spouštěčů)
Toto není vyčerpávající seznam, jen rychlé shrnutí několika scénářů, které jsem zažil, kdy byly spouštěče v té době správnou odpovědí.
Když jsou spouštěče nezbytné, vždy rád prozkoumám použití spouštěčů MÍSTO spouštěčů spíše než PO spouštěčích. Ano, jsou o něco více předem připravené*, ale mají některé docela důležité výhody. Přinejmenším teoreticky se vyhlídka na zabránění nějaké akci (a jejím logickým důsledkům) zdá mnohem efektivnější než nechat to, aby se to všechno stalo, a pak to zrušit.
*Říkám to proto, že musíte znovu kódovat příkaz DML v rámci spouštěče; proto se jim neříká BEFORE triggers. Rozdíl je zde důležitý, protože některé systémy implementují skutečné spouštěče PŘED, které se jednoduše spustí jako první. V SQL Server aktivační událost NAMÍSTO OF účinně zruší příkaz, který způsobil její spuštění.
Předpokládejme, že máme jednoduchou tabulku pro uložení názvů účtů. V tomto příkladu vytvoříme dvě tabulky, takže můžeme porovnat dva různé spouštěče a jejich dopad na dobu trvání dotazu a využití protokolu. Koncept je, že máme obchodní pravidlo:název účtu není přítomen v jiné tabulce, která představuje „špatná“ jména, a k vynucení tohoto pravidla se používá spouštěč. Zde je databáze:
USE [master];
GO
CREATE DATABASE [tr] ON (name = N'tr_dat', filename = N'C:\temp\tr.mdf', size = 4096MB)
LOG ON (name = N'tr_log', filename = N'C:\temp\tr.ldf', size = 2048MB);
GO
ALTER DATABASE [tr] SET RECOVERY FULL;
GO A tabulky:
USE [tr]; GO CREATE TABLE dbo.Accounts_After ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.Accounts_Instead ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.InvalidNames ( name sysname PRIMARY KEY ); INSERT dbo.InvalidNames(name) VALUES (N'poop'),(N'hitler'),(N'boobies'),(N'cocaine');
A nakonec spouštěče. Pro jednoduchost se zabýváme pouze vložkami a jak v případě po, tak i v případě, že některé jméno porušuje naše pravidlo, celou dávku prostě přerušíme:
CREATE TRIGGER dbo.tr_Accounts_After
ON dbo.Accounts_After
AFTER INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
ROLLBACK TRANSACTION;
RETURN;
END
END
GO
CREATE TRIGGER dbo.tr_Accounts_Instead
ON dbo.Accounts_After
INSTEAD OF INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
RETURN;
END
ELSE
BEGIN
INSERT dbo.Accounts_Instead(AccountID, name, filler)
SELECT AccountID, name, filler FROM inserted;
END
END
GO Nyní, abychom otestovali výkon, zkusíme do každé tabulky vložit 100 000 jmen s předvídatelnou mírou selhání 10 %. Jinými slovy, 90 000 jsou v pořádku jména, zbylých 10 000 neprojde testem a způsobí, že se spouštěč buď vrátí zpět, nebo se nevloží v závislosti na dávce.
Nejprve musíme před každou dávkou provést nějaké vyčištění:
TRUNCATE TABLE dbo.Accounts_Instead; TRUNCATE TABLE dbo.Accounts_After; GO CHECKPOINT; CHECKPOINT; BACKUP LOG triggers TO DISK = N'C:\temp\tr.trn' WITH INIT, COMPRESSION; GO
Než začneme s masem každé dávky, spočítáme řádky v protokolu transakcí a změříme velikost a volné místo. Poté projdeme kurzorem, abychom zpracovali 100 000 řádků v náhodném pořadí, přičemž se pokusíme vložit každý název do příslušné tabulky. Až skončíme, znovu změříme počty řádků a velikost protokolu a zkontrolujeme dobu trvání.
