Při navrhování databáze je třeba mít na paměti spoustu věcí a jen velmi málo z nás si dokáže zapamatovat každý cenný tip a trik, který jsme se naučili. Pojďme se tedy podívat na některé online zdroje, které obsahují tipy a osvědčené postupy pro návrh databáze. Postupem času se podělím o své vlastní názory na prezentované nápady na základě mých zkušeností s návrhem databází.
Je zřejmé, že tento článek není vyčerpávajícím seznamem, ale pokusil jsem se zkontrolovat a okomentovat průřez zdrojů. Doufejme, že najdete informace, které nejlépe vyhovují vašim potřebám a cílům.
Jako vedlejší poznámku jsem byl překvapen, když jsem zjistil, že mnoho článků souvisejících s postupy návrhu databází mělo velmi málo příkladů; online zdroje, které jsem kontroloval u článku o chybách a omylech, jich měly vyšší procento. Tento nedostatek je nevýhodou, protože příklady jsou extrémně důležité pro pochopení pointy.
Databázové tipy pro zkušené designéry
Nejprve začněme zdroji obsahujícími pokročilé tipy pro návrh databáze a osvědčené postupy. Ty jsou pro designéry, kteří již nějakou dobu pracují v datovém modelování. Některé články jsou zaměřeny na středně pokročilé úrovni, ale pokud pojednávají o pokročilých konceptech, zahrnul jsem je do tohoto seznamu.
Pokyny k databázi (RDBMS/SQL)
od Steva Djajasaputry | SOA, Java, vývoj softwaru – BlogSpot | 16. ledna 2013
Tento článek od pana Djajasaputry je docela působivý:uvádí četné tipy pro schéma, indexy a pohledy; poskytuje také poměrně podrobnou konvenci pojmenování. A jeho tipy pokračují (a dále). Šíře je působivá, ale neexistují téměř žádné příklady. Některé jeho body by mohly být považovány za diskutabilní, ale celkově jde o velmi solidní prezentaci.
Zejména na mě udělalo dojem, že uvádí přesné pravidlo o používání přirozených versus umělých (tj. náhradních nebo generovaných) primárních klíčů. Udržuje to hezké a jednoduché a upřesňuje, že bychom měli preferovat přirozený klíč, protože je smysluplný. Poskytuje také pokyny pro nejlepší použití umělého klíče – konkrétně, když přirozený klíč není jedinečný nebo když potřebujete změnit hodnotu přirozeného klíče. Jeho vlastními slovy:
Nejprve raději použijte přirozený klíč, protože je smysluplnější a aby se zabránilo duplicitám (znovu použijte existující sloupec). Existují však případy, kdy potřebujete umělý klíč:když přirozený klíč není jedinečný (např. jména) nebo pokud potřebujete změnit hodnotu.Protože jeho seznam tipů je tak dlouhý, nedokážu si představit, že bych si je všechny zapamatoval. Ale na každou sekci lze odkazovat, když pracujete na návrhu databáze, výkonu, uložených procedurách a verzování. Je zde také část o specifických bodech pro Oracle, která by byla užitečná, pokud spolupracujete se společností Oracle nebo plánujete její podporu.
Celkově vzato se jedná o velmi cenný a komplexní zdroj.
9 tipů pro lepší návrh databáze
od Jeffreyho Edisona | Vertabelo Blog | 22. září 2015
Zde si dopřeji malou sebepropagaci.
Tento článek 9 tipů pro lepší návrh databáze vychází z mých zkušeností designéra a architekta. Také jsem našel další poznatky z průzkumu osvědčených postupů ostatních pro návrh databází.
Můj seznam představuje některé z hlavních problémů, které mohou nastat při práci s datovými modely. Uspořádal jsem tipy v pořadí, v jakém se vyskytují během životního cyklu projektu (spíše než podle důležitosti nebo toho, jak často se objevují), protože to by bylo nejužitečnější, alespoň z mého pohledu. Čtenáři se mohou řídit tímto kontrolním seznamem osvědčených postupů v průběhu životního cyklu projektu.
Z článku:
Abychom parafrázovali Al Caponeho (nebo Johna Van Burena, syna 8. prezidenta USA), „testujte brzy, testujte často“. Tímto způsobem následujete cestu kontinuální integrace. Testování v rané fázi vývoje šetří čas a peníze. Při testování databáze by cílem mělo být simulovat produkční prostředí:„Den v životě databáze“. Jaké objemy lze očekávat? Jaké interakce uživatelů jsou pravděpodobné? Řeší se hraniční případy?Když jsem věnoval pozornost těmto tipům, zjistil jsem, že databáze jsou lépe navržené a robustnější. I když žádná z těchto činností nezabere enormní množství času, každá může mít obrovský dopad na kvalitu vašeho datového modelu.
