Již dlouho bylo zjištěno, že proměnné tabulky s velkým počtem řádků mohou být problematické, protože je optimalizátor vždy vidí jako proměnné s jedním řádkem. Bez rekompilace poté, co byla proměnná tabulky naplněna (protože předtím je prázdná), neexistuje pro tabulku žádná mohutnost a nedochází k automatickým rekompilacím, protože proměnné tabulky ani nepodléhají prahu rekompilace. Plány jsou proto založeny na kardinalitě tabulky nula, nikoli jedna, ale minimum je zvýšeno na jedničku, jak popisuje Paul White (@SQL_Kiwi) v této odpovědi dba.stackexchange.
Způsob, jakým bychom mohli tento problém obvykle obejít, je přidat OPTION (RECOMPILE) na dotaz odkazující na proměnnou tabulky, což optimalizátora přinutí zkontrolovat mohutnost proměnné tabulky po jejím naplnění. Abyste nemuseli ručně měnit každý dotaz a přidat explicitní nápovědu pro rekompilaci, byl v SQL Server 2012 Service Pack 2 a SQL Server 2014 kumulativní aktualizaci #3 zaveden nový příznak trasování (2453):
- KB #2952444 :OPRAVA:Nízký výkon při použití proměnných tabulky v SQL Server 2012 nebo SQL Server 2014
Když je aktivní příznak trasování 2453, může optimalizátor získat přesný obrázek mohutnosti tabulky po vytvoření proměnné tabulky. To může být dobrá věc™ pro mnoho dotazů, ale pravděpodobně ne pro všechny, a měli byste si být vědomi toho, jak to funguje odlišně od OPTION (RECOMPILE) . Nejpozoruhodnější je, že optimalizace vkládání parametrů, o které mluví Paul White v tomto příspěvku, se vyskytuje pod OPTION (RECOMPILE) , ale ne pod tímto novým příznakem trasování.
Jednoduchý test
Můj počáteční test sestával z pouhého naplnění proměnné tabulky a výběru z ní; to přineslo až příliš známý odhadovaný počet řádků 1. Zde je test, který jsem provedl (a přidal jsem nápovědu k rekompilaci pro porovnání):
DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, t.name FROM @t AS t; SELECT t.id, t.name FROM @t AS t OPTION (RECOMPILE); DBCC TRACEOFF(2453);
Pomocí SQL Sentry Plan Explorer můžeme vidět, že grafický plán pro oba dotazy je v tomto případě identický, pravděpodobně alespoň částečně, protože jde doslova o triviální plán:

Grafický plán pro triviální skenování indexu proti @t
Odhady však nejsou stejné. I když je příznak trasování povolen, z prohledávání indexu stále získáme odhad 1, pokud nepoužijeme nápovědu pro rekompilaci:
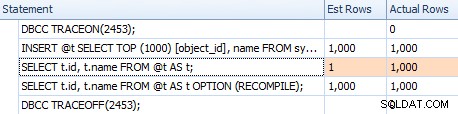
Porovnání odhadů pro triviální plán v mřížce výkazů
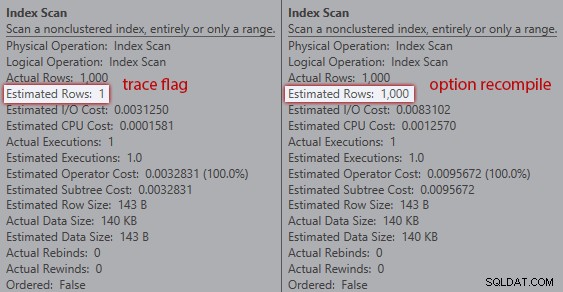
Porovnání odhadů mezi příznakem trasování (vlevo) a překompilováním (vpravo)
Pokud jste někdy byli kolem mě osobně, pravděpodobně si dokážete představit obličej, který jsem v tomto okamžiku udělal. S jistotou jsem si myslel, že buď článek KB uvádí nesprávné číslo příznaku trasování, nebo že potřebuji nějaké jiné nastavení povolené, aby byl skutečně aktivní.