SET NOCOUNT ON;
DECLARE @batch varchar(10) = 'After', -- or After
@d datetime2(7) = SYSUTCDATETIME(),
@n nvarchar(129),
@i int,
@err nvarchar(512);
-- measure before and again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CONVERT(int, FILEPROPERTY(name,N'SpaceUsed')))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR
SELECT name, i = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM
(
SELECT DISTINCT TOP (90000) LEFT(o.name,64) + '/' + LEFT(c.name,63)
FROM sys.all_objects AS o
CROSS JOIN sys.all_columns AS c
UNION ALL
SELECT TOP (10000) N'boobies' FROM sys.all_columns
) AS x (name)
ORDER BY i;
OPEN c;
FETCH NEXT FROM c INTO @n, @i;
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
IF @batch = 'After'
INSERT dbo.Accounts_After(AccountID,name) VALUES(@i,@n);
IF @batch = 'Instead'
INSERT dbo.Accounts_Instead(AccountID,name) VALUES(@i,@n);
END TRY
BEGIN CATCH
SET @err = ERROR_MESSAGE();
END CATCH
FETCH NEXT FROM c INTO @n, @i;
END
-- measure again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT duration = DATEDIFF(MILLISECOND, @d, SYSUTCDATETIME()),
CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CAST(FILEPROPERTY(name,N'SpaceUsed') AS int))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
CLOSE c; DEALLOCATE c; Výsledky (v průměru z 5 běhů každé dávky):
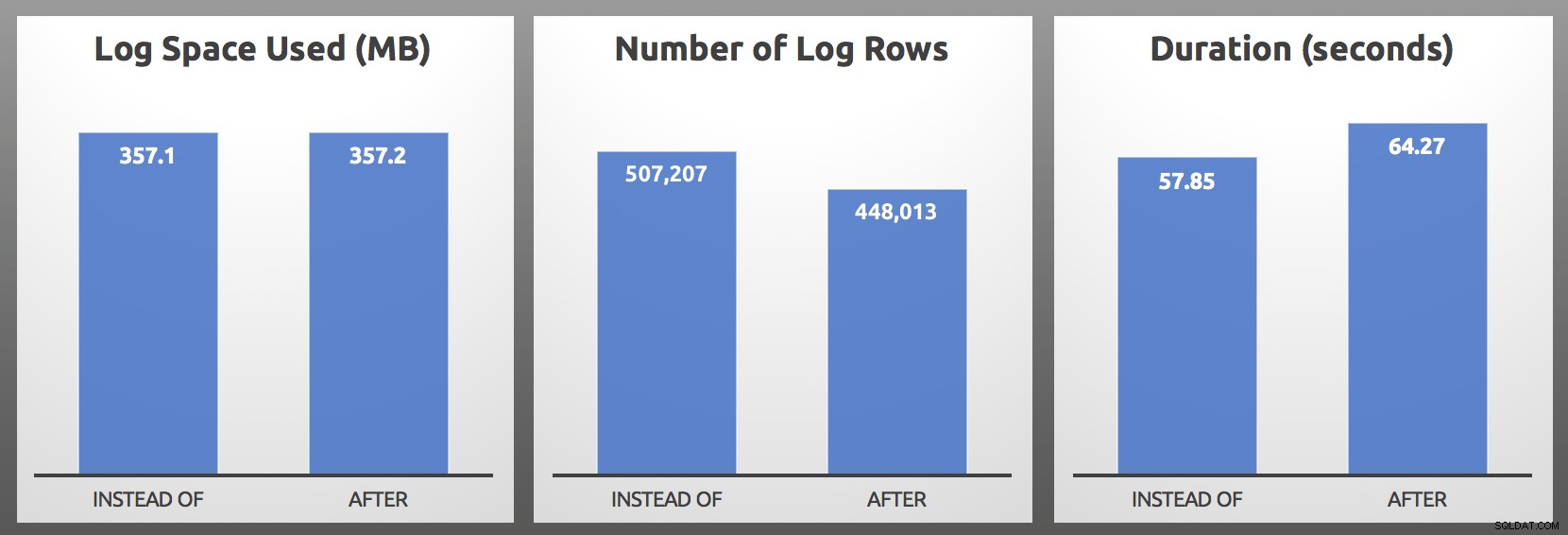 PO vs. MÍSTO :Výsledky
PO vs. MÍSTO :Výsledky