Doufám, že můj seznam tipů bude užitečný pro středně pokročilé a pokročilé designéry.
20 doporučených postupů návrhu databáze
od Cagdase Basaranera | Zůstatek kódu – BlogSpot | 24. července 2011
Pan Basaraner nám předkládá zajímavý seznam 20 doporučených postupů při návrhu databáze. Byl bych raději, kdyby některé z nich seskupil; například první čtyři položky by mohly být všechny zahrnuty v části „Používejte konvence dobrého pojmenování“.
Kromě toho uvádí, že použití syntetického, generovaného (celočíselného) ID jako primárního klíče všech tabulek je osvědčeným postupem. Ve skutečnosti je to stále diskutované téma s argumenty pro a proti. Některé z jeho osvědčených postupů jsou docela obecné, jako „Pro… databázové systémy pro kritika [sic] použijte zotavení po havárii a bezpečnostní službu…“ S tímto bodem nesouhlasím, ale je na velmi vysoké úrovni.
Pozitivní je, že tento článek byl jedním z mála, které zmiňují použití frameworku pro objektově relační mapování (ORM). Někteří komentátoři nesouhlasili s tím, jak byl tip formulován, ale je zmíněno alespoň použití rámce ORM:
Pokud je kód aplikace dostatečně velký, použijte rámec ORM (objektové relační mapování) (tj. Hibernate, iBatis ...). Výkonnostní problémy rámců ORM lze vyřešit pomocí podrobných konfiguračních parametrů.Přesto mohl být tento seznam vylepšen. Měl by jasně identifikovat body, které jsou specifické pouze pro některé systémy pro správu databází (například SQL Server). Přesné statistiky týkající se výkonu, heuristiky nebo důležitosti trávit čas nad designem spíše než na údržbu a předělat bylo by to dobré. Bylo také zapotřebí více příkladů, ale to je problém většiny těchto článků.
Pokud pracujete se serverem SQL Server, uvažujete o použití rámce ORM nebo potřebujete spíše odrážkový seznam tipů než dlouhý a podrobný článek, pak je tento článek pro vás.
(Poznámka:Tento článek se také objevil na několika dalších webech, včetně CodeBuild, Java Code Geeks a DZone.)
Základy návrhu databáze. 10 věcí, které absolutně musíte udělat
od Michelle A. Poolet | SQL Server Pro | 1. března 2011
Část tipů paní Pooletové je zcela standardní a lze je nalézt v mnoha dalších zdrojích, ale existuje i několik poněkud neobvyklých bodů. Mezi jejími obecnými body propaguje použití podtypů a supertypů (s nimiž plně souhlasím), protože to odráží objektově orientovaný design a vývojáři jej mohou snadno pochopit. Z jejího článku:
Nebojte se zahrnout entity supertypů a podtypů do svého návrhu v CDM a dále. Podtypy představují klasifikace nebo kategorie nadtypu... Entity jsou reprezentovány jako podtypy, když kategorizace entity vyžaduje více než jedno slovo nebo frázi.
Pokud má kategorie svůj vlastní život se samostatnými atributy, které popisují, jak kategorie vypadá a chová se, a oddělenými vztahy s jinými entitami, pak je čas vyvolat strukturu nadtypu/podtypu . Pokud tak neučiníte, zabráníte úplnému pochopení dat a obchodních pravidel, která řídí sběr dat.
Některé z jejích komentářů konkrétně odkazují na MS SQL Server, i když jsou komentáře ve skutečnosti obecnými problémy. Jeden hlavní bod, který paní Poolet uvádí, je velmi specifický pro SQL Server:„Kód úložiště, který se dotýká dat databáze jako uložená procedura“.
To je v pořádku, pokud plánujete podporu pouze jednoho systému správy databází, jako je SQL Server. Ale pro přenosné implementace by to nebyla dobrá rada. Obecně navrhuji pro přenositelnost na alespoň dva systémy správy s různými jazykovými podporami uložených procedur. Proto bych se této praxi vyhnul.
