V části 1 této série jsme úspěšně importovali strukturu databáze SuiteCRM do našeho online nástroje pro modelování databází. Tehdy jsme viděli, že model obsahuje 201 tabulek bez vztahů mezi nimi. Máme divokou hromadu stolů, které vypadaly opravdu chaoticky. V tomto článku vám ukážu, jak můžete uspořádat tak velký model.
Ihned po importu do Vertabelo vypadá model databáze SuiteCRM následovně:
Model funguje – ale ne efektivně. Budeme ho muset upravit, aby byl opravdu užitečný. Protože chceme analyzovat databázi SuiteCRM po akce se provádějí na jeho GUI, musíme porozumět definicím tabulek a vztahům mezi tabulkami. Začněme seskupením tabulek do tematických oblastí a vytvořením nejdůležitějších vztahů.
Vertabelo nabízí tři hlavní nástroje, které vám pomohou organizovat velké diagramy:
- Téma
- Tabulky a zástupci zobrazení
- Referenční zkratky
Popíšu je později v tomto článku, ale více se můžete dozvědět také sledováním tohoto videa.
Krok 1. Zakažte automatické generování cizích klíčů
Nejprve zakážeme automatické generování cizích klíčů. Ve výchozím nastavení Vertabelo generuje atributy cizího klíče, když přebíráme vztahy z primární tabulky do odkazované tabulky. To je obvykle dobrá věc, ale ne tady. Již máme atributy, které představují cizí klíče. Co nám chybí, jsou „skutečné“ vztahy mezi tabulkami. Chcete-li tuto možnost vypnout, klikněte na „Můj účet“ v horní nabídce a najděte „Osobní preference“ sekce.
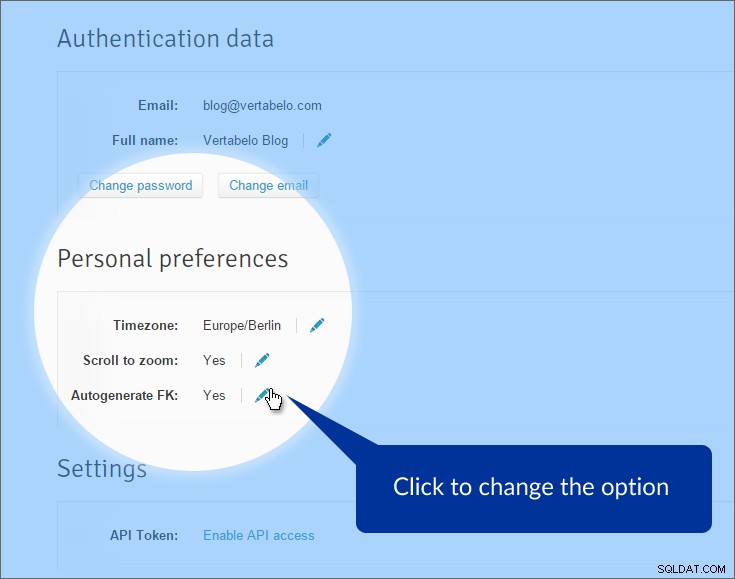
Možnost je vypnutá. Nyní, když nakreslíme referenční čáru mezi tabulkami, vytvoří se čára – ale budeme muset určit, které atributy se použijí, na primární i cizí straně.