V mých testech bylo použití protokolu téměř stejné velikosti, s více než 10 % více řádků protokolu generovaných spouštěčem NAMÍSTO OF. Na konci každé dávky jsem provedl nějaké kopání:
SELECT [Operation], COUNT(*) FROM sys.fn_dblog(NULL, NULL) GROUP BY [Operation] ORDER BY [Operation];
A zde byl typický výsledek (zvýraznil jsem hlavní delty):
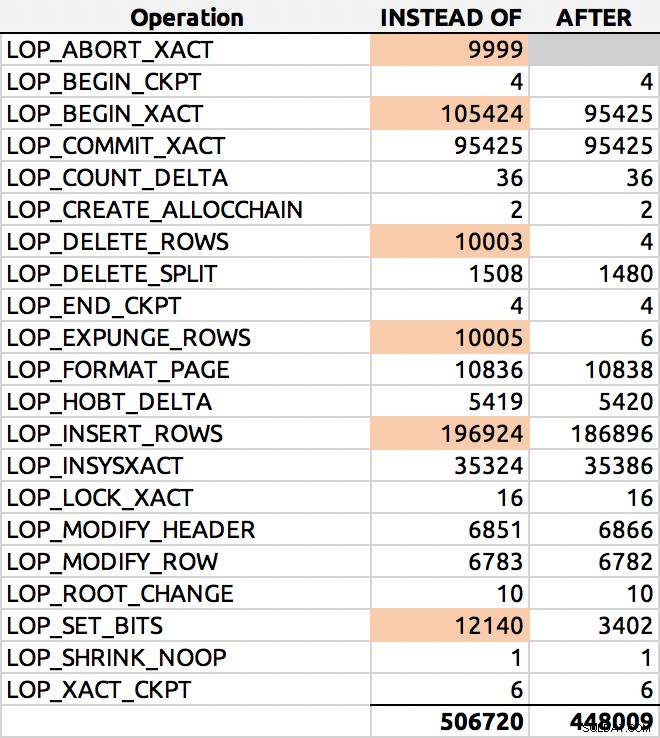 Distribuce řádků protokolu
Distribuce řádků protokolu
Zabrousím do toho hlouběji jindy.
Ale když se do toho pustíte…
…nejdůležitější metrikou bude téměř vždy trvání a v mém případě spoušť NAMÍSTO OF fungovala v každém přímém testu alespoň o 5 sekund rychleji. V případě, že vám to všechno zní povědomě, ano, už jsem o tom mluvil, ale tehdy jsem u řádků protokolu nepozoroval stejné příznaky.
Všimněte si, že to nemusí být vaše přesné schéma nebo pracovní vytížení, můžete mít velmi odlišný hardware, vaše souběžnost může být vyšší a míra selhání může být mnohem vyšší (nebo nižší). Moje testy byly provedeny na izolovaném stroji s dostatkem paměti a velmi rychlými PCIe SSD. Pokud je váš protokol na pomalejší jednotce, mohou rozdíly ve využití protokolu převážit nad ostatními metrikami a výrazně se změnit doby trvání. Všechny tyto faktory (a další!) mohou ovlivnit vaše výsledky, takže byste měli testovat ve svém prostředí.
Jde však o to, že MÍSTO spouště může být vhodnější. Teď, kdybychom mohli dostat MÍSTO DDL spouštěčů…