Benjamin Nevarez (@BenjaminNevarez) mě rychle upozornil, že se musím blíže podívat na článek KB „Chyby, které jsou opraveny v SQL Server 2012 Service Pack 2“. Zatímco zakryli text za skrytou odrážkou v části Highlights> Relational Engine, článek se seznamem oprav odvádí o něco lepší práci při popisu chování příznaku trasování než původní článek (zdůrazňuji můj):
Pokud je proměnná tabulky propojena s jinými tabulkami v SQL Server může mít za následek pomalý výkon kvůli neefektivnímu výběru plánu dotazů, protože SQL Server nepodporuje statistiky ani nesleduje počet řádků v proměnné tabulky při kompilaci plánu dotazů.Z tohoto popisu by se tedy zdálo, že příznak trasování je určen pouze k řešení problému, když se proměnná tabulky účastní spojení. (Proč toto rozlišení není v původním článku, netuším.) Ale funguje to také, pokud přimějeme dotazy dělat trochu více práce – výše uvedený dotaz je optimalizátorem považován za triviální a příznak trasování nefunguje v tom případě se ani nesnažte nic dělat. Ale naskočí, pokud se provede optimalizace na základě nákladů, a to i bez spojení; příznak sledování prostě nemá žádný vliv na triviální plány. Zde je příklad netriviálního plánu, který nezahrnuje spojení:
DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT TOP (100) t.id, t.name FROM @t AS t ORDER BY NEWID(); SELECT TOP (100) t.id, t.name FROM @t AS t ORDER BY NEWID() OPTION (RECOMPILE); DBCC TRACEOFF(2453);
Tento plán již není triviální; optimalizace je označena jako plná. Většina nákladů se přesune na operátor řazení:
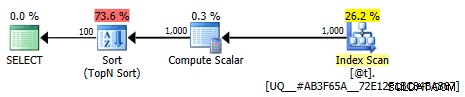
Méně triviální grafický plán
A odhady se shodují pro oba dotazy (tentokrát vám ušetřím tipy na nástroje, ale mohu vás ujistit, že jsou stejné):

Mřížka příkazů pro méně triviální plány s nápovědou pro rekompilaci a bez ní
Zdá se tedy, že článek KB není úplně přesný – dokázal jsem si vynutit chování očekávané od příznaku trasování, aniž bych zaváděl spojení. Ale chci to otestovat také s připojením.
Lepší test
Vezměme si tento jednoduchý příklad s příznakem trasování a bez něj:
--DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; --DBCC TRACEOFF(2453);
Bez příznaku trasování optimalizátor odhaduje, že jeden řádek bude pocházet z prohledávání indexu proti proměnné tabulky. Pokud je však povolen příznak trasování, získá 1 000 řádků:
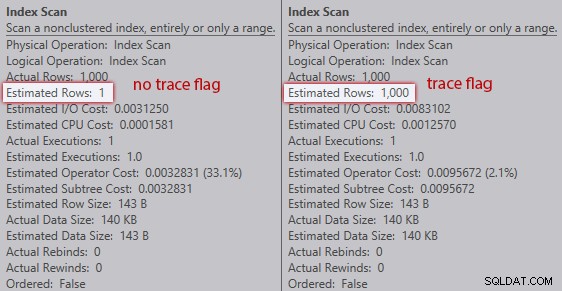
Porovnání odhadů skenování indexu (vlevo žádný příznak trasování, vlajka trasování vpravo)
Rozdíly tím nekončí. Když se podíváme blíže, můžeme vidět celou řadu různých rozhodnutí, která optimalizátor učinil, všechna vycházejí z těchto lepších odhadů:
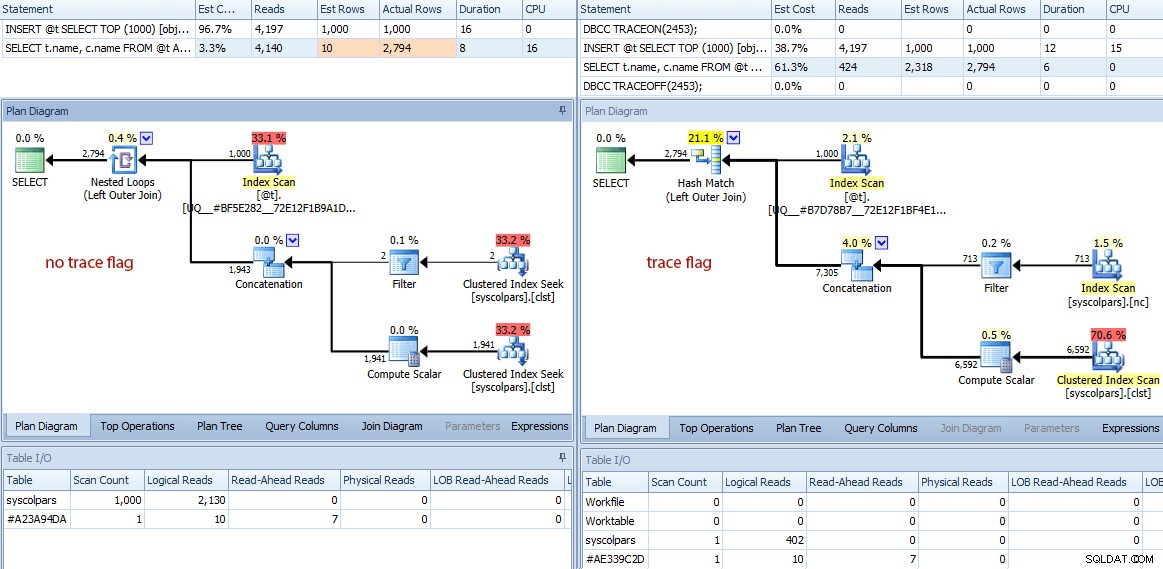
Porovnání plánů (žádný příznak trasování vlevo, příznak trasování vpravo)
Rychlé shrnutí rozdílů:
- Dotaz bez příznaku trasování provedl 4 140 operací čtení, zatímco dotaz s vylepšeným odhadem provedl pouze 424 (zhruba 90% snížení).
- Optimalizátor odhadl, že celý dotaz vrátí 10 řádků bez příznaku trasování a mnohem přesnějších 2 318 řádků při použití příznaku trasování.
- Bez příznaku trasování se optimalizátor rozhodl provést spojení vnořených smyček (což dává smysl, když se odhaduje, že jeden ze vstupů je velmi malý). To vedlo k tomu, že operátor zřetězení a oba hledání indexu se provedou 1 000krát, na rozdíl od shody hash zvolené pod příznakem trasování, kde se operátor zřetězení a oba skenování prováděly pouze jednou.
- Záložka Tabulka I/O také zobrazuje 1 000 skenů (prohledávání rozsahu maskované jako hledání indexu) a mnohem vyšší počet logických čtení proti
syscolpars(systémová tabulka zasys.all_columns). - Přestože trvání nebylo významně ovlivněno (24 milisekund vs. 18 milisekund), pravděpodobně si dokážete představit, jaký dopad by tyto další rozdíly mohly mít na vážnější dotaz.
- Pokud přepneme diagram na odhadované náklady, uvidíme, jak výrazně odlišná může proměnná tabulky oklamat optimalizátor bez příznaku trasování:
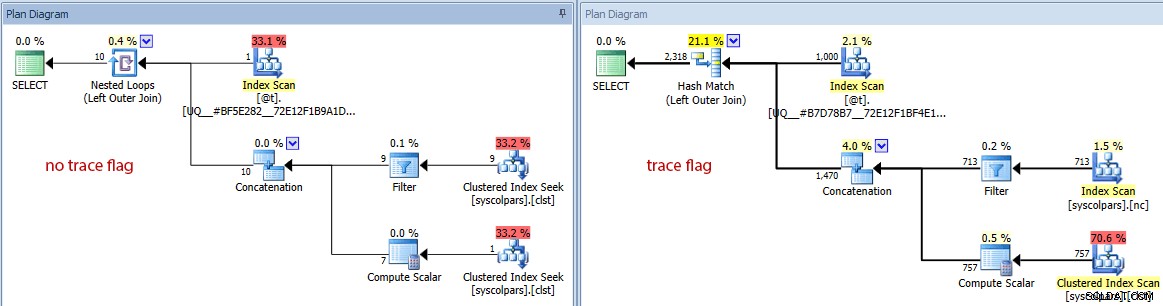
Porovnání odhadovaného počtu řádků (žádný příznak trasování vlevo, trasování vlajka vpravo)
Je jasné a není to šokující, že optimalizátor odvádí lepší práci při výběru správného plánu, když má přesný přehled o mohutnosti. Ale za jakou cenu?