Tento článek je nejužitečnější pro lidi, kteří vyvíjejí pro SQL Server a zaměřují se na americký trh (spíše než na mezinárodní systém). Jako Američan žijící v zahraničí jsem však zjistil, že některé její příklady jsou až příliš „zaměřené na USA“. Neameričan například nemusí rozumět tomu, co je Zip+4 doména je, a proto by nechápal, proč by tato doména měla mít vlastnost NOT NULL.
Abych to ilustroval, vytvořil jsem datový model pro obě americké neamerické adresy. Budeme předpokládat, že náš datový model může vyžadovat propojení entit s více než jednou adresou:například jedna pro fakturaci, jedna pro doručení. První adresa bude spojena s platební metodou; v tomto případě bude adresa použita k ověření vašeho práva autorizovat tuto platbu. Doručovací adresa je samozřejmě ta, kam bude objednávka doručena.
Vytvořme americkou adresu jako součást modelu databáze zákaznických objednávek. (Poznámka:nejedná se o úplný model, ale o příklad uložení objednávek produktů.)
Wise Coders Solutions doporučuje definovat samostatná pole pro čísla domů a názvy ulic a nastavit tato pole jako NOT NULL; to by zakázalo jakoukoli adresu, která nemá číslo domu a název ulice. Ale co lidé, kteří používají PO boxy? Jejich adresy se obvykle zapisují jako „PO Box 123“. Měli bychom je přinutit, aby jako číslo domu uvedli číslo PO Box a jako název ulice „PO Box“? Myslím, že ne.
Místo toho použijeme formulář s „Řádek adresy 1“ a „Řádek adresy 2“. Několik lidí argumentovalo proti používání čísel v názvech polí, ale pro mě je to docela zřejmé řešení. Také jsem definoval maximální délky polí (35 a 70 znaků), které jsou typické pro mezinárodní platby.
Všimněte si, že designy pro USA i pro neamerické vzory mají pole pro regiony v rámci země, ale vzor pro USA vyžaduje, aby byla zahrnuta 2znaková zkratka státu. Všimněte si také, že americký design neumožňuje adresy v jiných zemích.
Pokud máte obavy z globálního využití vaší databáze, musíte ve fázi návrhu uvažovat globálně. Jsou naše databáze připraveny pro mezinárodní použití našich aplikací?
Poučení ze špatného návrhu datového skladu
od Michelle A. Poolet | SQL Server Pro | 15. června 2009
Tento článek se zabývá datovým skladem (DWH) a některými problémy s jeho návrhem a implementací. Mírně se zaměřuje na SQL Server, ale je to docela ortodoxní přehled navrhování pro datové sklady a business intelligence. Zakoupení a vytváření uživatelsky přívětivých rozhraní nemusí být nejužitečnější z tipů, ale nesouhlasím s nimi – prostě si nemyslím, že jsou součástí návrhu DWH.
Paní Poolet prohlašuje, že proces extrakt-transformace (ETL) by měl provádět kontroly kvality dat a potenciálně „čistit“ data, dokud nebude existovat přijatelný standard kvality dat. Podle mého názoru to riskuje vytvoření datového skladu, který nebude správně zrcadlit informace extrahované ze zdrojového systému. Čištění dat by mělo být prováděno ve zdrojových systémech. ETL by měla pouze transformovat data tak, aby je bylo možné načíst do datového skladu.
Pozitivní je, že doporučení recyklace nebo vytvoření opakovaně použitelných ETL rutin je vysoce relevantní. Navíc souhlasím s paní Poolet ohledně škálovatelnosti. Její komentáře k řízení rizik a dodržování předpisů, zejména Sarbanes-Oxley Act, se zdají být zcela konkrétní; Předpokládám, že pocházejí z oblasti jejího podnikání.
Nakonec má pěkný kontrolní seznam bodů týkajících se dimenzí, tabulek faktů a výběru schémat během návrhu OLAP (online analytické zpracování). Zdá se, že jsou velmi důležité během procesu návrhu databáze. Byl bych rád, kdyby tento seznam byl delší, s více podrobnostmi nebo příklady, ale byl jsem rád, že byly zahrnuty tyto praktické tipy.