Krok 2. Seskupte tabulky s předponou s předmětovými oblastmi
Dále seskupíme několik tabulek. Provedeme to pomocí oblasti Předmět nástroj, který umožňuje sdružovat tabulky na základě vybraných kritérií. V našem případě se snažíme identifikovat tabulky, které spolu souvisí nebo jsou součástí stejného procesu. Výsledkem budou skupiny jako „Hovory“, „Schůzka“ a „Kampaně“.
Kliknutím na „Přidat novou oblast“ můžeme vytvořit předmětovou oblast ikonu v panelu nástrojů:
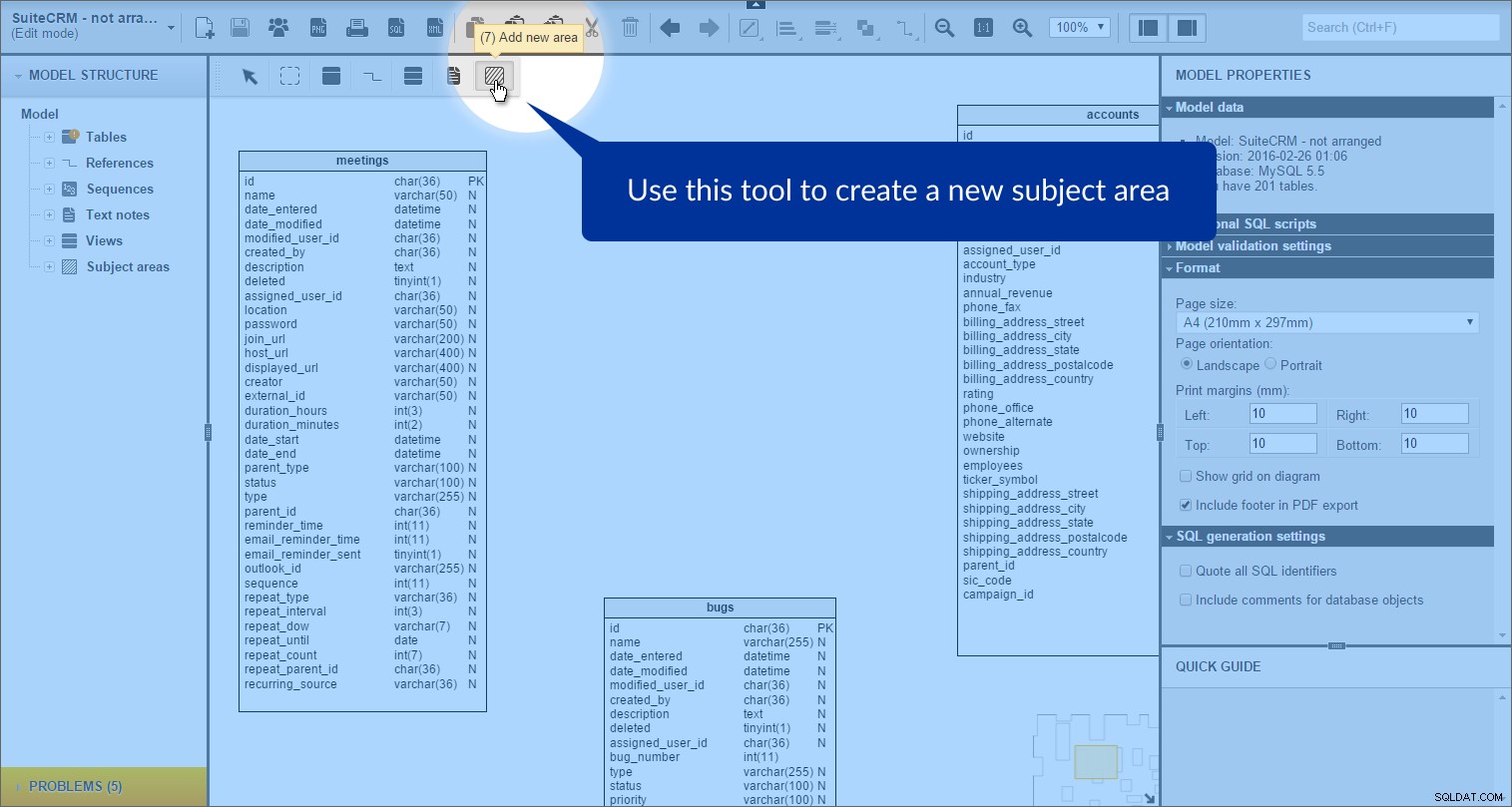
a poté nakreslení obdélníku na náš model:
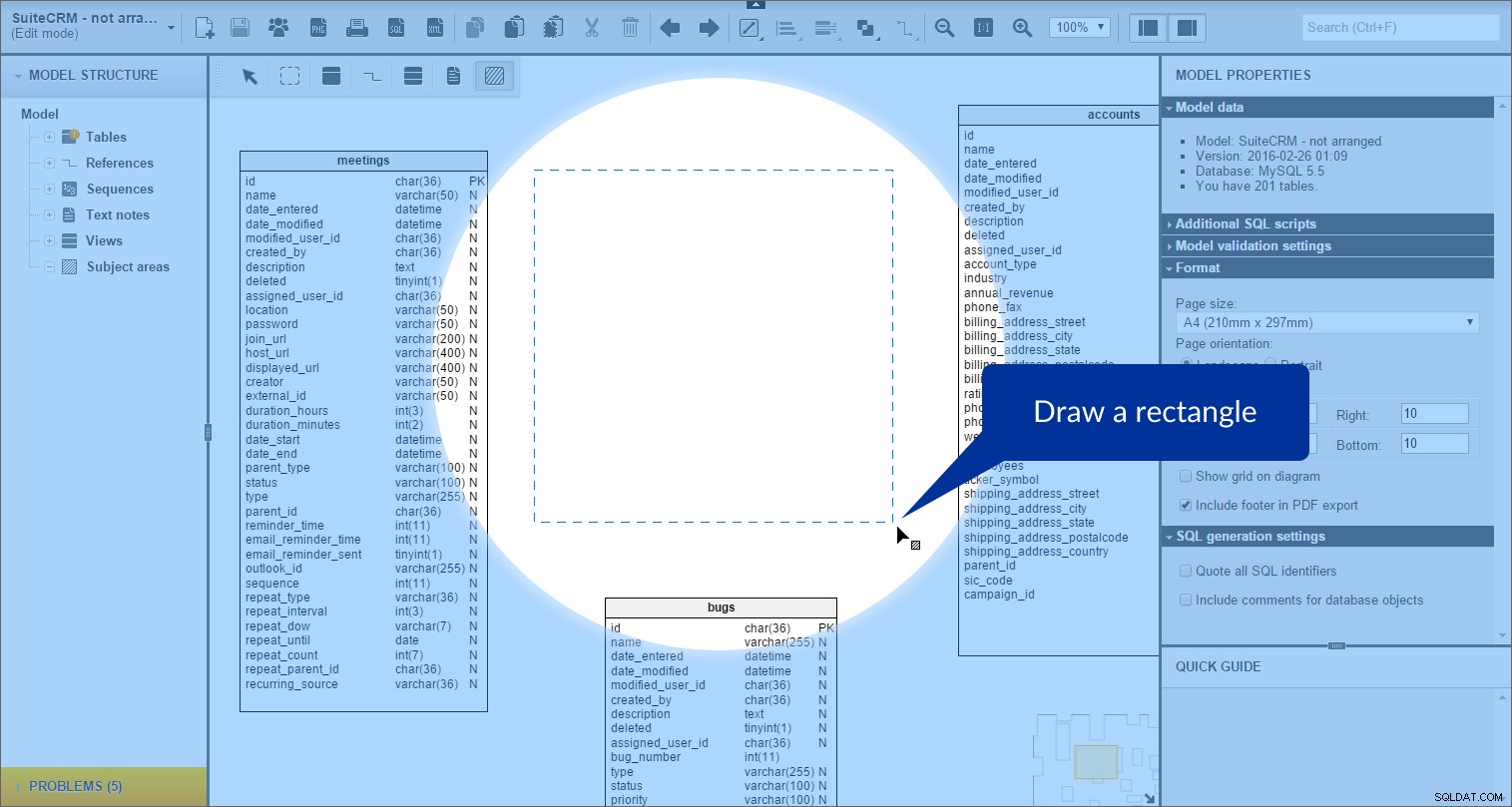
Oblast předmětu je vytvořena. Můžeme to vidět v „Struktura modelu“ panel vlevo:
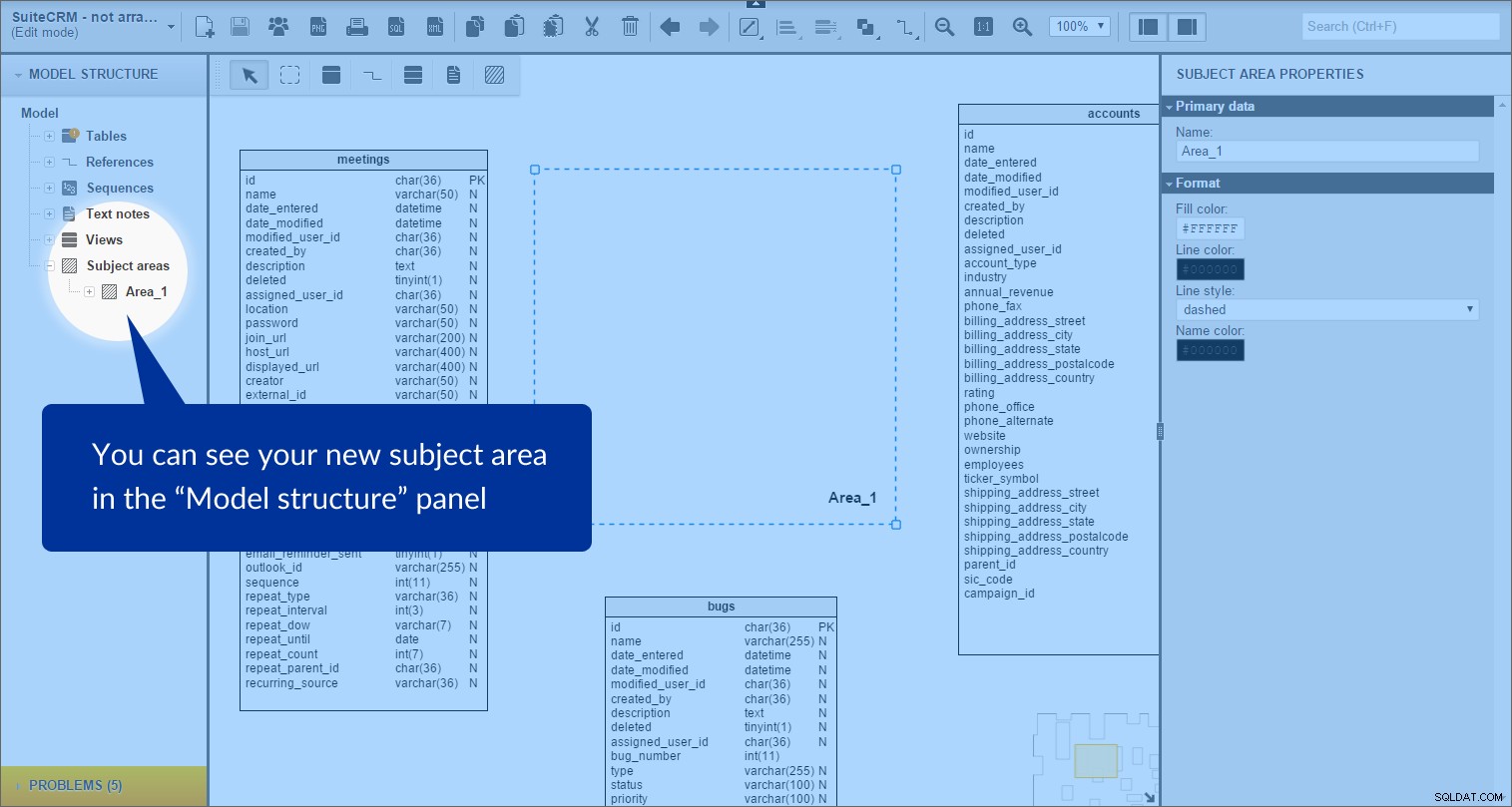
Každá předmětová oblast obsahuje seznam všech objektů, které jsou uvnitř jejích hranic; v tomto případě se jedná o tabulky a typy odkazů.