Rekompilace a režie
Když použijeme OPTION (RECOMPILE) s výše uvedenou dávkou bez aktivovaného příznaku trasování získáme následující plán – který je v podstatě identický s plánem s příznakem trasování (jediný znatelný rozdíl je, že odhadované řádky jsou 2 316 namísto 2 318):
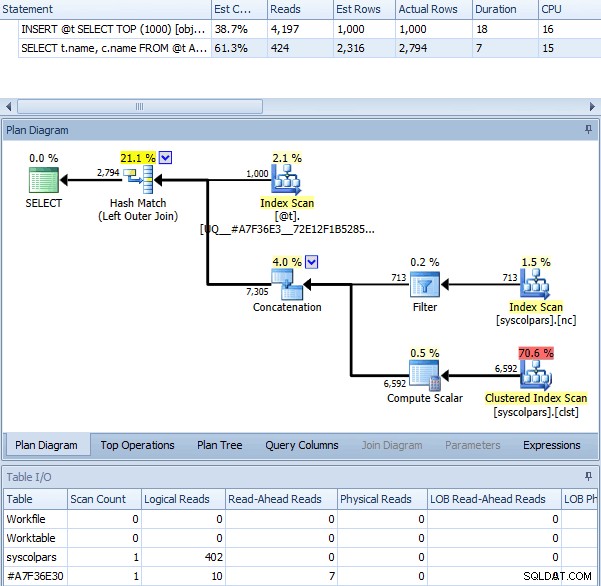
Stejný dotaz jako OPTION (REKOMPILOVAT)
To by vás mohlo vést k domněnce, že příznak trasování dosahuje podobných výsledků tím, že pokaždé spustí rekompilaci. Můžeme to prozkoumat pomocí velmi jednoduché relace Extended Events:
CREATE EVENT SESSION [CaptureRecompiles] ON SERVER
ADD EVENT sqlserver.sql_statement_recompile
(
ACTION(sqlserver.sql_text)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = N'C:\temp\CaptureRecompiles.xel'
);
GO
ALTER EVENT SESSION [CaptureRecompiles] ON SERVER STATE = START; Spustil jsem následující sadu dávek, které provedly 20 dotazů s (a) žádnou možností rekompilace nebo příznakem trasování, (b) možností rekompilace a (c) příznakem trasování na úrovni relace.
/* default - no trace flag, no recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; GO 20 /* recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id] OPTION (RECOMPILE); GO 20 /* trace flag */ DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DBCC TRACEOFF(2453); GO 20
Pak jsem se podíval na data události:
SELECT
sql_text = LEFT(sql_text, 255),
recompile_count = COUNT(*)
FROM
(
SELECT
x.x.value(N'(event/action[@name="sql_text"]/value)[1]',N'nvarchar(max)')
FROM
sys.fn_xe_file_target_read_file(N'C:\temp\CaptureRecompiles*.xel',NULL,NULL,NULL) AS f
CROSS APPLY (SELECT CONVERT(XML, f.event_data)) AS x(x)
) AS x(sql_text)
GROUP BY LEFT(sql_text, 255);
Výsledky ukazují, že při standardním dotazu nedošlo k žádné rekompilaci, příkaz odkazující na proměnnou tabulky byl rekompilován jednou pod příznakem trasování a jak můžete očekávat, pokaždé pomocí RECOMPILE možnost:
| sql_text | recompile_count |
|---|---|
| /* překompilovat */ DECLARE @t TABLE (i INT … | 20 |
| /* příznak trasování */ DBCC TRACEON(2453); PROHLÁSIT @t … | 1 |
Výsledky dotazu na data XEvents
Dále jsem vypnul relaci Extended Events a poté jsem změnil dávku na měření v měřítku. Kód v podstatě změří 1 000 iterací vytvoření a naplnění proměnné tabulky a poté vybere její výsledky do tabulky #temp (jeden způsob, jak potlačit výstup tolika nepoužitých sad výsledků), pomocí každé ze tří metod.