11 důležitých pravidel návrhu databáze, kterými se řídím
od Shivprasad Koirala | Kód projektu | 25. února 2014
Velmi se mi líbí rozumné a jasné rady na začátku tohoto článku. Pojmy jako „zvažte povahu aplikace“ a „rozdělte svá data na logické části“ jsou na místě. To jsou důležité pomocníky při vytváření vašeho datového modelu. Jak říká pan Koirala:
Když začnete s návrhem databáze, první věcí, kterou je třeba analyzovat, je povaha aplikace, pro kterou navrhujete, zda je transakční nebo analytická. Najdete mnoho vývojářů, kteří standardně používají pravidla normalizace, aniž by přemýšleli o povaze aplikace a později se dostali do problémů s výkonem a přizpůsobením.Existuje však několik bodů, které mě nechávají nepřesvědčené. Vezměte například centralizaci párů název-hodnota do jedné tabulky. Tento design One True Lookup Table (OTLT) je diskutován, ale obecně je považován za špatný postup nebo přinejmenším za anti-pattern v designu. Jsem na straně skupiny anti-OTLT; tyto tabulky přináší řadu problémů. Jako ekvivalent této praxe bychom mohli použít analogii vývoje softwaru s použitím jediného enumerátoru k reprezentaci všech možných hodnot všech možných konstant.
Abychom vám připomněli, tabulka OTLT obvykle vypadá nějak takto, se záznamy z více domén vhozenými do stejné tabulky. Souhlasím s anti-OTLT skupinou; tyto tabulky představují řadu problémů.
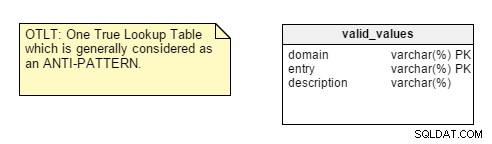
Některé body navíc působí trochu esotericky, například „sledujte data oddělená oddělovači“. I když je to platný bod, není to ten, na který obvykle myslím při vytváření nového datového modelu.
Pan Koirala má několik návrhových položek OLAP, které obecně nejsou uvedeny v jiných seznamech osvědčených postupů. Jeho zahrnutí návrhu dimenzí a faktů může být užitečné, ale může být také nebezpečné pro začínající návrháře.
Tento článek je zajímavý, pokud přecházíte od začátku k pokročilejšímu datovému modelování. Pomůže vám zvážit analytickou versus transakční povahu vašich budoucích modelů.
Big Data:Pět jednoduchých tipů pro výkon návrhu databáze
od Dave Beulke | davebeulke.com | 19. března 2013

Článek pana Beulke se zabývá designovými tipy zaměřenými na výkon. Ukazuje, jak kontrolovat správnou normalizaci:ani příliš, ani příliš málo. (Přílišná normalizace bude mít negativní dopad na výkon databáze.)
Použití přirozených obchodních klíčů namísto generovaných primárních klíčů je také dobrou radou, když se chcete vyhnout převodu z obchodního klíče na vygenerované ID řádku pro každý přístup k databázi.
Dobrou radou je také použití správných standardů pojmenování a typů sloupců. Pointa ohledně nadměrného používání sloupců s možnou hodnotou Null je správná:vytváření všech sloupců jako sloupců s možnou hodnotou Null je chyba, ale definování sloupce jako sloupce s možnou hodnotou Null může být vyžadováno pro konkrétní obchodní funkci. Vlastními slovy autora:
Mohou všechny sloupce obsahovat hodnotu NULL? V rámci definic databázových sloupců by měly být analyzovány, vyhodnoceny a prototypovány dobré datové domény, rozsahy a hodnoty pro obchodní aplikaci. Dobré výchozí hodnoty, omezený rozsah hodnot a vždy hodnota jsou nejlepší pro výkon a aplikační logiku. Sloupce s možností NULL jsou vhodné pouze v případě, že data jsou neznámá nebo ještě nemají hodnotu. Údaje o datu úmrtí někoho jsou klasickým příkladem sloupce s hodnotou NULL, protože nejsou známy, pokud již nejsou mrtví. Ujistěte se, že návrh databáze představuje data, která jsou známá, a používá pouze minimum sloupců s možností NULL.Všechny tipy pana Beulkeho jsou velmi pevné, i když poněkud neoriginální. Uvítal bych více položek Big Data – to je ostatně název článku. Nakonec jsem měl pocit, že článek postrádá hloubku i šířku a nemá žádné příklady k objasnění bodů. Nabízí však cenné rady týkající se normalizace a přirozených klíčů.