V SuiteCRM existuje mnoho tabulek, které sdílejí společnou předponu. Začal jsem tedy seskupovat prefixové tabulky dohromady. Podívejte se jako příklad na tabulky „acl“. Na panelu „Struktura modelu“ jsem našel všechny tabulky, jejichž názvy začínaly „acl_“:
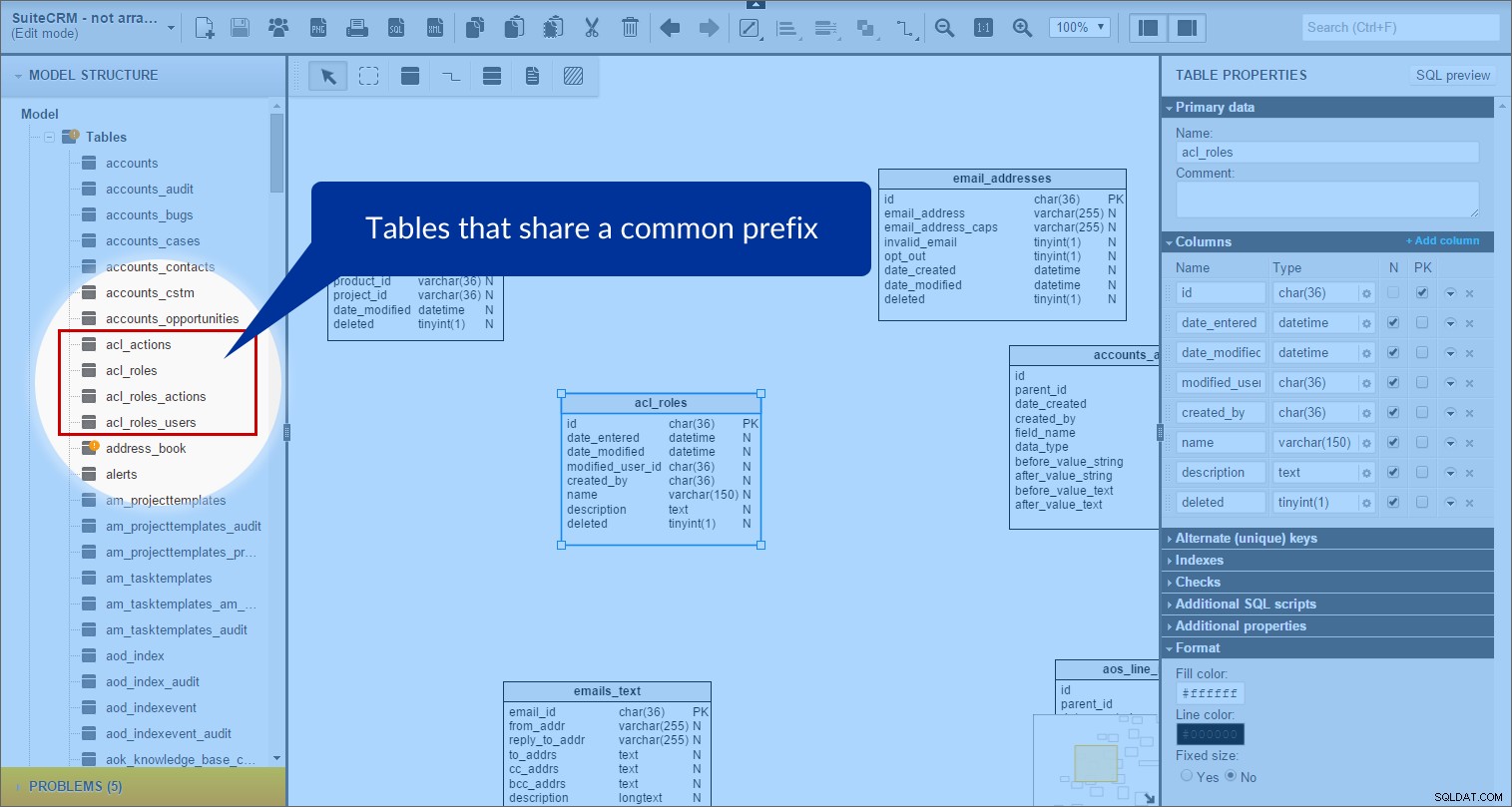
Poté jsem v modelu vytvořil předmětovou oblast „acl“ a přetáhl do ní všechny příslušné tabulky. (Pro lepší viditelnost jsem nastavil barvu pozadí na fialovou.)
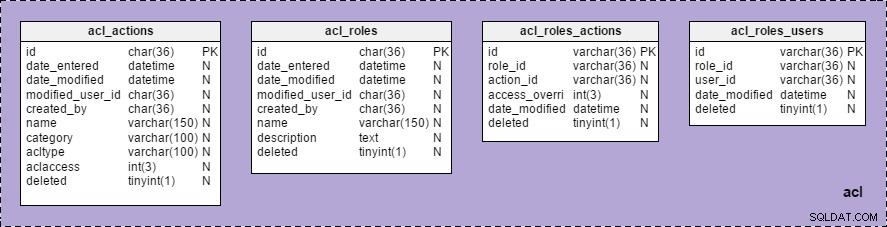
Nyní můžeme vidět skupinu „acl“ se seznamem všech tabulek, které do ní patří, pod „Předmětové oblasti“ v „Struktura modelu“ :
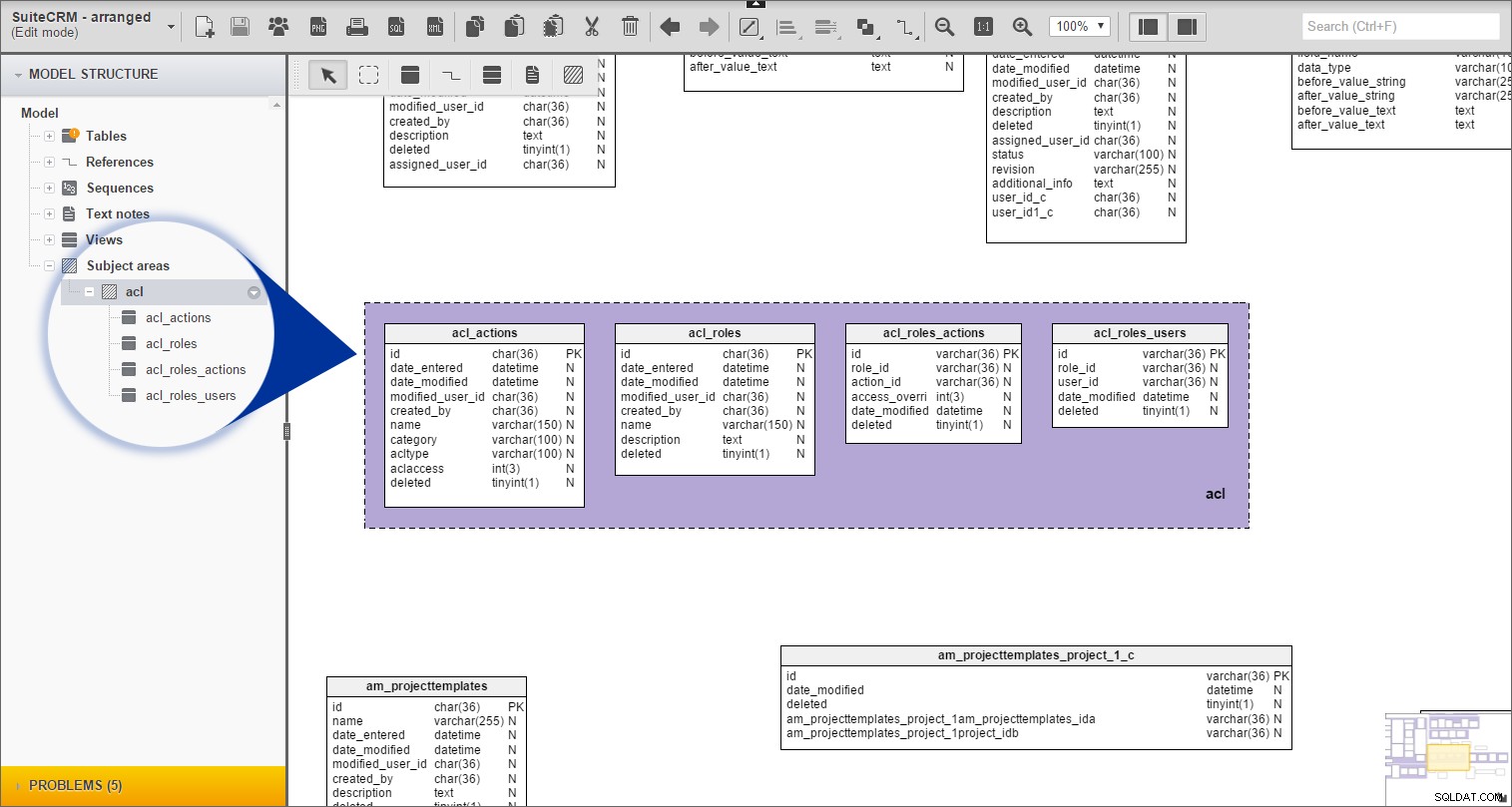
Zopakoval jsem stejný postup pro všechny zbývající tabulky s předponou.
Krok 3:Uspořádejte zbývající tabulky.