SET NOCOUNT ON; /* default - no trace flag, no recompile */ SELECT SYSDATETIME(); GO DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DROP TABLE #x; GO 1000 SELECT SYSDATETIME(); GO /* recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id] OPTION (RECOMPILE); DROP TABLE #x; GO 1000 SELECT SYSDATETIME(); GO /* trace flag */ DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DROP TABLE #x; DBCC TRACEOFF(2453); GO 1000 SELECT SYSDATETIME(); GO
Spustil jsem tuto dávku 10krát a vzal jsem průměry; byli:
| Metoda | Průměrná doba trvání (milisekundy) |
|---|---|
| Výchozí | 23 148,4 |
| Znovu zkompilovat | 29 959,3 |
| Příznak trasování | 22 100,7 |
Průměrná doba trvání pro 1 000 iterací
V tomto případě bylo získání správných odhadů při každém použití nápovědy pro rekompilaci mnohem pomalejší než výchozí chování, ale použití příznaku trasování bylo o něco rychlejší. To dává smysl, protože – zatímco obě metody opravují výchozí chování používání falešného odhadu (a v důsledku toho získání špatného plánu), rekompilace berou zdroje, a když neposkytují nebo nemohou poskytnout efektivnější plán, mají tendenci přispívají k celkovému trvání dávky.
Zdá se to jednoduché, ale počkejte…
Výše uvedený test je mírně – a záměrně – chybný. Do proměnné tabulky vkládáme pokaždé stejný počet řádků (1 000) . Co se stane, když se počáteční populace proměnné tabulky u různých dávek liší? Určitě se pak dočkáme rekompilací, dokonce i pod příznakem sledování, že? Čas na další test. Pojďme nastavit trochu jinou relaci Extended Events, jen s jiným názvem cílového souboru (aby nedošlo k záměně dat z druhé relace):
CREATE EVENT SESSION [CaptureRecompiles_v2] ON SERVER
ADD EVENT sqlserver.sql_statement_recompile
(
ACTION(sqlserver.sql_text)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = N'C:\temp\CaptureRecompiles_v2.xel'
);
GO
ALTER EVENT SESSION [CaptureRecompiles_v2] ON SERVER STATE = START;
Nyní se podívejme na tuto dávku a nastavíme počty řádků pro každou iteraci, které se výrazně liší. Spustíme to třikrát a odstraníme příslušné komentáře, takže máme jednu dávku bez příznaku trasování nebo explicitní rekompilaci, jednu dávku s příznakem trasování a jednu dávku s OPTION (RECOMPILE) (přesný komentář na začátku usnadňuje identifikaci těchto dávek na místech, jako je výstup Extended Events):
/* default, no trace flag or recompile */
/* recompile */
/* trace flag */
DECLARE @i INT = 1;
WHILE @i <= 6
BEGIN
--DBCC TRACEON(2453); -- uncomment this for trace flag
DECLARE @t TABLE(id INT PRIMARY KEY);
INSERT @t SELECT TOP (CASE @i
WHEN 1 THEN 24
WHEN 2 THEN 1782
WHEN 3 THEN 1701
WHEN 4 THEN 12
WHEN 5 THEN 15
WHEN 6 THEN 1560
END) [object_id]
FROM sys.all_objects;
SELECT t.id, c.name
FROM @t AS t
INNER JOIN sys.all_objects AS c
ON t.id = c.[object_id]
--OPTION (RECOMPILE); -- uncomment this for recompile
--DBCC TRACEOFF(2453); -- uncomment this for trace flag
DELETE @t;
SET @i += 1;
END
Spustil jsem tyto dávky v Management Studio, otevřel je jednotlivě v Průzkumníku plánů a filtroval strom příkazů pouze na SELECT dotaz. Rozdílné chování ve třech dávkách můžeme vidět při pohledu na odhadované a skutečné řádky:

Porovnání tří šarží, pohled na odhadované vs. skutečné řádky
V mřížce úplně vpravo můžete jasně vidět, kde pod příznakem trasování nedošlo k překompilování
Můžeme zkontrolovat data XEvents, abychom viděli, co se vlastně stalo s rekompilacemi:
SELECT
sql_text = LEFT(sql_text, 255),
recompile_count = COUNT(*)
FROM
(
SELECT
x.x.value(N'(event/action[@name="sql_text"]/value)[1]',N'nvarchar(max)')
FROM
sys.fn_xe_file_target_read_file(N'C:\temp\CaptureRecompiles_v2*.xel',NULL,NULL,NULL) AS f