10 doporučených postupů návrhu databáze
od Ann All | Podnikové aplikace dnes | 15. července 2014
Deset doporučených postupů návrhu databáze je ve skutečnosti prezentováno jako série snímků. Ms. All obsahuje informace od ostřílených vývojářů, jako je Michael Blaha. Podporuje opětovné použití vašich osvědčených postupů a vzorů. Ty jsou srozumitelné a osvědčené a v tomto ohledu jsou vhodnější než datové modely, které musí být vytvořeny od začátku. Z článku paní Allové:
Často například provádím zpětnou analýzu databází – databází aplikace, která má být nahrazena, i databází souvisejících aplikací. Tyto existující databáze často nemají dostupný datový model. Datový model je však součástí schématu databáze a lze jej alespoň částečně extrahovat pomocí technik reverzního inženýrství databáze. … Existují osvědčené reprezentace dat, které se často vyskytují a není třeba je znovu vytvářet od začátku.Toto je krátká prezentace, kterou mohou návrháři datových modelů rychle prohledat a získat tipy, které s nimi rezonují. Pro mě je tip na opětovné použití jedním z mých oblíbených.
Osvědčené postupy pro databázi
od Cunningham &Cunningham, Inc.
Tyto osvědčené postupy začaly dobře, ale pak se dostaly do některých lepkavých problémů. Nejsem přesvědčen, že nabízené rady jsou vždy správné.
Pozitivní je, že jsou zde velmi pěkné popisy kontroverzních „osvědčených postupů“, jako je vždy používání automaticky generovaných náhradních klíčů a používání nebo vyhýbání se uloženým procedurám. Jako příklad:
Předchozí autor napsal:"Obecně se vyhněte primárním klíčům, které mají význam. Jména nejsou jedinečná a mnoho zdánlivě jedinečných identifikátorů, jako jsou čísla sociálního pojištění, ve skutečnosti nejsou, kvůli problémům se spolehlivostí dat v reálném světě." Stručně řečeno, toto je doporučení mít vždy automaticky generovaný (obvykle číselný) náhradní klíč namísto logického klíče založeného na doméně. Toto je spíše patová odpověď na složitý problém, i když je to taková, která v mnoha případech postačí a je přinejmenším výhodnější než mít žádný primární klíč.(Poznámka autora:Při hledání těchto dvou vět na Googlu se mi nepodařilo najít tohoto „předchozího autora“.)
A je uveden odkaz na souhrnný článek o hlavních argumentech na každé straně debaty Auto Keys versus Domain Keys.
Na druhou stranu jsem zjistil, že tipy na „rozdělení operačního systému, dat a přihlašování na různé fyzické disky“ a „používání RAID“ jsou trochu tajemné. Nechápejte mě špatně – za určitých okolností je to pravděpodobně dobrá rada, ale nezařadil bych ji do svého seznamu 20 nejlepších.
Tipy pro návrh databáze
od Wise Coders
V této sbírce je několik jedinečných a zajímavých tipů, jako je doporučení uzavřít transakce co nejdříve.
Ne zcela souhlasím se všemi zde uvedenými tipy na design. Například:
Předpokládejme pole „Stav“ s hodnotami „Aktivní“, „Neaktivní“ a „Nečinný“. Můžete uložit hodnotu jako úplný název, ale to může být neefektivní. Například uložení výčtu nebo znaku (1) s možnými hodnotami ‚a‘, ‚i‘, ‚d‘ zabere méně místa v databázi.To je přinejmenším kontroverzní – jiné zdroje doporučují nepoužívat „tajné kódy“, jako je tento. Místo toho použijte k uložení těchto stavových kódů samostatnou tabulku.
Kromě toho jsou statistiky spojené s tipy na výkon diskutabilní a v článku nejsou žádné příklady.
Pozitivní je, že toto je pěkný krátký seznam tipů, které by měly být dostupné středně pokročilým databázovým modelářům.
Zdroje pro začínající návrháře databází
Nyní se podívejme na několik článků pro ty, kteří s návrhem databází teprve začínají.
Základy dobrého návrhu databáze ve vývoji webu
od Kayly Knight | Onextrapixel.com | 17. března 2011
Zde jsme trochu pokročilejší, s radami od funkčnosti po modelovací nástroje.
Paní Knightová nás provede úvodem do návrhu databáze. Její článek je zajímavý, protože klade důraz na databáze pro vývoj webu. I tak jsou její body poměrně univerzální a lze je použít při návrhu databáze v mnoha situacích.