Dvakrát stejná tabulka v diagramu? Tabulkové zkratky!
Existuje asi 80 prefixovaných tabulek. Po jejich seskupení mi zbylo asi 120 ‚divokých‘ stolů. Ty jsou smysluplné:ukládají informace o uživatelích, klientech, hovorech, schůzkách a dalších věcech CRM. To je spousta informací, které bychom měli zůstat v souhrnu, takže pojďme tyto tabulky seřadit.
Funkce, kterou jsem považoval za nejužitečnější pro uspořádání těchto tabulek, se nazývá tabulkové zkratky . Někdy chcete v modelu použít stejnou tabulku více než jednou. (Proč? Chcete-li model vyrovnat a vyhnout se překrývání.) To lze snadno provést pomocí „Kopírovat“ a „Vložit jako zástupce“ tlačítka.
Stačí vybrat tabulku, pro kterou chcete vytvořit zástupce, a kliknout na Kopírovat na horním panelu nástrojů (nebo stiskněte Ctrl + C ):
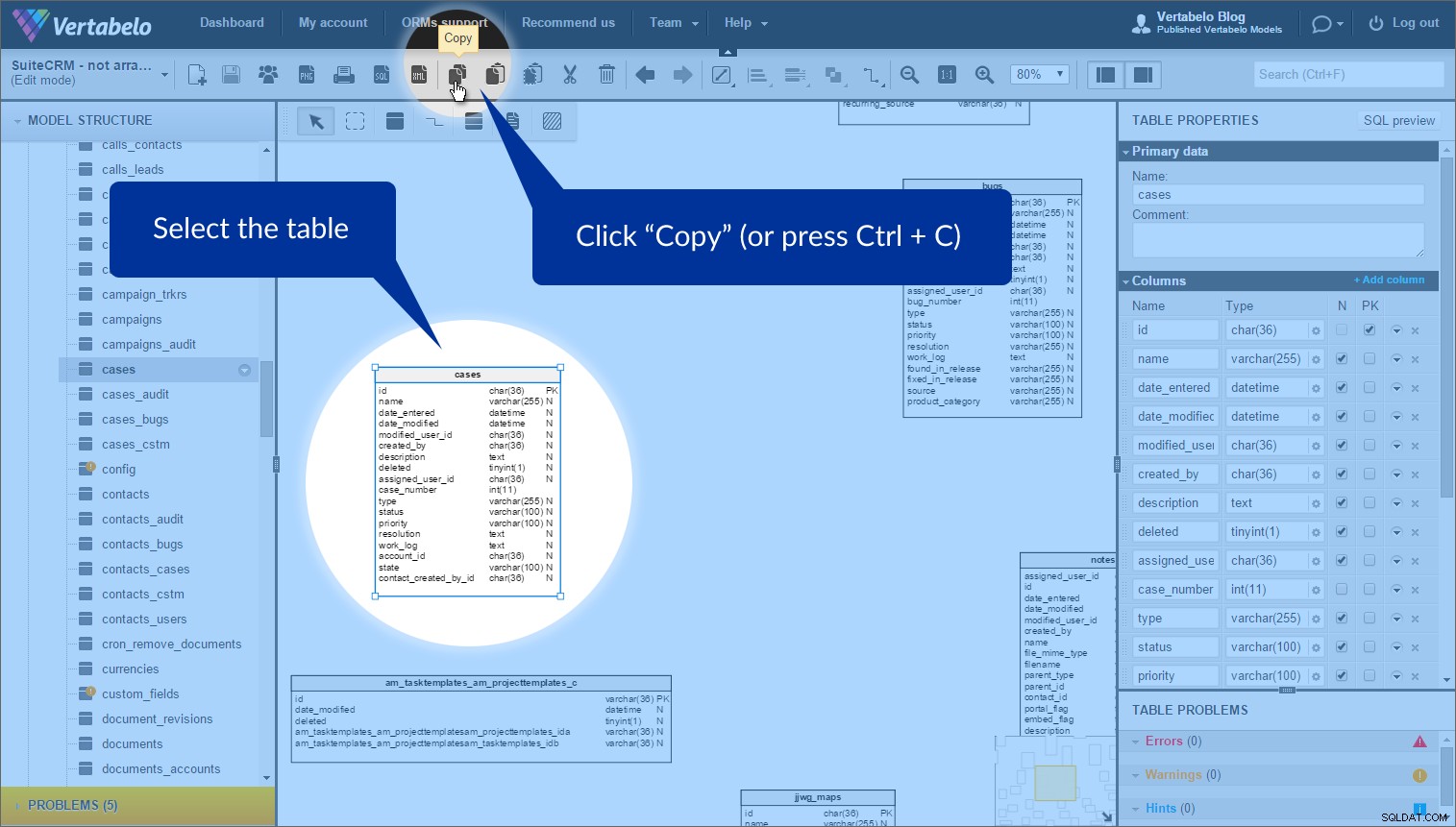
Chcete-li vytvořit zástupce, klikněte na „Vložit jako zástupce“ (nebo stiskněte Ctrl + K ). Poté se objeví nová tabulka s tečkovaným obrysem:
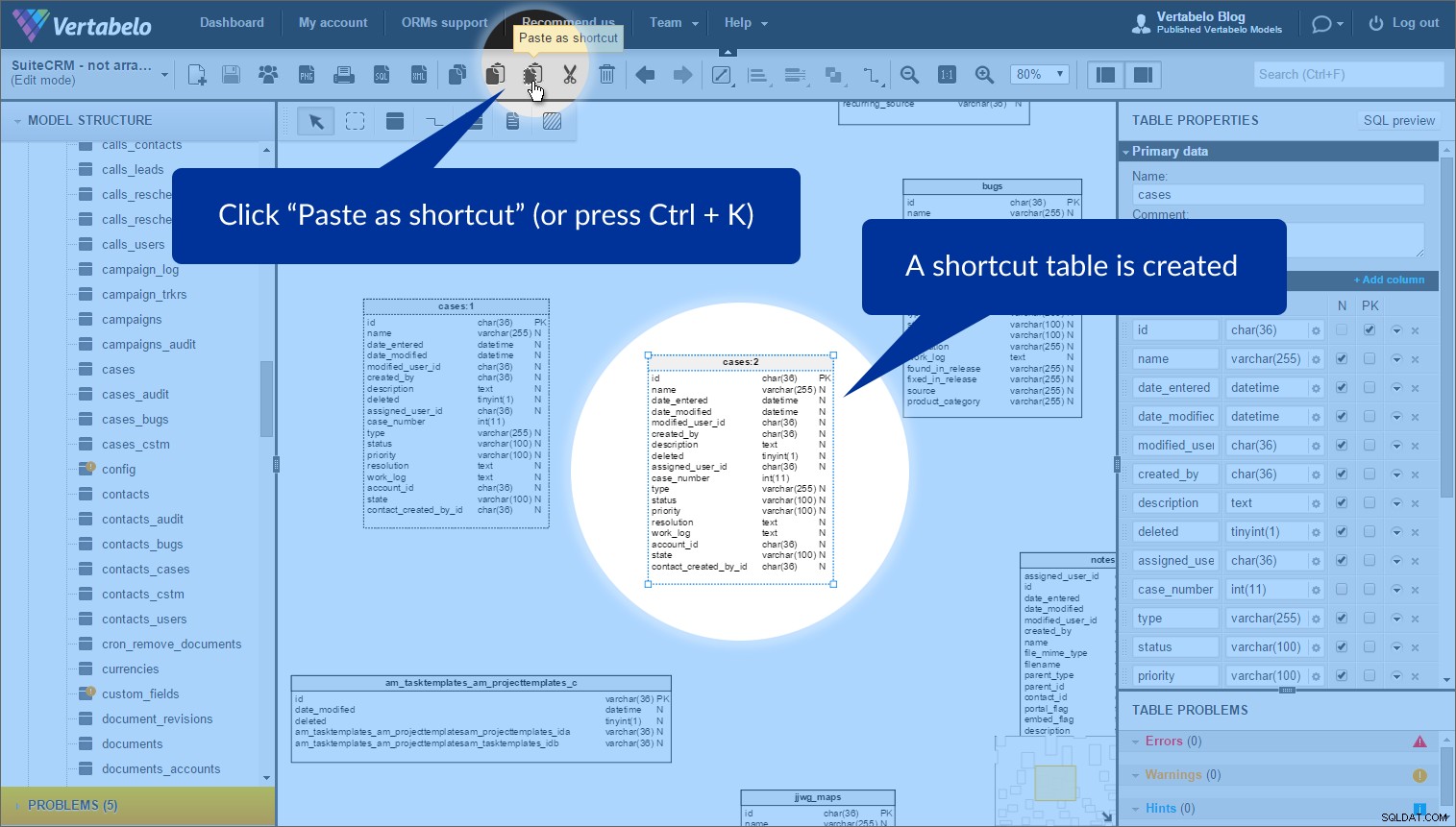
Toto není kopii tabulky, ale jinou instanci původní tabulky. Můžeme jej umístit kamkoli do našeho modelu. Použil jsem instance stejné tabulky v různých tematických oblastech, abych se vyhnul překrývajícím se odkazům. Stojí za zmínku, že každá instance tabulky má přiřazený název předmětové oblasti (vedle názvu), když se nachází v této předmětové oblasti.
Dobrým příkladem toho, jak to funguje, jsou users stůl. Lze jej nalézt v části „Uživatel a účty“, „Role“, „Dokumenty“ a další tematické oblasti. To uvidíme později v modelu.