CROSS APPLY (SELECT CONVERT(XML, f.event_data)) AS x(x)
) AS x(sql_text)
GROUP BY LEFT(sql_text, 255); Výsledky:
| sql_text | recompile_count |
|---|---|
| /* překompilovat */ DECLARE @i INT =1; KDYŽ … | 6 |
| /* příznak trasování */ DECLARE @i INT =1; KDYŽ … | 4 |
Výsledky dotazu na data XEvents
Velmi zajímavé! Pod příznakem trasování *vidíme* rekompilace, ale pouze v případě, že se hodnota parametru za běhu výrazně liší od hodnoty uložené v mezipaměti. Když se hodnota za běhu liší, ale ne o moc, nezískáme rekompilaci a použijí se stejné odhady. Je tedy jasné, že příznak trace zavádí práh rekompilace do proměnných tabulky, a potvrdil jsem (pomocí samostatného testu), že to používá stejný algoritmus jako ten, který je popsán pro #temp tabulky v tomto „starobylém“, ale stále relevantním článku. Dokážu to v následném příspěvku.
Znovu otestujeme výkon, spustíme dávku 1000krát (s vypnutou relací Extended Events) a změříme dobu trvání:
| Metoda | Průměrná doba trvání (milisekundy) |
|---|---|
| Výchozí | 101 285,4 |
| Znovu zkompilovat | 111 423,3 |
| Příznak trasování | 110 318,2 |
Průměrná doba trvání pro 1 000 iterací
V tomto konkrétním scénáři ztratíme přibližně 10 % výkonu pokaždé, když vynutíme rekompilaci nebo použijeme příznak trasování. Nevím přesně, jak byla delta rozdělena:Nebyly plány založené na lepších odhadech významně lepší? Vyrovnaly rekompilace jakékoli zvýšení výkonu o tolik ? Nechci tomu věnovat příliš mnoho času a byl to triviální příklad, ale ukazuje vám, že hrát si s tím, jak funguje optimalizátor, může být nepředvídatelná záležitost. Někdy můžete být lepší s výchozím chováním mohutnosti =1 s vědomím, že nikdy nezpůsobíte žádné zbytečné překompilování. Příznak trasování může dávat velký smysl, pokud máte dotazy, kde opakovaně naplňujete proměnné tabulky stejnou sadou dat (řekněme vyhledávací tabulka PSČ) nebo vždy používáte 50 nebo 1 000 řádků (řekněme vyplnění proměnná tabulky pro použití při stránkování). V každém případě byste určitě měli otestovat dopad, který to má na jakoukoli pracovní zátěž, kde plánujete zavést příznak trasování nebo explicitní rekompilace.
TVP a typy tabulek
Byl jsem také zvědavý, jak to ovlivní typy tabulek a zda uvidíme nějaké zlepšení v mohutnosti pro TVP, kde existuje stejný příznak. Vytvořil jsem tedy jednoduchý typ tabulky, který napodobuje dosud používanou proměnnou tabulky:
USE MyTestDB; GO CREATE TYPE dbo.t AS TABLE ( id INT PRIMARY KEY );
Pak jsem vzal výše uvedenou dávku a jednoduše nahradil DECLARE @t TABLE(id INT PRIMARY KEY); pomocí DECLARE @t dbo.t; – všechno ostatní zůstalo úplně stejné. Spustil jsem stejné tři dávky a tady je to, co jsem viděl:

Porovnání odhadů a skutečných hodnot mezi výchozím chováním, překompilováním možností a příznakem trasování 2453
Takže ano, zdá se, že příznak trasování funguje úplně stejně s TVP – rekompilace generují nové odhady pro optimalizátor, když počty řádků překročí práh rekompilace, a jsou přeskočeny, když jsou počty řádků „dost blízko.“
Pro, proti a upozornění
Jednou z výhod příznaku trasování je, že se některým můžete vyhnout překompiluje a stále vidíte mohutnost tabulky – pokud očekáváte, že počet řádků v proměnné tabulky bude stabilní, nebo pokud nezaznamenáte významné odchylky plánu kvůli různé mohutnosti. Další je, že to můžete povolit globálně nebo na úrovni relace a nemusíte zavádět rady pro rekompilaci na všechny vaše dotazy. A konečně, alespoň v případě, kdy byla mohutnost proměnných tabulky stabilní, správné odhady vedly k lepšímu výkonu než výchozí nastavení a také k lepšímu výkonu než použití možnosti rekompilace – všechny tyto kompilace se jistě mohou sčítat.