Článek začíná tím, že nás žádá, abychom se obecně zamysleli nad funkčností, nejen nad databází:
Mysli mimo databázi. Zkuste se zamyslet nad tím, co bude web potřebovat. Pokud je například potřeba členská stránka, prvním instinktem může být začít přemýšlet o všech datech, která bude muset každý uživatel uložit. Zapomeňte na to, to bude později. Raději si zapište, že uživatelé a jejich informace bude potřeba uložit do databáze a co ještě? Co budou tito členové muset na webu udělat? Budou vytvářet příspěvky, nahrávat soubory nebo fotografie nebo posílat zprávy? Poté bude databáze potřebovat místo pro soubory/fotografie, příspěvky a zprávy.Odtud paní Knightová zavede čtenáře do nástrojů pro návrh databází a kroků zahrnutých v tomto procesu. Její článek uvádí příklady a odkazy na další zdroje.
Myslím, že tento článek by byl skvělým úvodem pro začínající návrháře databází a měl by dobře fungovat s Geek Girl’s série.
Zkoumání tipů pro návrh databáze
od Douga Lowe | Pro figuríny
Seznam „Dummies“ pana Lowea je široká řada základních návrhářských tipů. Mnoho z nich najdete jinde, ale je užitečné mít je na jednom místě. Nenajdete nic jedinečného nebo vysoce kontroverzního, kromě doporučení používat uložené procedury. Vždy zpochybňuji toto silné tvrzení, protože mě velmi znepokojuje přenositelnost datového modelu pro více systémů DBM.
Zde je jeden z rozumných tipů pana Lowea:
Vyhněte se polím s názvy jako CustomerType, kde je hodnota pole jednou z několika konstant, které nejsou definovány jinde v databázi, jako je R pro maloobchod nebo W pro velkoobchod. Dnes můžete mít pouze tyto dva typy zákazníků, ale potřeby aplikace se mohou v budoucnu změnit a vyžadovat třetí typ zákazníka.Tato doporučení jsou nejvhodnější při práci se serverem SQL.
Pět jednoduchých tipů pro návrh databáze
od Lamonta Adamse | TechRepublic | 25. června 2001
Klíčové slovo pro tento zdroj je „jednoduché“. Tyto informace s dalším vysvětlením a příklady naleznete v jiných článcích.
Nicméně rada pana Adamse „Vezměte uživateli klíče pryč“ je zajímavý bod, na jiných místech jen zřídka zmiňovaný. Pokračuje:
Při rozhodování, které pole nebo pole použít jako klíče v tabulce, vždy zvažte pole, která budou uživatelé upravovat. Obvykle je špatný nápad vybrat si jako klíč uživatelsky upravitelné pole.Pan Adams má na mysli to, že byste měli zvážit potenciální požadavek uživatele na úpravu polí při rozhodování, která pole použít jako klíče. Uvítal bych více vysvětlení ohledně alternativ, jako jsou syntetické/generované klíče, ale koncept je dobrý.
S posledním bodem jsem nesouhlasil. Pro každý vámi navržený stůl doporučuje „fudge faktor“:
Není o moc horší než zjistit nebo být informován, že ve vaší „hotové“ databázi chybí pole pro klíčovou informaci. V jedné společnosti, pro kterou jsem pracoval, to byl tak častý jev, že jsme o „zamrznutí databází“ začali mluvit jako o „zamrznutí databáze“.V mé mysli je to v podstatě „přidání několika dalších textových polí na konec“. Zdá se, že to odporuje některým dalším tipům pana Adamse, konkrétně těm, které se týkají pochopení obchodních potřeb a používání smysluplných jmen. Tato extra fudge pole by se jen nazývala něco jako „extra1“ nebo „extra2“. Jaká je jejich obchodní potřeba? A jak jsou tato smysluplná jména? I když se mi líbí většina jeho návrhářských tipů, tento „fudge faktor“ není něco, co dodržuji.
Design databáze:čestná uznání
Je zřejmé, že existují další články, které popisují tipy a osvědčené postupy pro návrh databáze. Další materiály naleznete na následujících odkazech:
Návrh relační databáze:základ osvědčených postupů | od Digital Ethos | 24. prosince 2012
Nejlepší postupy pro návrh schémat databáze (začátečníci) | od Jim Murphy | 28. března 2011
IT Best Practices:Návrh databáze | University of Nebraska–Lincoln
Zdroje pro návrh online databáze:Kam byste šli?
Jak již bylo zmíněno, tento seznam rozhodně nemá být vyčerpávajícím prozkoumáním každého článku o návrhu databáze na internetu. Spíše jsme identifikovali několik článků, o kterých si myslíme, že jsou užitečné, nebo které mají konkrétní zaměření, které vám mohou pomoci.
Neváhejte a doporučte další články.