Při vytváření tematických oblastí se zavedenými vztahy mezi tabulkami hojně používám zkratky tabulek. Chcete-li vidět, jak to funguje, podívejte se na předmět „Příležitosti“ zmapovaný níže. Všimněte si, že všechny tabulky v dané předmětové oblasti jsou pojmenovány podle tohoto pravidla:{název tabulky} :{název předmětové oblasti} .
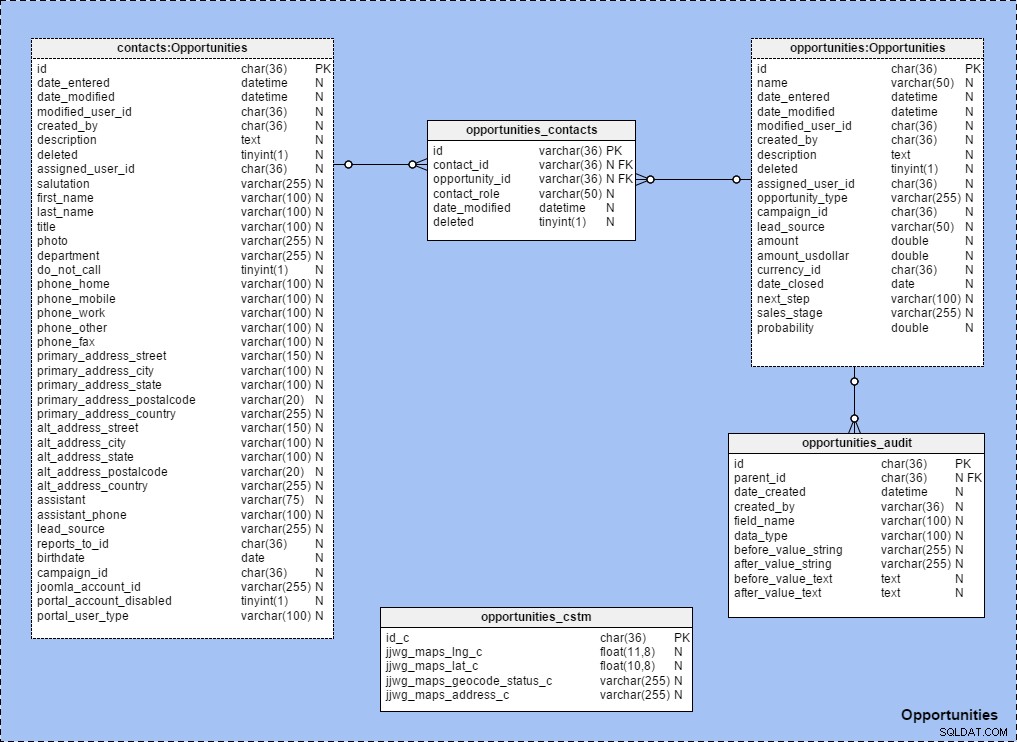
Když rozbalíme {název předmětové oblasti} v panelu „Struktura modelu“ jasně vidíme, že obsahuje tabulky a odkazy:
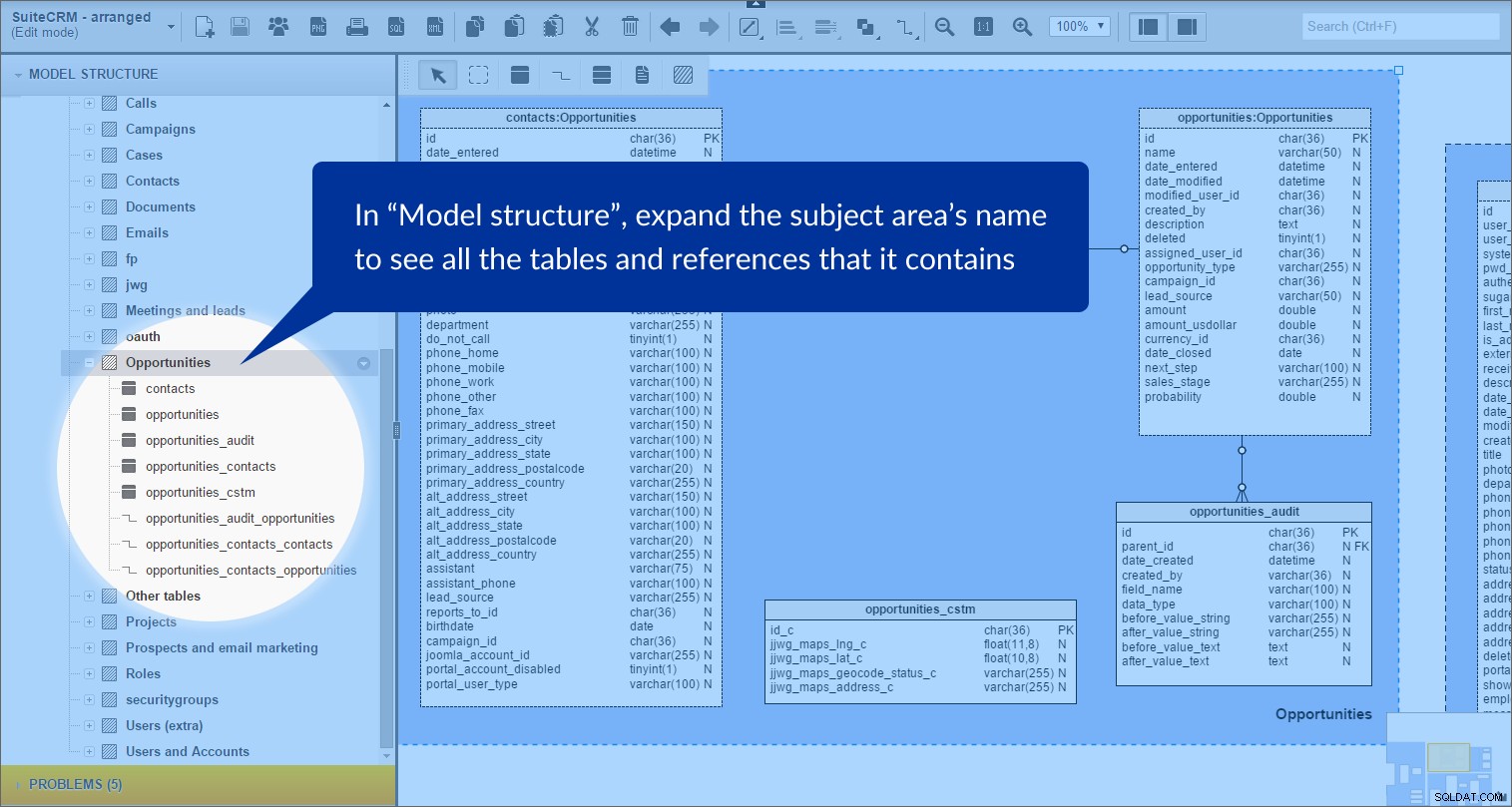
Udělal jsem to pro následující tematické oblasti:„Hovory“, „Případy“, „Kampaň“, „Kontakty“, „Dokumenty“, „Schůzka a potenciální zákazníci“, „přísaha“, „Projekty“, „Prospekty a e-mailový marketing“, „Role“ a „Uživatelé a účty“. Všechny tyto oblasti sdílejí světle modré pozadí.