Existují samozřejmě i některé nevýhody. Jeden, který jsem zmínil výše, je ve srovnání s OPTION (RECOMPILE) přicházíte o určité optimalizace, jako je vkládání parametrů. Další je, že příznak trasování nebude mít dopad, který očekáváte na triviální plány. A jednou, kterou jsem cestou objevil, je použití QUERYTRACEON nápověda k vynucení příznaku trasování na úrovni dotazu nefunguje – pokud mohu říci, příznak trasování musí být na místě, když je vytvořena a/nebo naplněna proměnná tabulky nebo TVP, aby optimalizátor viděl mohutnost výše 1.
Mějte na paměti, že spuštění příznaku trasování globálně zavádí možnost regrese plánu dotazů na jakýkoli dotaz zahrnující proměnnou tabulky (proto byla tato funkce poprvé zavedena pod příznakem trasování), takže prosím otestujte celou svou zátěž bez ohledu na to, jak použijete příznak trasování. Také, když testujete toto chování, udělejte to prosím v databázi uživatelů; některé optimalizace a zjednodušení, u kterých normálně očekáváte, že nastanou, prostě nenastanou, když je kontext nastaven na tempdb, takže jakékoli chování, které tam pozorujete, nemusí zůstat konzistentní, když kód a nastavení přesunete do databáze uživatelů.
Závěr
Pokud používáte proměnné tabulky nebo TVP s velkým, ale relativně konzistentním počtem řádků, může být pro vás výhodné povolit tento příznak trasování pro určité dávky nebo procedury, abyste získali přesnou mohutnost tabulky bez ručního vynucení rekompilace na jednotlivé dotazy. Můžete také použít příznak trasování na úrovni instance, který ovlivní všechny dotazy. Ale jako každá změna, v obou případech budete muset být pečliví při testování výkonu celé vaší pracovní zátěže, explicitně se dívat na jakékoli regrese a zajistit, že chcete chování příznaku trasování, protože můžete důvěřovat stabilitě vaší proměnné tabulky. počet řádků.
Jsem rád, že do SQL Server 2014 byl přidán příznak trasování, ale bylo by lepší, kdyby se to stalo výchozím chováním. Ne že by používání velkých proměnných tabulek mělo oproti velkým #temp tabulek nějakou významnou výhodu, ale bylo by hezké vidět větší paritu mezi těmito dvěma dočasnými typy struktur, které by mohly být diktovány na vyšší úrovni. Čím větší paritu máme, tím méně se lidé musí rozhodovat, kterou z nich by měli použít (nebo alespoň mít méně kritérií, která je třeba při výběru zvážit). Martin Smith má skvělé otázky a odpovědi na dba.stackexchange, které se pravděpodobně nyní mají aktualizovat:Jaký je rozdíl mezi dočasnou tabulkou a proměnnou tabulky na serveru SQL?
Důležitá poznámka
Pokud se chystáte nainstalovat SQL Server 2012 Service Pack 2 (bez ohledu na to, zda chcete nebo nechcete použít tento příznak trasování), přečtěte si také můj příspěvek o regresi v SQL Server 2012 a 2014, která může ve vzácných případech zavést potenciální ztrátu dat nebo poškození během online obnovy indexu. K dispozici jsou kumulativní aktualizace pro SQL Server 2012 SP1 a SP2 a také pro SQL Server 2014. Pro větev RTM 2012 nebude žádná oprava.
Další testování
Mám na seznamu další věci k testování. Za prvé bych rád viděl, zda má tento příznak trasování nějaký vliv na typy tabulek v paměti v SQL Server 2014. Nade vší pochybnost také dokáži, že příznak trasování 2453 používá stejný práh rekompilace pro tabulku. proměnné a TVP jako u #temp tabulek.