Zbývající tabulky jsou seskupeny podle názvu a předpokládaného významu:„E-maily“, „Uživatelé (extra)“ a „Další tabulky“. Tyto skupiny mají barvu pozadí nastavenou na světle červenou.
Když dvakrát kliknete na název tabulky v navigačním stromě, pohled se přiblíží na tuto tabulku v modelu a vyberete ji. Když přiblížíte otáčením kolečka myši, pohled se přiblíží ve směru ukazatele myši.Aranžovaný model
Použil jsem dříve popsané možnosti k co největšímu zploštění modelu při logickém seskupování tabulek. Výsledkem je 26 tematických oblastí, z nichž některé obsahují pouze tabulky, zatímco jiné mají tabulky a vztahy. Pojďme si udělat rychlý přehled každé kategorie:
Předmětové oblasti, které obsahují tabulky a vztahy:
„Hovory“, „Kampaně“, „Případy“, „Kontakty“, „Dokumenty“, „Schůzky a potenciální zákazníci“, „Příležitosti“, „Projekty“, „Zájemci a e-mailový marketing“, „Role“, „Uživatelé a účty“
Všechny vztahy jsou nastaveny jako nepovinné. Tím se zachovají informace o tom, že tyto tabulky spolu souvisí a pomocí jakých atributů.
Předmětové oblasti, které obsahují pouze tabulky:
„acl“, „am“, „aod“, „aok“, „aop“, „aor“, „aos“, „aow“, „E-maily“, „fp“, „jwg“, „oauth“, „security_groups ““, „Uživatelé navíc“
To neznamená, že zde vztahy neexistují; jen nejsou zdůrazňovány.
Předmět „Další tabulky“ je určen pro tabulky, které se ve skutečnosti nehodí do konkrétní skupiny.
Jak model vypadá?
Přeuspořádaný model vypadá takto:
Zjevně byla použita konvence pojmenování. Zde je přehled pokynů, kterými jsme se řídili:
- Názvy tabulek jsou většinou v množném čísle:
users,contracts,folders,roles,tasks. Některé názvy tabulek jsou jednotné, napříkladproject. - Primární klíč ve většině tabulek se nazývá jednoduše
ida je typu char(36). - Když nastane vztah jedna k mnoha, cizí klíč se obvykle jmenuje
parent_id. (Příklad:contacts_audit.parent_idje odkaz nacontacts.id.) - Ve relacích many-to-many „
parent_id“ nelze použít jako název pro více sloupců. Místo toho je použit jednotný název tabulky s příponou „_id“. (Příklad:contacts_bugs.bug_idje odkaz nabug.id.) - Jsou situace, kdy je stejný sloupec použit jako cizí klíč pro více tabulek. (Příklad:
calls.parent_idodkazuje na sloupec id v každé z následujících tabulek:accounts,bugs,cases,contacts,leads,tasks,opportunities and prospects. Hodnoty v databázi jsem nezkontroloval, ale odhaduji, že v těchto tabulkách nejsou žádné stejné klíčové hodnoty. Protože všechny jsou typu char(36), pravděpodobně se používá nějaká kombinace názvu tabulky a automatického přírůstku. To si ověříme v nadcházejících článcích.) - Používáme stejné názvy pro sloupce, které mají v různých tabulkách stejný význam. (Příklad:
modified_user_id,created_byaassigned_user_idlze nalézt v mnoha tabulkách v modelu. Všechny jsou odkazovány nausers.id.)
Co bude dál?
V nadcházejících článcích budeme používat GUI SuiteCRM a budeme sledovat změny, které to v databázi způsobí. S těmito informacemi se pokusíme provést změny v modelu, reorganizovat tematické oblasti a v případě potřeby navázat spojení. Také se podíváme na další pravidla specifická pro SuiteCRM, jako je způsob generování primárních klíčů.
Práce s velkými databázovými diagramy není nikdy snadná práce. Stejně jako budování dobrého základu pro domov, trávit více času na základech nyní přinese výhody později. Pokud chceme analyzovat modely, jako je ten, který stojí za SuiteCRM, analyzování předtím, než zorganizujeme strukturu modelu a definujeme vztahy mezi tabulkami, je to sisyfovský styl.